
山东大学软件学院_人工智能导论期末复习
山东大学软件学院人工智能导论期末复习
人工智能导论期末
byJingYang,仅用作学弟学妹复习参考,禁止一切资料买卖行为。笔者在此门考试中取得了98的成绩,因此这门课是一门只要你掌握知识就能取得好成绩的课程。希望对大家有所帮助。
-
蚁群算法
-
蚂蚁觅食行为的启发
在自然界中,蚂蚁寻找食物的路径并不是直接的,而是通过以下步骤逐渐优化:
- 蚂蚁会释放一种化学物质,称为信息素(Pheromone),来标记路径。
- 蚂蚁选择路径时,会更倾向于选择信息素浓度高的路径。
- 随着时间推移,信息素会逐渐挥发(衰减)。
- 最终,蚂蚁群体趋于选择一条最优路径。
蚁群算法正是模拟这种自组织行为,通过信息素的积累和挥发,解决优化问题。
-
蚁群算法的核心思想
蚁群算法通过一群人工蚂蚁协同工作,不断寻找问题的解,最终收敛于最优解。其核心机制包括:
- 信息素更新:
- 信息素增强:蚂蚁走过路径后,会在路径上增加一定量的信息素。
- 信息素挥发:为了防止信息素无限累积,避免陷入局部最优,信息素会随时间衰减。
- 启发式信息: 蚂蚁选择路径时,不仅依赖于信息素浓度,还需要结合启发式信息(如路径长度或成本)。
- 随机概率选择: 每只蚂蚁根据路径的综合吸引力(信息素浓度和启发式信息)随机选择下一步路径。
- 信息素更新:
-
蚁群算法的实现步骤
-
初始化:
- 设置初始信息素值。
- 定义蚂蚁数量、迭代次数、信息素挥发因子、启发式因子等参数。
-
路径构建:
-
每只蚂蚁从起点出发,依次选择下一步路径,直到形成完整解。
-
路径选择的概率公式:
P i j = τ i j α ⋅ η i j β ∑ k ∈ allowed τ i j α ⋅ η i j β P_{ij} = \frac{\tau_{ij}^{\alpha}\cdot\eta_{ij}^{\beta}}{\sum_{k \in \text{allowed}} \tau_{ij}^{\alpha}\cdot\eta_{ij}^{\beta}} Pij=∑k∈allowedτijα⋅ηijβτijα⋅ηijβ- P i j P_{ij} Pij: 从节点 iii 到 jjj 的选择概率。
- τ i j \tau_{ij} τij: 路径上的信息素浓度。
- η i j \eta_{ij} ηij: 启发式信息(如路径的吸引力,通常为距离的倒数)。
- α,β: 权重因子,分别控制信息素和启发式信息的重要性。
-
-
信息素更新:
-
对每只蚂蚁的路径进行信息素增强:
τ i j ← ( 1 − ρ ) ⋅ τ i j + ∑ 蚂蚁 Δ τ i j \tau_{ij} \gets (1-\rho ) \cdot \tau_{ij} + \sum_{\text{蚂蚁}} \Delta \tau_{ij} τij←(1−ρ)⋅τij+蚂蚁∑Δτij
- ρ \rho ρ: 信息素挥发因子。
- Δ τ i j \Delta \tau_{ij} Δτij: 蚂蚁走过路径时增加的信息素量,通常与路径长度成反比。
-
-
迭代优化:
- 重复路径构建和信息素更新过程,逐步优化解。
-
终止条件:
- 达到最大迭代次数或信息素分布稳定。
-
-
-
粒子群算法
粒子群优化算法(PSO)可以理解为一群“会飞的鸟”在寻找食物的过程。每只鸟代表一个粒子,它们飞过一个“搜索空间”(可能的解空间),通过合作和竞争最终找到最优解(即食物所在的位置)。
- 粒子、速度和位置
-
粒子的位置:代表一个可能的解,比如
X i = ( x i 1 , x i 2 , . . . , x i D ) X_i = (x_{i1},x_{i2},...,x_{iD}) Xi=(xi1,xi2,...,xiD)
每个粒子有自己的坐标位置,就像鸟在天空中的位置。 -
粒子的速度:代表它飞行的方向和快慢,比如
V i = ( v i 1 , v i 2 , . . . , v i D ) V_i = (v_{i1},v_{i2},...,v_{iD}) Vi=(vi1,vi2,...,viD)
速度决定了粒子下一步会飞到哪里。
- 目标
粒子的目标是找到“食物”,即问题的最优解。每个粒子需要决定下一步怎么飞,这取决于两个因素:
- 自己过去找到过的最佳位置( p b e s t p_{best} pbest)。
- 整个群体(或者邻居)找到过的最佳位置( g b e s t g_{best} gbest)。
- 速度更新公式
速度的更新公式:
v i d = w ∗ v i d − 1 + c 1 ∗ r 1 ∗ ( p i d − x i d ) + c 2 ∗ r 2 ∗ ( p g d − x i d ) v_{id}=w*v_{id-1}+c_1*r_1*(p_{id}-x_{id})+c_2*r_2*(p_{gd}-x_{id}) vid=w∗vid−1+c1∗r1∗(pid−xid)+c2∗r2∗(pgd−xid)
可以分成三部分:
- 惯性部分 w ∗ v i d − 1 w*v_{id-1} w∗vid−1:
-
反映粒子的“惯性思维”。
-
表示粒子想保持原来的飞行方向和速度(类似惯性)。
-
惯性权重 w决定了这种惯性有多强:
- w 较大时,粒子更倾向于探索更远的地方(全局搜索)。
- w 较小时,粒子更倾向于精细地搜索附近(局部搜索)。
-
认知部分 c 1 ∗ r 1 ∗ ( p i d − x i d ) c_1*r_1*(p_{id}-x_{id}) c1∗r1∗(pid−xid):
- 反映粒子的“自我学习”能力。
- 粒子会根据自己找到的历史最优位置( p b e s t p_{best} pbest)调整飞行方向。
-
社会部分 c 2 ∗ r 2 ∗ ( p g d − x i d ) c_2*r_2*(p_{gd}-x_{id}) c2∗r2∗(pgd−xid):
- 反映粒子的“社会学习”能力。
- 粒子会向群体找到的最佳位置( g b e s t g_{best} gbest)靠拢,表现为跟随“领头鸟”的策略。
- 位置更新公式
位置的更新公式:
x i d + 1 = x i d + v i d x_{id+1}=x_{id}+v_{id} xid+1=xid+vid
简单理解就是:
- 下一步的位置 = 当前的位置 + 当前的速度。
例如,鸟在当前位置往某个方向飞了一段距离,它的新位置就是飞行后的终点。
- 粒子的协作
- 每只粒子会记住自己过去找到的最佳位置,并尝试靠近这个位置。
- 同时,每只粒子会关注整个群体(或邻居)找到的最佳位置,向这个位置靠近。
- 在不断的调整中,所有粒子逐渐收敛到一个最优解。
- 参数的作用
- 惯性权重 w:
- w 大时,粒子飞得更远,探索新区域(全局搜索)。
- w 小时,粒子在局部精确搜索(局部搜索)。
- 学习因子 c1,c2:
- c1 影响自我学习的重要性。
- c2 影响群体学习的重要性。
- 通常 c1=c2=2 是推荐值,平衡个体探索和群体合作。
- 随机数 r1,r2:
- 引入随机性,让粒子不总是按照固定路径飞行,从而避免陷入局部最优。
-
通俗总结
-
粒子群优化算法就像一群寻找食物的鸟。
-
每只鸟飞行时会记住自己的最佳位置( p b e s t p_{best} pbest),同时也会跟随群体的最佳位置( g b e s t g_{best} gbest)。
-
它们的速度由惯性、自我调整和群体学习共同决定,最终逐步靠近最优解(找到食物)。
历年题整理(重复的往年题不再列出)
23年
名词解释
-
数据挖掘
-
答:数据挖掘(DM)是指从数据库中挖掘知识
-
eg:知识发现是指从数据库中发现知识
-
-
不确定性推理方法
-
答:从不确定性的初始证据出发,通过运用不确定性的知识,最终推出具有一定程度的不确定性但却是合理或者近乎合理的结论的思维过程。
-
eg:推理:从已知事实(证据)出发,通过运用相关知识逐步推出结论或者证明某个假设成立或不成立的思维过程。
-
-
专家系统:
- 答:专家系统是一种智能的计算机程序,它运用知识和推理来解决只有专家才能解决的复杂问题
-
状态空间法:
- 答:

- 答:
-
深度学习
- 答:指基于深层神经网络模型和方法的机器学习
简答题
- 简述证据理论中的似然函数与信任函数的区别与联系

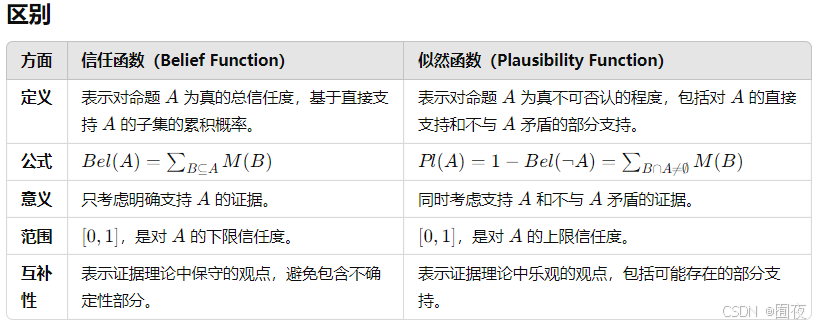
-
简述卷积神经网络的卷积层和池化层的基本思想
- 卷积:卷积层通过可训练的卷积核对输入数据进行卷积操作,提取其中的局部特征。局部连接和权值共享。
- 池化(pooling):池化层用于对特征映射进行降维,通过聚合局部特征来保留关键信息,同时减小计算复杂度
-
简述BP神经网络的学习过程


-
简述遗传算法的基本思想
- 在求解问题时从多个解开始,然后通过一定的法则进行逐步迭代以产生新的
解。 - 初始种群→计算适应度→选择/交叉/变异→下一代
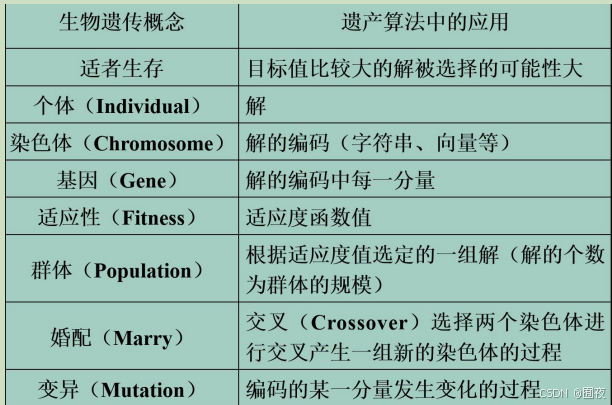
- 在求解问题时从多个解开始,然后通过一定的法则进行逐步迭代以产生新的
-
画出专家系统的一般结构,并解释其核心部件
-
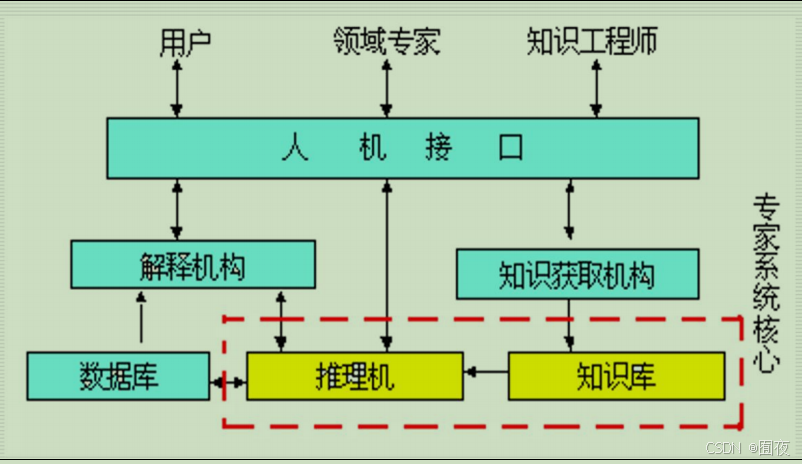
-
核心部件:
- 知识库主要用来存放领域专家提供的有关问题求解的专门知识
- 推理机的功能是模拟领域专家的思维过程,控制并执行对问题的求解
-
问答题
-
用一阶谓词公式表示下列关系(谓词逻辑公式) (5分*3 = 15分)
(1)老李的儿子是教师
Teacher(son(Li)) (个体是函数)
(2)Smith作为一名工程师在IBM工作
Works (engineer (Smith), IBM) (二阶谓词,个体是谓词)
(3)小明会打篮球或踢足球
Plays (Xiaoming, basketball) ∨ Plays (Xiaoming, football) -
任何人的兄弟不可能是女生
任何人的姐妹必然是女生
前提事实:mary和bill是姐妹
证明:mary不可能是tom的兄弟.(10分)
-

-
注意,使用归结原理对子句进行归结时,要注意变元名称的替换,这样最后才能对的上。并且在后续的ANSWER求解时,严格注意变元名称的替换,最后才能得到正确结果。
-
求解步骤:

-
-
八数码问题,要求给出A搜索树的流程图,并给出最短路径(最优选择路径) 启发式策略为:h ( n )表示与目的状态不符的数码数目.(15分)
- 你应当熟悉书上133至134页
- 注意,对于启发策略的书上描述是””不在位“的数码数“,因此我们找出在位的数码数,用8减掉即可得到。
- 注意,往下延伸子树的时候,不要把返回上一状态的也画出来了。
- 注意,open表放的是已发现待搜索的状态,要根据代价大小对状态进行重排(启发式搜索需要重排open表),代价小的放前面。
- 说明哪种是A*算法:
- w(n) = h(n) ,表示与目的状态不符的数码数目。
- w(n) = p(n) ,表示各数码移到目的位置所需的移动距离的总和。
- 答:

-
简述人工智能的研究领域和发展前景。
-
研究领域:
- 自动定理证明、博弈、模式识别、机器视觉、自然语言理解、智能信息检索、数据挖掘与知识发现、专家系统、自动程序设计、机器人、组合优化问题、人工神经网络、分布式人工智能与多智能体、智能控制、智能仿真、智能CAD、智能CAI、智能管理与智能决策、智能多媒体系统、智能操作系统、智能计算机系统、智能通信、智能网络系统、人工生命。(书上第一章,我觉得只要记住全书每一章对应的那个领域和一些主流领域即可)
-
研究的基本内容:
- 知识表示
- 机器感知
- 机器思维
- 机器学习
- 机器行为
-
发展前景: 人工智能将在自动驾驶、医疗、金融等领域持续发展。随着深度学习和强化学习的进步,AI将在处理复杂任务和大数据分析上发挥更大作用。同时,伦理问题和安全性问题将成为未来研究的重点。(非书上)
-
20
名词解释
-
演绎推理
-
来自3.1.2,演绎推理是从全称判断推导出单称判断的过程,即由一般性知识推出适合于某一具体情况的结论。这是一种由一般到个别的推理。
-
从一组已知为真的事实出发,直接运用经典逻辑的推理规则推出结论的过程称为自然演绎推理。其中,基本的推理规则是P规则,T规则,假言推理,拒取式推理等 -
规则:
-
P规则
在推理的任何步骤上都可引入前提。
-
T规则
在推理过程中,如果前面步骤中有一个或多个公式永真蕴含公式S,则可
把S引入推理过程中。 -
CP规则:
如果能从任意引入的命题R和前提集合中推出S来,则可从前提集合推出
R → S来。 -
反证法
-
假言推理:通过两个假言命题推导出新的假言命题。
p→q,q→r,推导出 p→r。
-
拒取式推理:逻辑谬误,错误地通过否定前件来推导否定后件。
p→q,¬p,推导出 ¬q(错误)。
-
-
-
智能计算
- 受自然界和生物界规律的启迪,人们根据其原理模仿设计了许多求解问题的算法,包括人工神经网络、模糊逻辑、遗传算法等,这些算法称为智能计算,也称为计算智能。
-
启发式搜索
- 考虑特定问题领域可应用的知识,动态地确定调用操作算子的步骤,优先选择较适合的操作算子,尽量减少不必要的搜索,以求尽快地到达结束状态。(利用启发信息的搜索过程)
- 对比:盲目搜索:在不具有对特定问题的任何有关信息的条件下,按固定的步骤(依次或随机调用操作算子)进行的搜索。
-
前束范式
- 所有的量词(∀、∃)都位于公式的最前面。
- 应该对应课本上化为子句集中的”化为前束形“步骤
简答题
-
模糊推理中模糊关系的合成有哪些方法?
-
简述产生式系统的工作过程。
(1)从规则库中选择与综合数据库中的已知事实进行匹配。
(2)匹配成功的规则可能不止一条,进行冲突消解。
(3)执行某一规则时,如果其右部是一个或多个结论,则把这些结论加入到综合数据库中:如果其右部是一个或多个操作,则执行这些操作。
(4)对于不确定性知识,在执行每一条规则时还要按一定的算法计算结论的不确定性。
(5)检查综合数据库中是否包含了最终结论,决定是否停止系统的运行。
-
简述Agent合同网的协商过程。
- 不在考试范围

问答题
-
用一阶谓词公式表示下列关系
-
有一个人是所有人的经理。
∃x∀y Manager(x,y)
-
某些人对食物过敏。
∃x Allergy(x,food)
-
喜欢读《红楼梦》的人,一定喜欢读《京华烟云》。
∀x (Likes(x,“红楼梦”)→Likes(x,“京华烟云”))
-
有些大学生运动员是国家选手。
∃x(StudentAthlete(x)∧NationalPlayer(x))
-
不是每个软件学院的学生喜欢在开发板上编程。
¬∀x (Student(x)∧From(x,“软件学院”)→LikesProgramming(x,“开发板”))
-
-
假设所有通过计算机考试并获奖的人是快乐的,假设所有肯学习的或幸运的都能通过所有考试,小张不肯学习但是幸运的,任何幸运的人都能获奖。运用归结原理证明:小张是快乐的。
-

-
这题提示我们,在归结中有些子句可以用多次,有些可以一次不用。如果你归结不出来,先试着自己根据题目条件推出结论,按照推导步骤归结即可。这还启发我们,不要眼高手低,有些题目不做你永远不知道会碰到什么问题
-
21
名词解释
-
知识发现
从数据库中发现知识
-
双倍体遗传算法
是一种基于遗传算法的优化算法,采用显性隐性两个染色体同时进行进化
简答题
-
人工智能的发展经历了哪几个阶段,分别有什么特点
-
孕育阶段(1956年前)
特点:
- 这一阶段并非人工智能的正式诞生期,但为人工智能的诞生奠定了理论和技术基础。人类自古以来就尝试通过各种机械装置来替代或增强人类的脑力劳动。
- 古代的自动机械、算盘、逻辑学、图灵机等思想和发明都对后来的人工智能产生了影响。
- 重要事件:
- 图灵机(Turing Machine):艾伦·图灵提出的“图灵机”理论(1936年)为后来的计算机科学和人工智能奠定了基础。
- 图灵测试(Turing Test):图灵在1950年提出的“图灵测试”作为判断机器是否具备智能的标准,也为人工智能研究提供了理论框架。
-
形成阶段(1956-1969)
特点:
-
这一阶段人工智能的概念逐渐成形,学术界开始关注和讨论机器能否具有类似人类的智能。
-
1956年,人工智能正式命名,并成为一个研究领域。该阶段是人工智能的萌芽期,学术界和研究机构纷纷投入到人工智能的探索之中。
-
重要事件:
-
1956年达特茅斯会议:在这次会议上,约翰·麦卡锡、艾伦·纽厄尔、赫伯特·西蒙等学者首次提出了“人工智能”这一概念,并认为“每一方面的智能行为都可以通过机器来模拟”。
-
符号主义(Symbolic AI):这一时期的人工智能主要采用符号主义方法,认为智能是符号操作的结果,注重在计算机中表示和操作符号的方式。
-
早期程序和系统 :
- 逻辑理论家(Logic Theorist):由艾伦·纽厄尔和赫伯特·西蒙开发的程序,是早期尝试模拟人类问题解决过程的程序之一。
- 通用问题求解器(General Problem Solver):同样由纽厄尔和西蒙开发,旨在模拟人类解决问题的过程。
-
-
-
发展阶段(1970年以后)
特点:
- 随着计算机硬件和算法的进步,人工智能研究进入一个较为深入的探索阶段,尤其是在知识表示、推理、专家系统等领域取得了长足进展。
- 该阶段的人工智能应用逐步开始渗透到实际应用领域,如医学诊断、工业控制等。
- 然而,由于计算能力和算法的限制,人工智能面临许多瓶颈,特别是对于复杂问题的解决能力仍显不足,进入所谓的“AI寒冬”时期。
- 重要事件:
- 专家系统:专家系统在这一时期发展起来,模拟专家解决特定领域问题的过程。代表性的专家系统有MYCIN(医学诊断系统)。
- 机器学习和推理:该阶段的人工智能开始涉及到机器学习、搜索算法、推理等领域,但大多数研究还停留在理论探索阶段。
- AI寒冬:由于技术和应用上的局限性,人工智能的研究资金和关注度在1970年代末和1980年代初出现了大幅度的下降,进入了所谓的“AI寒冬”。
-
大数据驱动人工智能发展期(2011年以后)
特点:
- 这一阶段人工智能迎来了新一轮的飞速发展,主要得益于大数据、计算能力的提升(尤其是GPU加速计算),以及深度学习等新技术的出现。
- **深度学习(Deep Learning)**作为一种重要的机器学习方法,彻底改变了人工智能的应用场景,尤其是在图像识别、语音处理、自然语言处理等领域表现出色。
- 这一时期人工智能的应用场景大大拓展,从互联网到医疗、金融、交通、自动驾驶、智能制造等各个领域均得到了广泛应用。
- 重要事件:
- 深度学习的突破:2012年,AlexNet在ImageNet图像识别大赛中取得突破性成果,深度卷积神经网络(CNN)显示出强大的图像处理能力,为深度学习在计算机视觉领域的应用铺平了道路。
- 大数据:数据量的爆炸性增长为深度学习提供了充足的训练数据,机器学习算法在大规模数据集上的训练取得了突破性进展。
- GPU计算:图形处理单元(GPU)的计算能力极大加速了深度学习算法的训练,使得复杂的神经网络模型得以实现和应用。
- 人工智能普及:包括语音识别(如Siri、Alexa、Google Assistant)、自动驾驶(如特斯拉、Waymo)、金融风控(如信用评估、智能投顾)、医疗诊断(如癌症筛查)等应用迅速普及。
总结
人工智能的发展经历了四个主要阶段:
- 孕育阶段:基础理论和早期的思想探索。
- 形成阶段:人工智能概念的提出与初步的学术讨论。
- 发展阶段:技术进步与应用初步拓展,但遭遇“AI寒冬”。
- 大数据驱动发展期:深度学习的突破与大数据、GPU计算的推动,人工智能迎来了快速发展期,广泛应用于各个领域。
每个阶段的特点和突破,都为人工智能的成熟和现代应用奠定了基础。
-
-
简述回溯搜索策略的基本思想
- 注意,NPS和NSS不同于DFS和BFS算法里的open表和close表,open、close相当于stack(queue)和visit,而NPS里的某个点被发现是死路(以该点为根的子树不包含答案)时才会进入NSS。
(1)用未处理状态表(NPS)使算法能返回(回溯)到其中任一状态。
(2)用一张“死胡同”状态表(NSS)来避免算法重新搜索无解的路径。(注意,某结点为根的子树的所有叶节点都不是目的结点时,把此节点放入死胡同表。叶节点不是目的节点直接放入)
(3)在PS 表中记录当前搜索路径的状态,当满足目的时可以将它作为结果返回。
(4)为避免陷入死循环必须对新生成的子状态进行检查,看它是否在该三张表中 。
熟悉121面的表如何画
-
粒子群算法的基本思想
- 将每个个体看作n维搜索空间中一个没有体积质量的粒子,在搜索空间中以一定的速度飞行,该速度决定粒子飞行的方向和距离。所有粒子有一个由优化函数决定的适应值。
-
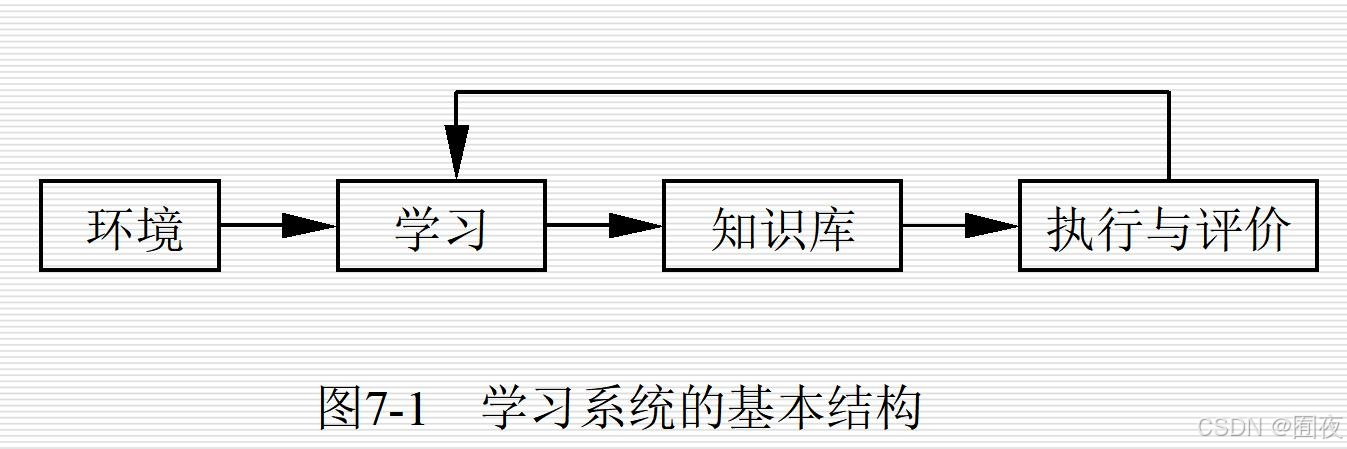
什么是机器学习,简述学习系统的基本结构
- 使计算机能模拟人的学习行为,自动地通过学习来获取知识和技能,不断改善性能,实现自我完善。
大题
-

- 做这题可以参考90面例4.1
- 几个需要的公式:
-
-
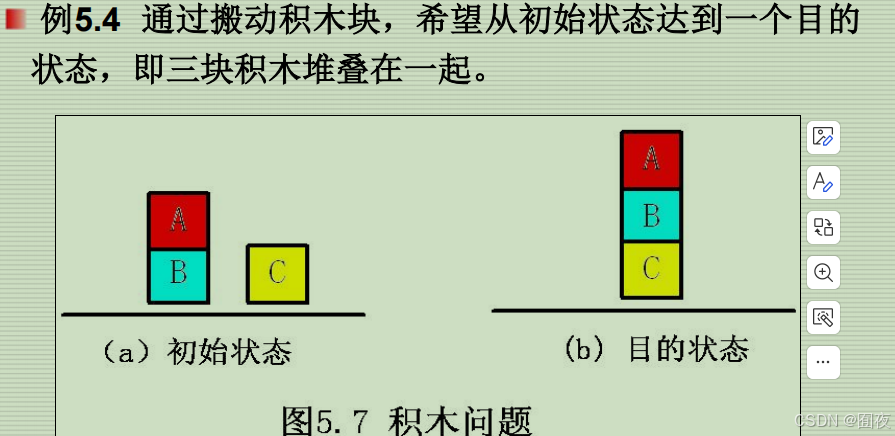
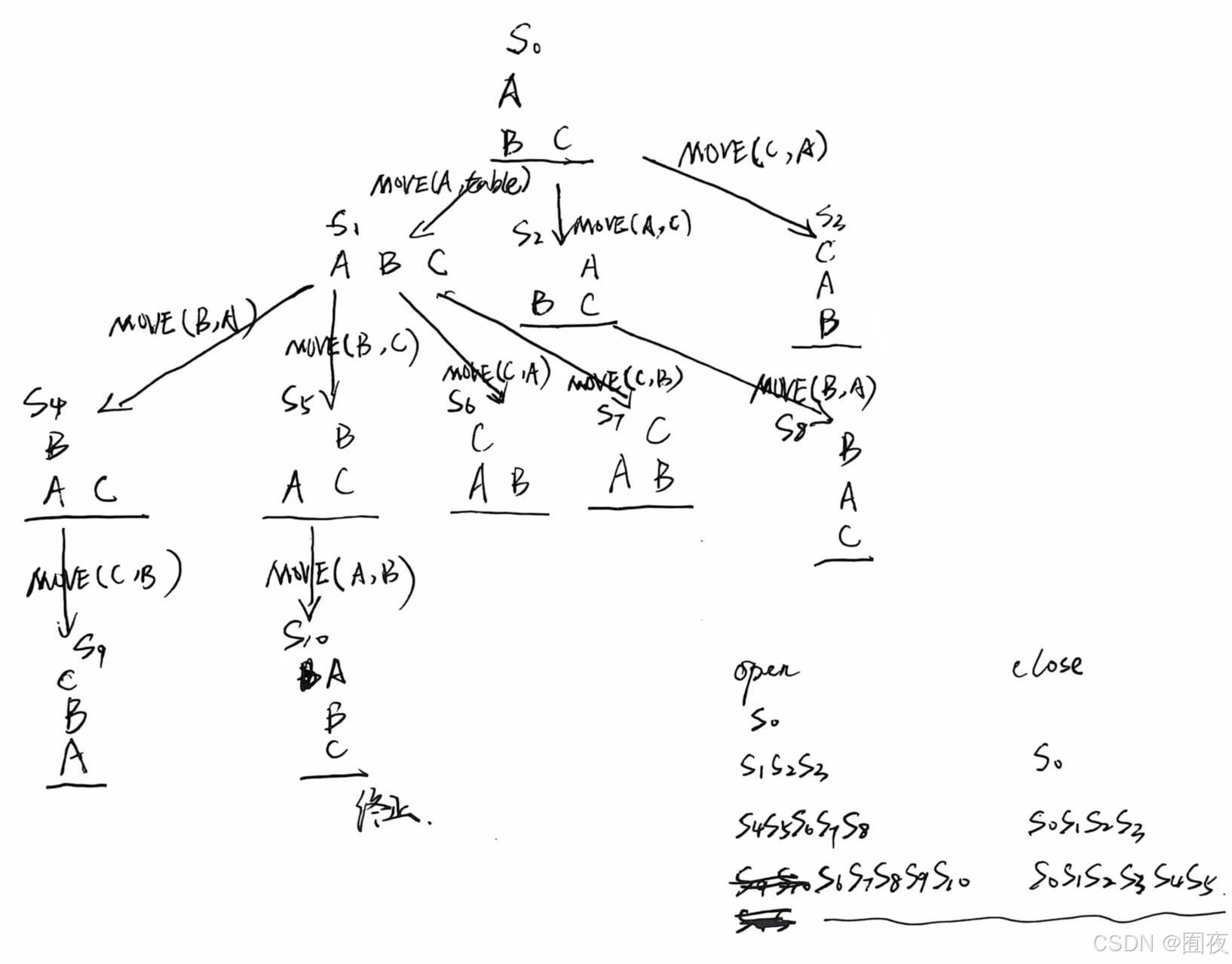
操作算子为MOVE(X,Y):把积木X搬到Y(积木或桌面)上面。操作算子可运用的先决条件: 1)被搬动积木X的顶部必须为空; 2)如果 Y 是积木,则积木 Y 的顶部也必须为空; 3)同一状态下,运用操作算子的次数不得多于一次。写出搜索树和结束状态时open、close表
- DFS用栈,BFS用队列
- 做题过程中发现,扩展树时,不能扩展回父节点状态,也不能扩展成任何树中已有状态
-
简述你对人工神经网络的理解和看法
- 书上第一章:人工神经网络是一个用大量简单处理单元经广泛连接而组成的人工网络,用来模拟大脑神经系统的结构和功能。神经网络是人工智能中一个重要的研究领域,对神经网络的大量研究为神经计算机走向应用提供了物质基础。神经网络已经在模式识别、图像处理、组合优化、自动控制、信息处理、机器人学等领域获得日益广泛的应用

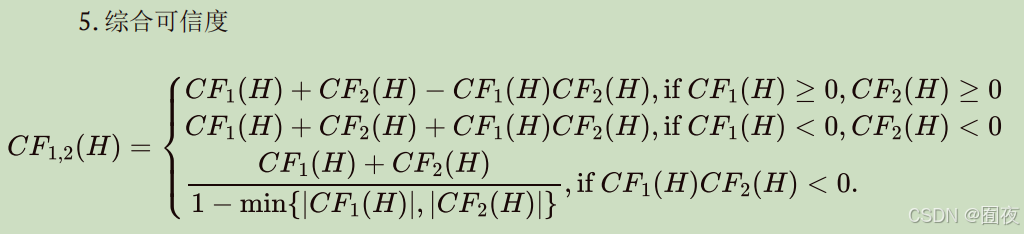
19
名词解释
- 弱人工智能
- 指不能真正实现推理和解决问题的智能机器,这些机器表面看像是智能的,但并不是真正拥有智能,也不会有自主意识。
- D-S模型(Dempster-Shafer Theory)
- 即证据理论,一种用于处理不确定性的理论(信任度,似然度)
- C-F模型(Certainty-Factor Model)
- 基于可信度表示的不确定性推理的基本方法

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)