
pytorch基础(六)-优化器
pytorch基本属性和方法
·
基本属性

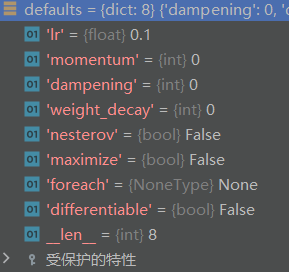
default:
优化器超参数
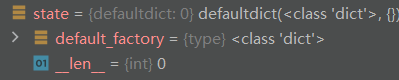
state:
优化器缓存
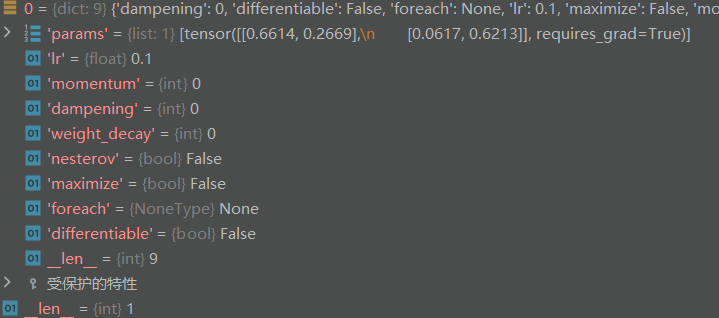
params_groups:
管理的参数组
_step_count:
记录更新参数(学习率调整中使用)
基本方法
step()
更新一次参数
weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))
optimizer = optim.SGD([weight], lr=0.1)
print("weight before step:{}".format(weight.data))
optimizer.step()
print("weight after step:{}".format(weight.data))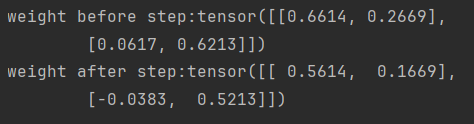
zero_grad()
清空所有梯度
optimizer.step() 
add_param_group()
x_1 = optimizer.param_groups
w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, 'lr': 0.0001})
x_2 = optimizer.param_groups 

state_dict()
获取优化器当前的字典信息
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
opt_state_dict = optimizer.state_dict()
# ...梯度下降
torch.save(optimizer.state_dict(), os.path.join(BASE_DIR, "optimizer_state_dict.pkl")) 
load_state_dict()
加载优化器信息
state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
optimizer.load_state_dict(state_dict)state_dict before load state:
{'state': {}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': [0]}]}
state_dict after load state:
{'state': {0: {'momentum_buffer': tensor([[6.5132, 6.5132],
[6.5132, 6.5132]])}}, 'param_groups': [{'lr': 0.1, 'momentum': 0.9, 'dampening': 0, 'weight_decay': 0, 'nesterov': False, 'maximize': False, 'foreach': None, 'differentiable': False, 'params': [0]}]}
梯度下降
v_i:当前梯度下降的更新量
m:动量
v_i-1:上一次梯度下降的更新量
g(w_i):当前梯度下降的梯度
lr:学习率
w_i:当前时刻权重
w_i+1:更新后权重

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)