
毕业设计:基于深度学习的肺结节识别系统 目标检测 人工智能
毕业设计:基于深度学习的肺结节识别系统结合了深度学习和计算机视觉技术,旨在解决肺结节自动识别的难题。本文将介绍系统的设计原理和关键技术,探讨其在医学影像处理和肺癌早期筛查领域的应用前景。为计算机、软件工程、人工智能和大数据等专业的毕业生提供了一个有意义的研究课题。无论您对深度学习技术保持浓厚兴趣,还是希望探索机器学习、算法或人工智能领域的同学,将为您提供灵感和指导,引领您进入这个具有挑战性和创新性
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于深度学习的肺结节识别系统
项目背景
肺结节是肺部最常见的病变之一,它可能是肺癌的早期表现。早期的肺癌诊断对于治疗和预后至关重要。然而,传统的肺结节识别方法通常需要人工参与和专业医生的解读,费时费力且容易出现误诊。肺结节识别系统通过利用深度学习算法和计算机视觉技术,自动地从医学影像中检测和识别肺结节,提供快速、准确的诊断结果,帮助医生进行早期肺癌的筛查和诊断,提高治疗的成功率和患者的生存率。
数据集
由于网络上缺乏现有的合适的肺结节识别数据集,本研究决定通过相机拍摄和互联网收集两种方式,收集医学影像图片并制作一个全新的数据集。首先,我们在医院等场所使用相机进行现场拍摄,捕捉真实的肺部影像,并特别关注肺结节的不同形态和特征。其次,我们通过互联网收集了大量的医学影像数据,包括正常肺部和肺结节的各种情况。通过这两种方式,我们能够获得丰富、多样的肺部影像数据,为基于深度学习的肺结节识别系统的研究提供准确、可靠的数据基础。
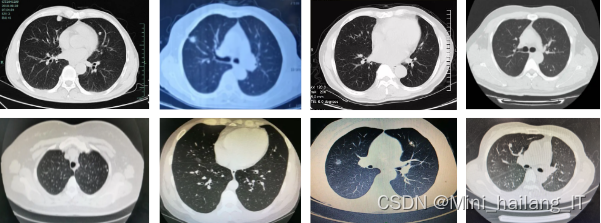
为了增加数据的多样性和覆盖度,本研究对自制的肺结节识别数据集进行了数据扩充。我们采用了图像增强和数据增强的方法,通过对原始数据进行旋转、镜像、缩放等操作,生成了更多样、更具代表性的肺部影像样本。此外,我们还使用了生成对抗网络(GAN)等生成模型,生成与原始数据相似但具有一定差异性的新样本,并将其添加到数据集中。
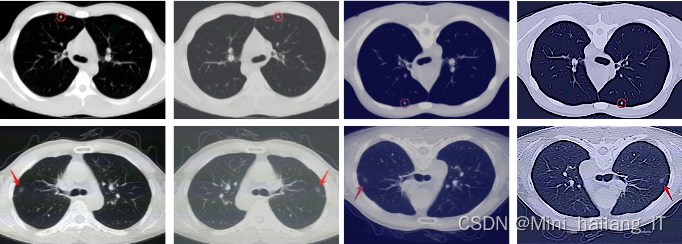
设计思路
算法理论技术
U-Net模型
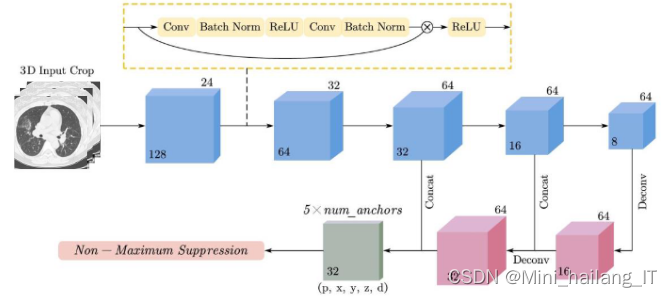
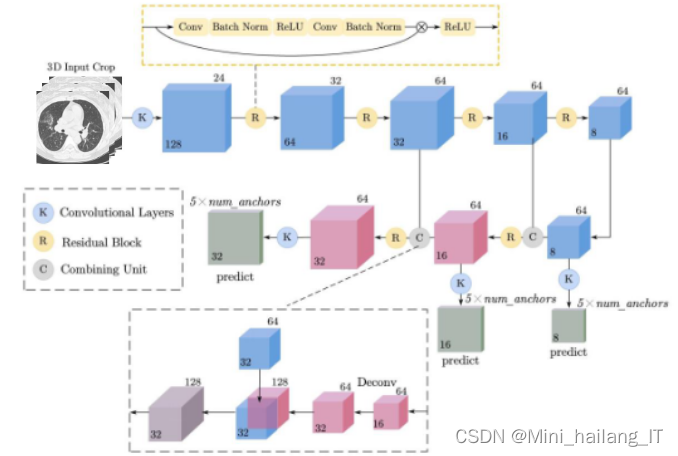
U-Net是一种经典的语义分割模型,在深度学习领域被广泛引用。它采用了编码器-解码器结构,通过先下采样再上采样的方式形成了U型结构。这种结构方便进行特征融合,弥补底层特征图的语义信息不足,有效地综合高级语义信息和低级特征信息。基于U-Net的特征融合思想,可以将类U-Net结构引入目标检测领域,以解决传统目标检测模型难以有效检测小目标的问题。这种模型通过蓝色的特征提取模块和红色的上采样模块将高低层特征相连,实现不同层之间的特征融合,并最终输出通道数为的特征图。输出包括预测的结节类别概率(是结节或不是结节)、结节中心在三维坐标系中的坐标以及结节直径大小。模型中还使用了预设的锚框数量。由于GPU计算资源的限制,三维肺结节检测网络需要将输入图像裁切为立方块进行处理。
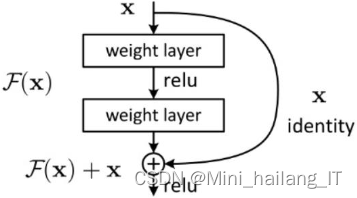
残差学习旨在解决深度网络退化问题。由于深层网络容易陷入局部最优解,训练误差可能比浅层网络更高。为此,设计了残差单元,将输入表示为恒等映射加上残差,使得网络可以学习到残差部分。残差单元通过Identity mapping和Residual mapping实现,其中Residual mapping使用常见的卷积操作学习残差,而Identity mapping将输入通过跳跃连接与学习到的残差进行逐元素相加。这样可以简化学习目标和难度,使网络对输出的变化更敏感,并解决深度网络的退化问题。此外,残差学习结构只增加了Shortcut Connection来实现恒等映射,不会增加额外的计算开销,整个网络仍然可以进行端到端的训练。
特征金字塔网络(FPN)也常用于肺结节检测模型中。通过将FPN改造为三维网络,并保留自顶向下的多尺度特征图横向连接结构,可以在增加一定计算量的同时,融合低分辨率、语义信息较强的特征图和高分辨率、空间信息更丰富的特征图。同时,对每个层级的特征图进行预测输出,使得每个层级对应特定尺度的目标更加敏感,从而实现更好的检测性能。
多分支并行
网络由编码路径和解码路径组成,编码路径从两个卷积层开始得到初始特征图,然后通过残差模块和最大池化层逐步得到编码路径的最后一张特征图。解码路径将二维FPN的5层输出减少为3层,使用拼接操作而非相加操作,经过卷积层和Dropout层改变输出的通道数,并得到3种不同尺度的输出特征图。多分支输出结构的设计理论上可以让模型对不同尺度的目标具有更好的敏感度,但实验中发现,FPN结构对模型检测性能的提升并不明显。甚至如果为每层输出分支设置不同尺度大小的锚框,反而会导致略微的性能下降。这主要是因为FPN的多尺度融合方法只是简单地利用了不同的浅层特征图进行多分支预测,每个预测分支经过上采样和残差模块,但感受野的变化不明显,而感受野与目标尺度的匹配是提升检测性能的关键。此外,肺结节检测网络的深度较浅,特征图的语义信息和细节信息都相对有限,进一步减小了每个预测分支对不同尺度目标的敏感度差异。
多分支的并行网络结构,用于肺结节检测任务。通过设计多个网络分支并改变每个分支的感受野,可以使网络对不同尺度的目标具有更高的敏感度。网络结构由编码路径和解码路径组成,其中编码路径通过卷积层、残差模块和最大池化层逐步提取特征,解码路径通过反卷积层进行上采样,并与低层特征图进行融合。为了解决尺度变化感知的问题,本文构造了三个平行分支,每个分支具有相同的结构,但最后一个残差模块的膨胀系数不同。同时,为了综合不同分支对不同尺度目标的敏感度,引入了多尺度特征融合结构和相同的多尺度锚框。这样的设计旨在同时利用浅层网络的优势和不同感受野的有效性,提高肺结节检测的性能。
实验环境
操作系统为Ubuntu 16.04,Python版本为3.6.12,编译器选择PyCharm,用于开发的工具库为PyQt5。PyQt5是基于Qt5的Python接口,是功能强大的图形程式框架之一。它提供了丰富的窗口控件集合,开发者可以通过在Qt Designer上拖动控件的方式进行界面设计,并自动生成可执行的Python代码。PyQt5的使用方便快捷,能够满足系统界面可视化的需求。通过结合Ubuntu操作系统、Python编程语言和PyQt5库,开发者可以轻松地构建出功能强大、美观易用的图形界面应用程序。
模型训练
设计思路可以分为以下几个步骤:
- 数据收集和预处理:收集肺结节图像数据集,并进行预处理操作,如图像去噪、图像增强、图像标准化等,以提高模型的鲁棒性和准确性。
- 数据标注:对收集的肺结节图像进行标注,标明肺结节的位置和类别信息。可以手动标注或者利用半自动化或自动化的方法进行标注。
- 构建深度学习模型:选择适当的深度学习模型来进行肺结节识别。常用的模型包括卷积神经网络(CNN)和其变种(如ResNet、VGG、Inception等),以及一些目标检测模型(如Faster R-CNN、YOLO等)。
- 模型训练:使用标注的肺结节图像数据集对深度学习模型进行训练。训练过程中,可以采用数据增强技术来扩充数据集,以增加模型的泛化能力。同时,可以利用预训练模型进行迁移学习,加快训练过程和提高模型性能。
- 模型评估和优化:使用验证集或交叉验证方法对训练好的模型进行评估,计算指标如准确率、召回率、F1分数等,以评估模型的性能。根据评估结果,可以进行模型的优化,如调整网络结构、调整超参数等。
相关代码示例:
# 创建模型实例
model = LungNoduleModel(num_classes=2)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(10):
model.train()
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
model.eval()
with torch.no_grad():
total = 0
correct = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Epoch {epoch+1}: Validation Accuracy = {accuracy:.2f}%")海浪学长项目示例:






更多帮助

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 27
27 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)