
Ollama的本地调用|豆包MarsCode AI刷题
最关键的点就是GGUF格式根本不需要llama.cpp,而手册里是bin格式,是需要的,现在已经过时了这个锅,我必须甩给gpt,他这一本正经的胡说八道,害我走了太多弯路了,我下次再也不这么肯定的问他了。
看完你将理解:
看官方文档的重要性
选择教程的重要性
理解c++处理大模型文件的格式
浅浅理解,在不同的环境下运行文件的逻辑
官方模型调用与部署
下载
1第一步下载ollama.exe
然后到ollama的指令那里,找想要使用的对应模型
www.ollama.com/library
没有魔法的需要去镜像(需自行探索
2先调到你要下载的模型,要根据自己电脑性能选择
然后cmd进入命令行输入指令
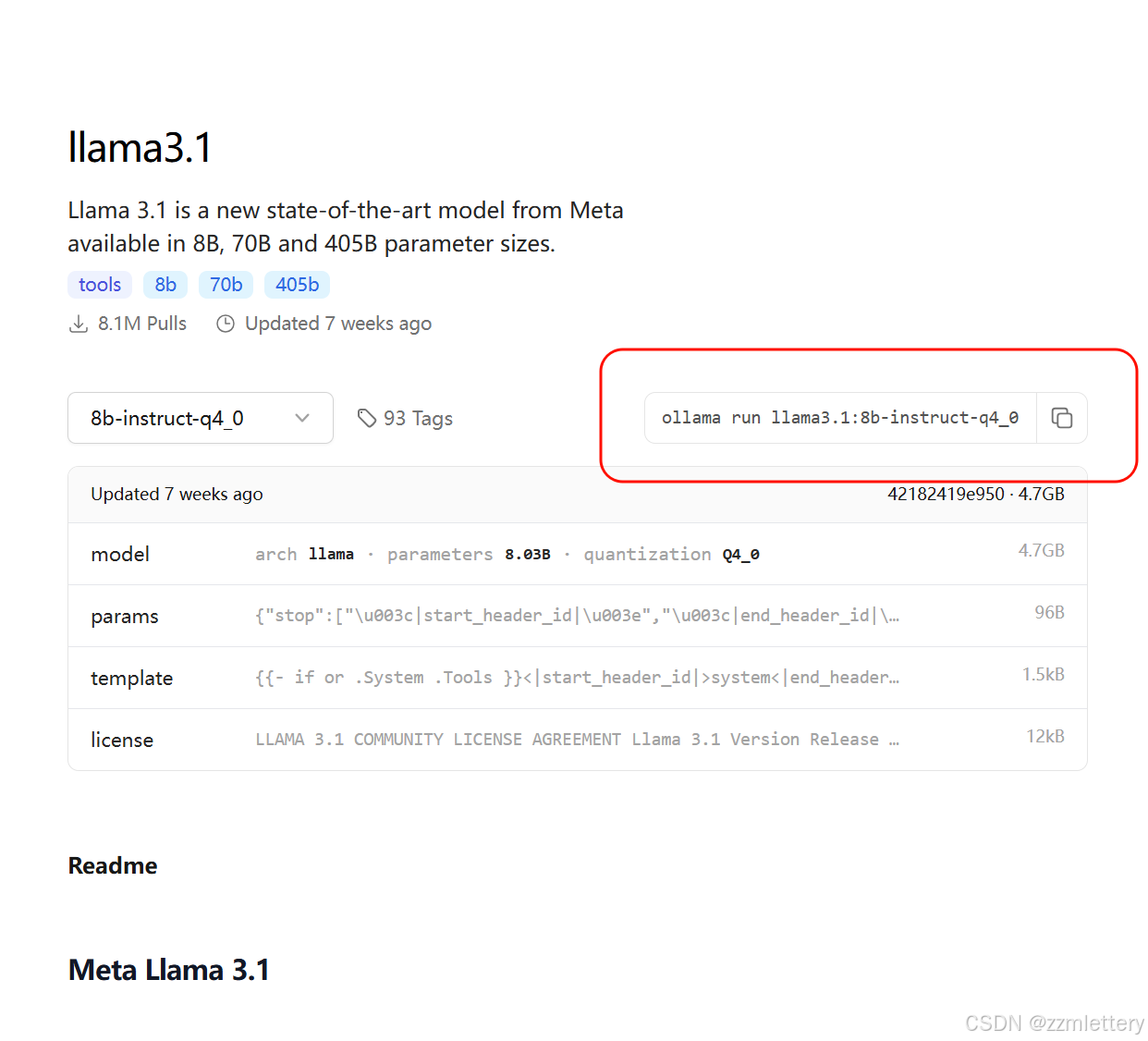
小心每天别输入不一样的指令,不然会重新下载

Error: max retries exceeded: unexpected EOF
怎么还报错了
部署
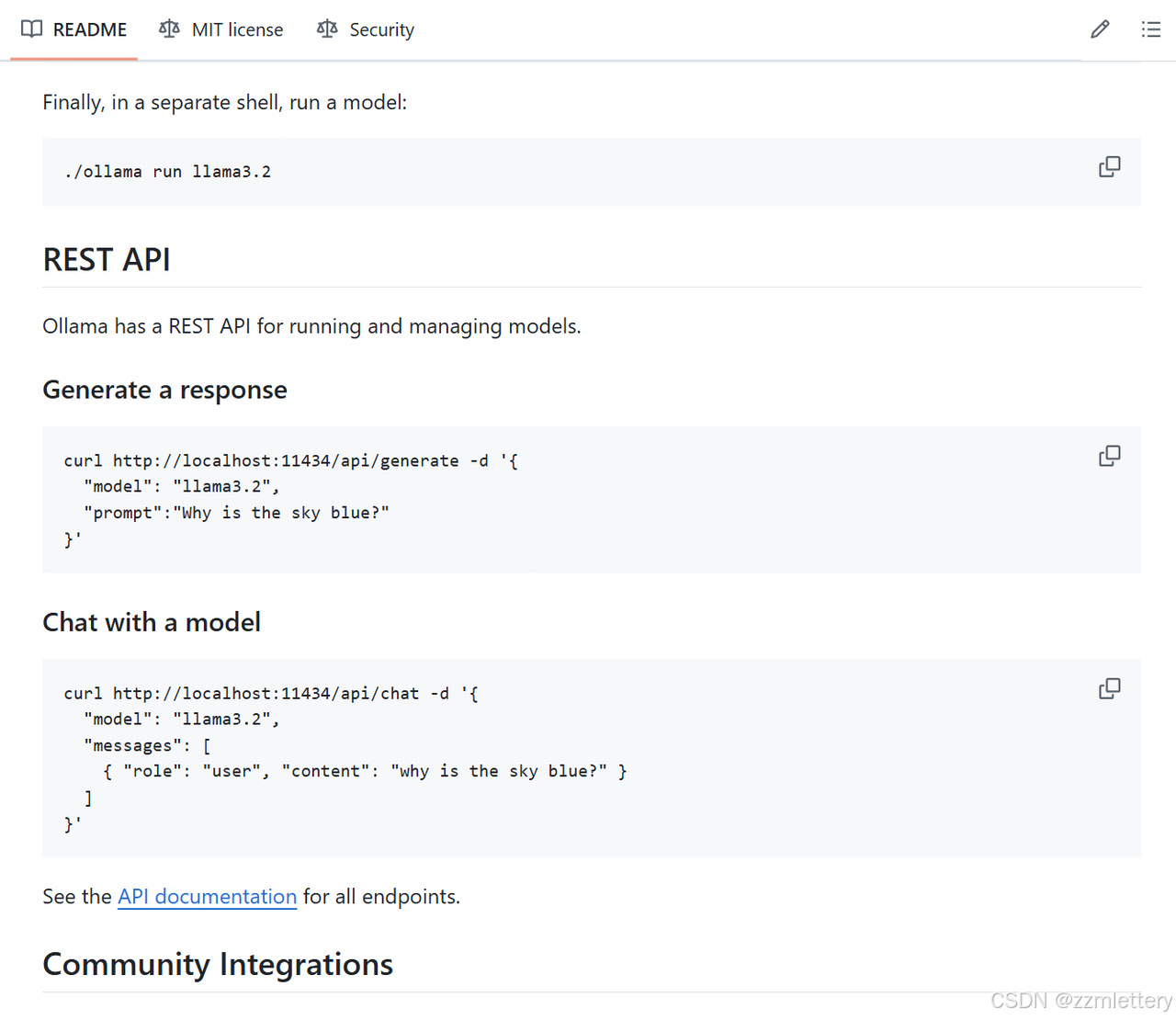
可以docker部署
用ollama官方的 docs.openwebui.com
也可以直接下载一个exechatboxai.app/zh
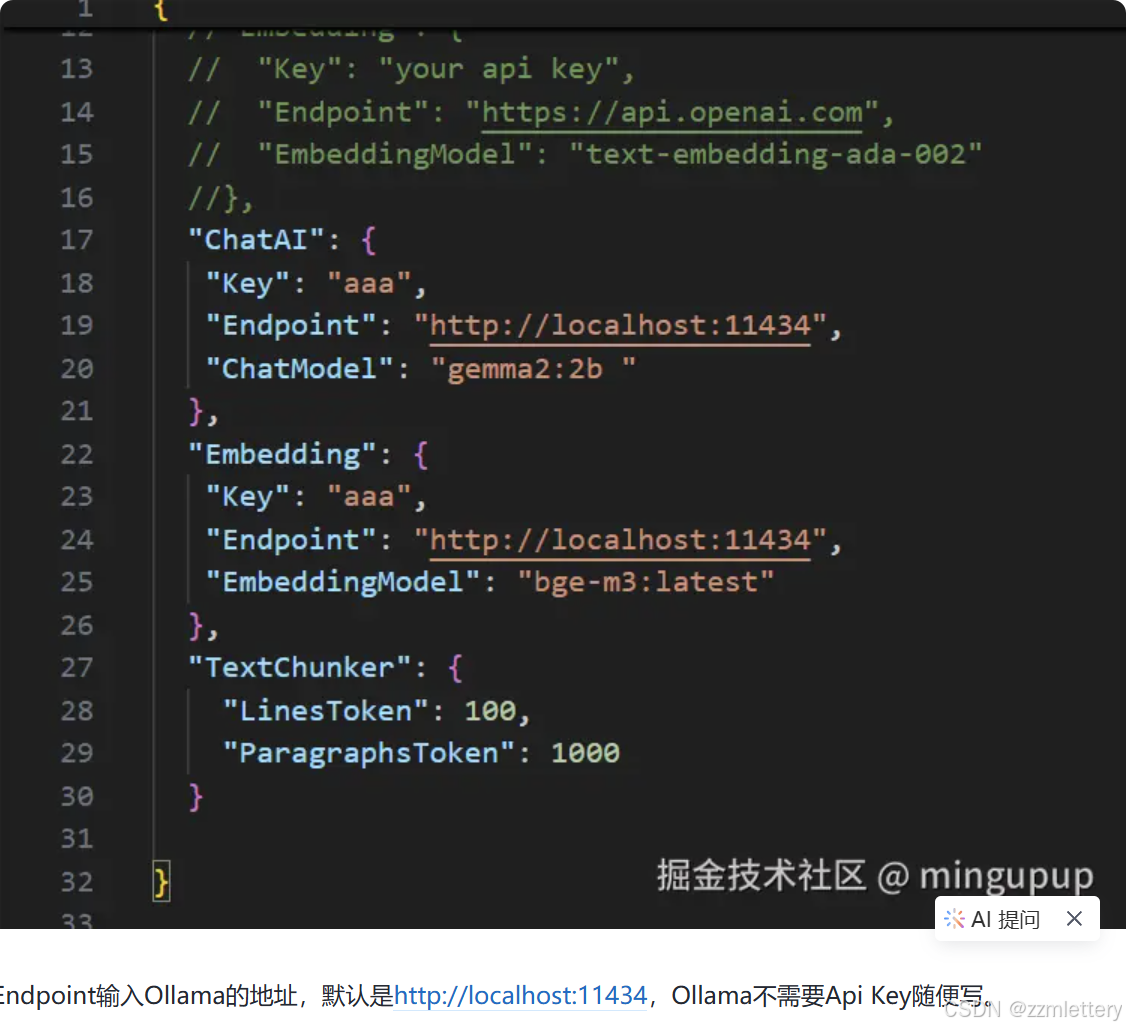
调用
Ollama的地址,默认是http://localhost:11434,Ollama不需要Api Key随便写或者不用写
我好像一个小丑,它通过本地调用的方式是直接本地接口,而不是API
我一直以为是和openai一样的,还是要好好看官方的文档,ollama可以去github看readme
让ai写一个通过接口调用的代码就行
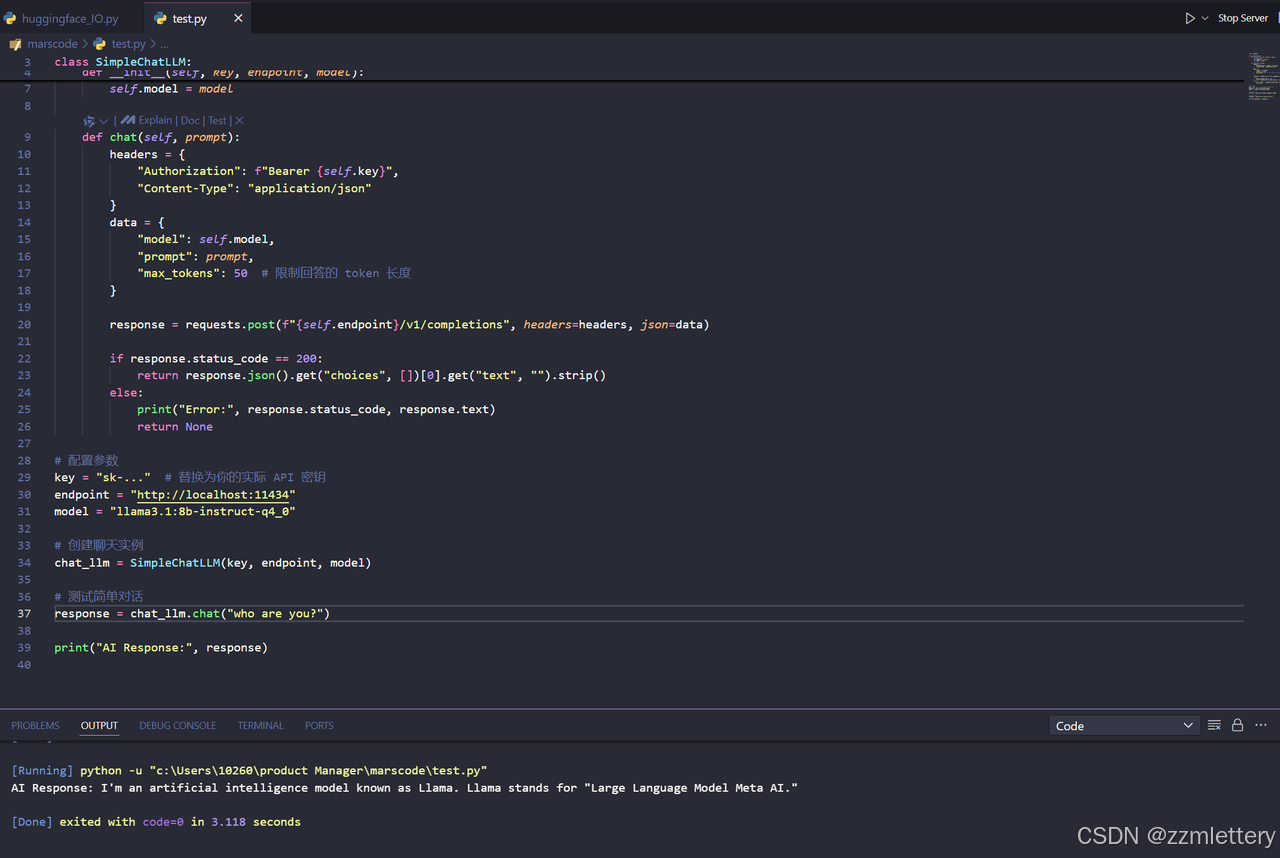
import requests
class SimpleChatLLM:
def __init__(self, key, endpoint, model):
self.key = key
self.endpoint = endpoint
self.model = model
def chat(self, prompt):
headers = {
"Authorization": f"Bearer {self.key}",
"Content-Type": "application/json"
}
data = {
"model": self.model,
"prompt": prompt,
"max_tokens": 50 # 限制回答的 token 长度
}
response = requests.post(f"{self.endpoint}/v1/completions", headers=headers, json=data)
if response.status_code == 200:
return response.json().get("choices", [])[0].get("text", "").strip()
else:
print("Error:", response.status_code, response.text)
return None
# 配置参数
key = "sk-..." # 替换为你的实际 API 密钥
endpoint = "https://api.siliconflow.cn"
model = "Qwen/Qwen2-7B-Instruct"
# 创建聊天实例
chat_llm = SimpleChatLLM(key, endpoint, model)
# 测试简单对话
response = chat_llm.chat("how are you?")
print("AI Response:", response)
import requests
class SimpleChatLLM:
def __init__(self, key, endpoint, model):
self.key = key
self.endpoint = endpoint
self.model = model
def chat(self, prompt):
headers = {
"Authorization": f"Bearer {self.key}",
"Content-Type": "application/json"
}
data = {
"model": self.model,
"prompt": prompt,
"max_tokens": 50 # 限制回答的 token 长度
}
response = requests.post(f"{self.endpoint}/v1/completions", headers=headers, json=data)
if response.status_code == 200:
return response.json().get("choices", [])[0].get("text", "").strip()
else:
print("Error:", response.status_code, response.text)
return None
# 配置参数
key = "sk-..." # 替换为你的实际 API 密钥
endpoint = "https://api.siliconflow.cn"
model = "Qwen/Qwen2-7B-Instruct"
# 创建聊天实例
chat_llm = SimpleChatLLM(key, endpoint, model)
# 测试简单对话
response = chat_llm.chat("how are you?")
print("AI Response:", response)
问答
问答的时候记得用英文,因为ollama没有中文能力
如果有自己的需求的话可以向下继续看,学会调用微调的大模型让他具备中文能力(自己微调还有一定距离)
huggingface调用微调ollama大模型
进入huggingface找一个自己中意的大模型
正确省流
一
有一个方案是我已经成功过的-这个方案不需要本地,全部api实现
用huggingface自带的transformers库和huggingface的api实现,直接把参考文档代码和要求甩给gpt,把该下载的包都下载,就能实现了,不过多赘述,我还试了一下用别人的flux,直接实现无限白嫖
可以后续单独出一篇huggingface食用指南
二
接下来是第二种方案,下载下来本地调用
有两种格式GGUF和Safetensor
Safetensor是用来微调和其他操作的,官方给的就是这个
GGUF是用来交流学习的,这个就可以下载别人的了,我们选一个中文微调过的
https://huggingface.co/hfl/llama-3-chinese-8b-instruct-v3-gguf/tree/main
1直接在你下载ollama的地方新建一个文本文件,命名为Modelfile
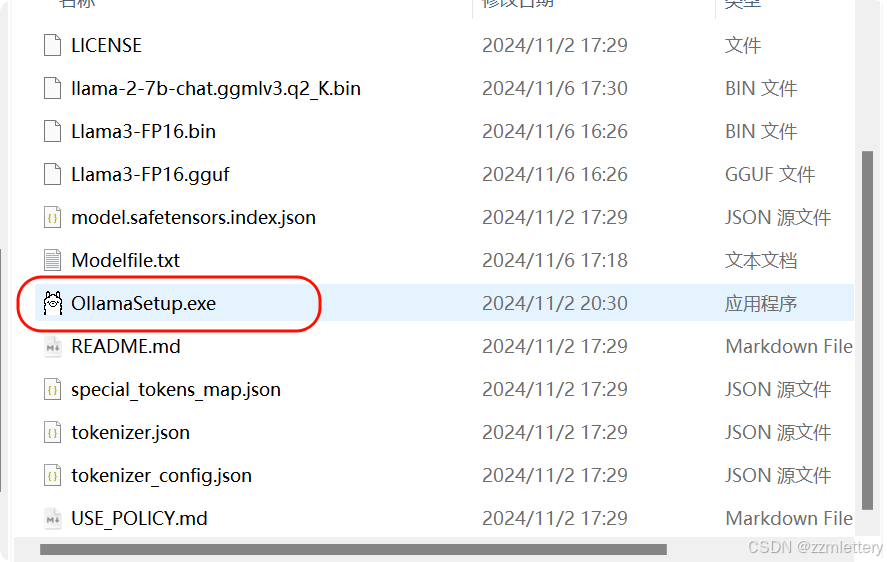
2输入下面代码,然后保存
FROM D:/AI/ollama/Llama3-FP16.gguf
3然后在命令行执行ollama的指令(这个是用来命名你这个模型叫llama3的)
ollama create llama3 -f Modelfile
4然后运行这个你命名的大模型
ollama run llama3
5结束
不想看错误示范到这里可以结束了
错误省流
需要安装 pip install llama-cpp-python 这个包。
我搞了半天单独下载llama-cpp-python,最后还是算了,直接全下得了
这是它的readmehttps://github.com/ggerganov/llama.cpp/blob/master/README.md#prepare-and-quantize
为什么一定要cpp这是gpt的回答(我从这里开始,就在正确的道路上越走越远,这句话是错的,GGUF文件是不需要cpp的,cpp就是用来把别的文件形式转化为GGUF的)
就是要用它去解析GGUF文件,实现调用
预想路径
1 下载
visualstudio build tools+cmake
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/
https://cmake.org/download/
2 打开visualstudio build tools的命令行执行命令(点启动

3克隆官方仓库
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp
4然后再cd到你路径下载的路径,再执行
cmake -B build -DCMAKE_BUILD_TYPE=Debug cmake --build build
5结束
艰辛历程(详细遇到的所有问题
希望你遇不到这些问题,希望你遇到的问题也被我遇到过了
注意vs的build tools(不是正常的visualstudio!!!!
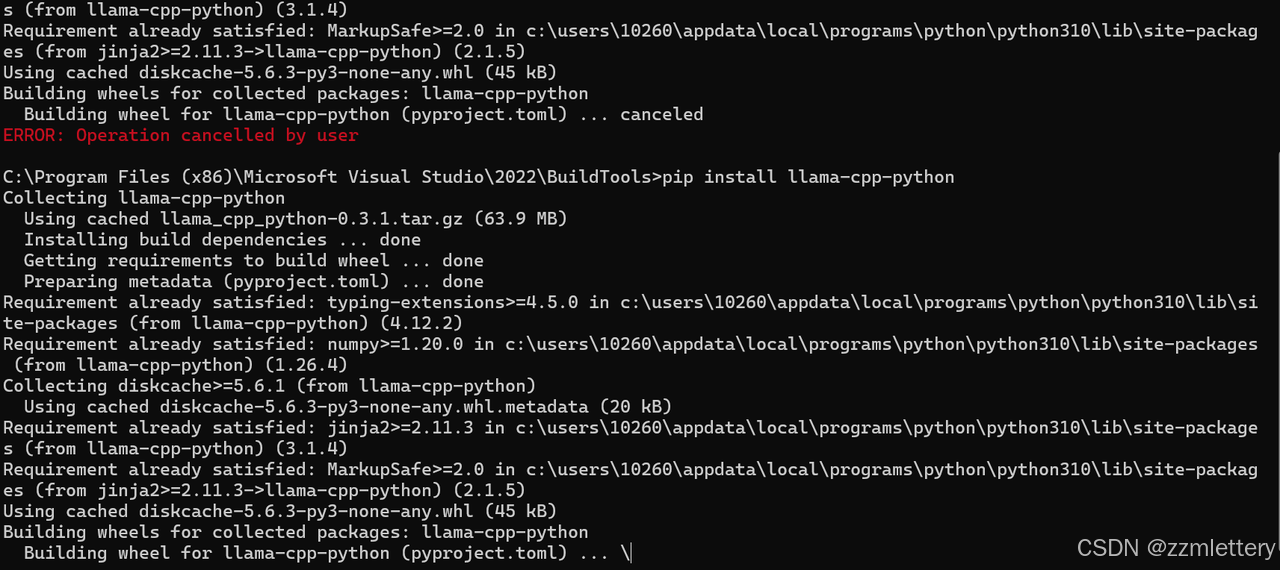
直接pip install llama-cpp-python会报错
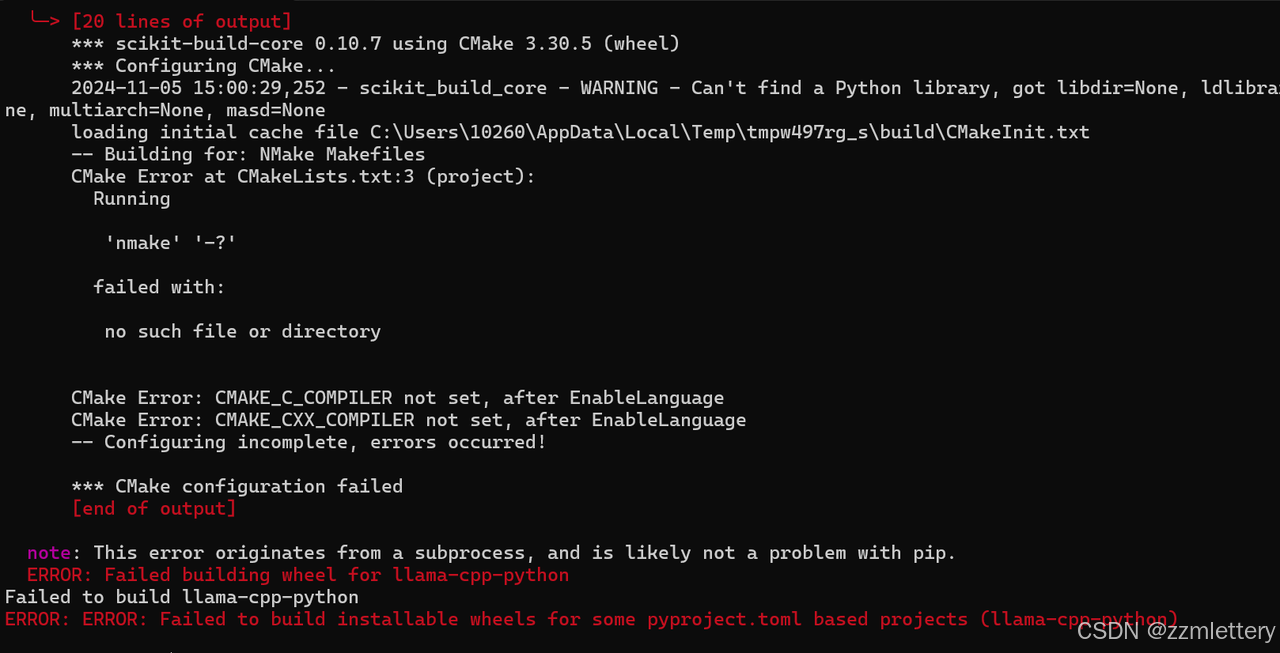
下载失败,gpt和github官方文档都要我安装visual studio(电脑真没多少地方了)

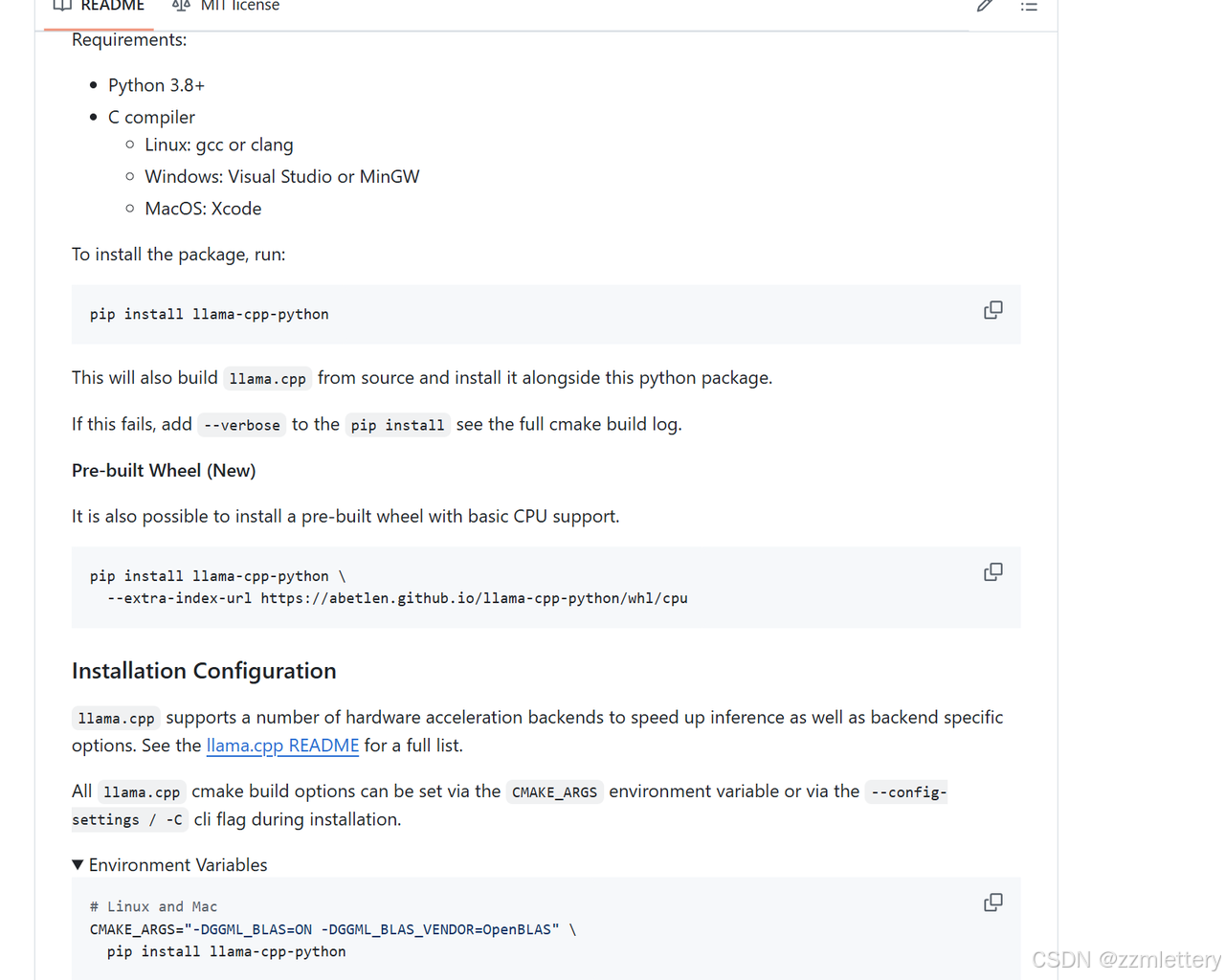
下载的时候记得选择有cmake的c++选项(不建议选太多,太多了电脑内存真的要爆炸,我关于ai和编程的东西已经快200g了

我——??? 这两个还不是同一个,好好好

成了成了
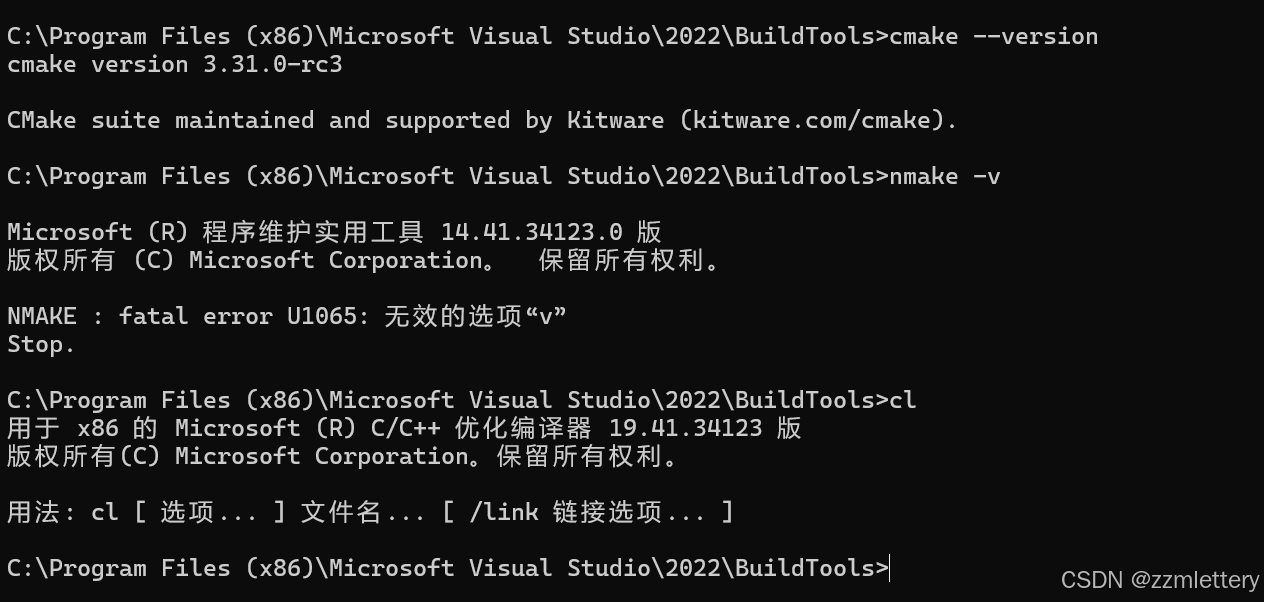
这回我们再来pip install llama-cpp-python
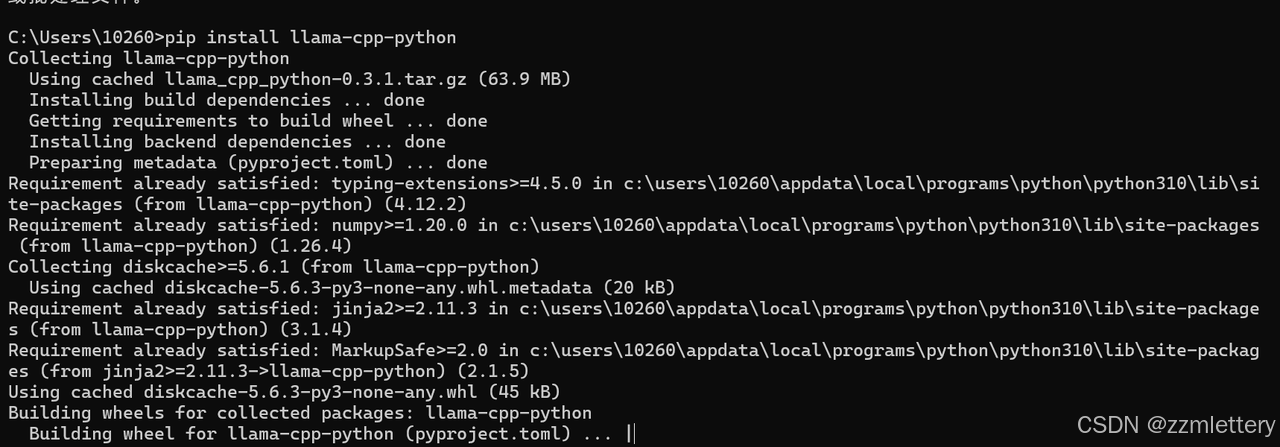
怎么卡在这不动了
难道一定要在 tools运行
网不好?防火墙没关?
应该是网不好,至少他还在转圈,我gpt也卡了
没内存?好好好,c盘要炸了
你别急,我还没急,今天必须把你给下下来
https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md
我再看一眼官方文档
四种方法是吧,我用第二种
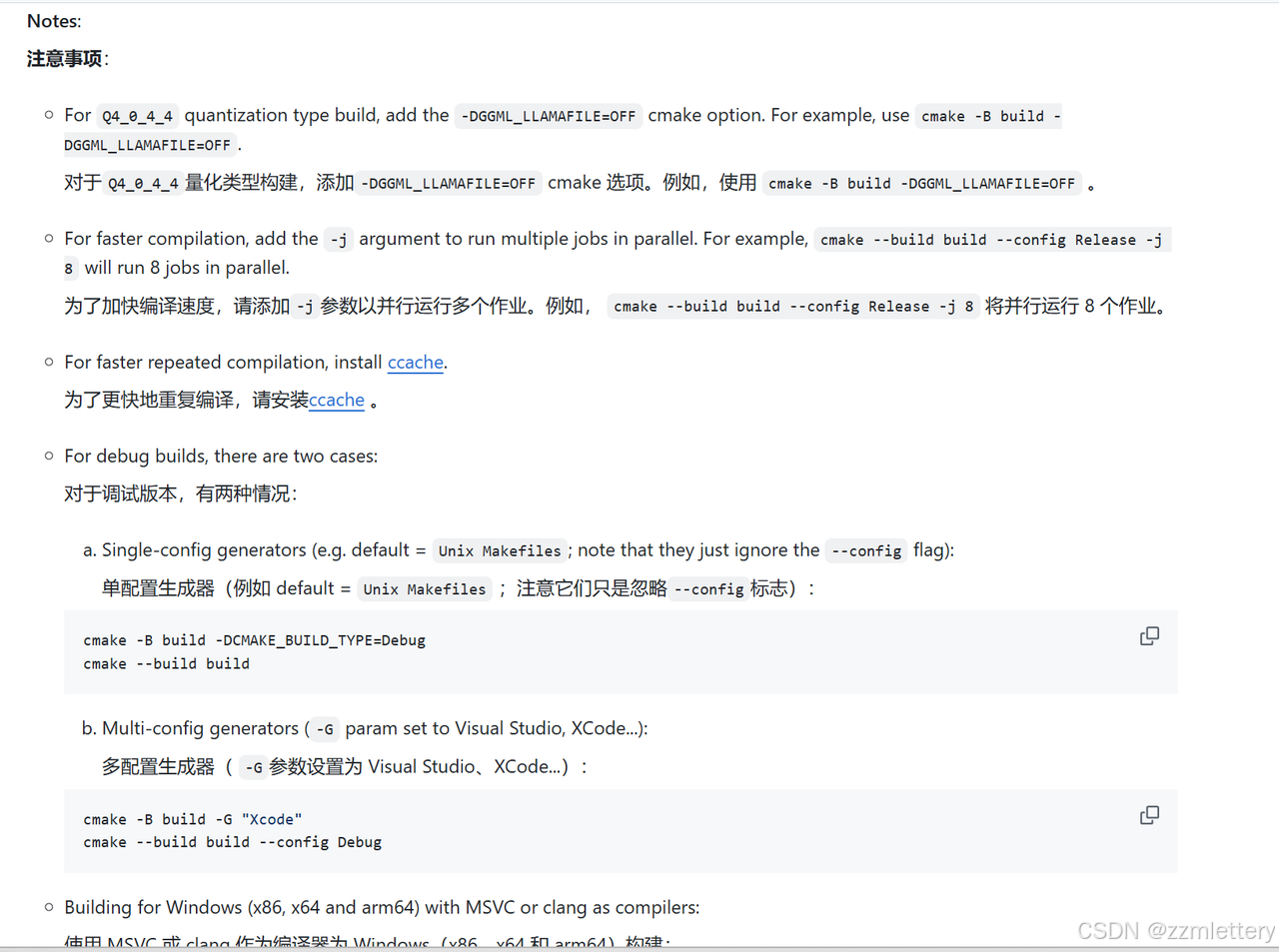
先从这里启动(不然一堆报错我替你们试过了,不好看看文档的惩罚)
官方文档里有说


然后再cd路径
cmake -B build -DCMAKE_BUILD_TYPE=Debug
cmake --build build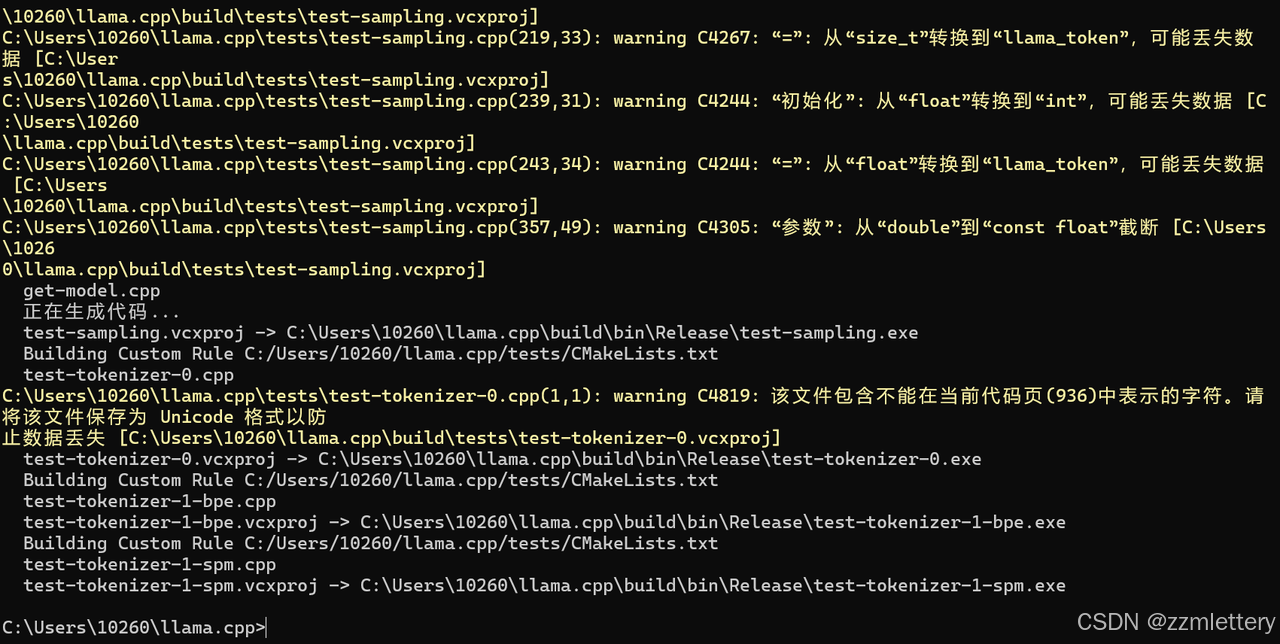
别急,胜利就在眼前
我这回是构建成功了吧
还是要下载llama-cpp-python吗
https://github.com/abetlen/llama-cpp-python我不信了
我等了快半个小时,他终于安装完了
下载到本地
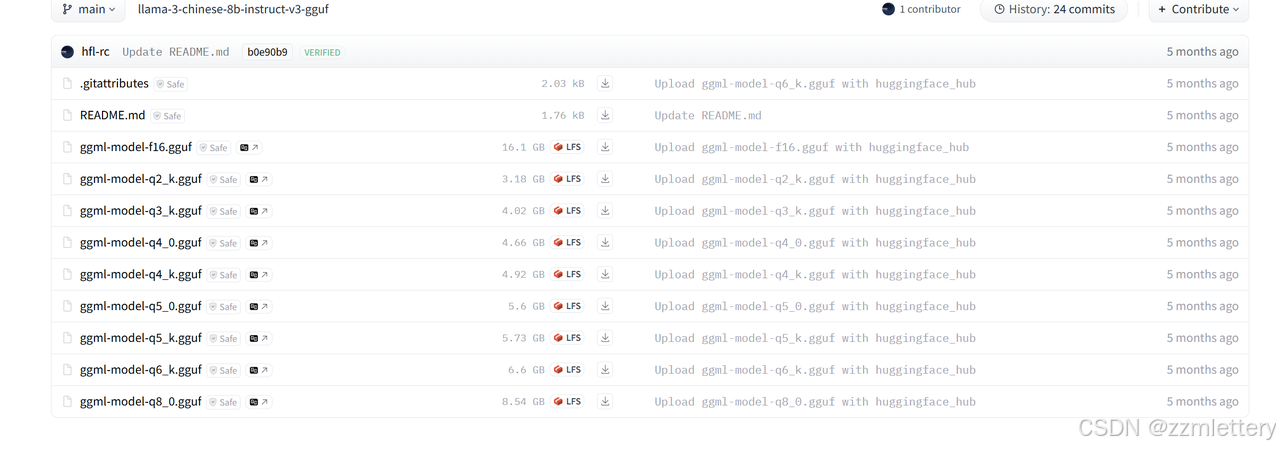
我的4060,12g显存应该能支持q8
根据自己需求来,文件越小需要配置越少
最终代码
# 导入需要的库
from llama_cpp import Llama
from typing import Optional, List, Mapping, Any
from langchain.llms.base import LLM
# 模型的名称和路径常量
MODEL_NAME = 'llama-2-7b-chat.ggmlv3.q4_K_S.bin'
MODEL_PATH = '/home/huangj/03_Llama/'
# 自定义的LLM类,继承自基础LLM类
class CustomLLM(LLM):
model_name = MODEL_NAME
# 该方法使用Llama库调用模型生成回复
def _call(self, prompt: str, stop: Optional[List[str]] = None) -> str:
prompt_length = len(prompt) + 5
# 初始化Llama模型,指定模型路径和线程数
llm = Llama(model_path=MODEL_PATH+MODEL_NAME, n_threads=4)
# 使用Llama模型生成回复
response = llm(f"Q: {prompt} A: ", max_tokens=256)
# 从返回的回复中提取文本部分
output = response['choices'][0]['text'].replace('A: ', '').strip()
# 返回生成的回复,同时剔除了问题部分和额外字符
return output[prompt_length:]
# 返回模型的标识参数,这里只是返回模型的名称
@property
def _identifying_params(self) -> Mapping[str, Any]:
return {"name_of_model": self.model_name}
# 返回模型的类型,这里是"custom"
@property
def _llm_type(self) -> str:
return "custom"
# 初始化自定义LLM类
llm = CustomLLM()
# 使用自定义LLM生成一个回复
result = llm("昨天有一个客户抱怨他买了花给女朋友之后,两天花就枯了,你说作为客服我应该怎么解释?")
# 打印生成的回复
print(result)
换个思路,我再搜一搜
原来还有一种方法

无敌了。。。。。。。。。。。。。。。。。。。。。。。。。。。
tmd,langchain手册里的文件格式是ggml,我下载的是gguf,根本就不需要ollama.cpp
你等我下一个小一点的别的格式模型,我真的不想我一下午在做无用功
https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML/tree/main
还是有问题,说我版本位数不匹配,一个64一个32
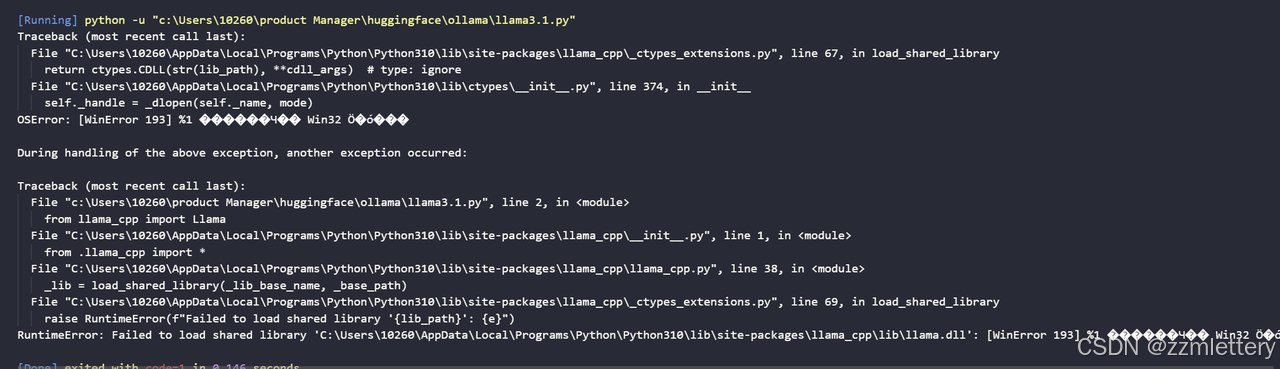
按照gpt说的,试了一下重新加载所有文件和版本
然后上指定位置更改制定的ollama.dll
还重新又去看了几遍llama.cpp的readme,还是没解决
先放在这吧
最后回顾一下
最关键的点就是
GGUF格式根本不需要llama.cpp,而手册里是bin格式,是需要的,现在已经过时了
这个锅,我必须甩给gpt,他这一本正经的胡说八道,害我走了太多弯路了,我下次再也不这么肯定的问他了


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 56
56 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)