ssd tensorflow 目标检测 计算 map
目录1、环境搭建2、ssd-tensorflow 项目下载3、文件夹建立4、数据标注5、标注数据整理6、源程序修改7、生成训练数据8、训练模型9、训练中10、tensorboard监控11、测试验证12、tips1、环境搭建win7_64NVIDIA K620显卡安装软件:anaconda4.40Python 3.6.1...
目录
1、环境搭建
win7_64
NVIDIA K620显卡
安装软件:
anaconda4.40
Python 3.6.1
tensorflow -gpu 1.14.0
CUDA 10.0.130
cudnn v7.6.3.30
上述显卡的驱动官网可以下载,但是速度比较慢,我会传一份到网盘。https://pan.baidu.com/s/1XYhRkwuVTQoS2OzZc7tQ-g
因为后续cmd使用很多,建议上GitHub 下载 cmder ,用来执行cmd命令,提高效率。
ssd 模型地址:https://github.com/balancap/SSD-Tensorflow
2、ssd-tensorflow 项目下载
从GitHub上下载项目源文件即可。
3、文件夹建立
下载后,在项目根目录中需要手动建立几个文件夹:
VOC2007
├─test
│ ├─Annotations
│ ├─ImageSets
│ │ └─Main
│ └─JPEGImages
└─train
├─Annotations
├─ImageSets
│ └─Main
└─JPEGImages
文件夹作用说明:(在数据标注后用到)
将用于train的xml,放入train\Annotations ,并将对应jpg,放入train\JPEGImages
将用于test的xml,放入test\Annotations ,并将对应jpg,放入test\JPEGImages
4、数据标注
在GitHub上下在 labelimg软件进行标注。
tips:
1、标注时原始图像大小不一定是300*300或512*512的。对原始图大小没有要求。
作者答复:
During training, the preprocessing methods perform random crop on images and resize everything to 300 x 300 at the end. So the input size should not have an effect on training results (Pascal VOC dataset for instance have images of different sizes). For the IOU, it depends on the threshold you give to the NMS algorithm : the lower it is, the more it will tends to merge overlapping boxes.
2、标注后每个图片有自己的xml描述文件。
3、标注工作的作业目录对后面的训练没有影响,可以将标注完成后的文件拷贝到训练的文件夹下。因为最终是用的与Annotations 同级别的ImageSets中的同名字的img。
5、标注数据整理
将标注后的数据手动分成2类,一部分为train文件,一部分为test。
将用于train的图片放入\train\ImageSets,用于train的图片的xml放入\train\Annotations
同理处理test的图片。
我是 159个训练照片,40个test照片。
每个照片内基本都是3个目标。这3个目标可以是不同的类别。
6、源程序修改
原作者是类别 num_class =20+ 1 (background)
我的对象是num_class 是 12 个
主要目的有几个:1、修改部分bug。2、因为分类数量不同,要修改成自己的项目需要的状态
修改bug:
修改dateset中的pascalvoc_to_tfrecords.py 83行: image_data = tf.gfile.FastGFile(filename, 'r').read()
为: image_data = tf.gfile.FastGFile(filename, 'rb').read()
修改项目差异:(参考:https://www.icode9.com/content-4-45616.html)
1、/datasets/pascalvoc_common.py文件中,24-46行,第一类none不要动,其他的类修改为自己数据集的类。我是判定钢的不同等级,如下:一共12类。
VOC_LABELS = {
'none': (0, 'Background'),
'STEEL_C05': (1, 'STEEL'),
'STEEL_C10': (2, 'STEEL'),
'STEEL_C20': (3, 'STEEL'),
'STEEL_C30': (4, 'STEEL'),
'STEEL_B05': (5, 'STEEL'),
'STEEL_B10': (6, 'STEEL'),
'STEEL_B20': (7, 'STEEL'),
'STEEL_B30': (8, 'STEEL'),
'STEEL_A05': (9, 'STEEL'),
'STEEL_A10': (10, 'STEEL'),
'STEEL_A20': (11, 'STEEL'),
'STEEL_A30': (12, 'STEEL'),
}
2、/datasets/pascalvoc_to_tfrecords.py文件中67行,修改SAMPLES_PER_FILES为几张图片转为一个tfrecord文件,我文件比较少,用的50个为一组
# TFRecords convertion parameters.
RANDOM_SEED = 4242
#SAMPLES_PER_FILES = 200
SAMPLES_PER_FILES = 503、/nets/ssd_vgg_300.py文件中,96-97行的 num_classes 和no_annotation_label改为“类别数+1” 是12+1 。
4、eval_ssd_network.py 文件中,66行,修改num_classes为“类别数+1” 是12+1。
5、nets/ssd_common.py line 257, 301: 修改为 12+1.
6、train_ssd_network.py
line27: 数据格式DATA_FORMAT = 'NCHW' #gpu NHCW -cpu。
line135: 类别个数:12+1
line154: 训练步数:这个自己改了,先给的小的训练看下loss。
7、/datasets/pascalvoc_2007.py文件中,第31行和55行的none类不要动,其他类修改为自己数据集的类,其中括号内的第一个数为图片数,第二个数为目标数(也就是bonding box数,关于如何计算目标数,我写了一个python文件,在附录中),52行和76行的total是所有类的总和。
统计boxing 的Python程序:
# -*- coding: utf-8 -*-
import re
import os
classes='STEEL_C05,STEEL_C10,STEEL_C20,STEEL_C30,STEEL_B05,STEEL_B10,STEEL_B20,STEEL_B30,STEEL_A05,STEEL_A10,STEEL_A20,STEEL_A30'
classAry=classes.split(',')
print(classAry[0])
#创建字典
dic_class_img={}
dic_class_box={}
for cla in classAry:
dic_class_box[cla]=0
dic_class_img[cla]=0
print(dic_class_box)
annotation_folder = './VOC2007/test/Annotations' #改为自己标签文件夹的路径
list = os.listdir(annotation_folder)
img_count=0
for i in range(0, len(list)):
img_count=img_count+1
path = os.path.join(annotation_folder,list[i])
filepath=annotation_folder + '/' + os.path.basename(path)
annotation_file =open(filepath,'rb').read().decode('utf8')
for cla in classAry:
count=len(re.findall(cla, annotation_file))
dic_class_box[cla]=dic_class_box[cla]+ count
if count>0:
dic_class_img[cla]=dic_class_img[cla]+1
print('total img '+str(img_count))
print("box:")
print(dic_class_box)
print("img")
print(dic_class_img)
img_total=0
box_total=0
# print train class
for cla in classAry:
print("'"+cla+"':("+str(dic_class_img[cla])+","+str(dic_class_box[cla])+"),")
img_total=img_total+dic_class_img[cla]
box_total=box_total+dic_class_box[cla]
# cal total
# total 中的img 数量不能重复,就是train或test文件下的img数量,box数量是所有的box的总和
print("'total':("+str(img_count)+","+str(box_total)+"),")
源码修改后的:
格式说明 '类别':(有多少个图片含有这个类,一共有多少个是这个类的box)
所以,在total这一列:
图片的数量 < 上面每个类的图片数量的总和。 即 159 < 84+128+7+0+21+....
boxing的数量 = 上面每个图片中的box数量的总和 即 476= 150+257+....
# (Images, Objects) statistics on every class.
TRAIN_STATISTICS = {
'STEEL_C05':(84,150),
'STEEL_C10':(128,257),
'STEEL_C20':(7,7),
'STEEL_C30':(0,0),
'STEEL_B05':(21,36),
'STEEL_B10':(16,26),
'STEEL_B20':(0,0),
'STEEL_B30':(0,0),
'STEEL_A05':(0,0),
'STEEL_A10':(0,0),
'STEEL_A20':(0,0),
'STEEL_A30':(0,0),
'total':(159,476),
}
TEST_STATISTICS = {
'STEEL_C05':(20,43),
'STEEL_C10':(23,51),
'STEEL_C20':(2,2),
'STEEL_C30':(1,1),
'STEEL_B05':(12,23),
'STEEL_B10':(0,0),
'STEEL_B20':(0,0),
'STEEL_B30':(0,0),
'STEEL_A05':(0,0),
'STEEL_A10':(0,0),
'STEEL_A20':(0,0),
'STEEL_A30':(0,0),
'total':(40,120),
}
SPLITS_TO_SIZES = {
#'train': 5011,
# 'test': 4952,
'train': 159,
'test': 40,
}
SPLITS_TO_STATISTICS = {
'train': TRAIN_STATISTICS,
'test': TEST_STATISTICS,
}
#NUM_CLASSES = 20
NUM_CLASSES = 12 # 不包含背景的数量7、生成训练数据
注意文件目录。
1、训练的tfrecord。在cmd中执行:
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=./VOC2007/train/ \
--output_name=voc_2007_train \
--output_dir=./tfrecords2、测试的tfrecord 。在cmd中执行:
python tf_convert_data.py \
--dataset_name=pascalvoc \
--dataset_dir=./VOC2007/test/ \
--output_name=voc_2007_test \
--output_dir=./tfrecords8、训练模型
参数控制:
修改train_ssd_network.py 62-66行,修改其中多久保存一次文件。
修改train_ssd_network.py 154行 NONE 为自己想要的迭代次数
cmd执行:其中num_classes 是自己的 类数+1
下面是GPU 计算的启动:
python train_ssd_network.py \
--train_dir=./logs/ \
--dataset_dir=./tfrecords \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=./checkpoints/ssd_300_vgg.ckpt \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=6 \
--ignore_missing_vars=True \
--num_classes=13 \
--checkpoint_exclude_scopes =ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \下面是CPU 的启动 要注意6.6 中的数据格式修改。
python train_ssd_network.py \
--train_dir=./logs/ \
--dataset_dir=./tfrecords \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=train \
--model_name=ssd_300_vgg \
--checkpoint_path=./checkpoints/ssd_300_vgg.ckpt \
--save_summaries_secs=60 \
--save_interval_secs=600 \
--weight_decay=0.0005 \
--optimizer=adam \
--learning_rate=0.001 \
--batch_size=6 \
--ignore_missing_vars=True \
--num_classes=13 \
--checkpoint_exclude_scopes =ssd_300_vgg/conv6,ssd_300_vgg/conv7,ssd_300_vgg/block8,ssd_300_vgg/block9,ssd_300_vgg/block10,ssd_300_vgg/block11,ssd_300_vgg/block4_box,ssd_300_vgg/block7_box,ssd_300_vgg/block8_box,ssd_300_vgg/block9_box,ssd_300_vgg/block10_box,ssd_300_vgg/block11_box \
--device=CPU \
--data_format=NHWC \
9、训练中
下面是GPU 计算的截图,CPU 计算的速度很慢
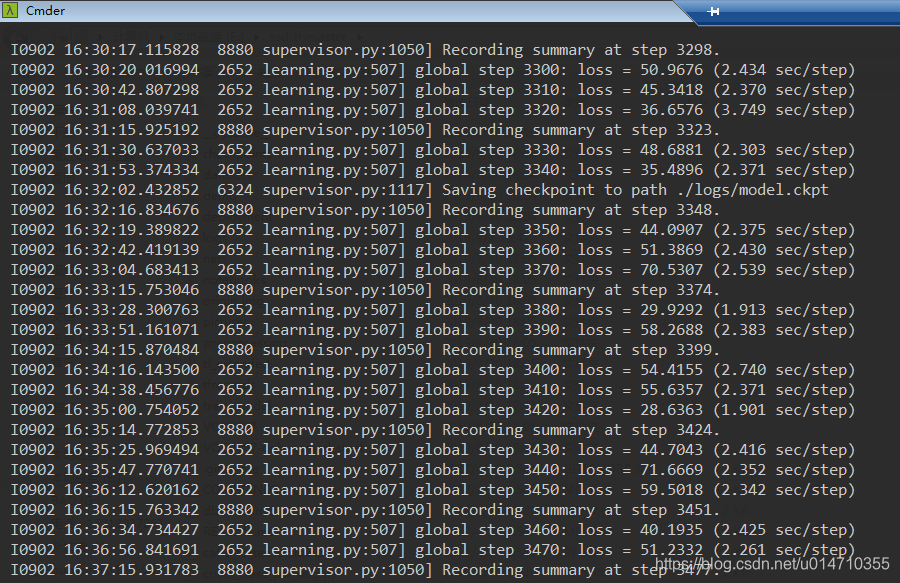
计算过程数据保存在 \logs 中
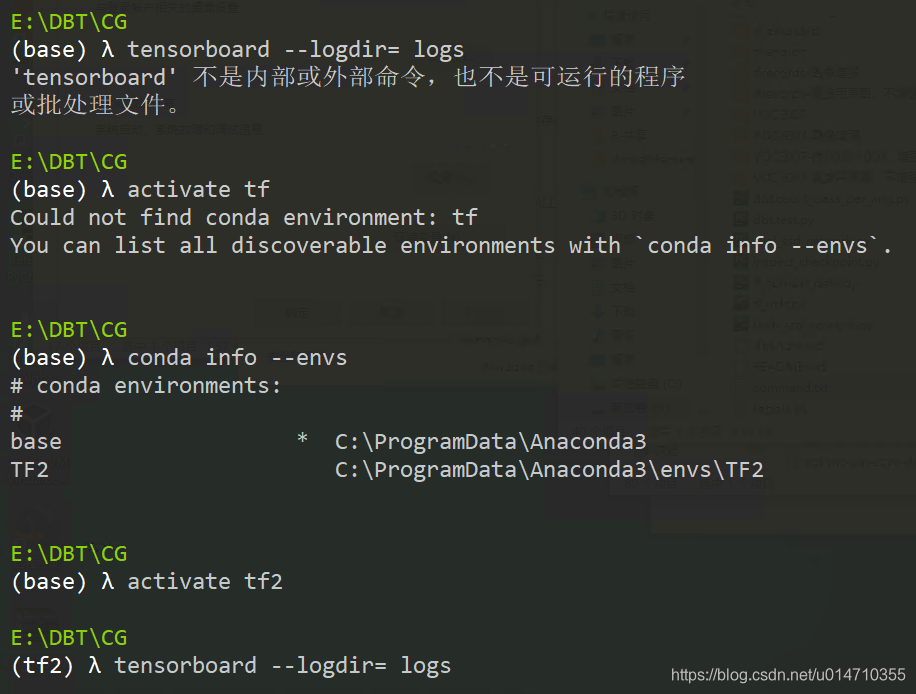
10、tensorboard监控
cmd执行 tensorboard --logdir= logs 文件夹路径
如果报错误,可能是环境变量没有配置,也可能是激活的环境不对。
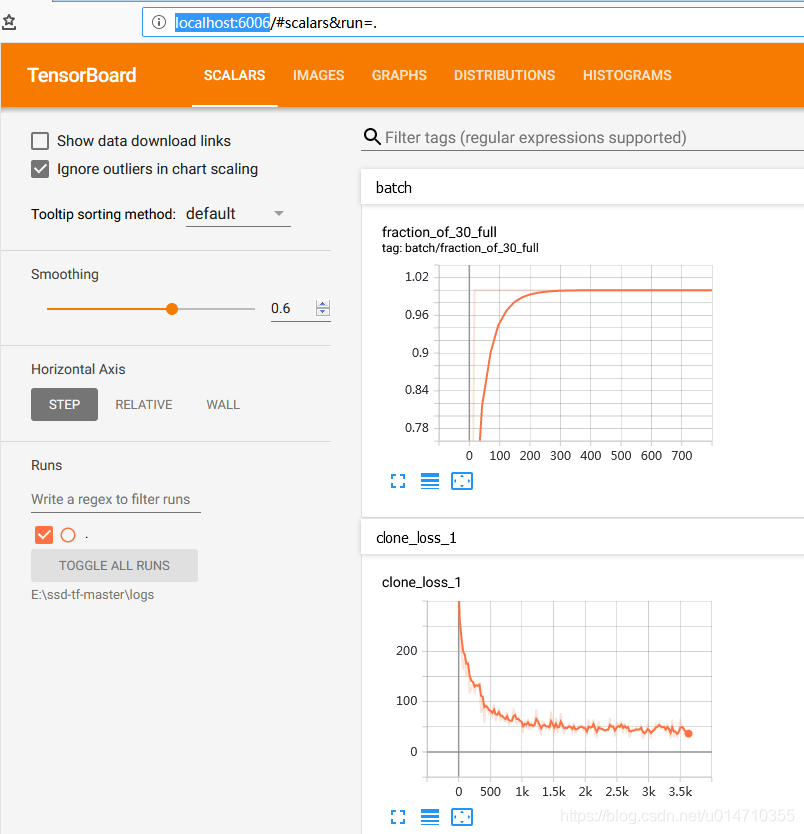
打开浏览器:http://localhost:6006
11、测试验证
如果是用的ssd_300模型,要将log文件夹中最新的如下名字的文件进行修改名字。
model.ckpt-4500.index
model.ckpt-4500.meta
model.ckpt-4500.data-00000-of-00001
只需要其中的 index 和 model.ckpt-4121.data-00000-of-00001 这2个文件,修改名字为下面的形式:
VGG_VOC0712_SSD_300x300_ft_iter_4500.ckpt.index
VGG_VOC0712_SSD_300x300_ft_iter_4500.ckpt.data-00000-of-00001
其中4500 是计算的次数。
然后 cmd 运行 jupyter notebook ssd_notebook.ipynb
浏览器中:
修改ckpt文件路径。
修改类的种类数。
运行即可。

12 map计算
首先修复bug
1 ./tf_extended/metrics.py Line 51.
"return variables.Variable" =>> "return variables.VariableV1"
2、eval_ssd_network.py 中,
在 def main 前面插入一个函数,最后如下:
# paste by dbt
def flatten(x):
result = []
for el in x:
if isinstance(el, tuple):
result.extend(flatten(el))
else:
result.append(el)
return result
def main(_):然后,全文查找eval_op,修改原文中的2处代码。
num_evals=num_batches,
# eval_op=list(names_to_updates.values()),
eval_op=flatten(list(names_to_updates.values())),代码修改完毕。
用单次ckpt计算map 的命令:根据自己的情况修改。
python eval_ssd_network.py \
--eval_dir=./logs/ \
--dataset_dir=./tfrecords \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_300_vgg \
--checkpoint_path=./checkpoints/VGG_VOC0712_SSD_300x300_ft_iter_1249.ckpt \
--batch_size=1 \
--num_classes=类别+背景
结果:
INFO:tensorflow:Evaluation [1/10]
I0513 15:23:34.508572 10124 evaluation.py:167] Evaluation [1/10]
INFO:tensorflow:Evaluation [2/10]
I0513 15:23:34.665219 10124 evaluation.py:167] Evaluation [2/10]
INFO:tensorflow:Evaluation [3/10]
I0513 15:23:34.805458 10124 evaluation.py:167] Evaluation [3/10]
INFO:tensorflow:Evaluation [4/10]
I0513 15:23:34.961698 10124 evaluation.py:167] Evaluation [4/10]
INFO:tensorflow:Evaluation [5/10]
I0513 15:23:35.055441 10124 evaluation.py:167] Evaluation [5/10]
INFO:tensorflow:Evaluation [6/10]
I0513 15:23:35.227406 10124 evaluation.py:167] Evaluation [6/10]
INFO:tensorflow:Evaluation [7/10]
I0513 15:23:35.367915 10124 evaluation.py:167] Evaluation [7/10]
INFO:tensorflow:Evaluation [8/10]
I0513 15:23:35.539777 10124 evaluation.py:167] Evaluation [8/10]
INFO:tensorflow:Evaluation [9/10]
I0513 15:23:35.680413 10124 evaluation.py:167] Evaluation [9/10]
INFO:tensorflow:Evaluation [10/10]
I0513 15:23:35.836731 10124 evaluation.py:167] Evaluation [10/10]
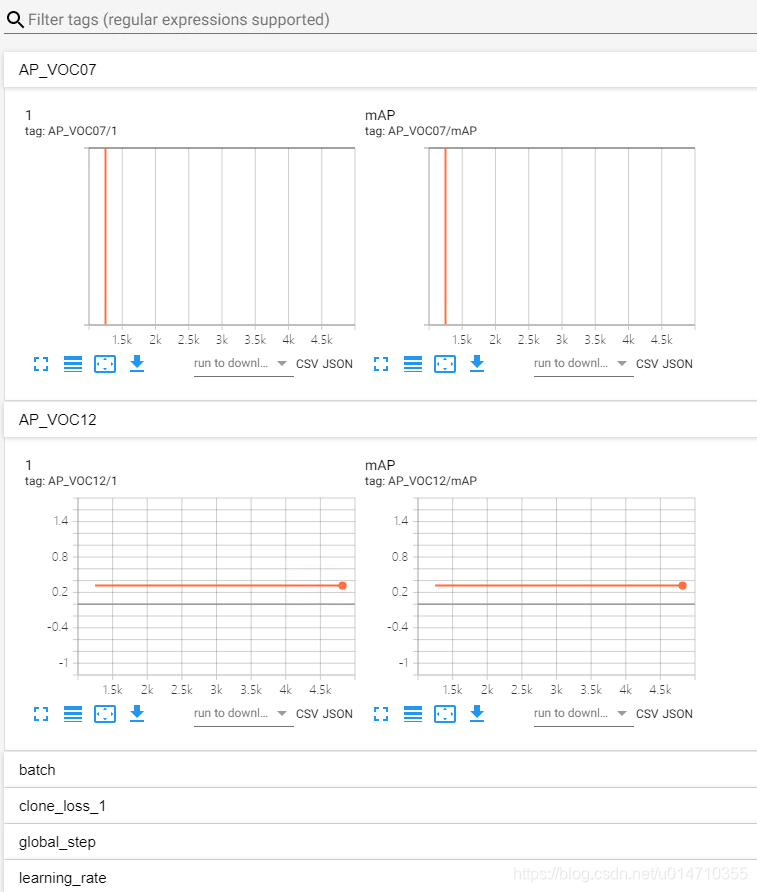
AP_VOC07/mAP[0.31858368837260659]
AP_VOC12/mAP[0.31584457148441314]
INFO:tensorflow:Finished evaluation at 2020-05-13-15:23:36
I0513 15:23:36.539761 10124 evaluation.py:275] Finished evaluation at 2020-05-13-15:23:36
Time spent : 10.984 seconds.
Time spent per BATCH: 1.098 seconds.在计算中,连续计算map,每次产生新的ckpt,就自动计算map
python eval_ssd_network.py \
--eval_dir=./logs/ \
--dataset_dir=./tfrecords \
--dataset_name=pascalvoc_2007 \
--dataset_split_name=test \
--model_name=ssd_300_vgg \
--checkpoint_path=./logs \ train过程中心的ckpt存放的目录
--batch_size=1 \
--wait_for_checkpoints=True \
--batch_size=1 \
--max_num_batches=100
--num_classes=类别+背景
就可以在tensorboard 中看到map的变化了,我找个模型还没有调好。
13、tips
tensorflow 数据类型
NCHW 用于GPU
NHWC 用于CPU
参考:
4、源码修改说明
5、详细的训练说明

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)