
CodeGraph 深度解析:给 Claude Code / Cursor 一张”本地代码地图”
一、项目快照
CodeGraph(colbymchenry/codegraph)是 2026 年 1 月由独立开发者 Colby McHenry 创建的开源项目,他在 Medium 个人介绍中自我描述为”15+ 年经验的自学软件工程师”。截至 2026 年 5 月 27 日,仓库已经积累了约 29.1k stars / 1.7k forks / 25+ contributors,5 月 23 日单日新增 2,434 star,登上 GitHub Trending 第二位。
技术栈非常简单:
- TypeScript 94.8% / JavaScript 5.2% 没有 Neo4j、没有向量数据库、没有外部 LLM API。
- License:MIT
- 支持平台:Windows / macOS / Linux,要求 Node ≥18 <25;0.9 起捆绑自己的 Node 运行时,可裸机一键安装
一句话定位:给 Claude Code、Codex CLI、Cursor、OpenCode、Gemini CLI、Antigravity、Kiro、Hermes Agent 做”前置索引”的本地 MCP 服务器。
二、它到底要解决什么问题
任何用过 Claude Code 或 Cursor agent 模式的人都见过这一幕:你问”用户认证流程是怎么走的?”,agent 立刻派出一个 Explore subagent,开始 grep -r → ls → Read file:1-200 → Read file:201-400 的循环。等它读完十几个文件,几万 token 已经烧掉,你的问题甚至还没真正开始回答。
作者把这件事量化了。在 Medium 长文里他写道:”我在自己的项目上计时——60 次 tool call、157,800 tokens、近 2 分钟的探索,Claude 才真正开始处理我的请求。”
CodeGraph 的核心立论是:这种探索本质上是把”静态结构信息”用 LLM 的工作记忆反复重算。文件之间的调用、import、继承关系是确定性的、AST 可推导的,没有任何理由每次会话都让 agent 用 grep 重新发现。提前算一次、放在本地 SQLite 里、通过 MCP 直接喂给 agent,就够了。
三、架构:极其工程化的 tree-sitter + SQLite
CodeGraph 的设计可以用一张图概括:
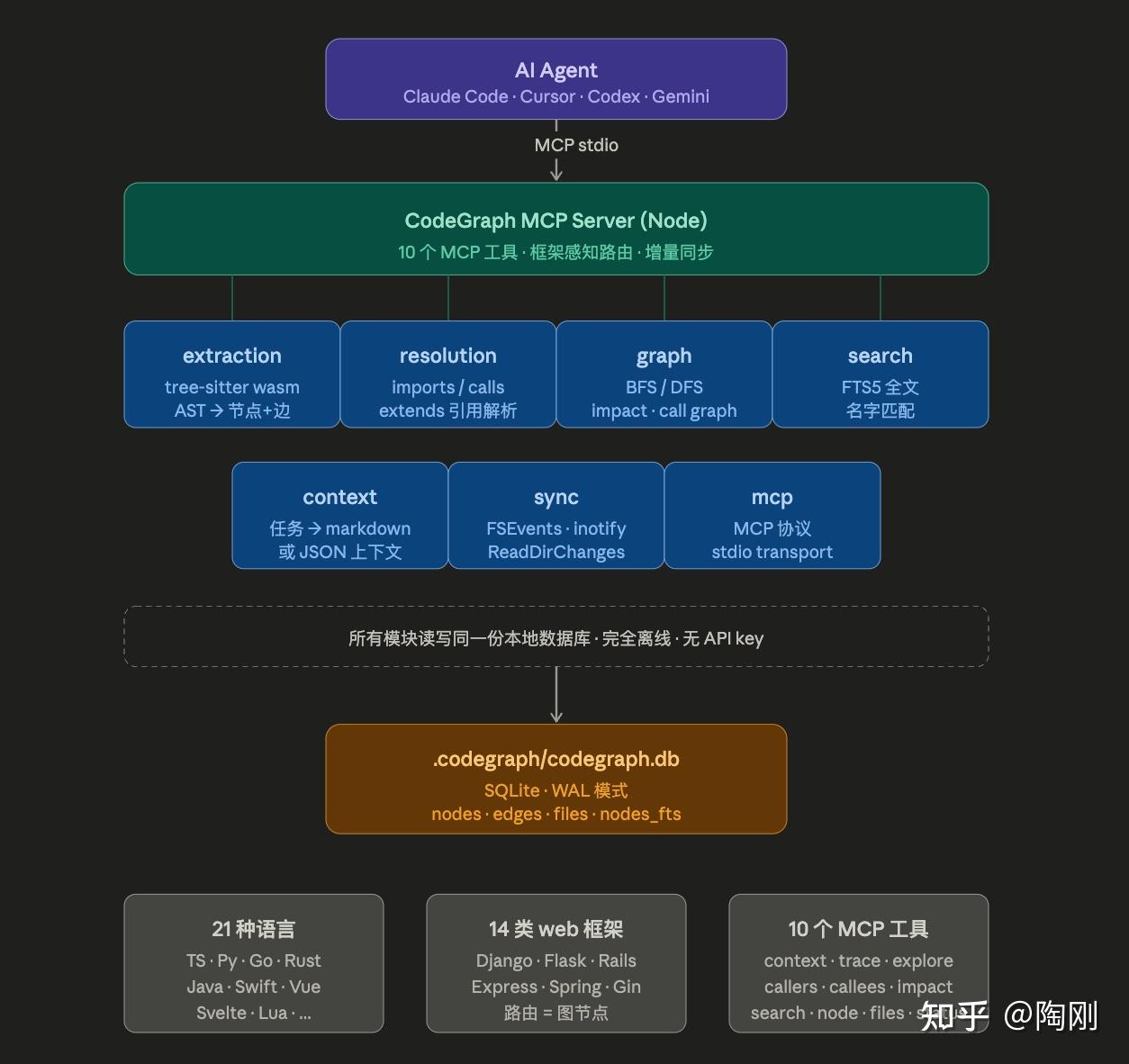
3.1 抽取:tree-sitter,而非 LSP
这里介绍一下"程序怎么理解代码"和相关的工具:
tree-sitter 是什么
tree-sitter 是 GitHub 在 2018 年开源的增量解析器生成器,原本是为 Atom 编辑器做代码高亮做的。它的工作就一件事:把源代码字符串变成一棵语法树(AST)。
你给它一段 Python:
def add(a, b):
return a + b它返回一棵结构化的树:
function_definition
├── name: "add"
├── parameters: [a, b]
└── body
└── return_statement
└── binary_expression (+)
├── left: a
└── right: b三个让它特别受欢迎的特点:
- 增量解析——你改一行代码,它只重算受影响的子树,不重头扫整个文件。这是它原本叫这个名字的原因,编辑器实时高亮全靠它。
- 容错——代码语法错了它照样能解析,给你"尽量正确"的树。LLM agent 写代码常常写到一半,这点很关键。
- 纯语法、不懂语义——它知道
add(a, b)是个函数调用,但不知道这个add到底定义在哪。它不做类型推断、不做跨文件引用解析。
LSP 是什么
LSP 全称 Language Server Protocol(语言服务器协议),是微软在 2016 年为 VS Code 设计、后来变成业界标准的协议。
它解决的问题是:以前每个 IDE 都得为每种语言单独写一套"代码智能"(跳转到定义、自动补全、找引用、重命名……)。N 种 IDE × M 种语言 = N×M 份重复工作。LSP 把这个矩阵拆成两半:
编辑器 (VS Code / Neovim / Cursor)
↕ LSP 协议 (JSON-RPC)
语言服务器 (rust-analyzer / pyright / tsserver / clangd)
↕
你的代码语言服务器是真正懂这门语言的程序——它通常基于编译器本身(rust-analyzer 来自 Rust 编译器团队、pyright 是微软的 Python 类型检查器、tsserver 来自 TypeScript 团队)。它能回答语义级问题:
- "光标下的
validateToken跳转到哪里?" - "这个变量是什么类型?"
- "谁调用了这个函数?"(不是名字相同的,是真正调用这个定义的)
- "把这个函数改名,所有引用一起改"
LSP 跑得更准,因为它真的理解类型系统、import resolution、泛型实例化——本质上它在脑子里维护了一份能编译的代码模型。
两者的关键差异
| tree-sitter | LSP(语言服务器) | |
|---|---|---|
| 回答的问题 | 语法:"这是个函数吗?" | 语义:"这个函数定义在哪?" |
| 需要编译吗 | 不需要,代码错了也能解析 | 通常需要项目能编译/类型检查 |
| 跨文件理解 | 没有 | 有 |
| 每种语言 | 一份 wasm(小、统一) | 一个独立的服务器进程(重、各家实现差异大) |
| 速度 | 毫秒级,编辑器实时用 | 大项目首次加载几秒到几十秒 |
| 典型用途 | 语法高亮、代码折叠、批量符号抽取 | IDE 跳转、重命名、补全、类型检查 |
CodeGraph 选 tree-sitter 而不是 LSP,是一个明确的工程权衡:
- 它放弃了"真正理解类型"的精度(比如
obj.foo()里obj到底是什么类的实例,tree-sitter 答不上来) - 换来了三件事:不用项目能编译(agent 在写到一半的代码上也能工作)、一份 wasm 覆盖所有平台(部署极简)、索引快到可以毫秒级响应文件保存
CodeGraph 全部走 tree-sitter wasm,对每种语言写一份 query 提取以下节点(来自 CLAUDE.md 列出的 NodeKind):
file, module, class, struct, interface, trait, protocol, function, method, property, field, variable, constant, enum, enum_member, type_alias, namespace, parameter, import, export, route, component
和以下边(EdgeKind):
contains, calls, imports, exports, extends, implements, references, type_of, returns, instantiates, overrides, decorates
这是关键的技术权衡:tree-sitter 比 LSP 弱(没有真正的类型推断、没有跨包符号表),但它有三个决定性优势:(1) 不需要项目能编译;(2) 一份 wasm 二进制覆盖所有平台;(3) 增量解析快到可以毫秒级响应文件保存。对一个面向 agent 的”探索性查询”工具,这个折中是合理的。
支持的语言现在已扩展到 21 种:TypeScript / JavaScript / Python / Go / Rust / Java / C# / PHP / Ruby / C / C++ / Swift / Kotlin / Scala / Dart / Svelte(含 Svelte 5 runes 和 SvelteKit 路由)/ Vue(含 Nuxt)/ Liquid(Shopify 主题)/ Pascal-Delphi(含 DFM/FMX 表单文件)/ Lua / Luau(Roblox)。
3.2 存储:SQLite + FTS5,没有图数据库
这是 CodeGraph 和友商最大的体系差异之一。看 schema(来自 IMPLEMENTATION_PLAN.md)就知道作者在追求什么:
nodes(id, kind, name, qualified_name, file_path, start_line, end_line,
language, signature, docstring, code_snippet, code_hash, metadata)
edges(source_id, target_id, kind, resolved, target_name, line_number)
files(path, content_hash, language, last_indexed, node_count)
unresolved_refs(...)
nodes_fts USING fts5(...) -- 全文搜索节点 ID 就是字符串路径如 "func:src/auth.ts:validateToken:45"。SQLite 在 WAL 模式下并发读写不阻塞,再加上为每种查询模式都准备好索引,BFS/DFS 在 10 万节点级别仍然亚毫秒。
值得注意的是,仓库早期的设计里有 vectors/ 模块(基于 @xenova/transformers 跑 ONNX,存 384 维 nomic-embed-text-v1.5 embeddings,SQLite vss 索引),但在某次提交中被整个移除了——issue #87 里有中国用户 zzqq131 直接问”为什么把整个向量搜索和 embedding 模块删掉?”。这个决策意味深长:作者用实测发现,对”找调用链、找定义、找路由”这类问题,符号名 + FTS5 + 图遍历就足够了,向量检索引入的延迟和不确定性反而是负担。
3.3 引用解析:手写而非 LLM 总结
resolution/ 模块做三件事:
- Imports → 文件:识别 tsconfig path alias、Cargo workspace、Python package
- Calls → 定义:先用 import 表过滤候选,再做 name matching
- Inheritance:
extends/implements双向边
特殊的是 dynamic-dispatch 桥接(synthesizers):识别 callback/observer 注册、EventEmitter、React setState → render、JSX render → child component、Django ORM descriptors 等模式,给图加一条 provenance: 'heuristic' 的合成边。这是让 trace 工具能跨”事件分发、回调、运行时绑定”这些 grep 永远穿不过的边界的关键。
3.4 暴露给 agent 的 10 个 MCP tool
按文档语义分两类。重型工具(agent 主力,main session 应避免直接调用):
codegraph_context— 给定一个任务/特性描述,组合 search + node + callers + callees,一次返回”涉及到的入口和上下文”codegraph_trace— “X 是怎么调到 Y 的”,每一跳的函数体内联返回,跨动态分发,一次 trace 调用就结束流程探索codegraph_explore— 一次返回若干相关符号的源码(按文件分组)+ 关系图
轻型工具(main session 可直接用,用于做改动前的精准查询):
codegraph_search(按名字找符号,只返位置)codegraph_callers/codegraph_callees(调用链)codegraph_impact(改动影响半径)codegraph_node(单个符号详情,可附源码)codegraph_files(项目文件树,比文件系统扫描快)codegraph_status(索引健康度)
CLAUDE.md 里有一段工程笔记,值得 agent 开发者借鉴:”CodeGraph 影响 agent 行为的渠道是低显著性的——只有 MCP initialize instructions 和 tool descriptions。改 wording 并不能可靠地改变 agent 的 tool 选择风格。真正起作用的是让工具本身一次性给够,让 agent 没有理由 fallback 去 Read。“
3.5 框架感知路由
extraction/frameworks/ 识别 14 类 web 框架的路由声明,把它们也变成图节点(kind: 'route'):
Django (path/re_path/url/include)、Flask、FastAPI、Express、NestJS(含 GraphQL/WebSocket)、Laravel、Drupal(*.routing.yml+ hook_*)、Rails、Spring(@GetMapping等)、Gin/chi/gorilla/mux、Axum/actix/Rocket、ASP.NET([HttpGet])、Vapor、React Router/SvelteKit
这意味着你可以让 agent 问”POST /api/users 这个接口的实现在哪?影响哪些下游?”——一次 codegraph_impact 直接出结果。
3.6 自动同步
sync/ 用原生 OS 事件 (FSEvents / inotify / ReadDirectoryChangesW),2 秒静默窗口 debounce,只过滤源码文件,做增量 reparse。结果是:你 Cmd-S 保存代码,再问 agent 时图已经更新。
四、横向对比:code RAG 这个赛道分几派
我把目前面向 AI agent 做代码上下文的工具按”如何表示代码”分了五派。CodeGraph 处在”图派 + 本地优先”那一格,相对位置很清楚:
| 工具 | 核心表示 | 索引位置 | 给 agent 的接口 | 主要场景 |
|---|---|---|---|---|
| CodeGraph | tree-sitter AST → SQLite 图 + FTS5 | 本地 | MCP(10 个工具) | Claude Code/Cursor/Codex 等 agent 的探索加速 |
| Aider repo map | tree-sitter tags + PageRank | 本地 | 拼到 prompt 里 | Aider 终端 pair programming |
| Cursor 内建索引 | 文件分块 → embedding | 远端 Turbopuffer + Merkle 树同步 | @Codebase | Cursor IDE 内 |
| Continue.dev | tree-sitter 分块 + embedding + FTS | 本地 ~/.continue/index | @Codebase / @Folder | Continue IDE 插件 |
| Sourcegraph Cody | SCIP(LSIF 后继)+ embedding | 远端 Sourcegraph 实例 | 内建 + MCP server | 企业代码搜索 |
| Augment Code | 语义索引(专有 Context Engine) | 远端 | MCP(远端 HTTPS) | 企业级 agent,跨仓 |
| Potpie.ai | Neo4j 属性图 | 服务端(自托管或 SaaS) | FastAPI + 专用 agent | 企业 spec-driven 大代码库 |
| Greptile | 仓库依赖图 | 远端 SaaS | PR review agent | AI code review |
| Bloop | 语义搜索 | 桌面/远端 | 桌面 UI | 自然语言代码搜索 |
| Repomix / Code2Prompt / yek | 整库拼成大文本 | 本地 | 复制粘贴 / MCP | 给长上下文 LLM 做一次性 dump |
| CodeQL | 数据流+控制流 facts → Datalog | 本地 | QL 查询 | 安全分析 / variant analysis |
| Glean (Meta) | 通用代码事实库 + SCIP 输入 | 服务端 | Glass API | Meta 内部 IDE / RAG |
4.1 对比Aider 的 repo map:相似目标,不同形态
Aider 是这条思路的开山者。它同样用 tree-sitter 抽 tags,但用 PageRank 给整个 repo 的符号排序,再在一个 token budget 里塞最重要的 N 个 tags 进 prompt。对比 CodeGraph:
- Aider 是”预算化的单次上下文“——Aider 官方文档明确写道:
"这个 token 预算受 --map-tokens 参数控制,默认 1k tokens。Aider 会根据对话的当前状态动态调整 repo map 的大小。"(默认 1k tokens 的 repo map 跟着每次对话发,可动态扩展)
- CodeGraph 是”按需图查询“——agent 自己决定问哪一片,每次只取相关子图。
对 Aider 这种”一次会话改几个文件”的 pair programming 模式,PageRank 静态摘要足够好。对 Claude Code 这种”先 explore subagent 摸清架构”的 agent 流水线,CodeGraph 的按需查询更省 token。
4.2 对比Cursor / Continue:embedding 派和图派的根本差异
Cursor 的做法是教科书级的 RAG,且公开的工程细节最完整:根据 Cursor 官方博客 cursor.com/blog/secure-codebase-indexing 和 turbopuffer 的客户案例页面
"Cursor 用一棵 Merkle 树来构建对代码库的初始视图……每个代码库实例在 turbopuffer 里都是一个独立的命名空间(namespace)。"
"turbopuffer 为 Cursor 提供代码检索能力——在合适的时机,把代码搜索的结果填充进上下文窗口。"。
流程是:本地按 tree-sitter 切块 → 上传 Cursor 服务器 → 算 embedding → 存进 Turbopuffer 向量库 → 本地用 Merkle 树同步差异。Continue.dev 类似,但 embedding 在本地用 transformers.js 算,索引落盘到 ~/.continue/index。
Embedding 派的强项:语义模糊查询好,”哪里在处理用户限流”这种问得到答案。短板:精确的”谁调用了 validateToken“是不可靠的,因为相似度排序会把名字相近但无关的函数排上来。
CodeGraph 反过来:结构化关系是精确的,模糊语义靠不上。问”日志系统在哪里实现”,CodeGraph 不一定胜过 embedding;但问”Session.request() 一路调到 URLSession.dataTask() 经过哪 9 个函数”——README 里那个 Alamofire 基准测试给出了答案,一次 trace 调用,depth 3,完整 9 跳链路。这种 call chain 是 embedding 路线几乎不可能做到的。
4.3 对比Sourcegraph Cody:精确性维度类似,部署模型相反
Cody 用 SCIP(Sourcegraph Code Intelligence Protocol,LSIF 的后继协议)——通过 scip-typescript、scip-java、rust-analyzer 等真正的编译器/类型检查器精确抽取符号。这比 tree-sitter 更准(懂泛型实例化、懂 import resolution 的所有边角),代价是每种语言都要一个专门的 indexer,要能编译。
部署上:Cody 中心化(数据上传 Sourcegraph 实例),CodeGraph 本地化(.codegraph/codegraph.db 文件不离开你的机器)。对个人开发者和不愿外传源码的团队,CodeGraph 的”无 API key、无外部服务”是硬性优势。对需要跨百仓库导航的大型组织,Sourcegraph 仍然是天花板。
4.4 对比Potpie.ai:同样图派,不同重量级
Potpie 也是知识图谱路线,但走的是重型路线:用 Neo4j 存属性图、FastAPI 服务层、Celery 任务队列、CrewAI 编排的 RAG agent。根据 http://itbrief.asia 的融资公告:
"Potpie 的目标客户是 百万行代码量级起步的大型企业……目前 Potpie 已经在为财富 500 强企业、以及医疗健康、保险科技等受监管行业的上市公司提供服务。"
Potpie 于 2026 年 3 月完成 220 万美元 Pre-Seed 融资,由 Emergent Ventures 领投,All In Capital、DeVC 和 Point One Capital 跟投。
CodeGraph 是轻型路线:一个 npm 包、一个 SQLite 文件、一个 MCP server,目标用户是”用 Claude Code 在自己项目里写代码的个人开发者和小团队”。Potpie 的图比 CodeGraph 更”语义化”——每个函数都有 LLM 生成的 docstring 写进图。CodeGraph 坚持”extraction 是确定性的,源自 AST,不被 LLM 总结“(CLAUDE.md 原话)——这让索引完全可复现、无 LLM 调用成本,但也意味着图本身不携带语义注解。
4.5 对比Augment Code:商业 Context Engine
Augment 把”context engine”做成卖点,但其定位明确不是”百万 token 暴力填充派”——其官方博客标题就是 “Context Window Wars: 200k vs 1M+ Token Strategies”,主打 200K 上下文 + 智能检索,索引能力上限按官方页面是 ”up to 500,000 files simultaneously across dozens of repositories”。Augment 的 MCP server 也可以接到 Claude Code/Cursor 上用。
对企业,Augment 的合规(SOC 2 Type II、ISO/IEC 42001)、单租户、BYOK 是 CodeGraph 没有的。对独立开发者,Augment 的远端架构和按 credits 计费是负担——Augment 官方文档 docs.augmentcode.com/context-services/mcp/overview 明确说:
"Context Engine MCP 按查询计费,每次查询消耗的 credits 数量不同——具体取决于底层成本和检索量。根据我们的实际数据,平均每次查询消耗 40–70 credits。"
4.6 对比repomix / code2prompt / yek:完全不同的哲学
这一派是”把整个 repo 拼成一个大文件“。在 Gemini 2.5 Pro 这种百万 token 模型上塞得下时管用,对大型 repo 几乎瞬间失效——Next.js repo 单纯文本就 5600 万 tokens。yek 用 git history 做优先级排序部分缓解了这个问题。
哲学差异:他们假设模型能在长上下文里自己挑相关内容;CodeGraph 假设 agent 应该被引导只看相关子图。 后者在 Claude Opus 4.7 这种 1M 上下文模型上仍然有意义,因为”应付得了”和”花得起钱”是两回事。
4.7 对比CodeQL / Glean:不同层次的目标
CodeQL(GitHub)和 Glean(Meta 开源)也都把代码变成可查询的事实库,但目标是精确语义分析——CodeQL 用 QL 语言查数据流污点分析、Glean 用 Datalog 风格的 Angle 查 facts。表达力远超 CodeGraph,但学习曲线陡、面向静态分析工程师而非 LLM agent。CodeGraph 是把”图查询”包装成 agent 友好的高层意图(”找谁调用了 X”),不是给人写复杂查询用的。
五、上手:三条命令
# 一次性安装(自动检测并配置已安装的 agent)
curl -fsSL https://raw.githubusercontent.com/colbymchenry/codegraph/main/install.sh | sh
# 或:npx @colbymchenry/codegraph
# 在项目里初始化 + 索引
cd your-project
codegraph init -i
# 启动 MCP 服务(agent 会自己拉起来,通常不用手动跑)
codegraph serve --mcpCLI 还包括 codegraph index、codegraph sync(增量更新)、codegraph query <name>、codegraph context <task>、codegraph impact <symbol> 和一个有趣的 codegraph affected——基于图反向追踪”我改了 src/auth.ts,哪些测试文件会被影响”,可以塞进 CI 只跑相关测试:
git diff --name-only HEAD | codegraph affected --stdin --quiet | xargs vitest run作为库使用(TypeScript):
import CodeGraph from '@colbymchenry/codegraph';
const cg = await CodeGraph.init('/path/to/project');
await cg.indexAll();
const results = cg.searchNodes('UserService');
const callers = cg.getCallers(results[0].node.id);
const context = await cg.buildContext('fix login bug',
{ maxNodes: 20, includeCode: true, format: 'markdown' });
const impact = cg.getImpactRadius(results[0].node.id, 2);
cg.watch(); // 自动同步六、实测结果(作者基准)
README 里有两组数字——这里我把它们都列出来,因为方法论不同:
早期 README:Claude Opus 4.6,单次运行,每个 repo 一个 Explore agent:
- VS Code (TS, 4002 文件, 59377 节点) → 3 calls 17s vs 52 calls 97s(94% 更少 · 82% 更快)
- Swift Compiler (25,874 文件, 272,898 节点) → 6 calls 35s vs 37 calls 128s,索引耗时 < 4 分钟
- 平均 92% fewer tool calls, 71% faster
v0.9.4 (2026-05-24) 重新验证:Claude Opus 4.7、claude -p headless、--strict-mcp-config、每组 4 次取中位数——更严谨的方法论给出更保守的数字:
平均 35% 更便宜 · 57% fewer tokens · 46% faster · 71% fewer tool calls(横跨 7 个真实开源项目)
第二组数字更可信,作者自己也写明大型 repo 收益更明显,像 Gin(约 150 个文件)这种小项目”native search 已经够便宜,差距被压缩”。
七、结论与建议
以下情况考虑用 CodeGraph :
- 主力 agent 是 Claude Code / Codex CLI / Cursor agent 模式,且经常在 1 万文件以上的项目里工作
- 不能或不想把源码上传到 SaaS(合规、隐私、纯偏好均算)
- 看重”调用链、影响分析、impact radius”这类精确结构化问题胜过”语义模糊匹配”
- 想要零配置——
codegraph init一条命令就完事,没有 embedding 模型选型、没有向量库、没有 API key
以下情况不建议用 CodeGraph:
- 需要跨多仓推理——CodeGraph 是单仓本地索引,不做 cross-repo
- 主要场景是”我不记得这段逻辑在哪、按语义找一下”——纯 embedding 工具(Cursor 内建、Continue)在这类查询上更稳
- 是企业,需要 SOC 2 / 单租户 / BYOK / 跨百仓——Sourcegraph、Augment、Potpie 是更合适的天花板
- 需要真正的类型推断和泛型解析做安全分析——SCIP/CodeQL 路线更准
一个值得借鉴的工程教训
CodeGraph 的演化过程本身比代码更有启发——作者最初设计了向量搜索 + embedding 模块(IMPLEMENTATION_PLAN.md 里有完整 384 维 sqlite-vss 设计),但在生产实测后删掉了整个模块。理由很简单:对 agent 的探索性查询,”按名字 + 结构边 + FTS5”已经把 95% 的问题解决了,引入 embedding 增加的延迟和不确定性反而把好不容易省下的 tool call 又花了回去。
这给所有 AI agent 工程师一个提醒:code RAG ≠ document RAG。代码有 AST,有调用图,有静态可推导的关系——把这些先吃掉,再考虑用 embedding 补语义层。CodeGraph 选了相反的优先级,并且效果不错。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)