YOLOv11 安全帽佩戴人工智能检测项目实战(本文提供完整数据集、项目代码、英伟达4090D显卡服务器环境)
YOLO11 安全帽佩戴人工智能检测项目实战(本文提供完整数据集、项目代码、英伟达 4090D 显卡服务器环境)。深度学习框架、YOLOv8、YOLOv11项目实战。
YOLOv11 安全帽佩戴人工智能检测项目实战(本文提供完整数据集、项目代码、英伟达 4090D 显卡服务器环境)
- 安全帽佩戴人工智能检测项目课程
- 安全帽佩戴人工智能检测项目课程阐述
- 安全帽佩戴人工智能检测项目课程实战
_ 初始化启动并创建
_ 进入实训平台,并启动打开进入实操界面
_ 导入所需库文件并验证环境
_ 读取数据
_ 读取待训练数据集并展示
_ 输出数据集的大小和数量
_ 展现详细数据格式
_ 清理数据
_ 展示数据图片
_ 开始训练
_ 设置训练参数
安全帽佩戴人工智能检测项目课程阐述
背景与意义
随着我国城镇化进程的加速推进,建筑行业作为国民经济支柱产业之一,其安全生产问题受到社会各界的广泛关注。据统计,建筑工地事故中约 23%与头部防护缺失直接相关(数据来源:国家应急管理部,2023)。安全帽作为建筑工人最重要的个人防护装备,其规范佩戴是降低伤亡风险的第一道防线。然而,传统的人工监管模式存在效率低、成本高、覆盖范围有限等问题,难以实现全天候、无死角的实时监测。在此背景下,基于计算机视觉与人工智能技术的安全帽识别系统应运而生,为解决这一行业痛点提供了创新性技术路径。
技术应用价值
建筑工地安全帽识别系统通过部署智能摄像头与深度学习算法,可实现以下核心功能:
- 实时监测预警:对未佩戴安全帽的人员进行毫秒级识别报警
- 行为轨迹分析:结合位置数据追踪高风险区域的违规行为
- 数据可视化:生成安全合规热力图与统计报表
- 多场景适应:支持复杂光照、遮挡及多角度条件下的精准识别
该技术将传统被动式安全管理转变为主动预防机制,使事故预防窗口从"事后追责"前移至"事中干预",显著提升工地安全管理效能。据试点项目数据显示,系统部署后违规佩戴率下降 72%,相关事故发生率降低 65%(案例数据:某特级建筑企业 2023 年报告)。
行业推动作用
从更宏观的视角来看,安全帽识别技术的应用具有三重战略价值:
- 人员安全保障升级:通过技术手段强化"最后一米"的防护执行,切实保障建筑工人生命安全,体现"以人为本"的行业发展理念。
- 管理效能革新:将安全管理成本降低约 40%(行业估算数据),同时提升监管透明度,助力建筑企业实现数字化转型升级。
- 行业标准重构:推动《智慧工地建设评价标准》(GB/T51435-2021)落地实施,为建筑行业智能化发展提供技术范本。
安全帽佩戴人工智能检测项目课程实战
初始化启动并创建
进入实训平台,并启动打开进入实操界面
首先我们需要进入https://www.lswai.com找到安全帽项目收藏项目 这样我们就会在我的数据集内找到。
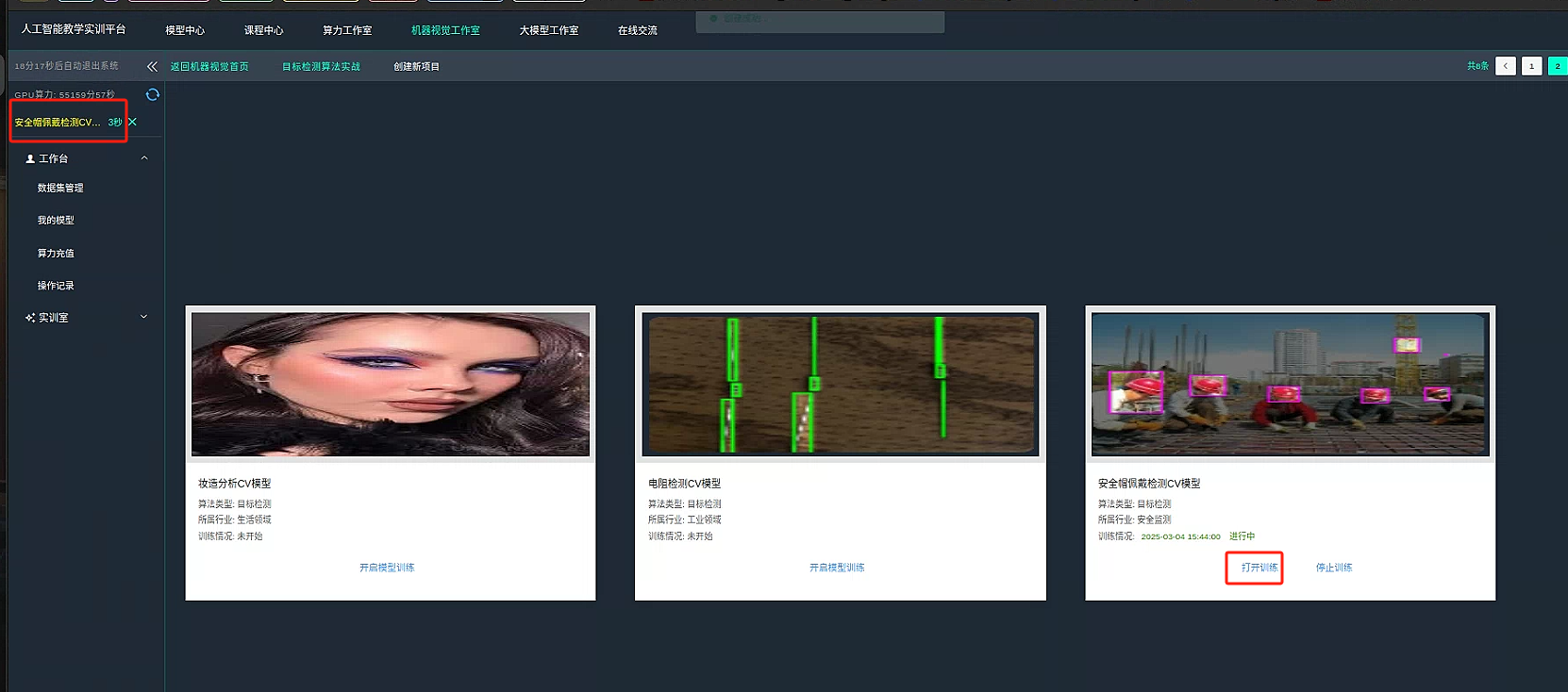
随后我们进入机器视觉工作室栏目 打开目标检测算法。
找到我们的安全帽项目,并开启训练。
并等待分配 GPU。
分配完成后请打开并等待数据转载。
请调整 GPU 使用时间 为 50 分钟
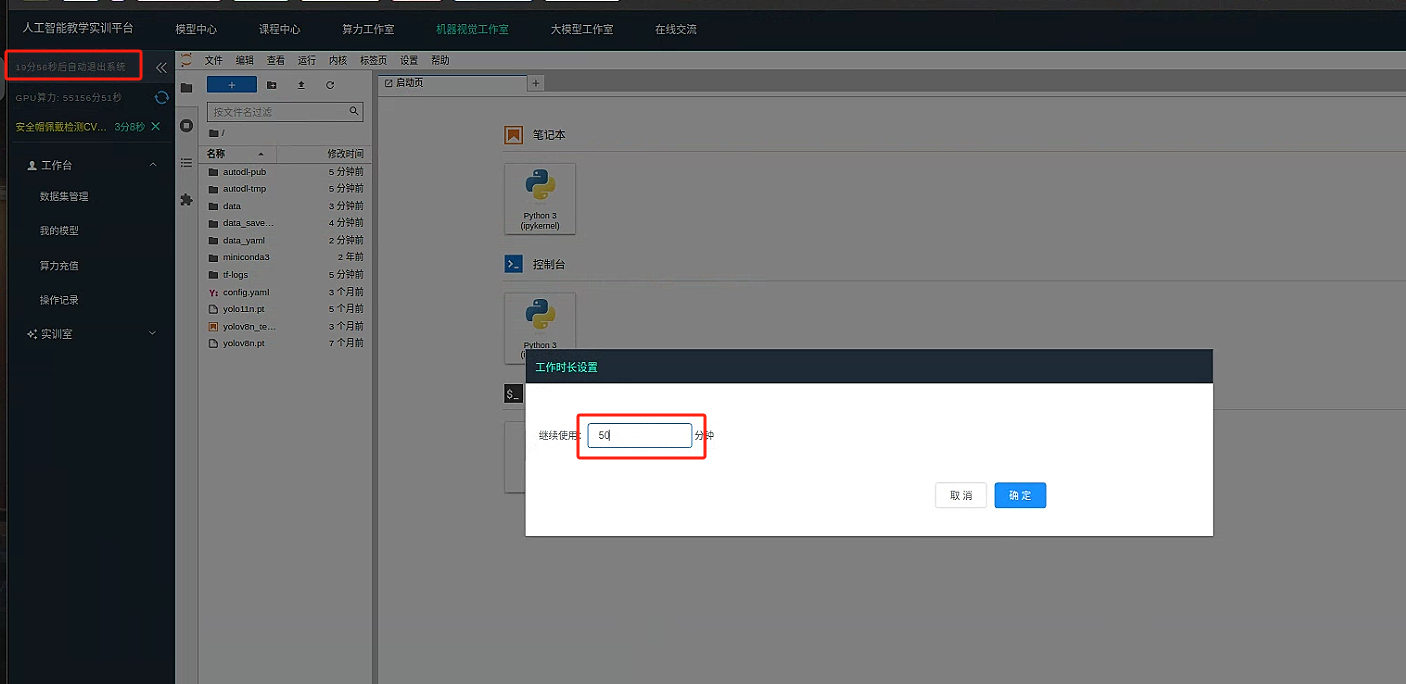
千万注意,如果 实例内部未曾打开过任何
jupyter notebook则可能会在一段时间后判定为 空闲服务器, 或者jupyter notebook距离上次活动 时间超过 25 分钟则也会被判定为空闲服务器 (保存,运行,创建新代码块,编写代码,等操作视为活跃) 如果需要使用纯命令行 ,请启动一个jupyter notebook并编写一个无限循环等待200s注意次此操作可能会造成服务器长期运行,浪费时长产生损失,实例一旦关闭会销毁所有数据无法恢复。
打开 示例代码运行即可测试环境。
导入所需库文件并验证环境
从现在开始 我们正式开始构建 安全帽项目 从数据到训练及最后的部署
示例代码可以忽略 也可使用 本教程,视为从新开发
验证环境 并导入一些可能用到的包
import torch
print(torch.cuda.is_available())
print(torch.__version__)
import warnings
import random
warnings.filterwarnings('ignore')
import os
import shutil
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import cv2
import yaml
from PIL import Image
from ultralytics import YOLO
from IPython.display import Video
- 读取数据
- 读取待训练数据集并展示
- 清理数据集
- 展示部分数据集
读取数据
读取待训练数据集并展示
dataset_path = '/root/data_yaml' # 平台数据集文件地址
yaml_file_path = os.path.join(dataset_path, 'data.yaml')
# 加载并打印 YAML 文件的内容
with open(yaml_file_path, 'r') as file:
yaml_content = yaml.load(file, Loader=yaml.FullLoader)
print(yaml.dump(yaml_content, default_flow_style=False))
输出数据集的大小和数量
# 设置训练和验证图像集的路径
train_images_path = os.path.join(dataset_path, 'train', 'images')
# valid_images_path = os.path.join(dataset_path, 'valid', 'images')
valid_images_path = os.path.join(dataset_path, 'valid', 'images')
# 初始化图像数量的计数器
num_train_images = 0
num_valid_images = 0
# 初始化集以保存图像的唯一大小
train_image_sizes = set()
valid_image_sizes = set()
# Check train images sizes and count
for filename in os.listdir(train_images_path):
if filename.endswith('.jpg'):
num_train_images += 1
image_path = os.path.join(train_images_path, filename)
with Image.open(image_path) as img:
train_image_sizes.add(img.size)
# 检查验证图像大小和数量
for filename in os.listdir(valid_images_path):
if filename.endswith('.jpg'):
num_valid_images += 1
image_path = os.path.join(valid_images_path, filename)
with Image.open(image_path) as img:
valid_image_sizes.add(img.size)
# 打印结果
print(f"Number of training images: {num_train_images}")
print(f"Number of validation images: {num_valid_images}")
# 检查训练集中的所有图像是否具有相同的大小
if len(train_image_sizes) == 1:
print(f"All training images have the same size: {train_image_sizes.pop()}")
else:
print("Training images have varying sizes.")
# 检查验证集中的所有图像是否具有相同的大小
if len(valid_image_sizes) == 1:
print(f"All validation images have the same size: {valid_image_sizes.pop()}")
else:
print("Validation images have varying sizes.")
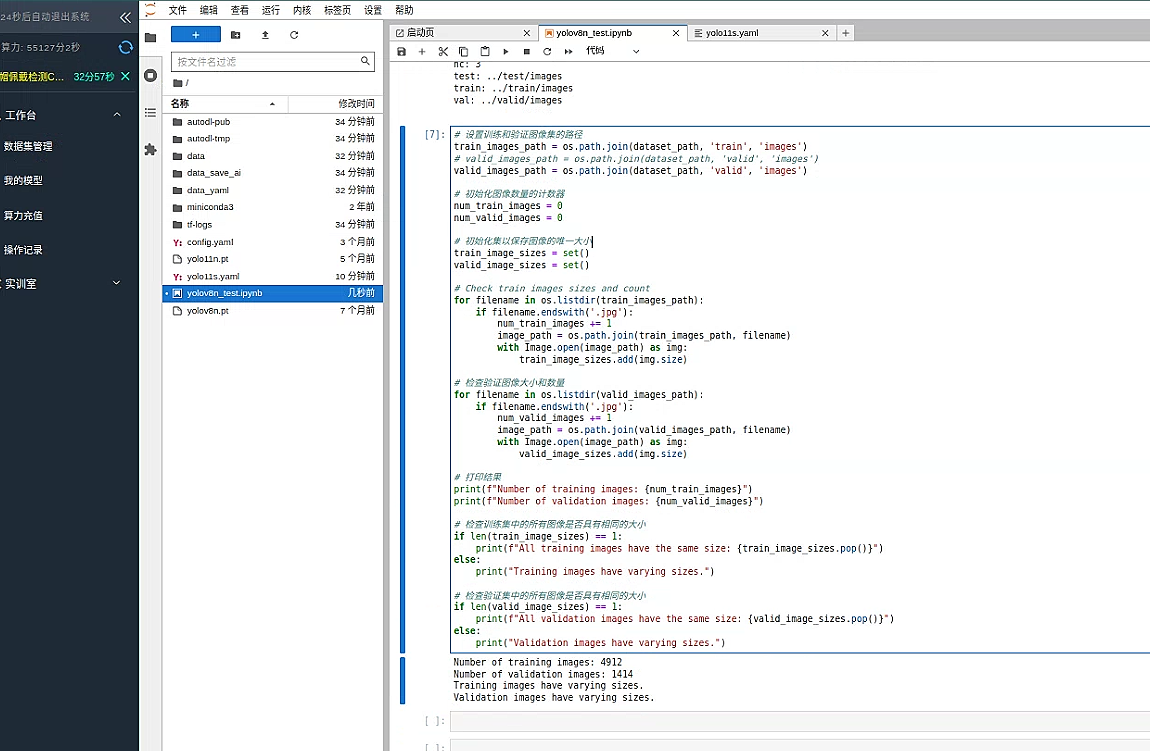
我们可以看到 有 4912 张训练集图片以及 1414 个验证集图片,但是大小都不同一,好在 yolo 对训练用图片大小没有做限制可以任意使用 。
展现详细数据格式
读取全部的数据集 并计算标签构成
from collections import Counter
from pathlib import Path
# 加载数据集配置文件
with open(yaml_file_path, 'r') as file:
data_config = yaml.safe_load(file)
# 定义统计标签的函数
def count_labels(data_path):
print('counting labels')
label_counts = Counter()
image_paths = list(Path(data_path).rglob('*.txt')) # 假设图片是jpg格式
print(len(image_paths))
for image_path in image_paths:
label_path = image_path.with_suffix('.txt')
if label_path.exists():
# print(label_path)
with open(label_path, 'r') as file:
labels = file.readlines()
for label in labels:
label_class = int(label.split()[0])
label_counts[label_class] += 1
return label_counts
print('data_config labels', data_config)
print('data_config yaml_file_path+data_config', dataset_path + "/test")
# 统计每个数据集(训练、验证、测试)的标签
train_counts = count_labels(dataset_path + "/test/labels")
val_counts = count_labels(dataset_path + "/valid/labels")
test_counts = count_labels(dataset_path + "/train/labels")
print(train_counts, val_counts, test_counts)
# 获取每个类别的名称
class_names = data_config['names']
# 合并所有统计结果
total_counts = train_counts + val_counts + test_counts
print('total_counts', total_counts)
# 输出每个类别的标签数量
for class_id, count in total_counts.items():
print(f"类别 {class_names[class_id]} 有 {count} 个标签")
从输出结果可以看出来 有 3 个标签 但是 构成似乎严重不平衡
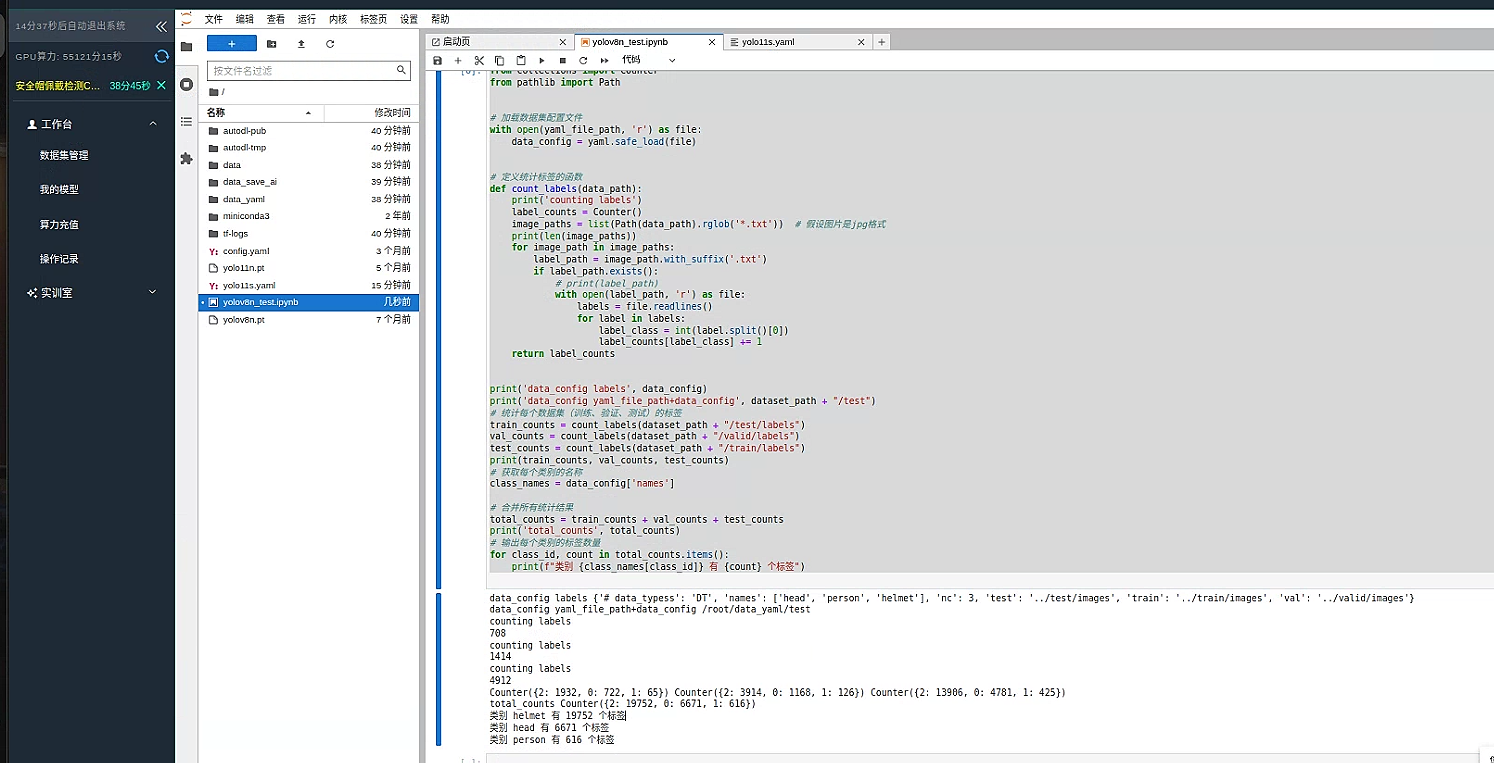
类别 helmet 有 19752 个标签 标签为 2
类别 head 有 6671 个标签 标签为 0
类别 person 有 616 个标签 标签为 1
因为 person 标签 严重低于其他的 因此我们可以考虑删除这个标签 或者增加这个标签的数据量,
清理数据
下面是删除这个标签的 方法
import os
def process_txt_files(folder_path):
# 获取文件夹内的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 遍历每个 txt 文件
for txt_file in txt_files:
txt_path = os.path.join(folder_path, txt_file)
with open(txt_path, 'r') as file:
lines = file.readlines()
# 处理每一行
modified_lines = []
for line in lines:
if line and line[0] == '1': # 如果首字符是数字 1 person的标签为 1
continue # 跳过该行
modified_lines.append(line) # 否则将此行保留
# 将修改后的内容写回文件
with open(txt_path, 'w') as file:
file.writelines(modified_lines)
# 调用函数,传入文件夹路径
process_txt_files(dataset_path + "/test/labels")
process_txt_files(dataset_path + "/valid/labels")
process_txt_files(dataset_path + "/train/labels")
随后我们再次展示数据集 可以看到 person 的标签为 1 的数据 已经被删除了
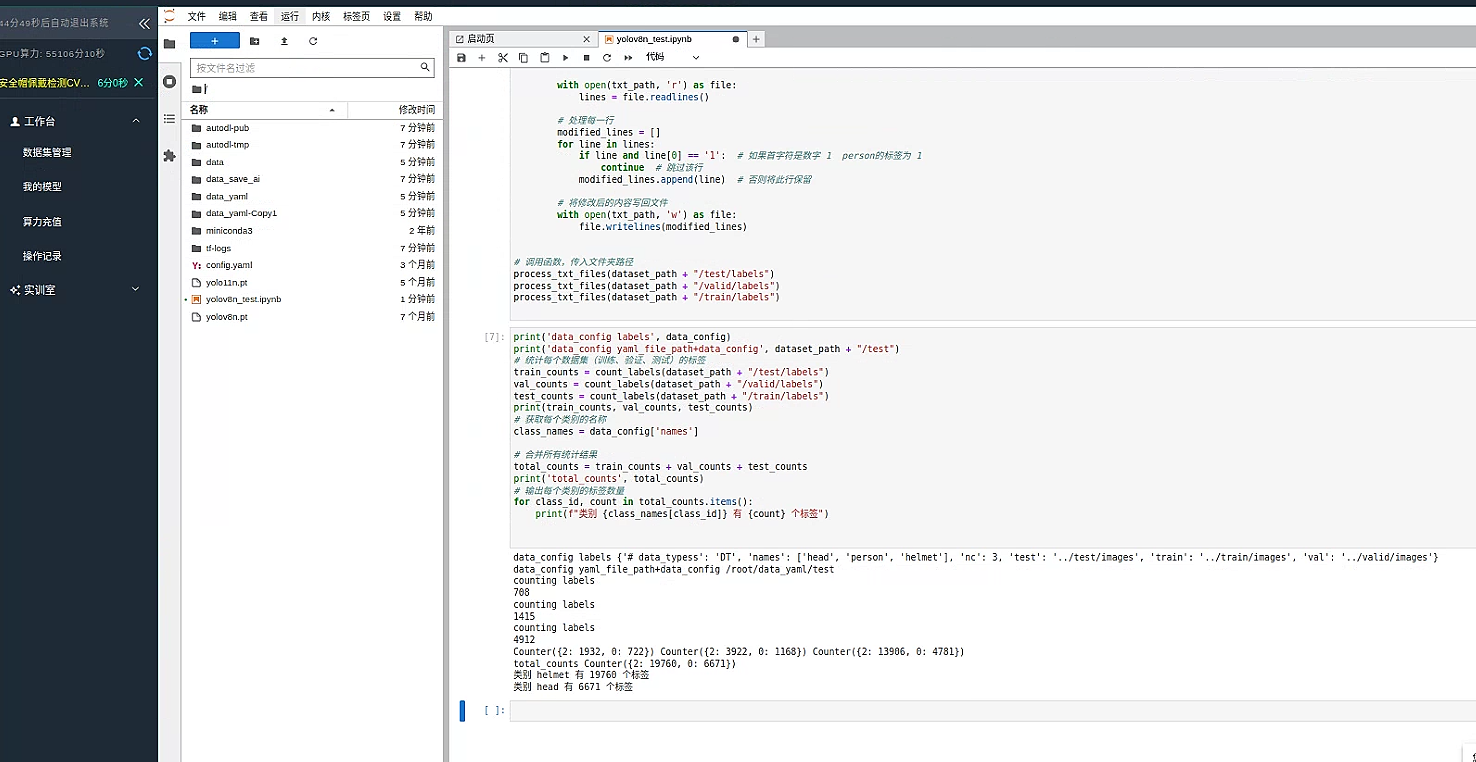
因为 helmet 的标签为 2 中间空出一个 标签 1 因此我们需要 将安全帽向前顺延一个
import os
def process_txt_files(folder_path):
# 获取文件夹内的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 遍历每个 txt 文件
for txt_file in txt_files:
txt_path = os.path.join(folder_path, txt_file)
with open(txt_path, 'r') as file:
lines = file.readlines()
# 处理每一行
modified_lines = []
for line in lines:
if line and line[0] == '2': # 如果首字符是数字 2
line = '1' + line[1:] # 将首字符修改为 1
modified_lines.append(line) # 保留该行
# 将修改后的内容写回文件
with open(txt_path, 'w') as file:
file.writelines(modified_lines)
# 调用函数,传入文件夹路径
process_txt_files(dataset_path + "/test/labels")
process_txt_files(dataset_path + "/valid/labels")
process_txt_files(dataset_path + "/train/labels")
最后我们 修改 data.yaml 文件 找到 /data_yaml 文件夹
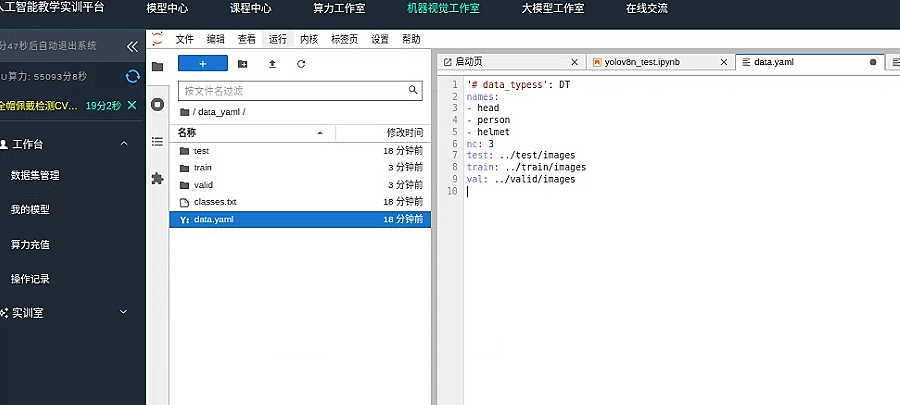
将其修改为 nc : 2 以及删去 person 标签
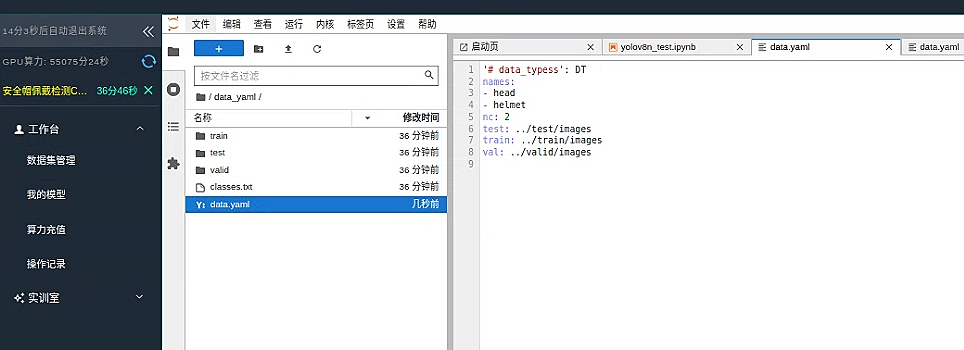
展示最后的数据集
# 加载数据集配置文件
with open(yaml_file_path, 'r') as file:
data_config = yaml.safe_load(file)
print('data_config labels', data_config)
print('data_config yaml_file_path+data_config', dataset_path + "/test")
# 统计每个数据集(训练、验证、测试)的标签
train_counts = count_labels(dataset_path + "/test/labels")
val_counts = count_labels(dataset_path + "/valid/labels")
test_counts = count_labels(dataset_path + "/train/labels")
print(train_counts, val_counts, test_counts)
# 获取每个类别的名称
class_names = data_config['names']
# 合并所有统计结果
total_counts = train_counts + val_counts + test_counts
print('total_counts', total_counts)
# 输出每个类别的标签数量
for class_id, count in total_counts.items():
print(f"类别 {class_names[class_id]} 有 {count} 个标签")
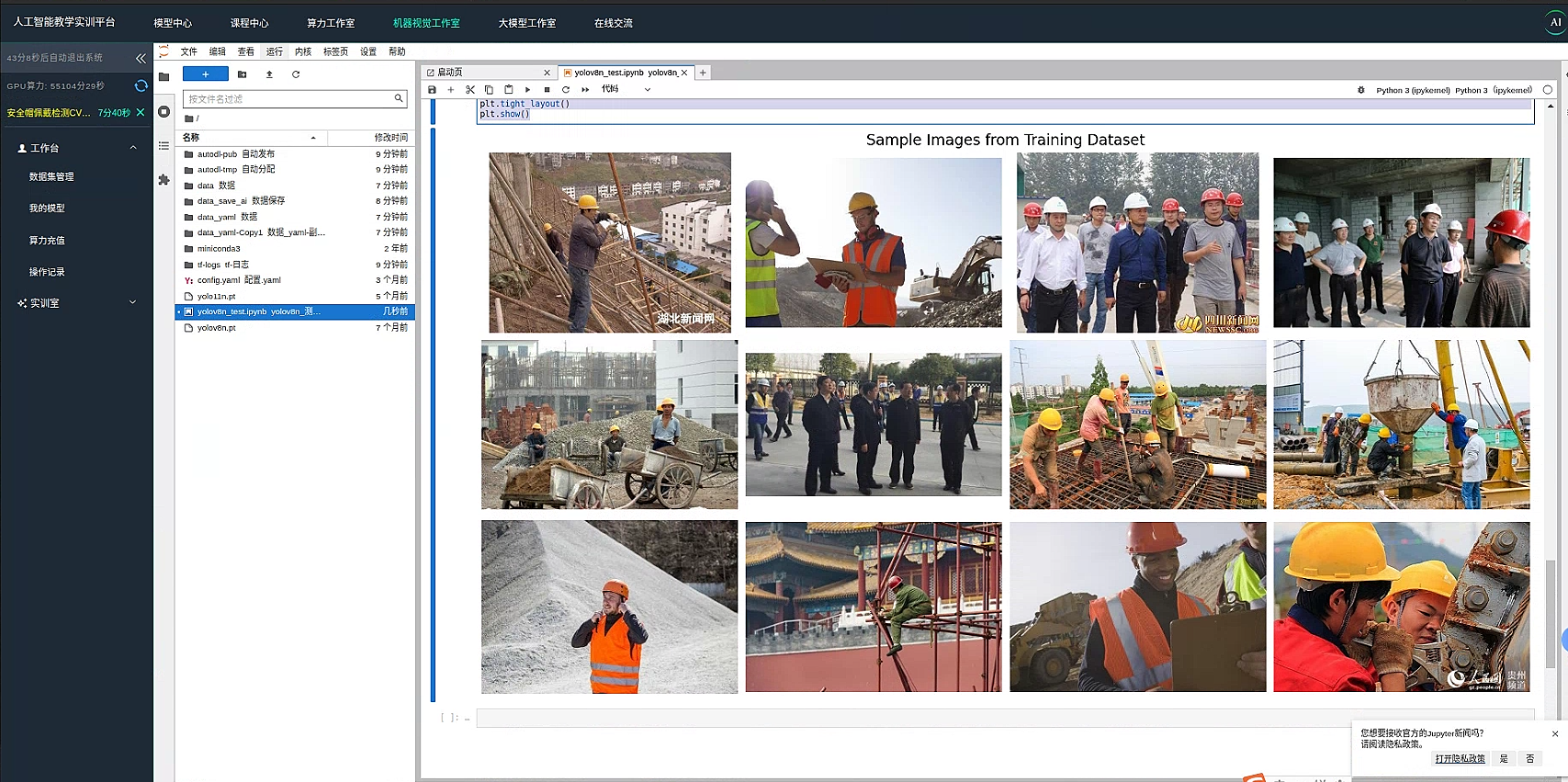
展示数据图片
我们使用 plt 展示一部分数据集确保数据图片正确读取
# List all jpg images in the directory
image_files = [file for file in os.listdir(train_images_path) if file.endswith('.jpg')]
# Select 8 images at equal intervals
num_images = len(image_files)
selected_images = [image_files[i] for i in range(0, num_images, num_images // 13)]
# Create a 2x4 subplot
fig, axes = plt.subplots(3, 4, figsize=(20, 11))
# Display each of the selected images
for ax, img_file in zip(axes.ravel(), selected_images):
img_path = os.path.join(train_images_path, img_file)
image = Image.open(img_path)
ax.imshow(image)
ax.axis('off')
plt.suptitle('Sample Images from Training Dataset', fontsize=20)
plt.tight_layout()
plt.show()
- 开始训练
- 设置训练参数
- 训练结果测试
开始训练
设置训练参数
读取 模型框架 yolo11s.yaml 并修改
创建一个 名为 yolo11s.yaml 文件然后粘贴这段配置
我们对 yaml 模型稍作修改满足我们的
# Ultralytics AGPL-3.0 License - https://ultralytics.com/license
# Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs
# Model docs: https://docs.ultralytics.com/models/yolo11
# Task docs: https://docs.ultralytics.com/tasks/detect
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
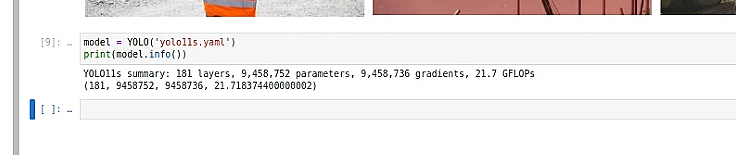
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- type: DynamicHead # 替换检测头
num_classes: 2 # 必须与data.yaml中的nc一致
in_channels: [256, 256, 256]
anchors: 3 # 每个尺度预测3个anchor
loss_cls:
- type: FocalLoss
alpha: [0.25, 0.75] # 反向补偿head类别的低样本量
loss_box: CIoU
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
neck:
- type: BiFPN # 修改特征金字塔
in_channels: [256, 512, 1024]
out_channels: 256
num_outs: 3
读取模型
model = YOLO('yolo11s.yaml')
print(model.info())
设置训练参数
results = model.train(
data=yaml_file_path,
epochs=100, #训练轮数
batch=40, #每次训练的样本数量
imgsz=800, #图片大小
device=0, #GPU
patience=15, # 当验证损失在15个epoch内没有改善时停止训练
optimizer='AdamW', #优化器
lr0=0.001, #学习率
dropout=0.0, #丢弃率
seed=42, #随机种子
erasing=0.4,#擦除率
degrees=15,#旋转角度
cache='ram',#缓存
pretrained=True, #预训练模型
hsv_h=0.015, # 降低色相变化幅度(反光材质敏感)
hsv_s=0.7, # 增强饱和度扰动(应对工地灰尘环境)
hsv_v=0.4, # 增强明度扰动(应对不同光照条件)
fliplr=0.5, # 提升水平翻转概率
mosaic=1.0, # 必须开启马赛克增强
mixup=0.2, # 启用混合样本
copy_paste=0.3, # 增强小目标密集场景
)
等待训练完成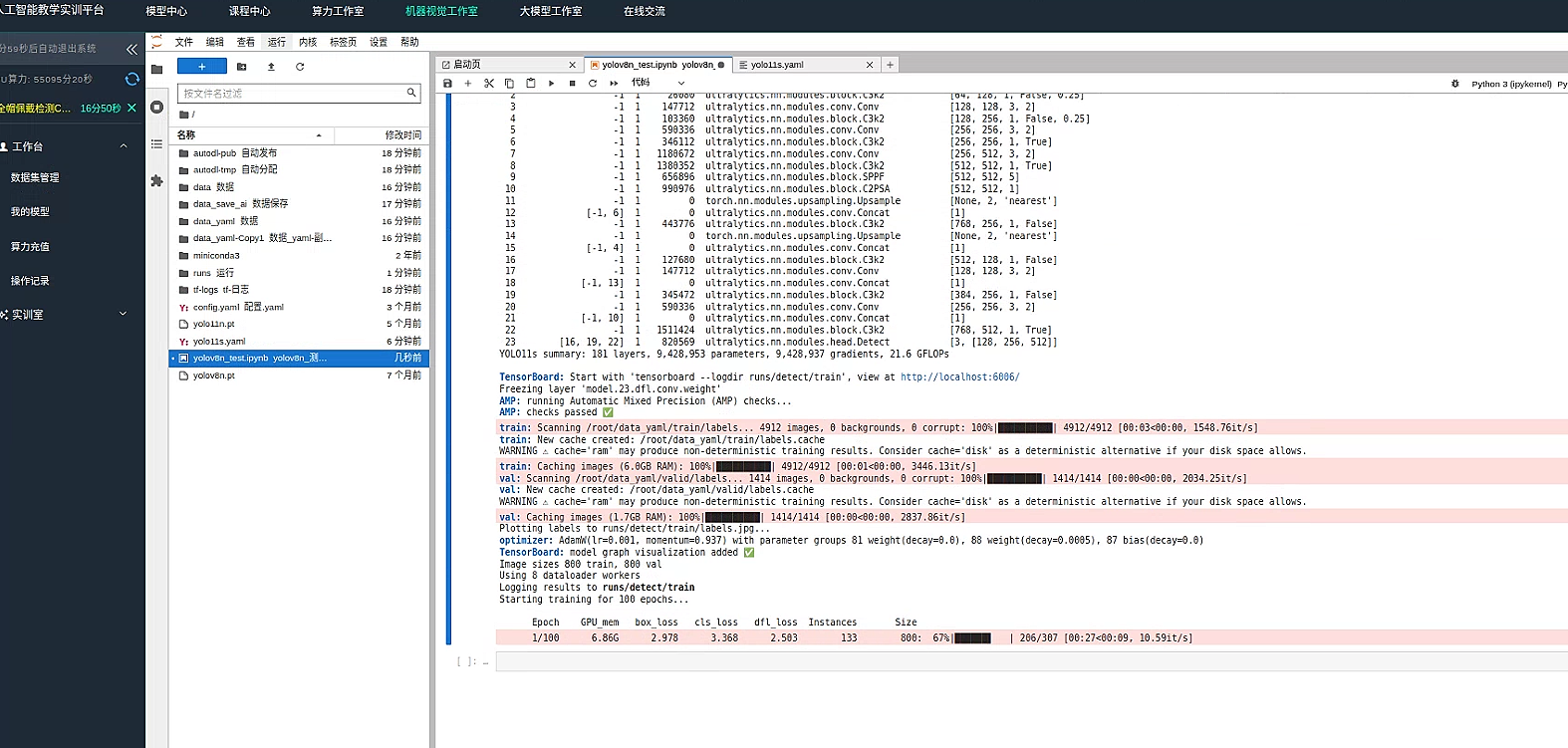
可以在 新建一个命令行 类似标签页一般 分屏使用 输入 gpustat -i 即可查看实时 GPU 使用量
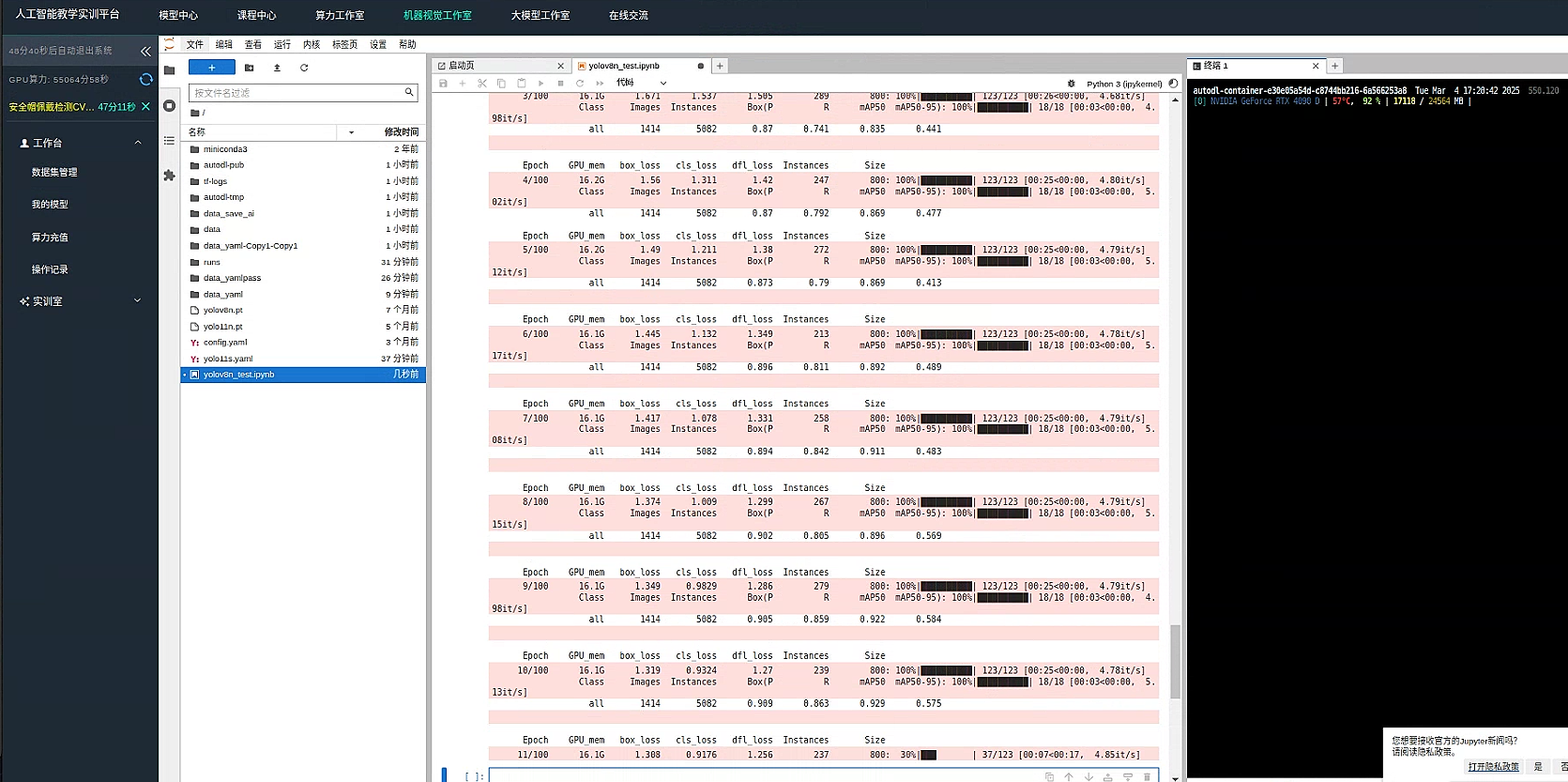
效率效果似乎还不错 整体来看,训练结果表现相当优秀,各项指标均较高:
- 检测准确性与召回率: 整体(all 类别)的精度为 0.942、召回率为 0.931,说明大部分目标都被正确检测到了,类别“head”和“helmet”的表现也相近,均有超过 90%的精度和召回率。
- mAP 指标: mAP50 达到 0.968,表明在较宽松的 IoU 阈值下,检测效果极佳;但 mAP50-95 为 0.674,说明在更严格的条件下仍有一定提升空间。
- 推理速度: 每张图片的推理时间约为 6.7ms,说明模型运行非常高效。
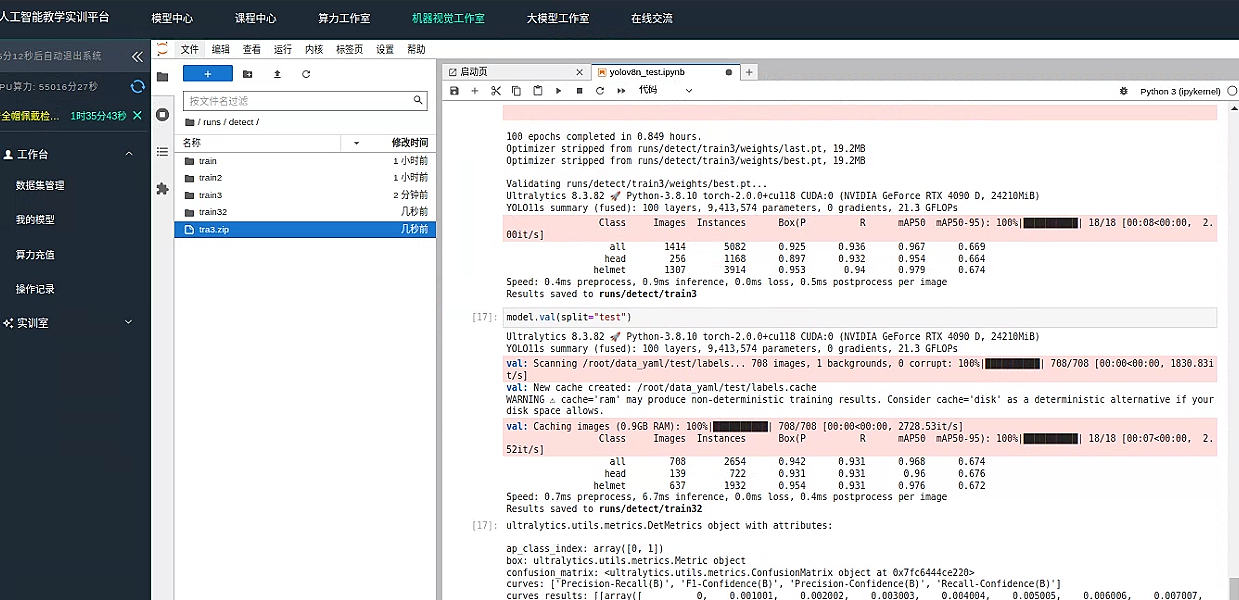
自此 安全帽佩戴检测模型训练项目结束了。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)