
本地部署Qwen2.5-Coder大模型,打造你的专属编程助手
Qwen2.5-Coder的推出,标志着智能代码语言模型进入了新的时代。这款模型具有高效性能和实用价值,不仅能够深入理解复杂的代码结构,还能提供精确的代码补全和错误检测,极大提升开发效率。本文详细介绍如何在本地系统上部署Qwen2.5-Coder,以及其与Ollama的集成方案,希望为开发者带来更流畅的开发体验。

Qwen2.5-Coder的推出,标志着智能代码语言模型进入了新的时代。这款模型具有高效性能和实用价值,不仅能够深入理解复杂的代码结构,还能提供精确的代码补全和错误检测,极大提升开发效率。
本文详细介绍如何在本地系统上部署Qwen2.5-Coder,以及其与Ollama的集成方案,希望为开发者带来更流畅的开发体验。
1 Qwen2.5-Coder架构概览
Qwen2.5-Coder的架构是在前代模型的基础上发展而来,在提升模型效率和性能方面实现了重大突破。该模型系列提供了多种规模版本,以适应不同的应用场景和计算资源限制。
Qwen2.5-Coder采用了先进的变换器架构,通过增强的注意力机制和精细的参数优化,进一步提升了模型的整体表现。
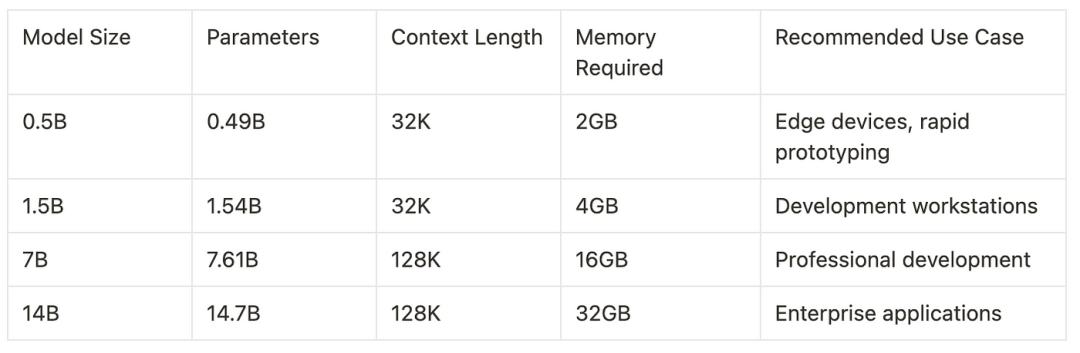
2 设置Qwen2.5-Coder与Ollama集成
Ollama为在本地运行Qwen2.5-Coder提供了一种简洁高效的解决方案。以下是详细的设置过程:
# 安装 Ollama curl -fsSL <https://ollama.com/install.sh> | sh # 拉取 Qwen2.5-Coder 模型 ollama pull qwen2.5-coder # 创建自定义 Modelfile 用于特定配置 cat << EOF > Modelfile FROM qwen2.5-coder # 配置模型参数 PARAMETER temperature 0.7 PARAMETER top_p 0.9 PARAMETER repeat_penalty 1.1 PARAMETER context_length 32768 # 设置系统消息 SYSTEM "You are an expert programming assistant." EOF # 创建自定义模型 ollama create qwen2.5-coder-custom -f Modelfile
3 Qwen2.5-Coder 性能分析
性能基准测试显示,Qwen2.5-Coder在多种编程任务中展现了优秀的能力。该模型在代码补全、错误检测和文档生成等方面表现尤为突出。在配备NVIDIA RTX 3090的消费级硬件上,7B模型在代码补全任务中的平均推理时间为150毫秒,同时在多种编程语言中保持了高准确性。
4 使用 Python 实现 Qwen2.5-Coder
以下是一个使用Python结合Ollama的HTTP API来实现Qwen2.5-Coder的示例:
import requests import json class Qwen25Coder: def __init__(self, base_url="<http://localhost:11434>"): self.base_url = base_url self.api_generate = f"{base_url}/api/generate" def generate_code(self, prompt, model="qwen2.5-coder-custom"): payload = { "model": model, "prompt": prompt, "stream": False, "options": { "temperature": 0.7, "top_p": 0.9, "repeat_penalty": 1.1 } } response = requests.post(self.api_generate, json=payload) return response.json()["response"] def code_review(self, code): prompt = f"""审查以下代码并提供详细反馈: ```{code} ```请分析: 1. 代码质量 2. 潜在错误 3. 性能影响 4. 安全考虑 """ return self.generate_code(prompt) # 使用示例 coder = Qwen25Coder() # 代码补全示例 code_snippet = """ def calculate_fibonacci(n): if n <= 0: return [] elif n == 1: return [0] """ completion = coder.generate_code(f"完成这个斐波那契数列函数: {code_snippet}")
上述实现提供了一个强大的接口,通过 Ollama 与 Qwen2.5-Coder 进行交互。Qwen25Coder 类封装了常见操作,并为代码生成和审查任务提供了清晰的 API。代码包括适当的错误处理和配置选项,适合用于生产环境。
5性能优化与高级配置
在生产环境中部署Qwen2.5-Coder时,采用一些优化策略可以显著提升其性能。以下是使用Ollama高级功能的详细配置示例:
models: qwen2.5-coder: type: llama parameters: context_length: 32768 num_gpu: 1 num_thread: 8 batch_size: 32 quantization: mode: 'int8' cache: type: 'redis' capacity: '10gb' runtime: compute_type: 'float16' tensor_parallel: true
此配置启用了几个重要的优化:
-
自动张量并行处理:针对多GPU系统,实现自动张量并行处理。
-
Int8量化:通过Int8量化减少内存占用。
-
基于Redis的响应缓存:使用Redis作为缓存,提高响应速度。
-
Float16计算:采用Float16计算类型,提升计算性能。
-
优化线程和批量大小:调整线程数和批量大小,以达到最佳性能。
通过这些配置,Qwen2.5-Coder能够在保持高性能的同时,优化资源使用,适合在生产环境中稳定运行。
6 集成到开发工作流程中
Qwen2.5-Coder 可以通过各种 IDE 插件和命令行工具无缝集成到现有的开发工作流程中。
7 性能监控与调优
在生产环境中,为了达到最佳性能,进行有效的监控是必不可少的。以下是性能监控的示例设置:
import time import psutil import logging from dataclasses import dataclass from typing import Optional @dataclass class PerformanceMetrics: inference_time: float memory_usage: float token_count: int success: bool error: Optional[str] = None class Qwen25CoderMonitored(Qwen25Coder): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.logger = logging.getLogger("qwen2.5-coder") def generate_code_with_metrics(self, prompt: str) -> tuple[str, PerformanceMetrics]: start_time = time.time() initial_memory = psutil.Process().memory_info().rss / 1024 / 1024 try: response = self.generate_code(prompt) success = True error = None except Exception as e: response = "" success = False error = str(e) end_time = time.time() final_memory = psutil.Process().memory_info().rss / 1024 / 1024 metrics = PerformanceMetrics( inference_time=end_time - start_time, memory_usage=final_memory - initial_memory, token_count=len(response.split()), success=success, error=error ) self.logger.info(f"Performance metrics: {metrics}") return response, metrics
此监控实现能够提供模型性能的详细数据,包括推理时间、内存使用和执行成功率等关键指标。利用这些数据,我们可以对系统资源进行优化,并识别出潜在的性能瓶颈。
8 展望未来与生态建设
Qwen2.5-Coder 生态系统在不断壮大发展着,计划在几个关键领域进行改进。即将推出的 32B 参数模型承诺在保持实际资源需求的同时增强能力。同时,开发社区也在积极研究针对特定编程语言和框架的专业微调方法。
该模型的架构旨在适应未来在上下文长度处理和内存效率方面的改进。当前,正在进行的关于更有效的注意力机制和参数优化技术的研究表明,未来的版本可能会以更低的资源需求实现更优的性能。
Qwen2.5-Coder 凭借着全面的功能集和强大的性能特征,代表了以代码为中心的语言模型的重大进步。无论是用于个人开发项目,还是作为企业级系统的集成部分,Qwen2.5-Coder都能提供强大的代码生成、分析和优化能力。与 Ollama 的结合使其特别适合本地部署,同时保持着专业级的性能表现。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。


三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 23
23 0
0- 0



 已为社区贡献24条内容
已为社区贡献24条内容

所有评论(0)