AI训练师人工智能客服之训练自己的数据集
然后将自己的xlx.json和dataset_info.json文件拖到自己服务器底下的LLaMA。找到dataset_info.json文件配置自己的训练集。
·
选择数据集
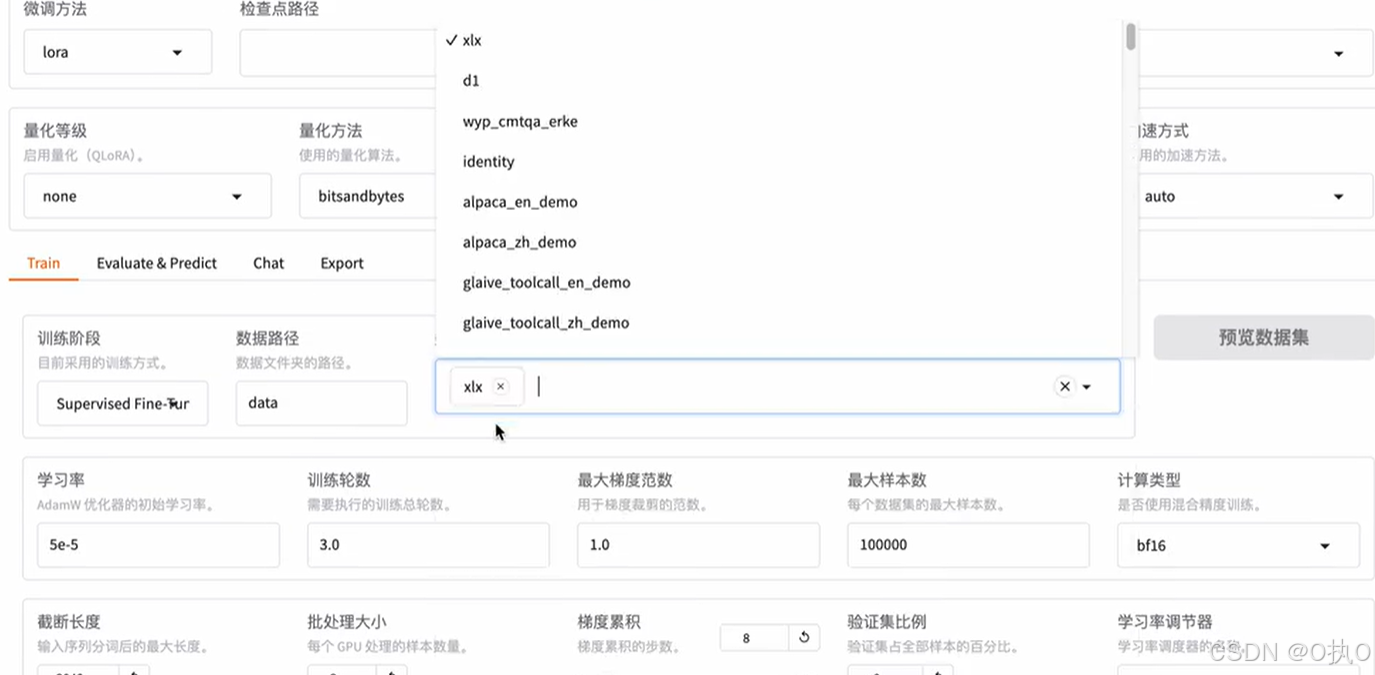
找到dataset_info.json文件配置自己的训练集
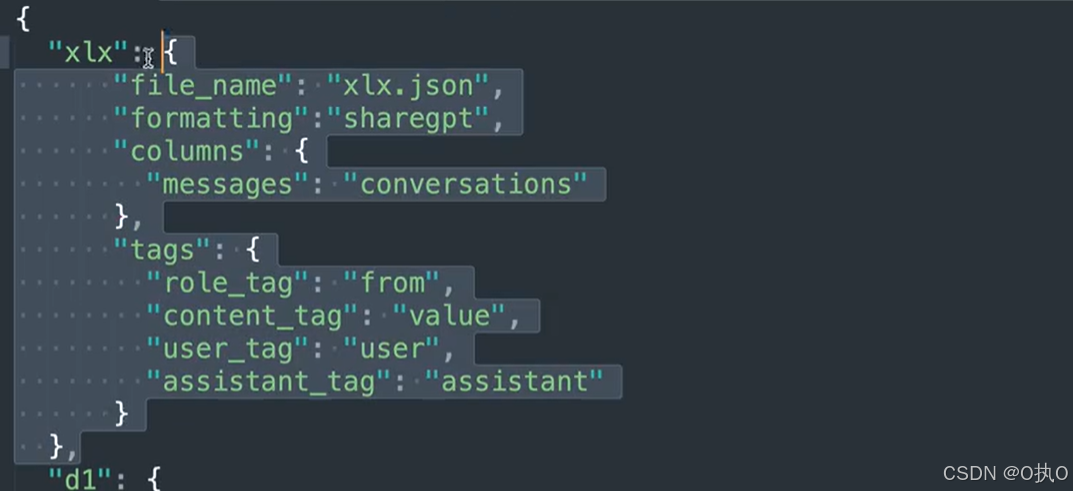
然后将自己的xlx.json和dataset_info.json文件拖到自己服务器底下的LLaMA
两种数据格式
Alpaca格式
指令监督微调数据集
instruction:用户输入的指令
input:用户输入的内容
output:模型回复的内容
备注:最终会把instruction、input、output进行合并
1、指令监督微调数据集(单轮)
{
"instruction":"P4班",
"input":"多少钱?",
"output":"100元"
}
最终用户提问的是:P4班多少钱?
模型回答是:多少钱?
当然数据集也可以这样写:
{
"instruction":"P4班多少钱?",
"input":"",
"output":"100元"
}
数据集格式:
//demo.json
ShareGPT格式
参数说明:
human:用户输入的问题
gpt:模型回复的问题
observation:对话中观察或外部事件
function:外部函数或API调用生成的内容
把准备好的数据集,添加到dataset_info.json中
通过PyCharm也好、其它编辑器也好,复制、粘贴过来,起个名字
xlx.json(json格式)
需要把dataset_info.json、xlx.json这两个文件,
拖到服务器里面的LLaMA-Factory-main、data
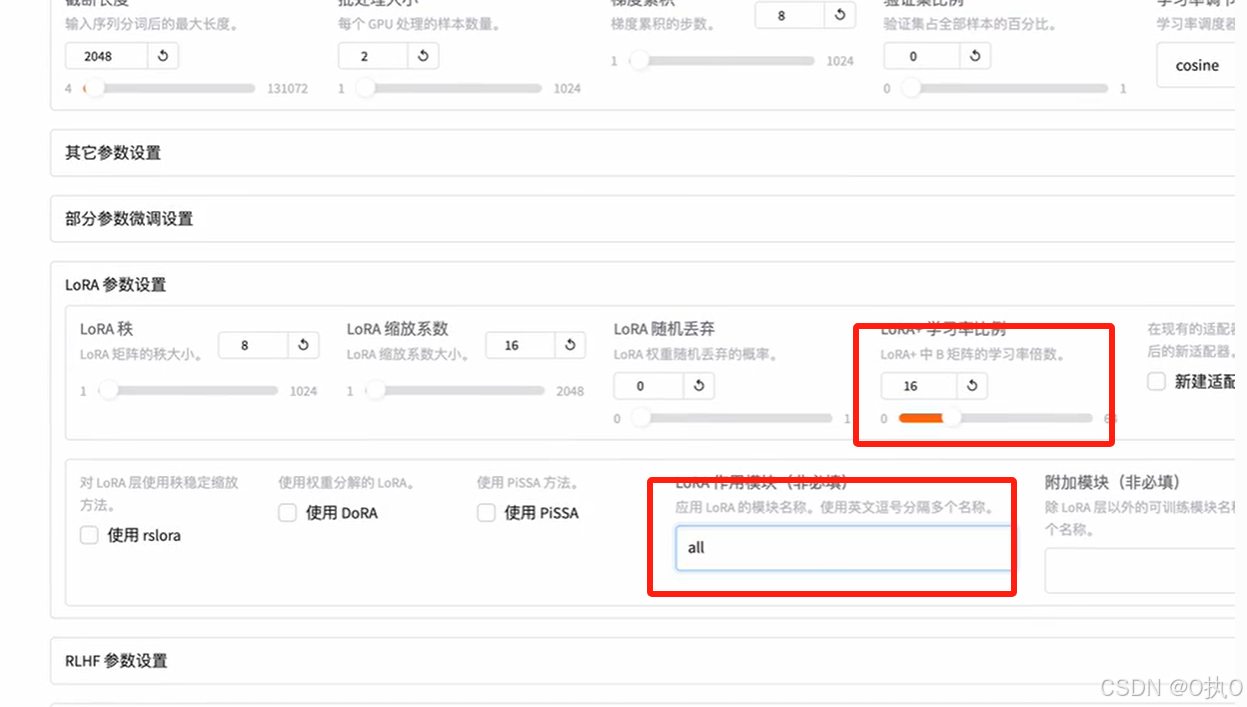
LoRA参数设置:
LoRA学习率比例:16
LoRA作用模块(非必填):all
输出目录:train_13(根据实际情况填写)
点击‘预览命令’、‘开始’,开始训练模型
当训练完毕后,在‘检查点路径’,选择‘输出目录’,点击‘加载模型’
此时就可以,进行问答测试了

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)