
蓝桥杯人工智能赛-日志记录
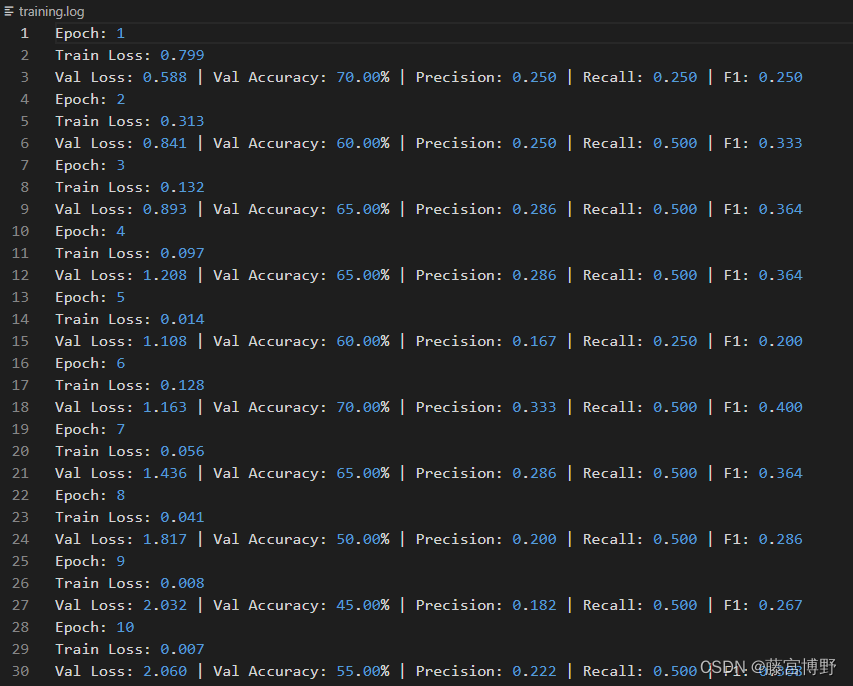
题目只要求完善函数即可,老样子,对给出的示例处理代码进行学习。处理后的结果如下所示。
·

题目只要求完善函数即可,老样子,对给出的示例处理代码进行学习。
#task-start
import pickle
import random
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset, random_split
from tqdm import trange
import warnings
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
import logging
warnings.filterwarnings("ignore")
SEED = 42
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
np.random.seed(SEED)
random.seed(SEED)
torch.backends.cudnn.deterministic = True # 这里就是把CUDA、random以及一系列的随机种子给固定,便于复现,一般直接调用就可以
class TextClassifier(nn.Module):
def __init__(self, vocab_size=1000, embed_dim=128, nhead=4, num_encoder_layers=2, num_classes=2):
super(TextClassifier, self).__init__()
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.transformer_encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model=embed_dim, nhead=nhead),
num_layers=num_encoder_layers
) # 从torch内部调用了一个Transformer Encoder
self.fc = nn.Linear(embed_dim, num_classes) # 分类全连接层
def forward(self, text):
embedded = self.embedding(text)
transformer_output = self.transformer_encoder(embedded)
output = self.fc(transformer_output[0])
return output
def get_data_loaders():
data, labels = pickle.load(open('text_classify_training_data.pkl', 'rb'))
dataset = TensorDataset(data, labels)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size]) # 这里用到了一个Tensor dataset和random split, 数据集
# 建议是自己写一个类去管控,这样代码等都有更大的调整空间。。。 random_split是一个分割数据集为训练和验证用的函数
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=32)
return train_loader, val_loader
def train(model, iterator, criterion, optimizer):
model.train()
total_loss = 0
for text, label in iterator: # 介绍一下通用的训练流程
optimizer.zero_grad() # 开始训练之前清空优化器中的梯度
outputs = model(text.transpose(0, 1)) # 预测
loss = criterion(outputs, label) # 监督学习的损失优化
loss.backward() # 损失反向传播
optimizer.step() # 优化器更新权重参数
total_loss += loss.item() # 注意,取出损失值需要用到item
return total_loss / len(iterator)
def evaluate(model, iterator, criterion):
model.eval()
total_loss = 0
predicted_labels = []
true_labels = [] # 记录Ground Truth以及预测标签
with torch.no_grad():
for text, label in iterator:
outputs = model(text.transpose(0, 1))
loss = criterion(outputs, label)
total_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
predicted_labels.extend(predicted.tolist())
true_labels.extend(label.tolist())
accuracy = accuracy_score(true_labels, predicted_labels) # 直接调用Sklearn的包计算
precision = precision_score(true_labels, predicted_labels)
recall = recall_score(true_labels, predicted_labels)
f1 = f1_score(true_labels, predicted_labels)
return total_loss / len(iterator), accuracy, precision, recall, f1
def run():
model = TextClassifier()
train_loader, val_loader = get_data_loaders()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
logging.basicConfig(filename='training.log', level=logging.INFO, format='%(message)s')
NUM_EPOCHS = 10
for epoch in trange(NUM_EPOCHS):
train_loss = train(model, train_loader, criterion, optimizer)
val_loss, val_accuracy, precision, recall, f1 = evaluate(model, val_loader, criterion)
logging.info(f"Epoch: {epoch+1}\nTrain Loss: {train_loss:.3f}\n"
f"Val Loss: {val_loss:.3f} | Val Accuracy: {val_accuracy * 100:.2f}% | Precision: {precision:.3f} | Recall: {recall:.3f} | F1: {f1:.3f}")
torch.save(model.state_dict(), 'model.pt')
if __name__ == '__main__':
run()
#task-end处理后的结果如下所示

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)