
毕业设计-基于深度学习的道路交通标志目标检测算法系统 YOLO python 卷积神经网络 人工智能
毕业设计-基于深度学习的道路交通标志目标检测算法系统的毕业设计。该系统旨在利用深度学习技术,自动化地检测和识别道路交通标志,提高交通安全和智能化交通管理水平。我们采用了预训练的 Faster R-CNN 模型作为基础,通过使用大规模的道路交通标志数据集进行模型训练和优化,实现了高准确性和高效率的目标检测。该系统能够快速准确地识别道路交通标志,并输出其位置和类别信息,为交通管理部门和驾驶员提供准确的
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的道路交通标志目标检测算法系统

设计思路
一、课题背景与意义
随着深度学习和目标检测算法的兴起,自动驾驶技术和车载设备智能化得以快速发展.很多车载设备中的智能驾驶辅助系统依赖相机与目标检测算法相结合,通过识别交通标志、信号灯和周围车辆等路况关键信息,为车辆提供安全警示等功能,使得驾驶员的安全性得到极大保障“.交通标志目标检测算法更关注远处微小交通标志的识别准确率问题,以保证搭载此辅助系统的车辆在行驶中能够提前发现远处交通标志.及时做出警示,对保障交通安全有着重要意义.
二、算法理论原理
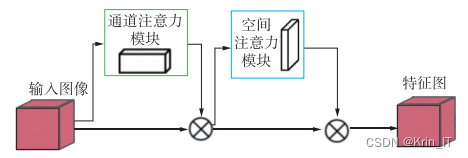
2.1 注意力机制
SA 可有效将两者结合并避免计算负担",将特征图沿通道分割为多个子特征图分支,并行计算各分支,再通过 Shuffle 单元来提取各分支间的特征依赖关系.然后,对所有分支进行融合,通过通道Shuffle 算子使每个分支的特征信息沿通道跨分支流动与合并。
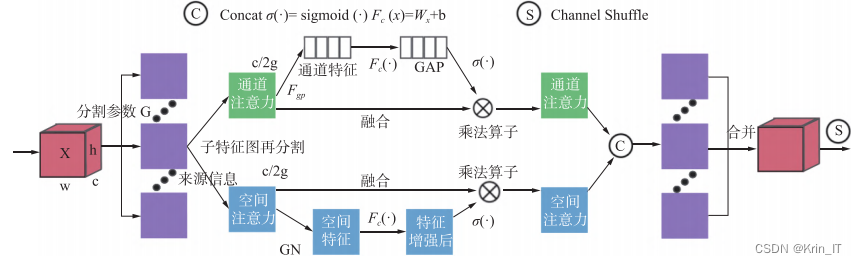
CBAM能够沿通道和空间顺序生成注意力区域,两者同属于轻量级的注意力模块.而两者的区别在于,SA 是将通道注意力与空间注意力进行并行运算CBAM 是顺序运算,由于 SA 具有较快的计算速度更适合应用在特征提取更集中的 Backbone中,而 Neck 中主要进行上下采样和不同特征图间拼接,在此部分生成注意力区域时,更注重结构较为简单的注意力顺序运算。
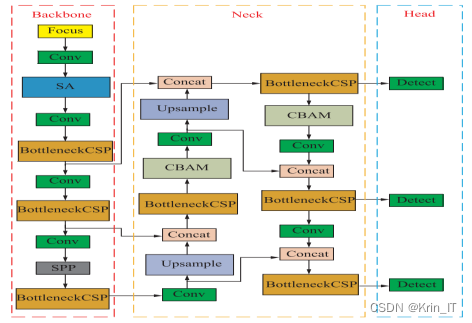
2.2 YOLOv5算法
对于远处交通标志被遮挡、距离过远像素不够清晰的情况对原网络结构中替换第一个 BottleneckCSP模块为 SA 模块,可以立即提取二倍下采样特征图中的特征信息,弱化原始输入图像中的干扰,CBAM 在Neck 中依据 Backbone 的特征图再次加强注意力区域.而对于 Head 的三个不同尺度的特征图,因为感受野的缘故,前两个 Head 对微小物体更敏感,因此放置两个CBAM在前两个Head 分支中。
相关代码:
model = faster_rcnn.mobilenet_v2(pretrained=True)
model = model.cuda() # 将模型移动到GPU(如果可用)
# 定义优化器和损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
criterion = YourCustomLossFunction() # 自定义损失函数,需根据目标检测任务的特点进行实现
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for images, targets in dataloader:
images = images.cuda()
targets = [target.cuda() for target in targets]
# 前向传播
outputs = model(images, targets)
loss = criterion(outputs, targets)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}")
# 保存训练好的模型
torch.save(model.state_dict(), 'path_to_save_model.pth')三、检测的实现
3.1 数据集
禁止、警告标志,通过对数据清洗,剔除、修改有问题的图片或标注,确定最终的数据集中一共 13 829 张图片.对原数据集的标注信息进行处理生成PASCALVOC标准标注格式,并按照图片尺寸缩放坐标,使其归一化,对训练集中的图片随机划分,80% 作为训练集,20%作为验证集,送入网络中训练。

3.2 实验环境搭建
该实验软件环境包括 Pytorch1.10.0、CUDA11.3以及编程语言采用python3.8.硬件环境:CPU为AMD EPYC 7543,内存32 GB,GPU为NVIDIA RTX A5000,显存 24 GB。
3.3 实验及结果分析
训练时的总损失曲线.:
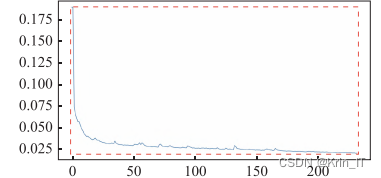
在两种注意力模型的对比中速度有所减弱却依然能够满足相机 FPS实时检测的基本要求SA-YOLOv5 在 Backbone 中合理嵌人了 SA模块并结合 CBAM 在 Neck 中优异的性能,比只用CBAM一种注意力模块的 CBAM-YOLOv5 提高了1.7%的检测精度综合来看,SA-YOLOv5 可以完全胜任交通标志目标检测任务

相关代码如下:
# 图像预处理
transform = transforms.Compose([
transforms.ToTensor(),
])
# 加载图像
image_path = 'path_to_image.jpg' # 输入图像路径
image = Image.open(image_path)
image_tensor = transform(image)
# 将图像转移到GPU(如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
image_tensor = image_tensor.to(device)
# 运行图像通过模型
outputs = model([image_tensor])
# 解析输出
boxes = outputs[0]['boxes']
scores = outputs[0]['scores']
labels = outputs[0]['labels']
# 设置阈值来筛选道路交通标志
threshold = 0.5
traffic_sign_boxes = []
for box, score, label in zip(boxes, scores, labels):
if score > threshold and label == 2: # 假设道路交通标志的标签为2
traffic_sign_boxes.append(box)
# 打印检测结果
for box in traffic_sign_boxes:
print('Traffic sign box coordinates:', box.tolist())实现效果图样例
创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)