
深度学习常用激活函数总结
首先数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,强化网络的学习能力。所以激活函数的最大特点就是非线性。不同的激活函数,根据其特点,应用也不同。Sigmoid和tanh的特点是将输出限制在(0,1)和(-1,1)之间,说明Sigmoid和tanh适合做概率值的处理,例如LSTM中的各种门;而ReLU就不行,因为ReLU无最大值限制,可能会出现很
1 为什么需要激活函数
首先数据的分布绝大多数是非线性的,而一般神经网络的计算是线性的,引入激活函数,是在神经网络中引入非线性,强化网络的学习能力。所以激活函数的最大特点就是非线性。
不同的激活函数,根据其特点,应用也不同。
Sigmoid和tanh的特点是将输出限制在(0,1)和(-1,1)之间,说明Sigmoid和tanh适合做概率值的处理,例如LSTM中的各种门;
而ReLU就不行,因为ReLU无最大值限制,可能会出现很大值。同样,根据ReLU的特征,Relu适合用于深层网络的训练,而Sigmoid和tanh则不行,因为它们会出现梯度消失。
2 常见的激活函数
1 Sigmoid
sigmoid函数也称为Logistic函数,因为Sigmoid函数可以从Logistic回归(LR)中推理得到,也是LR模型指定的激活函数。
sigmod函数的取值范围在(0, 1)之间,可以将网络的输出映射在这一范围,方便分析。
| 激活函数 | 表达式 | 导形式 | 取值范围 | 图像 | 适用 |
|---|---|---|---|---|---|
| Sigmoid | f=11+exf = \frac{1}{1+e^x}f=1+ex1 | f′=f(1−f)f'=f(1-f)f′=f(1−f) | (0,1) | 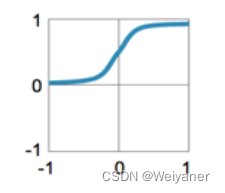 |
计算概率值 |
优缺点分析:
- 优点:
易于求导,数据符合泊松分布 - 缺点:
- 激活函数计算量大(在正向传播和反向传播中都包含幂运算和除法);
- 反向传播求误差梯度时,求导涉及除法;
- Sigmoid导数取值范围是[0, 0.25],由于神经网络反向传播时的“链式反应”,很容易就会出现梯度消失的情况。
- Sigmoid的输出不是0均值(即zero-centered);这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入,随着网络的加深,会改变数据的原始分布。|
2 Tanh
tanh为双曲正切函数,其英文读作Hyperbolic Tangent。tanh和 sigmoid 相似,都属于饱和激活函数,区别在于输出值范围由 (0,1) 变为了 (-1,1),可以把 tanh 函数看做是 sigmoid 向下平移和拉伸后的结果。
| 激活函数 | 表达式 | 导形式 | 取值范围 | 图像 | 适用 |
|---|---|---|---|---|---|
| tanh | f=ex−e−xex+e−xf = \frac{e^x-e^{-x}}{e^x+e^{-x}}f=ex+e−xex−e−x | f′=21+e−2x−1f'=\frac{2}{1+e^{-2x}}-1f′=1+e−2x2−1 | (-1,1) | 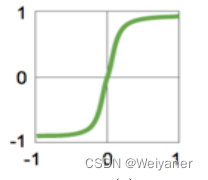 |
Tanh的特点
- 优点
- tanh的输出范围时(-1, 1),解决了Sigmoid函数的不是zero-centered输出问题;
- 缺点
- 幂运算的问题仍然存在;
- tanh导数范围在(0, 1)之间,相比sigmoid的(0, 0.25),梯度消失得到缓解,但仍然存在。
3 Relu及其变体(2012 AlexNet)
由于以上激活函数存在的梯度消失问题,所以2012年提出了整流线性单元(Relu)。
| 激活函数 | 表达式 | 导形式 | 取值范围 | 图像 | 适用 |
|---|---|---|---|---|---|
| Relu | f=max(0,x)f =max(0,x)f=max(0,x) | f′=1,0f'=1, 0f′=1,0 | [0,1) | 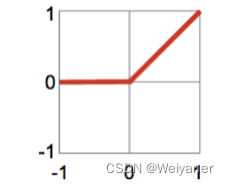 |
避免了梯度消失,适用于深度网络 |
| PRelu(ai变量)//LeakyRelu(ai=0.01)PRelu(a_i变量)//LeakyRelu(a_i=0.01)PRelu(ai变量)//LeakyRelu(ai=0.01) | f(x)={aix,x<0x,x>=0f(x)=\left\{\begin{aligned}a_ix, x<0 \\x,x>=0\end{aligned}\right.f(x)={aix,x<0x,x>=0 | f′(x)={ai,x<01,x>=0f'(x)=\left\{\begin{aligned}a_i, x<0 \\1,x>=0\end{aligned}\right.f′(x)={ai,x<01,x>=0 | (-1,1) | 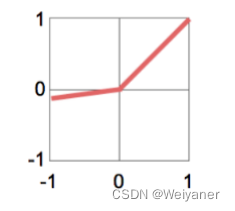 |
改善Relu的0梯度,为一个很小的负值,防止神经元死亡 |
| RRelu | y={x,x≥0a(ex−1),x<0y=\left\{\begin{array}{lc}x, & x \geq 0 \\ a\left(e^{x}-1\right), & x<0\end{array}\right.y={x,a(ex−1),x≥0x<0 | (-1,1) | 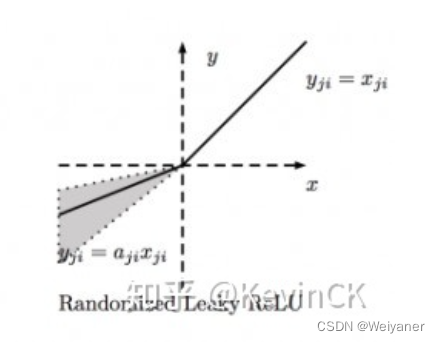 |
在负数部分的ai是从一个均匀的分布U(I,u)中随机抽取的数值 |
总结:
-
Leaky ReLU中的为常数,一般设置 0.01。这个函数通常比 Relu 激活函数效果要好,但是效果不是很稳定,所以在实际中 Leaky ReLu 使用的并不多。
-
PRelu(参数化修正线性单元) 中作为一个可学习的参数,会在训练的过程中进行更新。
-
RReLU(随机纠正线性单元)也是Leaky ReLU的一个变体。在RReLU中,负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。RReLU的亮点在于,在训练环节中,aji是从一个均匀的分布U(I,u)中随机抽取的数值。
4 Softmax
Softmax函数是用于多类分类问题的激活函数,在多类分类问题中,超过两个类标签则需要类成员关系。对于长度为K的任意实向量,Softmax函数可以将其压缩为长度为K,值在[ 0 , 1 ] 范围内,并且向量中元素的总和为1的实向量。
Softmax函数的分母结合了原始输出值的所有因子,这意味着Softmax函数获得的各种概率彼此相关。
为何叫做softmax,适合max函数比较得到的,max只会返回一个最大值,而忽略了其余值,softmax的方式就略显soft,按照归一化的方式保留每一个较小的值。
softmax(x)=exp(xi)∑iexp(xi)softmax(x) = \frac{exp(x_i)}{\sum_{i}exp(x_i)}softmax(x)=∑iexp(xi)exp(xi)
Softmax激活函数的特点:
- 在零点不可微。
- 负输入的梯度为零,这意味着对于该区域的激活,权重不会在反向传播期间更新,因此会产生永不激活的死亡神经元,梯度消失。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)