
AI编程实战经验 全程0代码参与《天池二手车价格预测》MAE 499分优化之路
本文分享了如何通过AI辅助实现二手车价格预测模型优化。作者使用阿里云天池数据,通过CatBoost模型训练,重点讲解了特征工程和参数优化的关键步骤:1. 初始模型建立阶段,直接使用AI生成基础预测程序;2. 特征工程阶段,通过EDA分析、异常值处理、统计特征衍生(品牌价格特征等)将MAE从560优化到517;3. 参数优化阶段,通过20小时的超参数搜索将MAE降至499。文章特别强调了避免数据泄露
0代码写二手车价格预测,下面不涉及写代码,遇到不懂的地方直接问AI,让AI解释就可以!
AI写代码主要给AI下达指令,让AI自动生成代码,运行代码,出错再让AI修复,直到目标达成。AI能快速把想法转化为代码实现。下面分享如何将MAE优化到499。
MAE越小说明,整体预测价格与真实价格偏差小,模型训练得越好。
进入阿里云搜索天池二车手价格预测
话不多说,开始AI编程
提示语
train.cvs是训练集、test.cvs是测试集,请生成二手车预测程序,要求使用CatBoost训练模型,预测结果写入cvs,并输出训练集MAE、验证集MAE
就这么给AI说句话,AI基本上就把一个二手车价格的预测程序写出来了!如果AI没有尝试读取cvs的列名,可以让AI写代码打印cvs列名并翻译字段的含义。天池有cvs的数据字典,也可以直接贴给AI。
不做任何优化的话,验证集的MAE可能会很大,所以不能直接甩锅给AI。
二手车价格预测主要两个活,第一个是特征工程,第二步,模型参数优化。
特征工程做好了,MAE基本上能拿比较好的分。
提示语
对tain.cvs做EDA,将结果写入.md
提示语
对train.cvs做统计分析并给出特征工程建议写入 md,描述每一列的数据特征,是否有缺失值,给出缺失值的处理建议,是否有异常值,给出处理建议
提示语
依据分析结果落实建议
极端值处理
用这个代码替换了AI的
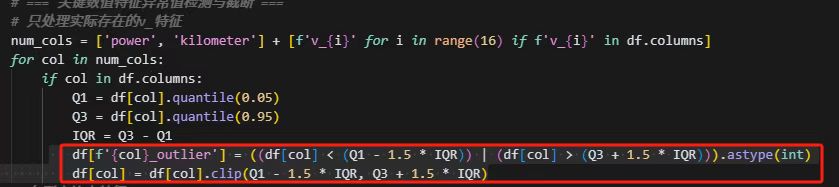
统计特征
给我感觉,如果不明确要求做统计特征操作,AI只做了异常值处理、空值填充等常规性操作!缺少统计特征。
提示语
tain.cvs划分成了训练集、验证集,test.cvs测试集。用训练集,统计不同品牌的价格特征形成衍生列,再合并到验证集、测试集。注意,不能直接使用验证集、测试集做统计,避免价格数据泄露
统计特征不做的话,MAE大概在560上下,做了统计特征,MAE能到517分上下。
统计特征包括均价、最小价格、最大价格、方差、标准差,可以是多种特征组合,比如:
不同品牌的价格统计特征,是不是很有实际意义,有的品牌溢价高,有的低。
不同品牌不同车龄的价格统计特征,体现出不同品牌的保值情况。
不同品牌不同车型的价格统计特征,也好理解吧
这里很容易出错的是,这种统计特征必须是在训练集统计,应用到验证集、测试集。如果直接用验证集的进行统计,会导致价格数据泄露,相当于让模型提前捕获到了验证集的价格信息。在数据上最大的体现就是MAE趋近于0,数值特别小,比如目前竞赛排行榜最好的成绩是300多分,因为这个误操作,本地可能跑出来MAE才8,提交到竞赛评估结果可能是2000,存在巨大的偏差。
特征工程做完,就是让AI寻找模型的超级参数,这个过程时间比较久,我这个代码执行了近20个小时吧,记不太清,总之非常费时间。这个过程让AI写代码输出进度信息,不然命令行一直不懂,也不知道进度情况。
模型对比,AI可以快速生成不同模型训练的比对效果。CatBoost、XGBoost、神卡网络,单模型、多模型融合,等等。我选择的是CatBoost。
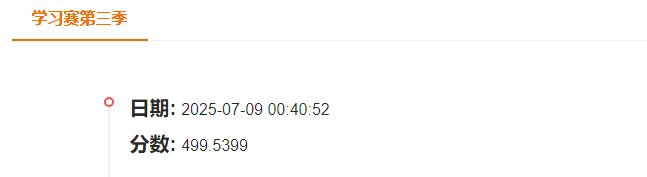
最终突破了500这关,抵达499分!
简单总结我的感受
MAE得分重点是特征工程,训练模型的超参数可以让AI生成超参数探索代码,花20个小时,就能拿到最优的参数。
特征工程程度与MAE得分
做了异常值处理、极端值处理、特征交互、log1处理 ,MAE能拿567分上下
做了统计特征,从训练集统计,合并到验证集、测试集,MAE能拿到516分上下
CatBoost超参数探索后,本地最优MAE 506分,竞赛评估结果499分
跑一次超参数20个小时,这是一个非常费时间的过程,跑一次就把参数记录下来,后面避免重复这个漫长的过程。
499再要向下突破,就得再想法子了。我的想法是,模型参数没有优化空间,就只能在特征工程上下功夫了。
499不是终点,后续再分享。
AI写代码工具 CodeBuddy


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)