
前端开发者玩转AI编程:揭秘Node+Langchain技术组合的魔法(四)
揭秘Node+Langchain技术组合的魔法(四)RAG
系列文章目录
揭秘Node+Langchain技术组合的魔法(一)快速开始
揭秘Node+Langchain技术组合的魔法(五)RAG2
目录
前言
在当今AI应用层开发的广阔天地中,RAG技术无疑占据了核心地位。将大型模型直接部署到本地,其意义似乎并不显著,毕竟在互联网如此便捷的今天,云端调用成为了更优选择。那么,RAG究竟是什么呢?网络上关于它的介绍繁多,简单来说,RAG技术就是为大型语言模型(LLM)注入外部知识源的强大力量,从而显著提升AI应用回复的质量与可靠性。将我们自身的知识库与AI大模型相结合,这才是AI应用层开发的精髓所在。近日,我在GIS小丸子的朋友圈中看到这样一句话:“在RAG知识库之后,许多Agent框架似乎也显得不再那么重要。”在使用了众多AI大模型之后,我对此深有感触。然而,我仍然满怀期待,相信下一代大模型将带来前所未有的革新与亮点。
一、如何理解RAG
1.前世今生
在人工智能领域,大模型开发一直是技术发展的关键所在。从最早的规则引擎到如今的高级神经网络,大模型的发展历程可谓波澜壮阔。
🌟第一阶段:模型研发 深度学习、神经网络、算法等耗费大量人力物力财力
🌟第二阶段:预训练模型的基础上调优 耗费大量算力资源、且需要丰富的微调经验
独立开发大模型对个人来说难度堪比登天,大型模型的微调更是依赖于庞大的计算能力,如果没有企业级的支持,个人几乎无法承担。在这样的背景下,RAG(Retrieval-Augmented Generation)概念应运而生。通过RAG技术,可以高效检索数据信息,这种方式不仅成本较低,而且能够迅速实现,为AI应用的发展开辟了新的路径。
2.抽丝剥茧
看了前面三篇文章的朋友应该还记得,大模型对话提示词的两个重要条件
|
SystemMessage |
HumanMessage |
|---|---|
| 系统提示词 | 用户提示词 |
假设你要让大模型帮你分析红楼梦,但是大模型训练没有收录这红楼梦,这时候就需要你把这篇文章的全部内容以提示词的方式告诉大模型,逻辑参照下面的代码
// 创建系统消息
const systemMessage = new SystemMessage(
"你是一个红学大师,致力于红楼梦文学的研究。"
);
// 创建用户消息
const userMessage = new HumanMessage("红楼梦原文如下:《红楼梦》 第一回
甄士隐梦幻识通灵 贾雨村风尘怀闺秀。。。此处省略n个字。。。,后人见了,无不叹息感慨,
想其盛衰。请帮我分析下贾宝玉的性格缺点 ");
// 调用模型
const res = await model.invoke([
systemMessage,
userMessage
]);这样它就可以对红楼梦进行分析了,这就是早期的RAG理念了,你需要让大模型知道一些知识,然后才能对这些知识进行问答,然后随着你的需求越来越多,还想让大模型分析三国、水浒、金瓶梅之类的,但总不能每次问答前都附加一些文字,于是乎后面就对RAG这个概念不断的优化,衍生出了一些包括向量数据库之类配套的工具
二、向量数据库
刚才有提到RAG不断演化的过程中出现了向量数据库的工具,它的作用就是我建立了一个数据库,数据库中存储了像红楼梦、三国演义、水浒、西游记、金瓶梅之类的文章,在问大模型问题之前,先从向量数据库中拿到相关的知识,然后再统一丢给大模型让大模型去分析处理
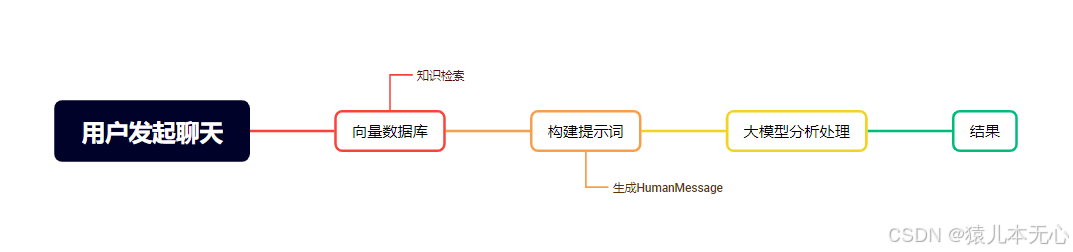
向量数据库知识检索时官网给了一个图来解释它的原理
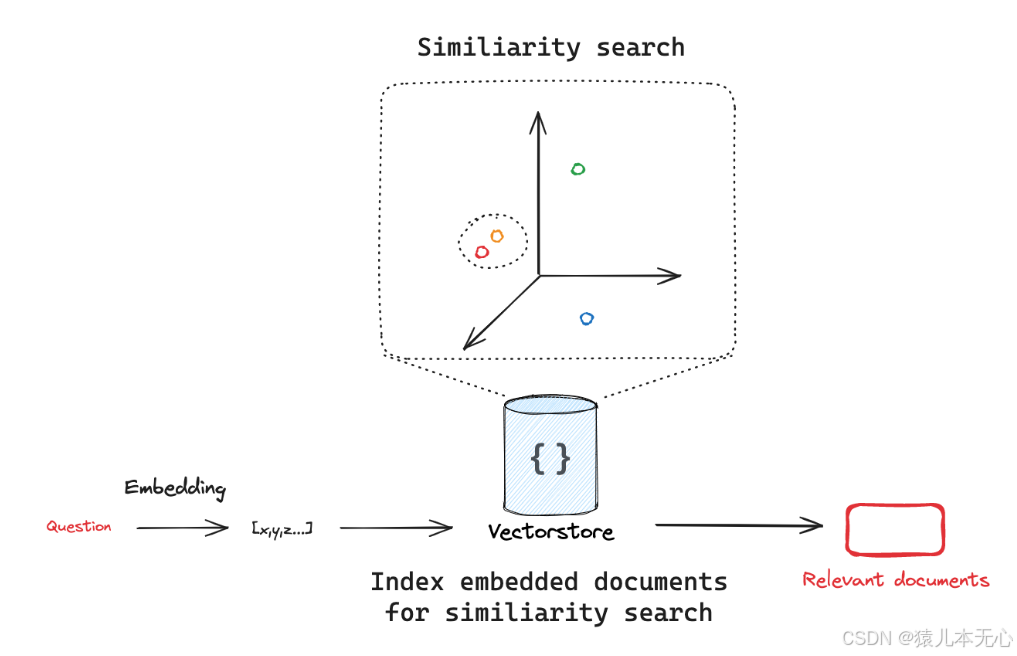
大致意思就是把问题转换成二进制的向量,然后用余弦相似度算法在向量数据库中匹配出相关的内容,然后再输出出去
1.数据库选择
官网中推荐的几种向量数据库如下

,我简单测试了下
- Memory 在内存中存储,关闭程序就会清空
- Chroma 在Node环境中不支持文件型的数据库,只支持客户端服务器的模式
- FAISS 文件型数据库,方便小项目和demo使用
- MongoDB 在Node环境中不支持文件型的数据库,只支持客户端服务器的模式
2.安装依赖以及代码封装
🛠️依赖安装(主要是faiss-node,其它的在项目创建的时候就已经安装了)
npm i @langchain/community faiss-node @langchain/core代码结构
└─vectorStore # 向量存储相关功能
├─data # 向量数据存储目录
└─index.js # 向量存储功能入口文件主代码
const { Document } = require('@langchain/core/documents');
const { RecursiveCharacterTextSplitter } = require('langchain/text_splitter');
const { OllamaEmbeddings } = require('@langchain/ollama');
const { FaissStore } = require('@langchain/community/vectorstores/faiss');
const path = require('path');
const fs = require('fs');
// 初始化 Ollama 嵌入模型
const embeddings = new OllamaEmbeddings({
baseUrl: process.env.OLLAMA_BASE_URL || 'http://localhost:11434',
model: process.env.OLLAMA_MAIN_MODEL || "deepseek-r1:8b"
});
// 存储集合映射
const collections = new Map();
class VectorStoreService {
static textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
separators: ["\n\n", "\n", " ", ""],
keepSeparator: false
});
// 判断向量存储集合是否存在
static async vectorStoreCollectionExists(collectionName) {
const dataDir = path.join(process.cwd(), 'core', 'vectorStore', 'data', 'faiss', collectionName);
return fs.existsSync(dataDir);
}
// 初始化集合
static async initCollection(collectionName) {
try {
if (!collectionName) {
throw new Error('集合名称不能为空');
}
if (!collections.has(collectionName)) {
// 确保数据目录存在
const dataDir = path.join(process.cwd(), 'core', 'vectorStore', 'data', 'faiss');
if (!fs.existsSync(dataDir)) {
fs.mkdirSync(dataDir, { recursive: true });
}
// 检查是否存在现有的向量存储
const storePath = path.join(dataDir, collectionName);
let vectorStore;
if (fs.existsSync(storePath)) {
// 加载现有的向量存储
vectorStore = await FaissStore.load(storePath, embeddings);
} else {
// 创建新的向量存储,添加一个默认的空文档以初始化索引
const defaultDoc = new Document({
pageContent: "",
metadata: {
is_default: true,
created_at: new Date().toISOString()
}
});
vectorStore = await FaissStore.fromDocuments([defaultDoc], embeddings);
// 保存向量存储
await vectorStore.save(storePath);
}
collections.set(collectionName, vectorStore);
}
return collections.get(collectionName);
} catch (error) {
console.error(`初始化集合 ${collectionName} 失败:`, error);
throw error;
}
}
// 添加文档到向量存储
static async addDocuments(collectionName, documents) {
try {
const vectorStore = await this.initCollection(collectionName);
if (!Array.isArray(documents) || documents.length === 0) {
throw new Error('documents必须是非空数组');
}
// 文档分块处理
const docs = [];
for (const doc of documents) {
let text = '';
if (typeof doc === 'string') {
text = doc;
} else if (doc.text) {
text = doc.text;
} else if (doc.pageContent) {
text = doc.pageContent;
} else {
console.warn('跳过无效文档:', doc);
continue;
}
const splits = await this.textSplitter.splitText(text);
const metadata = doc.metadata || {};
docs.push(...splits.map(content => new Document({
pageContent: content,
metadata: {
...metadata,
chunk_size: content.length,
created_at: new Date().toISOString()
}
})));
}
if (docs.length === 0) {
throw new Error('没有有效的文档内容可以添加');
}
// 添加到向量存储
await vectorStore.addDocuments(docs);
// 保存更新后的向量存储
const storePath = path.join(process.cwd(), 'core', 'vectorStore', 'data', 'faiss', collectionName);
await vectorStore.save(storePath);
return {
success: true,
count: docs.length
};
} catch (error) {
console.error(`添加文档到集合 ${collectionName} 失败:`, error);
throw error;
}
}
// 相似度搜索
static async similaritySearch(collectionName, query, k = 3) {
try {
if (!query) {
throw new Error('搜索查询不能为空');
}
const vectorStore = await this.initCollection(collectionName);
// 执行相似度搜索
const results = await vectorStore.similaritySearchWithScore(query, k);
// 格式化结果
return results.map(([doc, score]) => ({
content: doc.pageContent,
metadata: {
...doc.metadata,
similarity_score: score,
matched_at: new Date().toISOString()
}
}));
} catch (error) {
console.error(`在集合 ${collectionName} 中搜索失败:`, error);
throw error;
}
}
// 删除文档
static async deleteDocuments(collectionName, filter) {
try {
const vectorStore = await this.initCollection(collectionName);
// FAISS不支持按元数据过滤删除,这里我们重新创建一个空的向量存储
const storePath = path.join(process.cwd(), 'core', 'vectorStore', 'data', 'faiss', collectionName);
const newVectorStore = await FaissStore.fromDocuments([], embeddings);
await newVectorStore.save(storePath);
collections.set(collectionName, newVectorStore);
return true;
} catch (error) {
console.error(`从集合 ${collectionName} 删除文档失败:`, error);
throw error;
}
}
}
module.exports = VectorStoreService;三.RAG个人知识库搭建
1.目录结构设计
├─core # 核心功能目录
│ ├─rag # RAG(检索增强生成)相关功能
│ │ ├─baseRag.js # 基础RAG功能实现
│ │ ├─fileRag.js # 文件RAG功能实现
│ │ ├─webRag.js # 网页RAG功能实现
│ │ └─data # RAG数据存储目录
│ │ └─index.js # RAG功能入口文件因为RAG类型很多,下面就以文件型的知识库做下简单的讲解
逻辑很简单,基本上就两个步骤
- 📚 获取数据
- 🗂️ 把数据存到向量数据库中
2.文件RAG知识库搭建
第一步 创建文件夹,把需要学习的文件全放到文件夹中
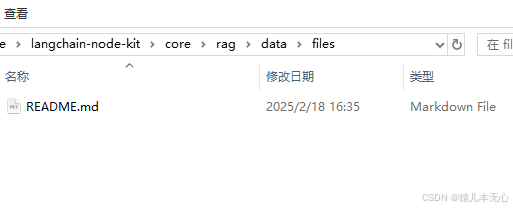
在这个文件夹中我放了一个geoserver-helper的说明文件,目的是想让大模型帮我分析geoserver-helper的使用说明
第二步 把文件内容存储到向量数据库中
首先要先创建基础RAG类,方便后期各种rag继承和扩展
const { Document } = require('@langchain/core/documents');
const VectorStoreService = require('../vectorStore');
class BaseRagService {
static COLLECTION_NAME = 'baseRag';
// 初始化向量存储
static async initVectorStore(collectionName) {
try {
// 初始化向量存储集合
await VectorStoreService.initCollection(collectionName);
// 检查集合是否存在
if(!await VectorStoreService.vectorStoreCollectionExists(collectionName)){
// 初始化数据
await this.initializeData();
} else {
console.log('集合已存在,将会使用原有的集合!');
}
} catch (error) {
console.error('初始化向量存储失败:', error);
throw error;
}
}
// 初始化数据(子类需要重写此方法)
static async initializeData() {
// 默认实现为空,子类应该根据具体需求重写此方法
console.log('注意:子类需要重写initializeData方法以初始化数据');
}
// 处理文档内容
static async processContent(docs, collectionName, additionalMetadata = {}) {
try {
// 初始化向量存储
await this.initVectorStore(collectionName);
// 添加文档到向量存储
const result = await VectorStoreService.addDocuments(collectionName, docs.map(doc => ({
...doc,
metadata: {
...doc.metadata,
...additionalMetadata,
processed_at: new Date().toISOString()
}
})));
return result;
} catch (error) {
console.error('处理文档内容失败:', error);
throw error;
}
}
// 相似度搜索
static async similaritySearch(collectionName, query, k = 5) {
try {
return await VectorStoreService.similaritySearch(collectionName, query, k);
} catch (error) {
console.error('文档内容相似度搜索失败:', error);
throw error;
}
}
// 删除文档内容
static async deleteContent(collectionName) {
try {
return await VectorStoreService.deleteDocuments(collectionName);
} catch (error) {
console.error('删除文档内容失败:', error);
throw error;
}
}
}
module.exports = BaseRagService;然后再添加 文件型RAG的代码逻辑
const fs = require('fs');
const path = require('path');
const chokidar = require('chokidar');
const { PDFLoader } = require('@langchain/community/document_loaders/fs/pdf');
const { TextLoader } = require('langchain/document_loaders/fs/text');
const { DocxLoader } = require('@langchain/community/document_loaders/fs/docx');
const BaseRagService = require('./baseRag');
const VectorStoreService = require('../vectorStore');
class FileRagService extends BaseRagService {
static RAW_DATA_DIR = path.join(process.cwd(), 'core', 'rag', 'data', 'files');
static COLLECTION_NAME = 'fileRag';
// 初始化数据
static async initializeData() {
try {
// 确保目录存在
if (!fs.existsSync(this.RAW_DATA_DIR)) {
fs.mkdirSync(this.RAW_DATA_DIR, { recursive: true });
}
// 初始化向量存储
await VectorStoreService.initCollection(this.COLLECTION_NAME);
//判断向量存储的数据是否存在 不存在则处理文档生成
if(!VectorStoreService.vectorStoreCollectionExists(this.COLLECTION_NAME)){
// 处理现有文档
await this.processDocuments();
}else {
console.log('文件RAG集合数据已存在,将会使用原有的集合!');
}
} catch (error) {
console.error('初始化数据失败:', error);
throw error;
}
}
// 处理文档列表
static async processDocuments() {
const files = fs.readdirSync(this.RAW_DATA_DIR);
for (const file of files) {
await this.processDocument(path.join(this.RAW_DATA_DIR, file));
}
}
// 处理单个文档
static async processDocument(filePath) {
try {
const ext = path.extname(filePath).toLowerCase();
let loader;
// 根据文件类型选择加载器
switch (ext) {
case '.pdf':
loader = new PDFLoader(filePath);
break;
case '.txt':
loader = new TextLoader(filePath);
break;
case '.docx':
loader = new DocxLoader(filePath);
break;
case '.md':
case '.markdown':
loader = new TextLoader(filePath);
break;
default:
console.log(`不支持的文件类型: ${ext}`);
return;
}
// 加载文档
const docs = await loader.load();
// 添加到向量存储
await this.processContent(docs, this.COLLECTION_NAME, {
file_path: filePath,
file_type: ext.slice(1)
});
console.log(`文档处理完成: ${filePath}`);
} catch (error) {
console.error(`处理文档失败 ${filePath}:`, error);
}
}
}
module.exports = FileRagService;3.rag接口调用
上篇文章中以聊天的接口过了一遍,这次再它原来的基础上扩展
Router层
// 基于检索增强生成(RAG)的聊天接口
router.post('/ragChat', ChatController.ragChat);Controller层
static async ragChat(req, res) {
try {
const { message } = req.body;
if (!message) {
return res.status(400).json({ error: '消息内容不能为空' });
}
const response = await chatService.ragChat(message);
res.json(response);
} catch (error) {
res.status(500).json({ error: '服务器内部错误' });
}
}Services层
static async ragChat(question) {
try {
// 从向量存储中检索相关文档
const fileRelevantDocs = await VectorStoreService.similaritySearch(
FileRagService.COLLECTION_NAME,
question,
1
);
const relevantDocs = fileRelevantDocs;
if (!relevantDocs || relevantDocs.length === 0) {
return ResultWrapper.success('抱歉,我没有找到相关的信息来回答这个问题。');
}
// 将检索到的文档内容合并为上下文
const context = relevantDocs
.map(doc => doc.content)
.join('\n\n');
// 创建提示模板
const qaPrompt = PromptTemplate.fromTemplate(`使用以下上下文来回答问题。如果你不知道答案,就说你不知道,不要试图编造答案。
上下文:{context}
问题:{question}
答案:`);
// 创建QA链
const qaChain = RunnableSequence.from([
{
context: (input) => input.context,
question: (input) => input.question,
},
qaPrompt,
ollama,
outputParser,
]);
// 执行QA链
const response = await qaChain.invoke({
context,
question,
});
return ResultWrapper.success(response);
} catch (error) {
console.error('QA处理失败:', error);
return ResultWrapper.error(error.message);
}
}4.成果测试
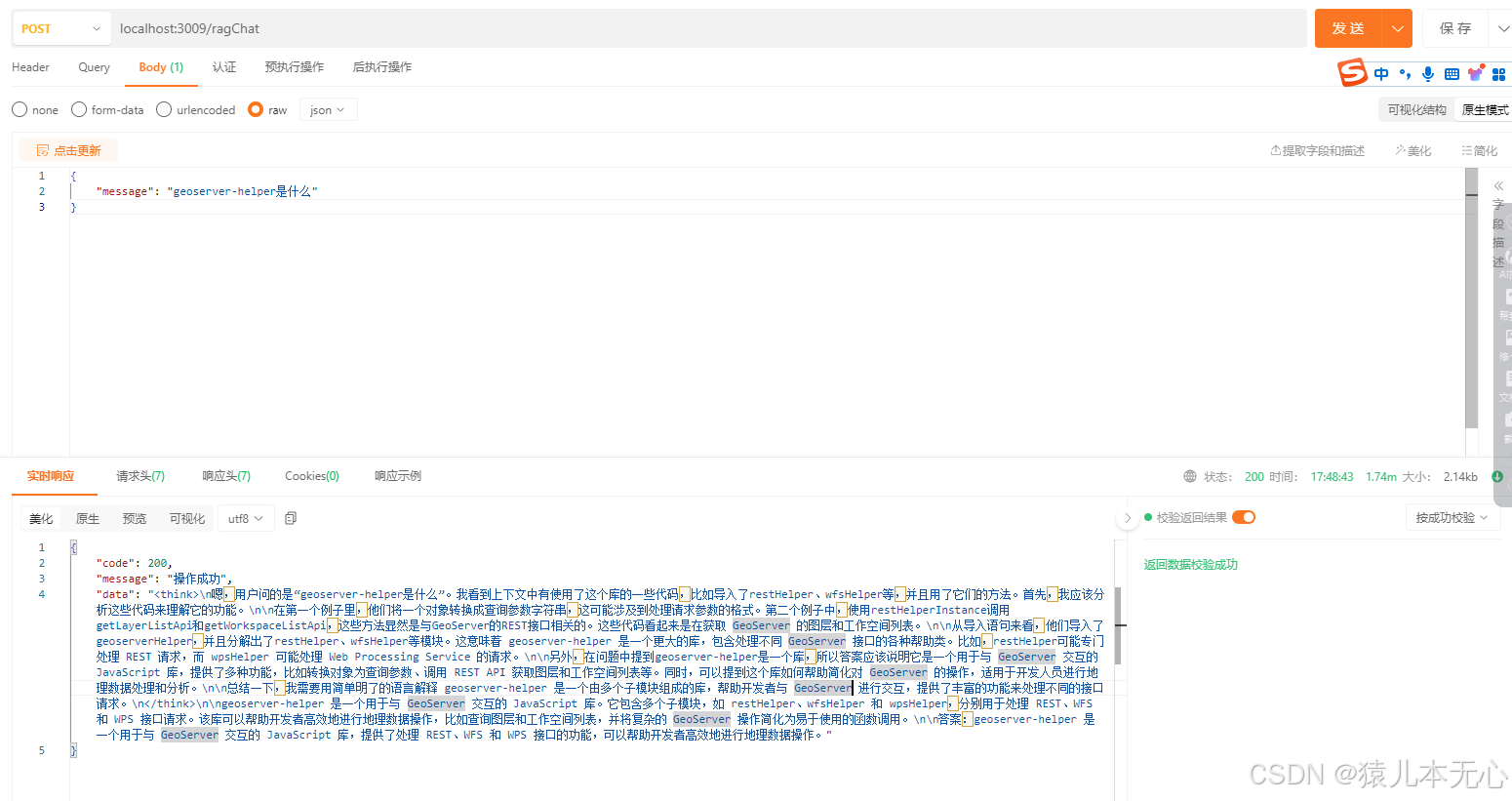
整体来说还是比较符合我的预期的
5.知识点总结
- 👀 需要关注langchain的各种loader,也就是加载文件的代码
- 🔗 需要和向量数据库配合使用
总结
RAG个人知识库是langchain开发的重点,也有好多有趣的玩法,可以自行探索。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)