
工业级大模型学习之路022:LangChain零基础入门教程(第五篇):向量存储与检索系统
·
一、向量检索是 RAG 系统的心脏
1.1 为什么需要向量数据库?
传统关键词检索的局限性:
- 只能匹配字面相同的词,无法理解语义相似性
- 无法处理同义词、近义词、多义词
- 对长文本和复杂查询的效果差
向量检索的核心优势:
- 语义理解:将文本转换为高维向量,相似语义的文本在向量空间中距离更近
- 模糊匹配:支持同义词、近义词、上下文相关的匹配
- 高效检索:支持百万级甚至亿级向量的毫秒级相似性搜索
1.2 向量检索的完整流程
文本分块 → 嵌入模型 → 向量生成 → 向量数据库存储
用户查询 → 查询向量生成 → 相似性搜索 → 返回Top-K相关分块
1.3 核心概念详解
1.3.1 嵌入模型(Embedding Model)
- 作用:将非结构化的文本转换为固定长度的稠密向量
- 核心指标:维度(通常为 768/1024/1536)、语义准确性、速度、支持的语言
- 主流中文嵌入模型:BGE 系列、M3E 系列、text2vec 系列
1.3.2 相似度计算方法
| 方法 | 原理 | 适用场景 |
|---|---|---|
| 余弦相似度(Cosine Similarity) | 计算两个向量之间的夹角余弦值 | 文本语义相似度(最常用) |
| 欧氏距离(Euclidean Distance) | 计算两个向量之间的直线距离 | 数值型数据、聚类 |
| 点积(Dot Product) | 计算两个向量的点积 | 归一化后的向量,速度最快 |
1.3.3 向量索引类型
- Flat 索引:暴力搜索,精度 100%,速度慢,适合小数据集(<10 万条)
- IVF 索引:倒排文件索引,速度快,精度略有损失,适合中等数据集(10 万 - 1000 万条)
- HNSW 索引:层次化导航小世界图,速度最快,精度高,内存占用大,适合大规模数据集(>1000 万条)
1.4 主流向量数据库对比
| 数据库 | 部署方式 | 开源 | 性能 | 适用场景 |
|---|---|---|---|---|
| Chroma | 嵌入式 | ✅ | 一般 | 开发、原型、小项目 |
| FAISS | 嵌入式 | ✅ | 优秀 | 大规模数据、高性能需求 |
| Pinecone | 云服务 | ❌ | 优秀 | 生产环境、无需运维 |
| Milvus | 分布式 | ✅ | 优秀 | 企业级、大规模生产环境 |
| Qdrant | 分布式 / 嵌入式 | ✅ | 优秀 | 生产环境、功能丰富 |
二、LangChain 向量存储核心 API 详解
2.1 嵌入模型接口 Embeddings
所有嵌入模型都实现了统一的Embeddings接口:
embed_documents(texts: list[str]):批量嵌入多个文档embed_query(text: str):嵌入单个查询文本
2.1.1 OpenAI 兼容嵌入模型(豆包)
from langchain_openai import OpenAIEmbeddings
# 豆包嵌入模型(完全兼容OpenAI接口)
embeddings = OpenAIEmbeddings(
api_key="你的豆包API密钥",
base_url="https://ark.cn-beijing.volces.com/api/v3",
model="bge-large-zh-v1.5" # 中文效果最好的开源嵌入模型
)
# 嵌入查询
query_vector = embeddings.embed_query("什么是RAG技术?")
print(f"向量维度:{len(query_vector)}")
# 批量嵌入文档
documents = ["RAG是检索增强生成技术", "大语言模型可以生成文本"]
doc_vectors = embeddings.embed_documents(documents)
print(f"嵌入了{len(doc_vectors)}个文档")2.1.2 本地嵌入模型(HuggingFace)
from langchain_huggingface import HuggingFaceEmbeddings
# 本地BGE中文嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5",
model_kwargs={"device": "cpu"}, # 有GPU可以改为"cuda"
encode_kwargs={"normalize_embeddings": True}
)2.2 Chroma 向量数据库(入门首选)
轻量级嵌入式向量数据库,无需额外部署,适合开发和原型。
基本用法
from langchain_chroma import Chroma
from langchain_core.documents import Document
# 初始化向量数据库
vector_store = Chroma(
collection_name="rag_collection",
embedding_function=embeddings,
persist_directory="./data/chroma_db" # 持久化存储路径
)
# 添加单个文档
doc = Document(
page_content="RAG技术于2020年由Facebook提出",
metadata={"source": "test.md", "page": 1}
)
vector_store.add_documents([doc])
# 批量添加文档
documents = [
Document(page_content="RAG可以解决大模型的幻觉问题", metadata={"source": "test.md", "page": 2}),
Document(page_content="向量数据库用于存储文本嵌入向量", metadata={"source": "test.md", "page": 3})
]
vector_store.add_documents(documents)
# 相似性搜索
results = vector_store.similarity_search("RAG解决了什么问题?", k=2)
for doc in results:
print(f"内容:{doc.page_content}")
print(f"来源:{doc.metadata['source']}")
# 带分数的相似性搜索(分数越小越相似)
results_with_scores = vector_store.similarity_search_with_score("什么是向量数据库?", k=2)
for doc, score in results_with_scores:
print(f"内容:{doc.page_content},相似度分数:{score:.4f}")元数据过滤
# 只搜索来自test.md第1页的文档
results = vector_store.similarity_search(
"RAG是什么时候提出的?",
k=2,
filter={"source": "test.md", "page": 1}
)持久化与加载
# 数据会自动持久化到persist_directory
# 重新加载数据库
vector_store = Chroma(
collection_name="rag_collection",
embedding_function=embeddings,
persist_directory="./data/chroma_db"
)
# 删除集合
Chroma.delete_collection("rag_collection", persist_directory="./data/chroma_db")2.3 FAISS 向量数据库(高性能首选)
Facebook 开发的高性能向量数据库,适合大规模数据。
from langchain_community.vectorstores import FAISS
# 初始化FAISS
vector_store = FAISS.from_documents(documents, embeddings)
# 持久化
vector_store.save_local("./data/faiss_db")
# 加载
vector_store = FAISS.load_local(
"./data/faiss_db",
embeddings,
allow_dangerous_deserialization=True
)
# 相似性搜索
results = vector_store.similarity_search("什么是RAG?", k=2)三、工业级向量检索最佳实践
3.1 嵌入模型选择指南
| 场景 | 推荐模型 | 维度 | 特点 |
|---|---|---|---|
| 中文通用场景 | BAAI/bge-large-zh-v1.5 | 1024 | 综合效果最好 |
| 中文轻量场景 | BAAI/bge-small-zh-v1.5 | 512 | 速度快,效果不错 |
| 多语言场景 | BAAI/bge-m3 | 1024 | 支持 100 + 语言 |
| 远程 API | 豆包 bge-large-zh-v1.5 | 1024 | 无需本地部署,速度快 |
3.2 检索参数调优
- top_k:返回的结果数量,通常为 3-10
- 太小:丢失相关信息
- 太大:引入太多噪声,增加大模型处理成本
- 相似度阈值:过滤掉相似度低于阈值的结果
- 余弦相似度:通常设置为 0.7-0.8
- 欧氏距离:通常设置为 0.3-0.5
- 批量大小:批量嵌入时的批次大小,通常为 32-128
3.3 检索结果后处理
- 去重:去除重复的文档片段
- 过滤:根据元数据过滤不需要的结果
- 排序:根据相似度分数和元数据进行二次排序
- 截断:如果结果太长,截断到合适的长度
3.4 向量数据库性能优化
- 批量导入:尽量使用批量导入而不是单个添加
- 索引优化:根据数据量选择合适的索引类型
- 硬件加速:使用 GPU 进行嵌入和检索
- 分片存储:大规模数据可以分片存储在多个节点上
四、项目整合:实现工业级 RAG 检索系统
4.1 第一步:新增依赖
在requirements.txt中添加向量存储相关依赖:
# 向量存储依赖
langchain-chroma
langchain-community
faiss-cpu # Windows/Linux CPU版本
# faiss-gpu # 有GPU可以使用这个版本
sentence-transformers # 本地嵌入模型所需
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple
4.2 第二步:新增配置项
在config/settings.py中添加向量存储配置:
# ====================== 向量存储配置 ======================
vector_store_type: str = Field(default="chroma", description="向量数据库类型:chroma/faiss")
vector_store_path: Path = Field(default=Path("./data/vector_db"), description="向量数据库存储路径")
vector_collection_name: str = Field(default="rag_collection", description="向量集合名称")
# 嵌入模型配置
embedding_provider: str = Field(default="doubao", description="嵌入模型提供商:doubao/huggingface")
embedding_model_name: str = Field(default="bge-large-zh-v1.5", description="嵌入模型名称")
embedding_device: str = Field(default="cpu", description="嵌入模型运行设备:cpu/cuda")
# 检索配置
retrieval_top_k: int = Field(default=3, description="检索返回的文档数量")
retrieval_similarity_threshold: float = Field(default=0.7, description="相似度阈值")4.3 第三步:实现向量存储工厂
在core/目录下创建vector_store_factory.py:
from typing import List, Optional
from langchain_core.documents import Document
from langchain_core.vectorstores import VectorStore
from core.vector_store_factory import VectorStoreFactory
from core.document_processor import DocumentProcessor
from config.settings import settings
from utils.logger import logger
from utils.exceptions import RetrievalError
class RAGRetriever:
"""RAG检索器,封装文档处理和向量检索"""
def __init__(
self,
vector_store: Optional[VectorStore] = None,
document_processor: Optional[DocumentProcessor] = None
):
self.vector_store = vector_store or VectorStoreFactory.get_vector_store()
self.document_processor = document_processor or DocumentProcessor()
logger.info("✅ RAG检索器初始化完成")
def add_document(self, file_path: str) -> int:
"""
添加单个文档到向量数据库
:param file_path: 文档路径
:return: 添加的分块数量
"""
try:
logger.info(f"添加文档到知识库:{file_path}")
# 处理文档
chunks = self.document_processor.process_file(file_path)
if not chunks:
logger.warning(f"文档{file_path}没有有效内容")
return 0
# 添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 文档添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"添加文档失败:{str(e)}") from e
def add_directory(self, dir_path: str, recursive: bool = False) -> int:
"""
批量添加目录下的所有文档
:param dir_path: 目录路径
:param recursive: 是否递归处理子目录
:return: 添加的总分块数量
"""
try:
logger.info(f"批量添加目录到知识库:{dir_path}")
chunks = self.document_processor.process_directory(dir_path, recursive)
if not chunks:
logger.warning(f"目录{dir_path}没有有效文档")
return 0
# 批量添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 批量添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"批量添加文档失败:{str(e)}") from e
def retrieve(
self,
query: str,
top_k: int = None,
similarity_threshold: float = None,
filter: dict = None
) -> List[Document]:
"""
检索相关文档
:param query: 用户查询
:param top_k: 返回结果数量,默认使用settings配置
:param similarity_threshold: 相似度阈值,默认使用settings配置
:param filter: 元数据过滤条件
:return: 相关文档列表
"""
try:
top_k = top_k or settings.retrieval_top_k
similarity_threshold = similarity_threshold or settings.retrieval_similarity_threshold
logger.debug(f"检索查询:{query},top_k={top_k},阈值={similarity_threshold}")
# 带分数的相似性搜索
results_with_scores = self.vector_store.similarity_search_with_score(
query=query,
k=top_k,
filter=filter
)
# 过滤相似度低于阈值的结果
filtered_results = []
for doc, score in results_with_scores:
# Chroma返回的是余弦距离(0-2),0表示完全相同;转换为相似度分数(0-1)
# 余弦距离转相似度:similarity = 1 - (distance / 2)
# 这适用于 ChromaDB 默认使用的余弦相似度
similarity = max(0.0, 1.0 - score / 2.0)
doc.metadata["similarity_score"] = similarity
logger.debug(f"文档相似度:{similarity:.4f},阈值:{similarity_threshold}")
if similarity >= similarity_threshold:
filtered_results.append(doc)
logger.debug(f"检索完成,找到{len(filtered_results)}个相关文档")
return filtered_results
except Exception as e:
raise RetrievalError(f"检索失败:{str(e)}") from e
def get_document_count(self) -> int:
"""获取向量数据库中的文档数量"""
try:
return self.vector_store._collection.count()
except:
# FAISS不支持直接获取数量,返回-1
return -1
def clear_knowledge_base(self):
"""清空知识库"""
try:
VectorStoreFactory.delete_collection()
# 重新初始化向量存储
self.vector_store = VectorStoreFactory.get_vector_store()
logger.info("✅ 知识库已清空")
except Exception as e:
raise RetrievalError(f"清空知识库失败:{str(e)}") from e4.4 第四步:实现 RAG 检索器
在core/目录下创建rag_retriever.py:
from typing import List, Optional
from langchain_core.documents import Document
from langchain_core.vectorstores import VectorStore
from core.vector_store_factory import VectorStoreFactory
from core.document_processor import DocumentProcessor
from config.settings import settings
from utils.logger import logger
from utils.exceptions import RetrievalError
class RAGRetriever:
"""RAG检索器,封装文档处理和向量检索"""
def __init__(
self,
vector_store: Optional[VectorStore] = None,
document_processor: Optional[DocumentProcessor] = None
):
self.vector_store = vector_store or VectorStoreFactory.get_vector_store()
self.document_processor = document_processor or DocumentProcessor()
logger.info("✅ RAG检索器初始化完成")
def add_document(self, file_path: str) -> int:
"""
添加单个文档到向量数据库
:param file_path: 文档路径
:return: 添加的分块数量
"""
try:
logger.info(f"添加文档到知识库:{file_path}")
# 处理文档
chunks = self.document_processor.process_file(file_path)
if not chunks:
logger.warning(f"文档{file_path}没有有效内容")
return 0
# 添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 文档添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"添加文档失败:{str(e)}") from e
def add_directory(self, dir_path: str, recursive: bool = False) -> int:
"""
批量添加目录下的所有文档
:param dir_path: 目录路径
:param recursive: 是否递归处理子目录
:return: 添加的总分块数量
"""
try:
logger.info(f"批量添加目录到知识库:{dir_path}")
chunks = self.document_processor.process_directory(dir_path, recursive)
if not chunks:
logger.warning(f"目录{dir_path}没有有效文档")
return 0
# 批量添加到向量数据库
self.vector_store.add_documents(chunks)
logger.info(f"✅ 批量添加成功,共添加{len(chunks)}个分块")
# 如果是FAISS,保存索引
if settings.vector_store_type == "faiss":
VectorStoreFactory.save_faiss_index(self.vector_store)
return len(chunks)
except Exception as e:
raise RetrievalError(f"批量添加文档失败:{str(e)}") from e
def retrieve(
self,
query: str,
top_k: int = None,
similarity_threshold: float = None,
filter: dict = None
) -> List[Document]:
"""
检索相关文档
:param query: 用户查询
:param top_k: 返回结果数量,默认使用settings配置
:param similarity_threshold: 相似度阈值,默认使用settings配置
:param filter: 元数据过滤条件
:return: 相关文档列表
"""
try:
top_k = top_k or settings.retrieval_top_k
similarity_threshold = similarity_threshold or settings.retrieval_similarity_threshold
logger.debug(f"检索查询:{query},top_k={top_k},阈值={similarity_threshold}")
# 带分数的相似性搜索
results_with_scores = self.vector_store.similarity_search_with_score(
query=query,
k=top_k,
filter=filter
)
# 过滤相似度低于阈值的结果
filtered_results = []
for doc, score in results_with_scores:
# Chroma返回的是L2距离,越小越相似;转换为相似度分数(0-1)
similarity = 1.0 / (1.0 + score)
if similarity >= similarity_threshold:
doc.metadata["similarity_score"] = similarity
filtered_results.append(doc)
logger.debug(f"检索完成,找到{len(filtered_results)}个相关文档")
return filtered_results
except Exception as e:
raise RetrievalError(f"检索失败:{str(e)}") from e
def get_document_count(self) -> int:
"""获取向量数据库中的文档数量"""
try:
return self.vector_store._collection.count()
except:
# FAISS不支持直接获取数量,返回-1
return -1
def clear_knowledge_base(self):
"""清空知识库"""
try:
VectorStoreFactory.delete_collection()
# 重新初始化向量存储
self.vector_store = VectorStoreFactory.get_vector_store()
logger.info("✅ 知识库已清空")
except Exception as e:
raise RetrievalError(f"清空知识库失败:{str(e)}") from e4.5 第五步:实现完整 RAG 问答服务
在core/目录下创建rag_service.py:
from typing import Iterator, AsyncIterator
from core.rag_retriever import RAGRetriever
from core.prompt_service import PromptService
from config.settings import settings
from utils.logger import logger
class RAGService:
"""完整的RAG问答服务"""
def __init__(self):
self.retriever = RAGRetriever()
logger.info("✅ RAG问答服务初始化完成")
def query(
self,
question: str,
top_k: int = None,
similarity_threshold: float = None,
use_anti_hallucination: bool = True
) -> str:
"""
同步问答
:param question: 用户问题
:param top_k: 检索结果数量
:param similarity_threshold: 相似度阈值
:param use_anti_hallucination: 是否使用反幻觉提示模板
:return: 生成的回答
"""
try:
logger.info(f"用户问题:{question}")
# 1. 检索相关文档
docs = self.retriever.retrieve(question, top_k, similarity_threshold)
if not docs:
return "抱歉,知识库中没有找到相关信息,无法回答您的问题。"
# 2. 构建上下文
context = "\n\n".join([f"[{i+1}] {doc.page_content}" for i, doc in enumerate(docs)])
logger.debug(f"检索到的上下文:{context[:500]}...")
# 3. 选择提示模板
template_version = "v2.0" if use_anti_hallucination else "v1.0"
# 4. 生成回答
answer = PromptService.generate(
template_name="rag_answer",
version=template_version,
inputs={
"context": context,
"question": question
}
)
logger.info(f"生成回答完成:{answer[:200]}...")
return answer
except Exception as e:
logger.error(f"问答失败:{str(e)}", exc_info=True)
return "抱歉,回答生成时发生错误,请稍后重试。"
def stream_query(
self,
question: str,
top_k: int = None,
similarity_threshold: float = None,
use_anti_hallucination: bool = True
) -> Iterator[str]:
"""流式问答"""
try:
logger.info(f"用户流式问题:{question}")
# 1. 检索相关文档
docs = self.retriever.retrieve(question, top_k, similarity_threshold)
if not docs:
yield "抱歉,知识库中没有找到相关信息,无法回答您的问题。"
return
# 2. 构建上下文
context = "\n\n".join([f"[{i+1}] {doc.page_content}" for i, doc in enumerate(docs)])
# 3. 选择提示模板
template_version = "v2.0" if use_anti_hallucination else "v1.0"
# 4. 流式生成回答
yield from PromptService.stream_generate(
template_name="rag_answer",
version=template_version,
inputs={
"context": context,
"question": question
}
)
except Exception as e:
logger.error(f"流式问答失败:{str(e)}", exc_info=True)
yield "抱歉,回答生成时发生错误,请稍后重试。"4.6 第六步:更新项目入口 main.py
from dotenv import load_dotenv
load_dotenv()
from core.rag_service import RAGService
import os
def test_rag_system():
"""测试完整RAG系统"""
print("🚀 第4天:向量存储与检索系统测试\n")
# 1. 初始化RAG服务
rag = RAGService()
# 2. 创建测试文档
os.makedirs("data", exist_ok=True)
test_text = """
# RAG技术详解
## 什么是RAG?
RAG(检索增强生成)是一种将外部知识库检索与大模型生成相结合的技术。
它于2020年由Facebook AI研究院提出,旨在解决大模型的知识过时和幻觉问题。
## RAG的工作原理
RAG系统的工作流程分为三个核心步骤:
1. **文档处理**:将原始文档切割成小块,转换为向量存储到向量数据库
2. **检索**:根据用户查询,从向量数据库中检索最相关的文档片段
3. **生成**:将检索到的文档片段和用户查询一起喂给大模型,生成回答
## RAG的核心优势
- ✅ **知识实时更新**:不需要重新训练模型,只需更新知识库
- ✅ **减少幻觉**:回答完全基于真实的文档内容
- ✅ **可解释性强**:可以追溯回答的具体来源
- ✅ **成本低廉**:比微调大模型便宜90%以上
"""
with open("data/rag_guide.md", "w", encoding="utf-8") as f:
f.write(test_text)
# 3. 添加文档到知识库
print("=== 添加文档到知识库 ===")
chunk_count = rag.retriever.add_document("data/rag_guide.md")
print(f"✅ 添加了{chunk_count}个分块到知识库")
print(f"知识库总文档数:{rag.retriever.get_document_count()}\n")
# 4. 测试问答
print("=== 测试RAG问答 ===")
questions = [
"RAG技术是什么时候提出的?",
"RAG的工作流程分为哪几个步骤?",
"RAG有哪些核心优势?",
"大模型的幻觉问题是什么?"
]
for i, question in enumerate(questions):
print(f"\n问题{i+1}:{question}")
answer = rag.query(question)
print(f"回答:{answer}")
# 5. 测试流式问答
print("\n" + "="*60)
print("=== 测试流式问答 ===")
question = "用自己的话解释什么是RAG技术"
print(f"问题:{question}")
print("回答:", end="", flush=True)
for chunk in rag.stream_query(question):
print(chunk, end="", flush=True)
print("\n")
print("🎉 所有RAG系统测试通过!")
if __name__ == "__main__":
test_rag_system()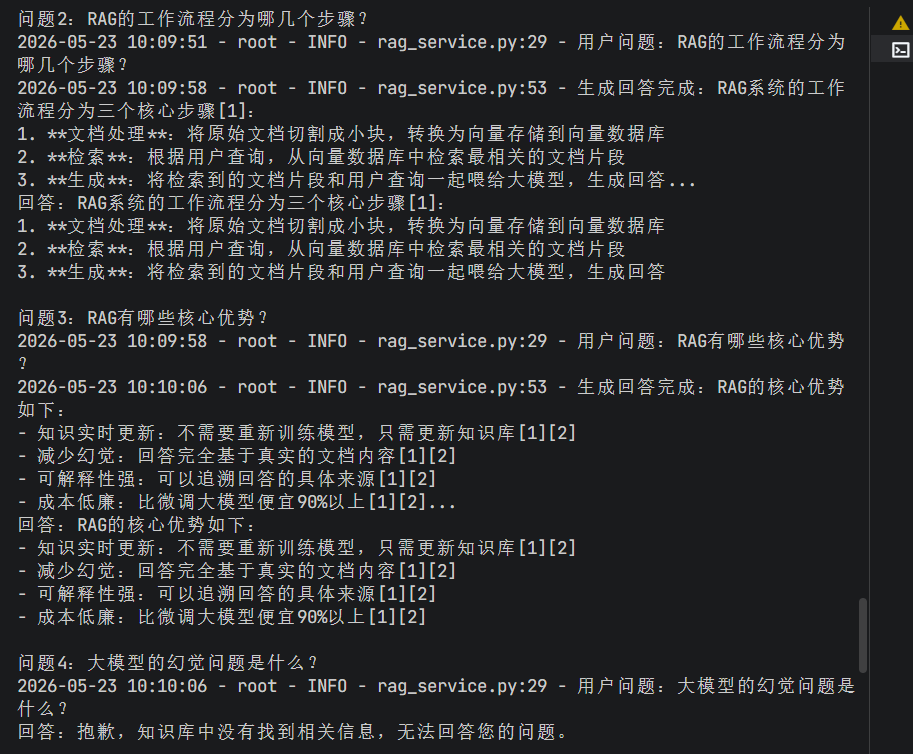

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 30
30 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)