
目标检测原理&代码实现(pytorch+yolov3)
目录一、目标检测 VS 图像分类 VS 图像分割二、目标检测1、目标检测基础理论2、基于深度学习的目标检测Two-stage流程One-stage流程3、人脸业务场景https://www.bilibili.com/video/BV1u44y1J7yV?p=2&spm_id_from=pageDriver一、目标检测 VS 图像分类 VS 图像分割图像分类只需要将图片分类别即可,目标检测,
·
说明:最近学习目标检测相关知识并进行简单记录,推荐先学习原理部分,再入手代码,每部分都附上学习视频。
一、目标检测 VS 图像分类 VS 图像分割
理论学习:视频推荐
图像分类只需要将图片分类别即可,目标检测,先定位再分类
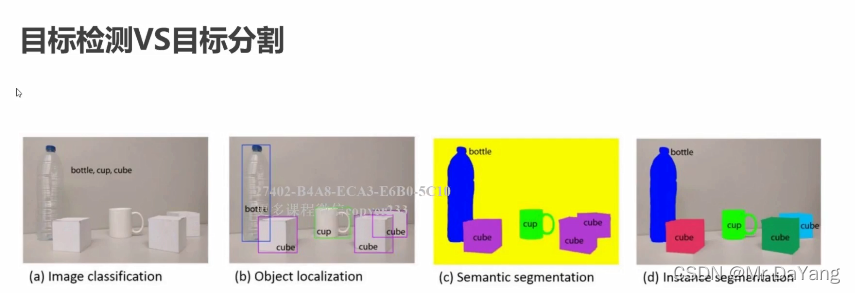
目标定位/检测:大体定位出框子
语义分割:相同语义的为一类颜色,图中紫色,像素级别
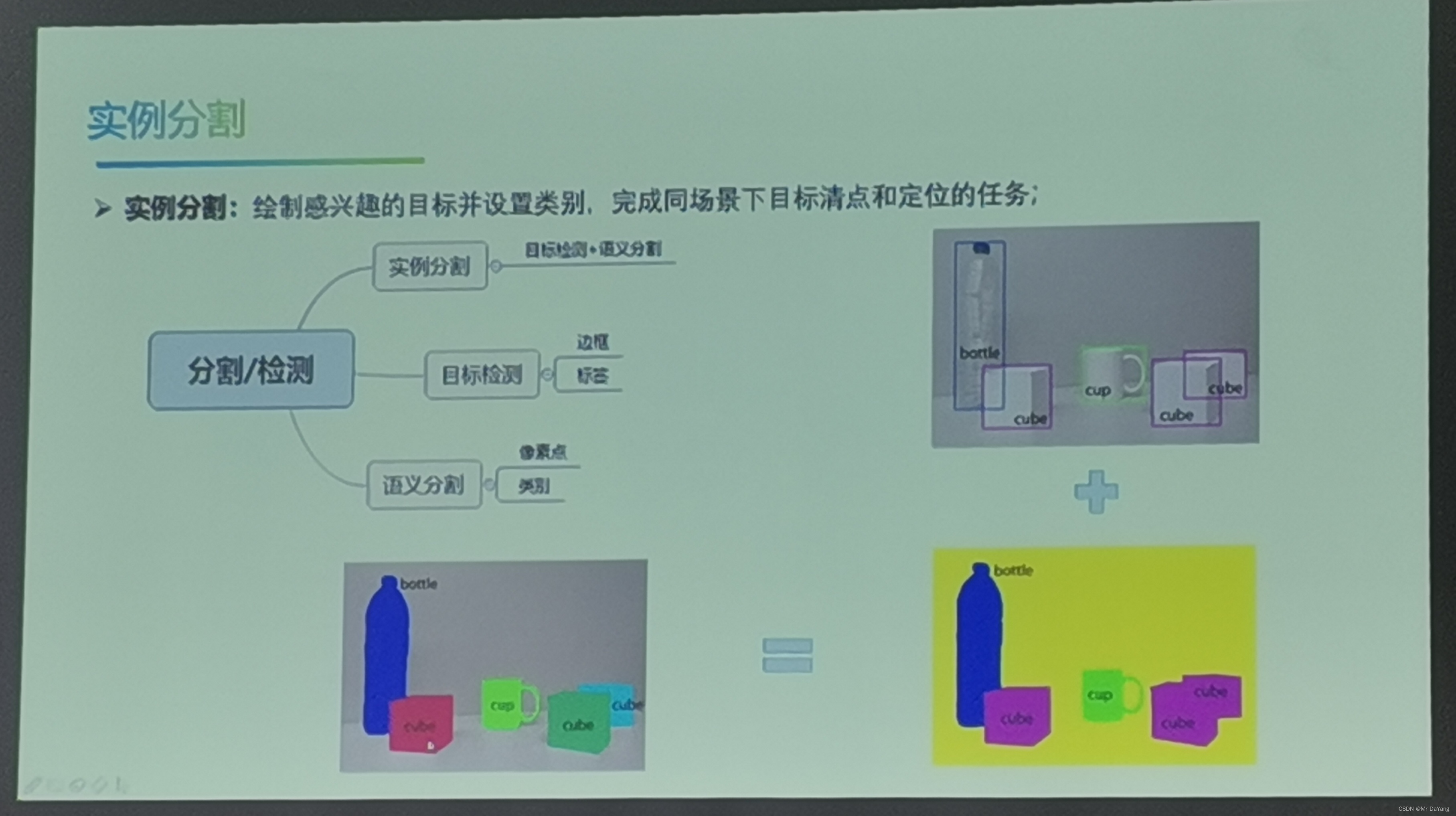
实例分割:每个物体精确分割好,再细分1,2
二、目标检测
1、目标检测基础理论
流程:
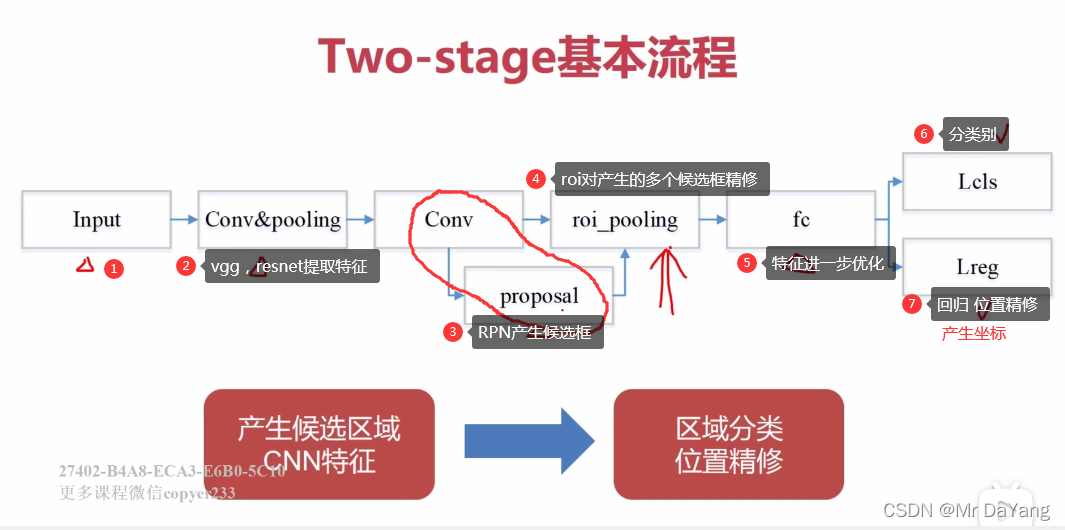
two stage:
先选择候选框,对框中像素进行特征提取(浅层的:颜色,hog直方图),对框子进行分类判决svw,通过非极大值致抑制的方法进行分类框合并。
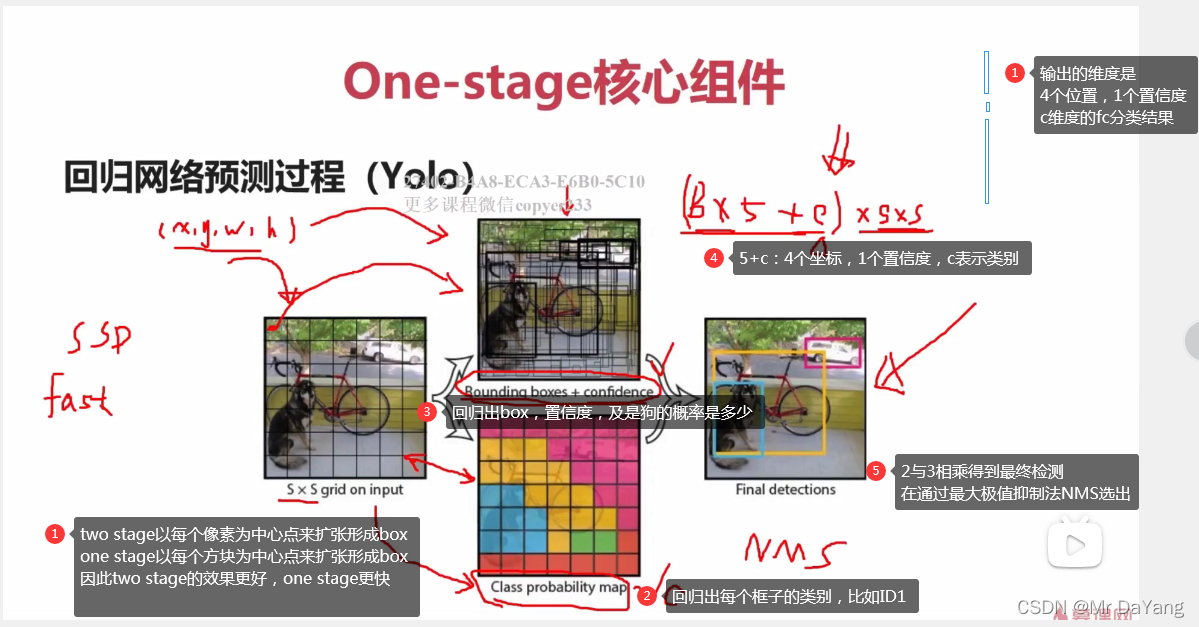
one stage:下面蓝色部分,直接预测输出(4个位置+1个置信度+c维的分类情况),而不用上面的那种分别进行pooling抠图,再分类回归的过程。





2、基于深度学习的目标检测
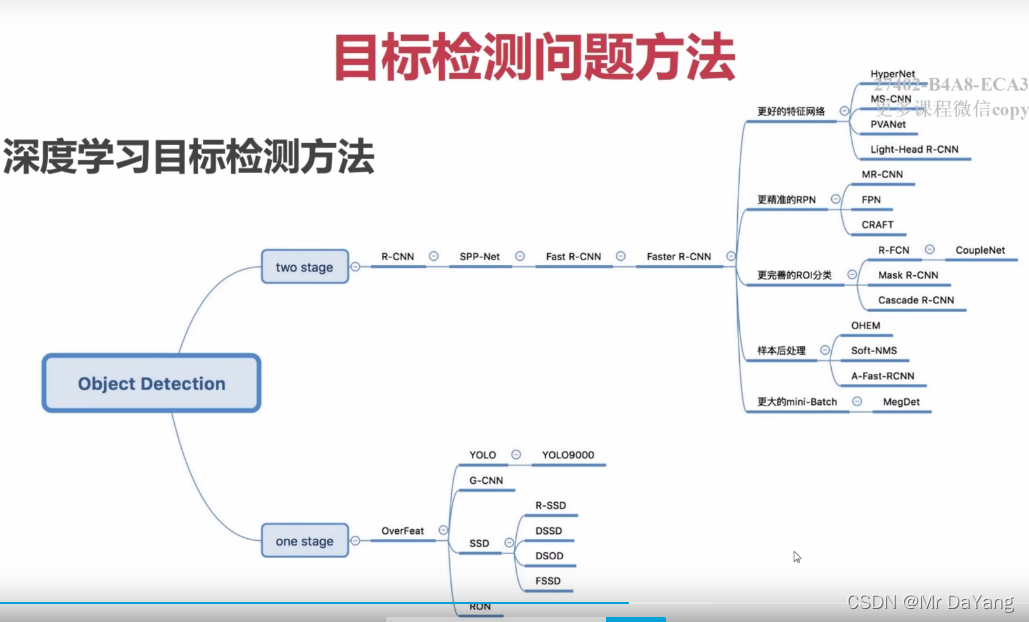
Two-stage流程
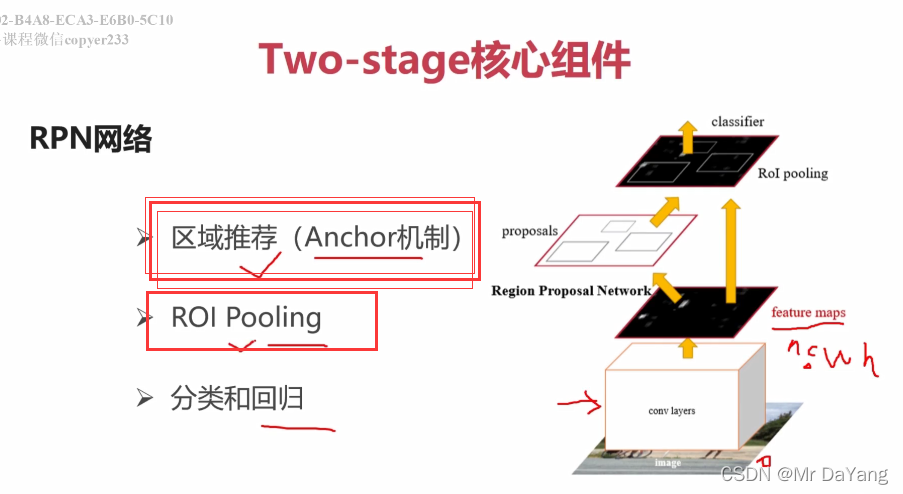
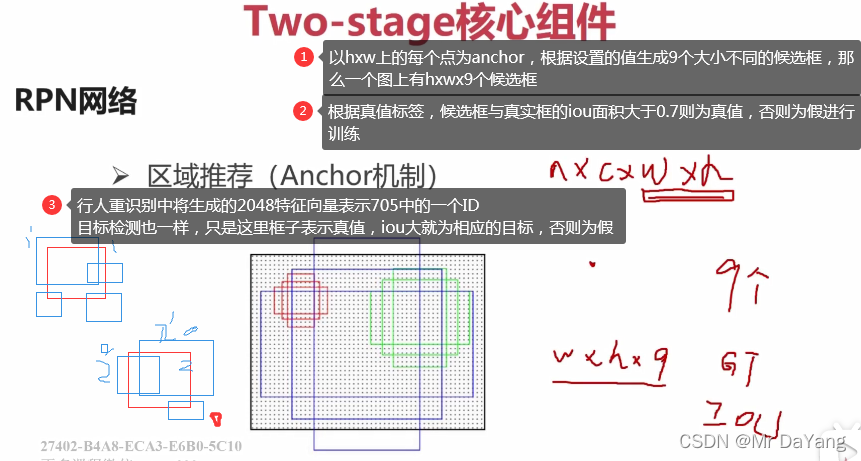


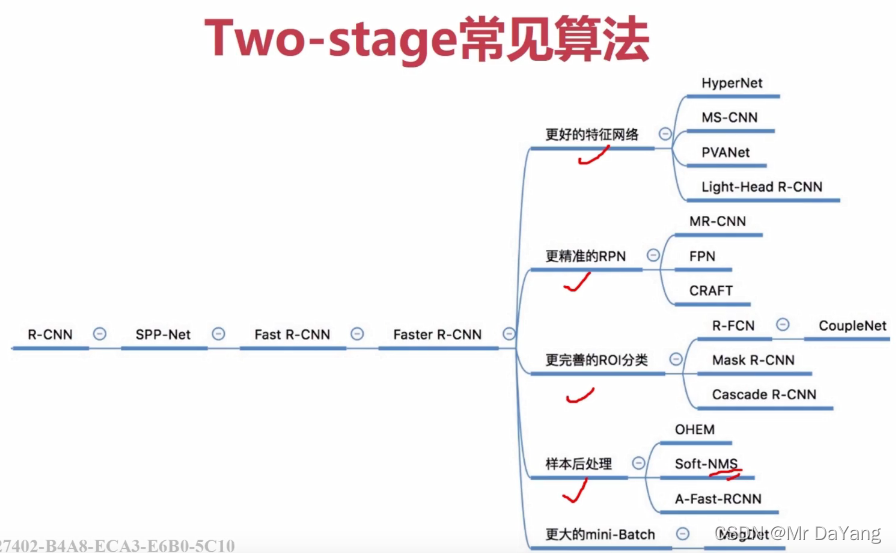
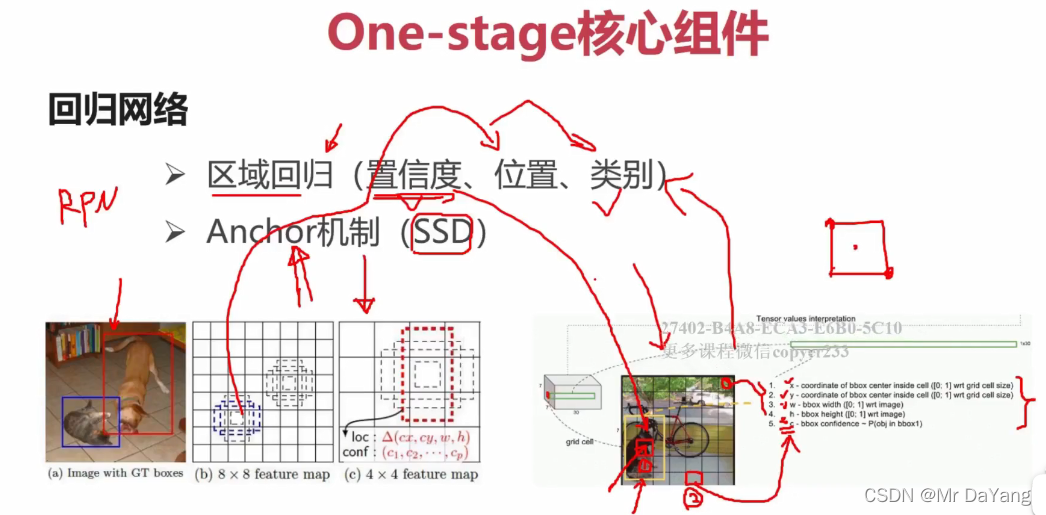
One-stage流程
在嵌入式使用中,倾向于使用one-stage速度快









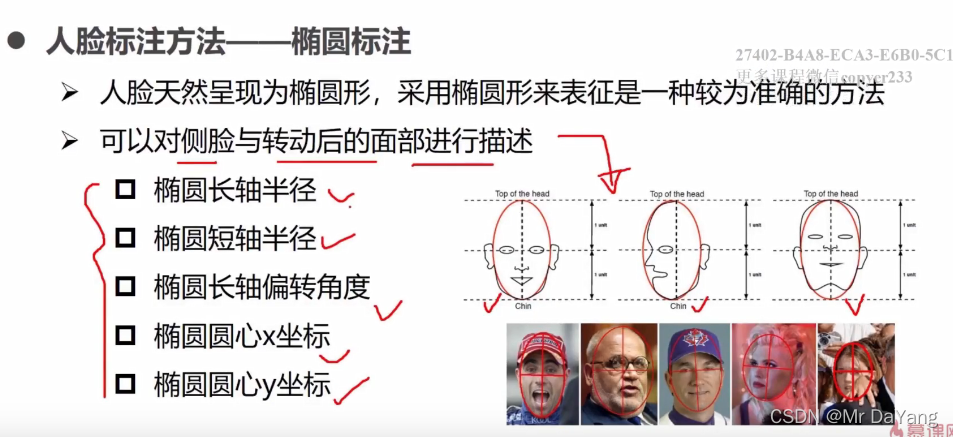
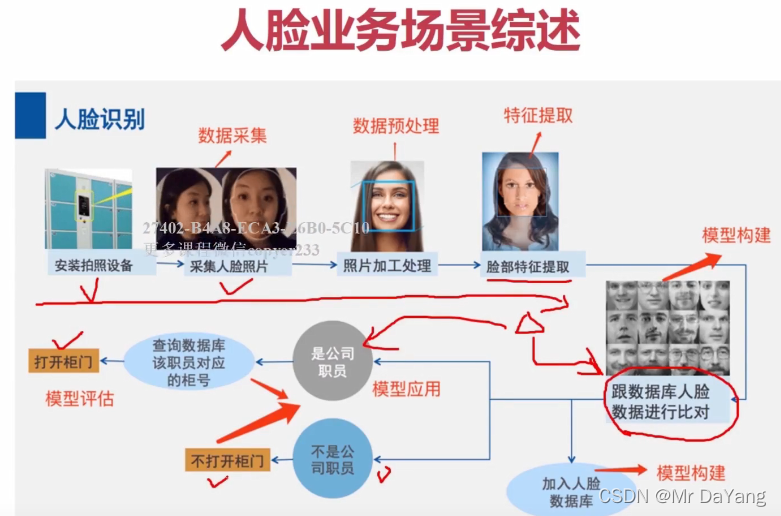
3、人脸业务场景

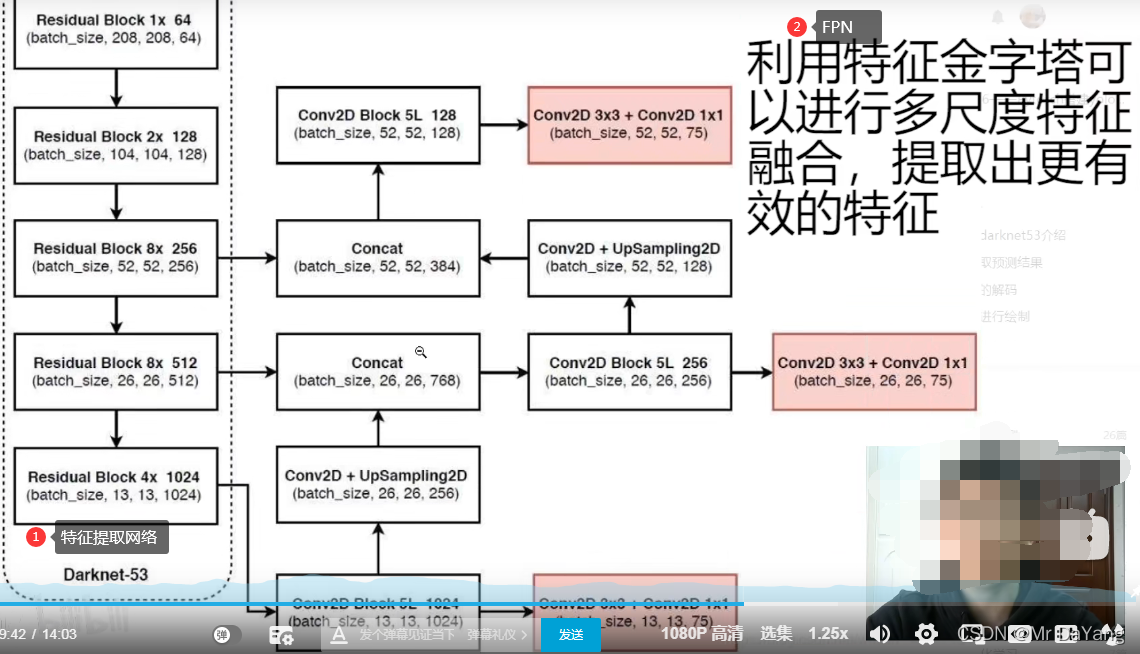
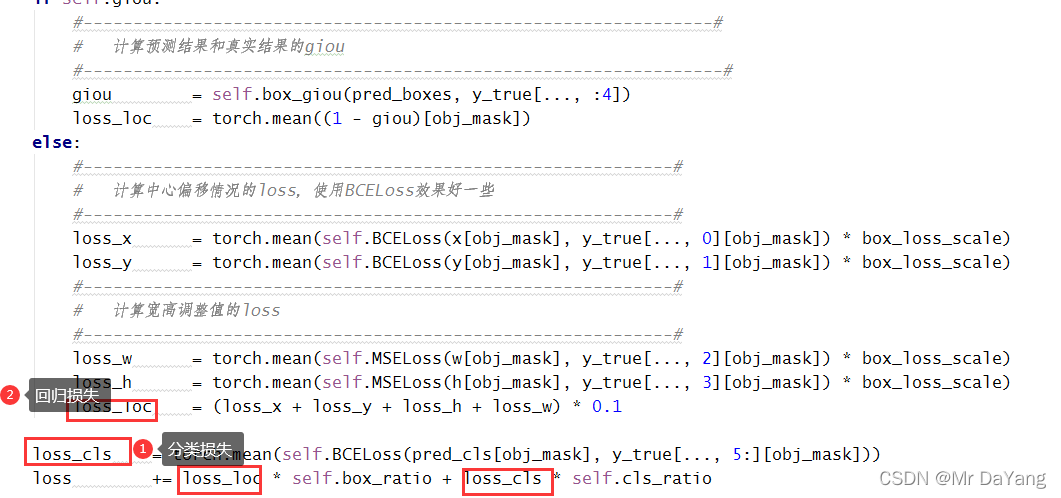
三、代码实践
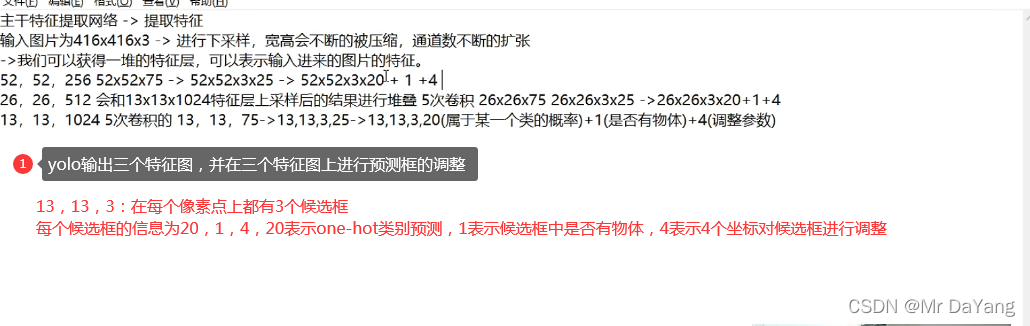
锚点、先验框是事先超参设置好的,然后根据训练结果进行两者的微调。
参考1:目标检测先验框和模型原理
参考2:anchor锚点
参考3:代码部署视频,此博主代码已实验过,可以正常运行





汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)