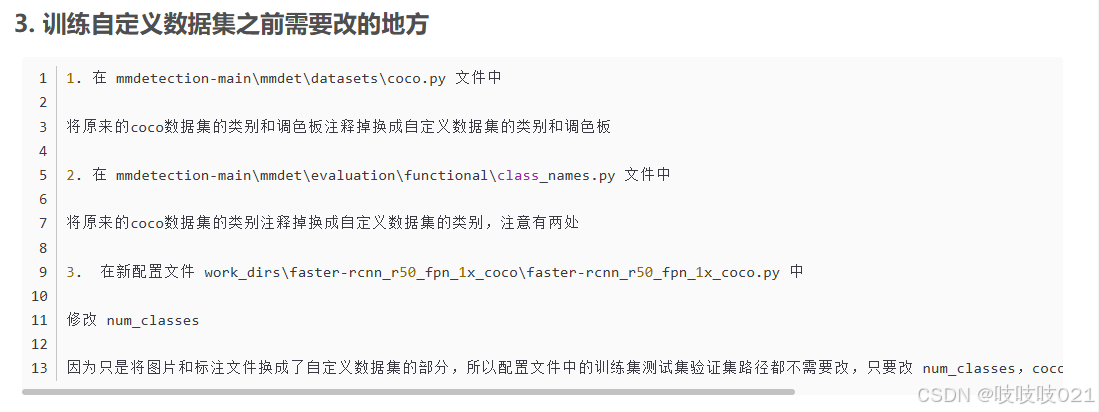
MMDetection :ValueError:need at least array to concatenate(多种解决方法)
1.若使用Label Studio 标注categories 类别id从0开始,且需更改图片路径,。2.若使用labelme 标注,categories 类别id从1开始,二,检查json文件,lab。在哪修改更快我也迷糊了,哈哈。一,更改coco.py。
·
原作1链接:https://blog.csdn.net/yueyadan/article/details/136366222
原作2链接:https://blog.csdn.net/weixin_45558466/article/details/139842747

pip install -v -e .一,原作摘要:添加类别,在train.py 和test.py 分别加入类别
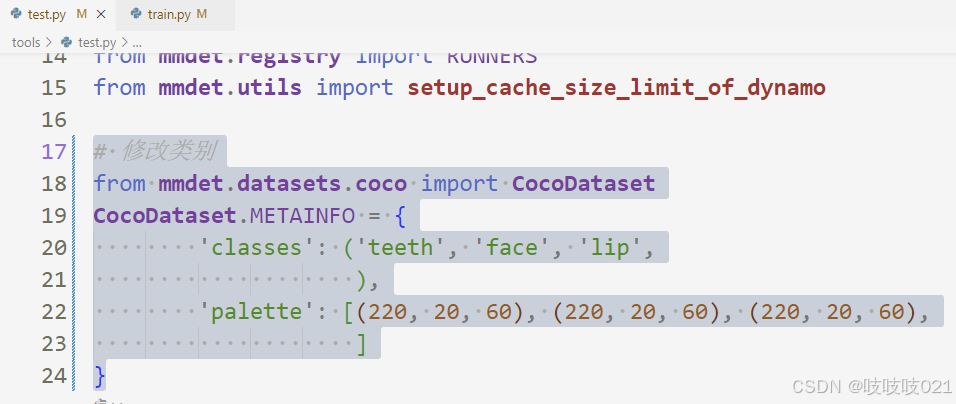
# 修改类别
from mmdet.datasets.coco import CocoDataset
CocoDataset.METAINFO = {
'classes': ('teeth', 'face', 'lip',
),
'palette': [(220, 20, 60), (220, 20, 60), (220, 20, 60),
]
}二,补充
1,修改coco.py,在configs 增加num_classes(可选)
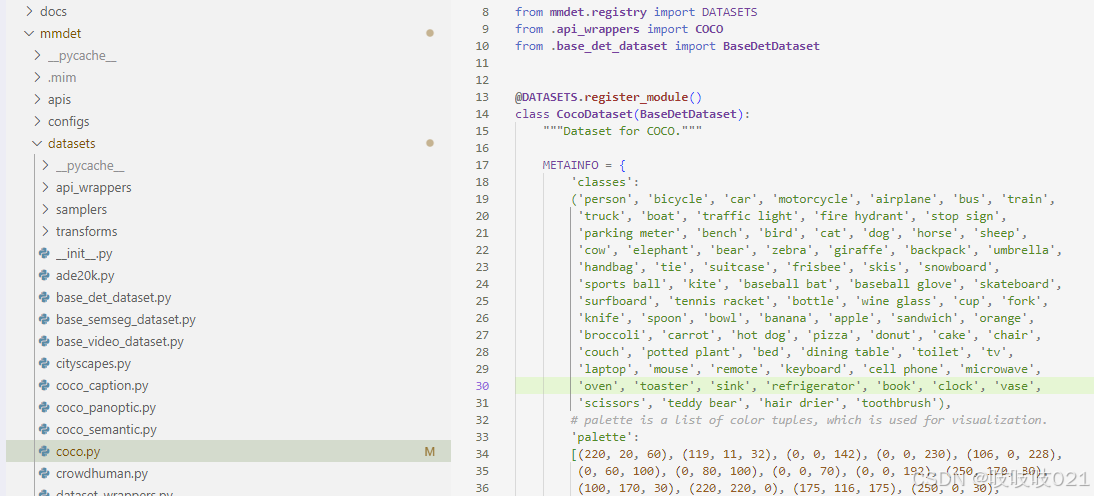

2,检查json文件(可选)
2.1.若使用Label Studio 标注categories 类别id从0开始,且需更改图片路径。

2.2.若使用labelme 标注,注意categories 类别id从1开始。

3. 数据集转换labelme2coco.py 。
# Copyright (c) OpenMMLab. All rights reserved.
"""This script helps to convert labelme-style dataset to the coco format.
Usage:
$ python labelme2coco.py \
--img-dir /path/to/images \
--labels-dir /path/to/labels \
--out /path/to/coco_instances.json \
[--class-id-txt /path/to/class_with_id.txt]
Note:
Labels dir file structure:
.
└── PATH_TO_LABELS
├── image1.json
├── image2.json
└── ...
Images dir file structure:
.
└── PATH_TO_IMAGES
├── image1.jpg
├── image2.png
└── ...
If user set `--class-id-txt` then will use it in `categories` field,
if not set, then will generate auto base on the all labelme label
files to `class_with_id.json`.
class_with_id.txt example, each line is "id class_name":
```text
1 cat
2 dog
3 bicycle
4 motorcycle
```
"""
import argparse
import json
from pathlib import Path
from typing import Optional
import numpy as np
from mmengine import track_iter_progress
# from mmyolo.utils.misc import IMG_EXTENSIONS
# 替代 mmyolo.utils.misc 中的 IMG_EXTENSIONS
IMG_EXTENSIONS = ('.jpg', '.jpeg', '.png', '.ppm', '.bmp', '.pgm', '.tif', '.tiff', '.webp')
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--img-dir', type=str, help='Dataset image directory')
parser.add_argument(
'--labels-dir', type=str, help='Dataset labels directory')
parser.add_argument('--out', type=str, help='COCO label json output path')
parser.add_argument(
'--class-id-txt', default=None, type=str, help='All class id txt path')
args = parser.parse_args()
return args
def format_coco_annotations(points: list, image_id: int, annotations_id: int,
category_id: int) -> dict:
"""Gen COCO annotations format label from labelme format label.
Args:
points (list): Coordinates of four vertices of rectangle bbox.
image_id (int): Image id.
annotations_id (int): Annotations id.
category_id (int): Image dir path.
Return:
annotation_info (dict): COCO annotation data.
"""
annotation_info = dict()
annotation_info['iscrowd'] = 0
annotation_info['category_id'] = category_id
annotation_info['id'] = annotations_id
annotation_info['image_id'] = image_id
# bbox is [x1, y1, w, h]
annotation_info['bbox'] = [
points[0][0], points[0][1], points[1][0] - points[0][0],
points[1][1] - points[0][1]
]
annotation_info['area'] = annotation_info['bbox'][2] * annotation_info[
'bbox'][3] # bbox w * h
segmentation_points = np.asarray(points).copy()
segmentation_points[1, :] = np.asarray(points)[2, :]
segmentation_points[2, :] = np.asarray(points)[1, :]
annotation_info['segmentation'] = [list(segmentation_points.flatten())]
return annotation_info
def parse_labelme_to_coco(
image_dir: str,
labels_root: str,
all_classes_id: Optional[dict] = None) -> (dict, dict):
"""Gen COCO json format label from labelme format label.
Args:
image_dir (str): Image dir path.
labels_root (str): Image label root path.
all_classes_id (Optional[dict]): All class with id. Default None.
Return:
coco_json (dict): COCO json data.
category_to_id (dict): category id and name.
COCO json example:
{
"images": [
{
"height": 3000,
"width": 4000,
"id": 1,
"file_name": "IMG_20210627_225110.jpg"
},
...
],
"categories": [
{
"id": 1,
"name": "cat"
},
...
],
"annotations": [
{
"iscrowd": 0,
"category_id": 1,
"id": 1,
"image_id": 1,
"bbox": [
1183.7313232421875,
1230.0509033203125,
1270.9998779296875,
927.0848388671875
],
"area": 1178324.7170306593,
"segmentation": [
[
1183.7313232421875,
1230.0509033203125,
1183.7313232421875,
2157.1357421875,
2454.731201171875,
2157.1357421875,
2454.731201171875,
1230.0509033203125
]
]
},
...
]
}
"""
# init coco json field
coco_json = {'images': [], 'categories': [], 'annotations': []}
image_id = 0
annotations_id = 0
if all_classes_id is None:
category_to_id = dict()
categories_labels = []
else:
category_to_id = all_classes_id
categories_labels = list(all_classes_id.keys())
# add class_ids and class_names to the categories list in coco_json
for class_name, class_id in category_to_id.items():
coco_json['categories'].append({
'id': class_id,
'name': class_name
})
# filter incorrect image file
img_file_list = [
img_file for img_file in Path(image_dir).iterdir()
if img_file.suffix.lower() in IMG_EXTENSIONS
]
for img_file in track_iter_progress(img_file_list):
# get label file according to the image file name
label_path = Path(labels_root).joinpath(
img_file.stem).with_suffix('.json')
if not label_path.exists():
print(f'Can not find label file: {label_path}, skip...')
continue
# load labelme label
with open(label_path, encoding='utf-8') as f:
labelme_data = json.load(f)
image_id = image_id + 1 # coco id begin from 1
# update coco 'images' field
coco_json['images'].append({
'height':
labelme_data['imageHeight'],
'width':
labelme_data['imageWidth'],
'id':
image_id,
'file_name':
Path(labelme_data['imagePath']).name
})
for label_shapes in labelme_data['shapes']:
# Update coco 'categories' field
class_name = label_shapes['label']
if (all_classes_id is None) and (class_name
not in categories_labels):
# only update when not been added before
coco_json['categories'].append({
'id':
len(categories_labels) + 1, # categories id start with 1
'name': class_name
})
categories_labels.append(class_name)
category_to_id[class_name] = len(categories_labels)
elif (all_classes_id is not None) and (class_name
not in categories_labels):
# check class name
raise ValueError(f'Got unexpected class name {class_name}, '
'which is not in your `--class-id-txt`.')
# get shape type and convert it to coco format
shape_type = label_shapes['shape_type']
if shape_type != 'rectangle':
print(f'not support `{shape_type}` yet, skip...')
continue
annotations_id = annotations_id + 1
# convert point from [xmin, ymin, xmax, ymax] to [x1, y1, w, h]
(x1, y1), (x2, y2) = label_shapes['points']
x1, x2 = sorted([x1, x2]) # xmin, xmax
y1, y2 = sorted([y1, y2]) # ymin, ymax
points = [[x1, y1], [x2, y2], [x1, y2], [x2, y1]]
coco_annotations = format_coco_annotations(
points, image_id, annotations_id, category_to_id[class_name])
coco_json['annotations'].append(coco_annotations)
print(f'Total image = {image_id}')
print(f'Total annotations = {annotations_id}')
print(f'Number of categories = {len(categories_labels)}, '
f'which is {categories_labels}')
return coco_json, category_to_id
def convert_labelme_to_coco(image_dir: str,
labels_dir: str,
out_path: str,
class_id_txt: Optional[str] = None):
"""Convert labelme format label to COCO json format label.
Args:
image_dir (str): Image dir path.
labels_dir (str): Image label path.
out_path (str): COCO json file save path.
class_id_txt (Optional[str]): All class id txt file path.
Default None.
"""
assert Path(out_path).suffix == '.json'
if class_id_txt is not None:
assert Path(class_id_txt).suffix == '.txt'
all_classes_id = dict()
with open(class_id_txt, encoding='utf-8') as f:
txt_lines = f.read().splitlines()
assert len(txt_lines) > 0
for txt_line in txt_lines:
class_info = txt_line.split(' ')
if len(class_info) != 2:
raise ValueError('Error parse "class_id_txt" file '
f'{class_id_txt}, please check if some of '
'the class names is blank, like "1 " -> '
'"1 blank", or class name has space between'
' words, like "1 Big house" -> "1 '
'Big-house".')
v, k = class_info
all_classes_id.update({k: int(v)})
else:
all_classes_id = None
# convert to coco json
coco_json_data, category_to_id = parse_labelme_to_coco(
image_dir, labels_dir, all_classes_id)
# save json result
Path(out_path).parent.mkdir(exist_ok=True, parents=True)
print(f'Saving json to {out_path}')
json.dump(coco_json_data, open(out_path, 'w'), indent=2)
if class_id_txt is None:
category_to_id_path = Path(out_path).with_name('class_with_id.txt')
print(f'Saving class id txt to {category_to_id_path}')
with open(category_to_id_path, 'w', encoding='utf-8') as f:
for k, v in category_to_id.items():
f.write(f'{v} {k}\n')
else:
print('Not Saving new class id txt, user should using '
f'{class_id_txt} for training config')
def main():
args = parse_args()
convert_labelme_to_coco(args.img_dir, args.labels_dir, args.out,
args.class_id_txt)
print('All done!')
if __name__ == '__main__':
main()

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)