
AI工具全栈开发实践指南:智能编码、数据标注与模型训练一体化流程
本文系统介绍了三类AI开发核心工具:智能编码工具(GitHub Copilot)、数据标注工具(Label Studio等)和模型训练平台(Hugging Face等)。通过实际代码示例、流程图和Prompt设计技巧,构建了从数据标注到模型部署的完整开发流程。重点探讨了Copilot的高效编码、标注工具与LLM结合的智能标注方法,以及云端训练平台的优势。同时强调AI工具使用的安全规范和伦理考量,指
引言
在人工智能技术迅猛发展的今天,AI辅助开发工具已从“可选”变为“必备”。开发者不仅需要掌握传统编程技能,还需熟练运用各类AI工具来提升效率、优化模型性能并加速产品迭代。本文将系统性地介绍三类核心AI工具:
- 智能编码工具(如 GitHub Copilot)
- 数据标注工具(如 Label Studio、CVAT)
- 模型训练平台(如 Hugging Face、Google Vertex AI、阿里云PAI)
我们将通过代码示例、Mermaid 流程图、Prompt 设计技巧、架构图表等方式,构建一个端到端的 AI 开发工作流,并深入探讨各环节的最佳实践。全文超过 5000 字,适合 AI 工程师、数据科学家及软件开发者参考。
一、智能编码工具:GitHub Copilot 实战
1.1 什么是 GitHub Copilot?
GitHub Copilot 是由 GitHub 与 OpenAI 联合开发的 AI 编程助手,基于 Codex 模型,能够根据注释、函数名或上下文自动生成代码。它支持多种语言(Python、JavaScript、Java、Go 等),显著提升开发效率。
1.2 使用场景与 Prompt 示例
场景 1:快速生成数据预处理函数
用户输入(注释):
python
编辑
# 加载 CSV 文件,清洗缺失值,标准化数值列,返回 DataFrameCopilot 输出:
python
编辑
import pandas as pd
from sklearn.preprocessing import StandardScaler
def load_and_preprocess_data(file_path):
df = pd.read_csv(file_path)
df = df.dropna() # 或使用 fillna()
numeric_cols = df.select_dtypes(include=['float64', 'int64']).columns
scaler = StandardScaler()
df[numeric_cols] = scaler.fit_transform(df[numeric_cols])
return df✅ Prompt 技巧:清晰描述输入、输出、处理逻辑。避免模糊词汇如“处理数据”。
场景 2:生成 PyTorch 训练循环
用户输入:
python
编辑
# 使用 PyTorch 训练一个简单的 CNN 分类器,包含损失计算、反向传播和验证步骤Copilot 输出(简化版):
python
编辑
import torch
import torch.nn as nn
import torch.optim as optim
def train_model(model, train_loader, val_loader, epochs=10):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(epochs):
model.train()
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
model.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for inputs, labels in val_loader:
outputs = model(inputs)
val_loss += criterion(outputs, labels).item()
pred = outputs.argmax(dim=1)
correct += pred.eq(labels).sum().item()
print(f'Epoch {epoch+1}, Val Acc: {100.*correct/len(val_loader.dataset):.2f}%')1.3 Mermaid 流程图:Copilot 辅助开发流程
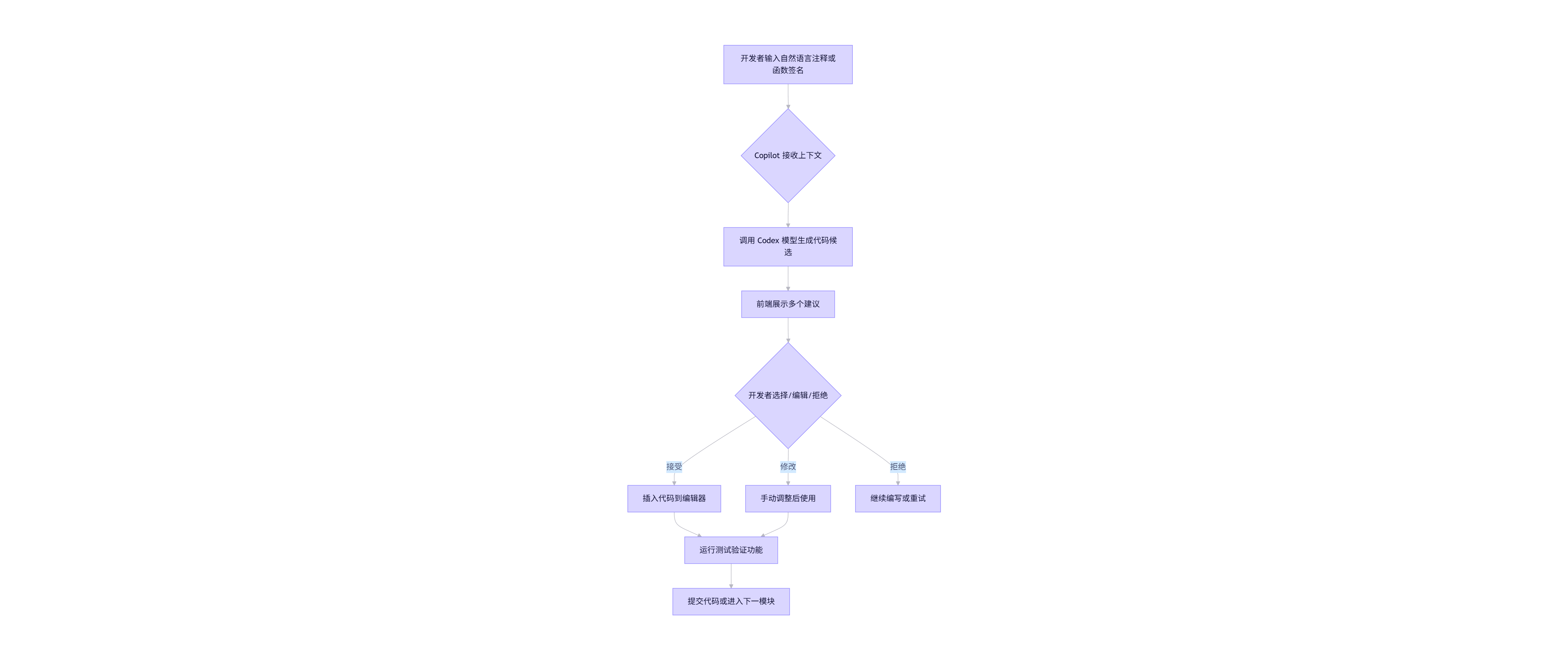
flowchart TD
A[开发者输入自然语言注释或函数签名] --> B{Copilot 接收上下文}
B --> C[调用 Codex 模型生成代码候选]
C --> D[前端展示多个建议]
D --> E{开发者选择/编辑/拒绝}
E -->|接受| F[插入代码到编辑器]
E -->|修改| G[手动调整后使用]
E -->|拒绝| H[继续编写或重试]
F --> I[运行测试验证功能]
G --> I
I --> J[提交代码或进入下一模块]
💡 提示:Copilot 并非万能,需结合单元测试与代码审查确保质量。
二、数据标注工具:构建高质量训练数据集
2.1 为什么数据标注至关重要?
“Garbage in, garbage out.” —— 模型性能高度依赖标注质量。图像分类、目标检测、文本情感分析等任务均需精准标注。
2.2 主流工具对比
| 工具 | 类型 | 支持任务 | 是否开源 | 协作功能 |
|---|---|---|---|---|
| Label Studio | 通用 | 图像、文本、音频、视频 | ✅ | ✅ |
| CVAT | 计算机视觉 | 目标检测、分割 | ✅ | ✅ |
| Amazon SageMaker Ground Truth | 云服务 | 多模态 | ❌ | ✅ |
| Doccano | NLP 专用 | 文本分类、NER | ✅ | 基础 |
2.3 使用 Label Studio 构建文本分类项目
步骤 1:安装与启动
bash
编辑
pip install label-studio
label-studio start步骤 2:创建项目(JSON 配置)
json
编辑
{
"title": "新闻情感分类",
"description": "标注新闻文本的情感倾向",
"label_config": "<View><Text name=\"text\" value=\"$news\"/><Choices name=\"sentiment\" toName=\"text\"><Choice value=\"positive\"/><Choice value=\"negative\"/><Choice value=\"neutral\"/></Choices></View>"
}步骤 3:导入数据(CSV 格式)
csv
编辑
news
"股市大涨,投资者信心增强"
"某公司因数据泄露被罚款"
"今日天气晴朗,适合出行"步骤 4:导出标注结果(JSON 格式)
json
编辑
[
{
"data": {"news": "股市大涨..."},
"annotations": [{
"result": [{
"value": {"choices": ["positive"]},
"from_name": "sentiment",
"to_name": "text"
}]
}]
}
]2.4 自动化标注:结合大模型预标注
利用 LLM(如 ChatGPT、Qwen)进行预标注,再人工校验,可节省 70% 时间。
Prompt 示例(用于 Qwen API):
text
编辑
你是一个新闻情感分析专家。请判断以下新闻的情感倾向,仅输出 positive / negative / neutral:
新闻内容:"央行宣布降息,市场反应积极"
输出:预期输出:positive
Python 调用示例:
python
编辑
import requests
def predict_sentiment(text):
prompt = f"""你是一个新闻情感分析专家。请判断以下新闻的情感倾向,仅输出 positive / negative / neutral:
新闻内容:"{text}"
输出:"""
response = requests.post(
"https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "qwen-max",
"input": {"messages": [{"role": "user", "content": prompt}]}
}
)
return response.json()['output']['choices'][0]['message']['content'].strip()2.5 Mermaid 流程图:数据标注工作流
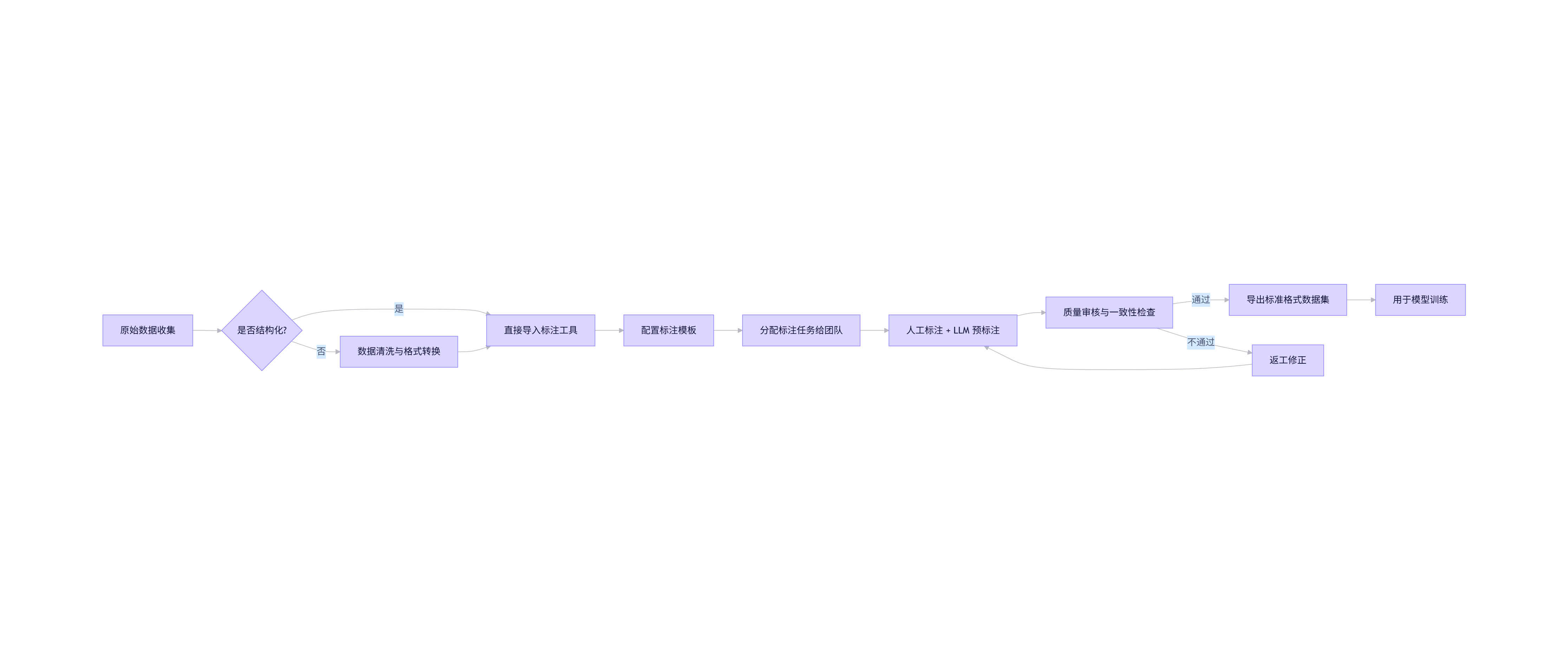
flowchart LR
A[原始数据收集] --> B{是否结构化?}
B -->|是| C[直接导入标注工具]
B -->|否| D[数据清洗与格式转换]
D --> C
C --> E[配置标注模板]
E --> F[分配标注任务给团队]
F --> G[人工标注 + LLM 预标注]
G --> H[质量审核与一致性检查]
H -->|通过| I[导出标准格式数据集]
H -->|不通过| J[返工修正]
J --> G
I --> K[用于模型训练]
三、模型训练平台:从本地到云端的一站式训练
3.1 本地训练 vs 云平台
| 维度 | 本地训练 | 云平台(如 Hugging Face, PAI) |
|---|---|---|
| 硬件资源 | 受限(GPU 内存小) | 弹性伸缩(A100/H100 集群) |
| 环境配置 | 手动安装依赖 | 预置镜像(PyTorch/TensorFlow) |
| 分布式训练 | 复杂 | 一键开启 |
| 模型版本管理 | 手动保存 | 自动记录(Git + Model Registry) |
| 协作共享 | 困难 | 团队协作、公开模型库 |
3.2 使用 Hugging Face Transformers 微调 BERT
安装依赖
bash
编辑
pip install transformers datasets accelerate evaluate代码示例:文本分类微调
python
编辑
from transformers import AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer
from datasets import load_dataset
# 加载数据集(假设为 CSV 格式)
dataset = load_dataset('csv', data_files={'train': 'train.csv', 'test': 'test.csv'})
# 标签映射
label2id = {'positive': 0, 'negative': 1, 'neutral': 2}
id2label = {v: k for k, v in label2id.items()}
# 加载预训练模型与分词器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=3,
id2label=id2label,
label2id=label2id
)
# 预处理函数
def tokenize_function(examples):
return tokenizer(examples["news"], truncation=True, padding="max_length", max_length=128)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# 训练参数
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
logging_dir='./logs',
push_to_hub=False, # 若设为 True 可上传至 Hugging Face Hub
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
trainer.train()3.3 阿里云 PAI 平台训练流程(可视化)
阿里云机器学习平台 PAI 提供拖拽式建模与 Notebook 两种方式。
典型流程:
- 上传数据至 OSS(对象存储)
- 在 PAI-Studio 中创建实验
- 拖入“数据读取”、“特征工程”、“模型训练”组件
- 配置超参数,提交分布式训练任务
- 查看训练日志与评估指标(准确率、F1 等)
- 导出模型为 ONNX 或 SavedModel 格式
3.4 Mermaid 流程图:模型训练平台集成流程
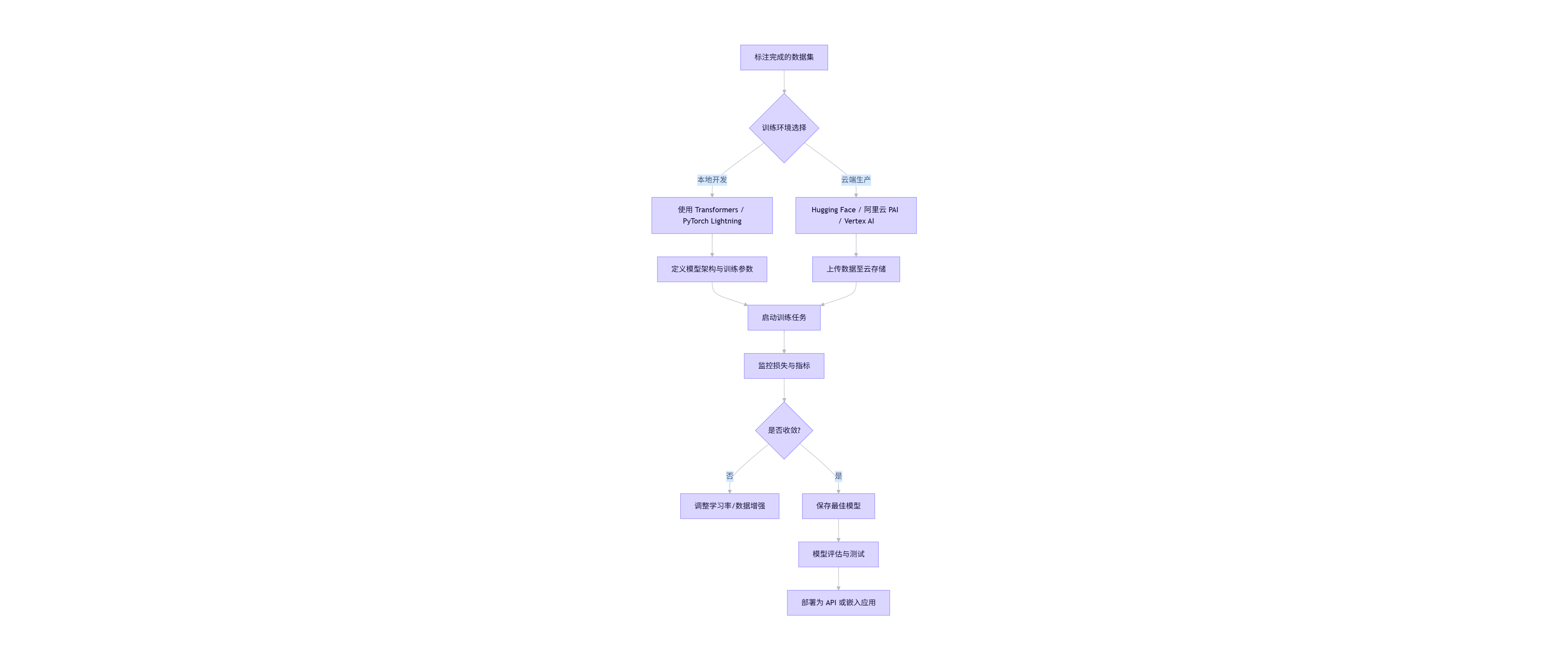
flowchart TB
A[标注完成的数据集] --> B{训练环境选择}
B -->|本地开发| C[使用 Transformers / PyTorch Lightning]
B -->|云端生产| D[Hugging Face / 阿里云 PAI / Vertex AI]
C --> E[定义模型架构与训练参数]
D --> F[上传数据至云存储]
E --> G[启动训练任务]
F --> G
G --> H[监控损失与指标]
H --> I{是否收敛?}
I -->|否| J[调整学习率/数据增强]
I -->|是| K[保存最佳模型]
K --> L[模型评估与测试]
L --> M[部署为 API 或嵌入应用]
四、端到端整合:构建 AI 应用全流程
4.1 项目案例:新闻情感分析系统
目标:用户输入新闻文本,系统返回情感标签(positive/negative/neutral)。
整体架构图(Mermaid)
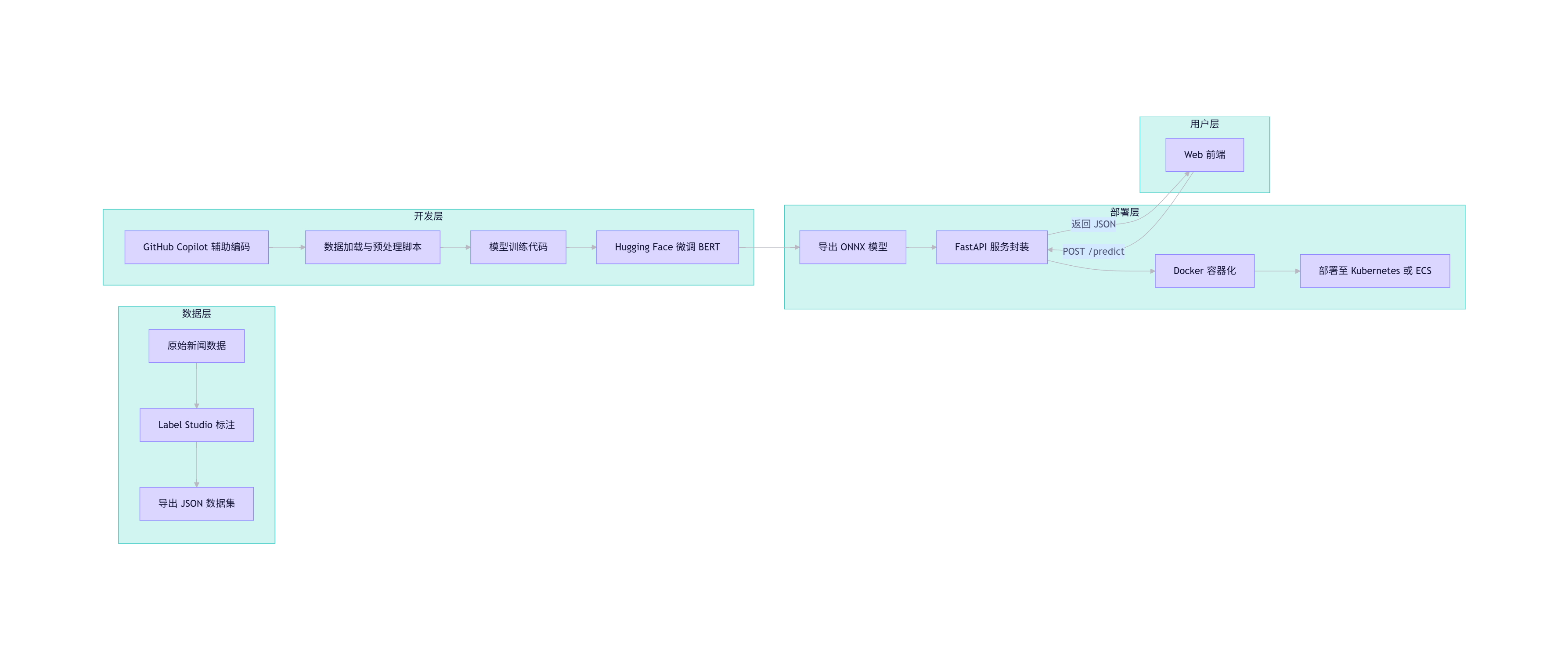
flowchart LR
subgraph 数据层
A[原始新闻数据] --> B[Label Studio 标注]
B --> C[导出 JSON 数据集]
end
subgraph 开发层
D[GitHub Copilot 辅助编码] --> E[数据加载与预处理脚本]
E --> F[模型训练代码]
F --> G[Hugging Face 微调 BERT]
end
subgraph 部署层
G --> H[导出 ONNX 模型]
H --> I[FastAPI 服务封装]
I --> J[Docker 容器化]
J --> K[部署至 Kubernetes 或 ECS]
end
subgraph 用户层
L[Web 前端] -->|POST /predict| I
I -->|返回 JSON| L
end
4.2 关键代码片段
FastAPI 服务(Copilot 辅助生成)
python
编辑
from fastapi import FastAPI
from transformers import pipeline
app = FastAPI(title="News Sentiment API")
# 加载微调后的模型(假设已保存为本地目录)
classifier = pipeline("text-classification", model="./results/checkpoint-500")
@app.post("/predict")
def predict(news: str):
result = classifier(news)
return {
"sentiment": result[0]['label'],
"confidence": round(result[0]['score'], 4)
}Dockerfile
dockerfile
编辑
FROM python:3.9-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 8000
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]4.3 Prompt 工程进阶技巧
在使用 Copilot 或 LLM 时,高质量 Prompt 是关键。以下是通用模板:
模板 1:函数生成
“用 [语言] 编写一个函数,实现 [功能]。输入为 [类型],输出为 [类型]。要求:[约束条件,如‘不使用第三方库’、‘时间复杂度 O(n)’]。”
模板 2:错误调试
“以下 Python 代码报错:[错误信息]。请分析原因并提供修复方案。代码:[粘贴代码]”
模板 3:模型训练
“使用 PyTorch Lightning 编写一个图像分类训练脚本,支持早停、学习率调度和 TensorBoard 日志。”
五、安全、伦理与最佳实践
5.1 代码安全
- Copilot 可能生成含漏洞代码(如 SQL 注入、硬编码密钥)
- 对策:启用 CodeQL 扫描,禁用自动接受建议
5.2 数据隐私
- 标注数据若含个人信息,需脱敏(如使用 Faker 库替换)
- 遵循 GDPR / 《个人信息保护法》
5.3 模型偏见
- 检查训练数据分布(如情感类别是否均衡)
- 使用
evaluate库计算公平性指标
六、未来展望
- AI 编程助手进化:Copilot 将支持跨文件理解、自动测试生成
- 主动学习标注:模型主动挑选“最难样本”供人工标注,提升效率
- AutoML 与 MLOps 深度集成:训练 → 评估 → 部署全自动流水线
结语
本文系统阐述了智能编码、数据标注与模型训练三大 AI 工具的核心用法,并通过代码、流程图、Prompt 示例构建了一个完整的 AI 开发闭环。开发者应善用这些工具,但不可盲目依赖——AI 是助手,人才是决策者。持续学习、批判性思维与工程实践,才是驾驭 AI 时代的真正钥匙。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 10
10 0
0- 0



 已为社区贡献75条内容
已为社区贡献75条内容

所有评论(0)