
tensorflow学习(8)- 使用AdamOptimizer优化器优化手写数字识别
前言上一节:tensorflow学习(7)- 使用Dropout优化手写数字识别 上一节使用Dropout优化手写数字识别,使得识别率已经达到95%以上,但是我们手写数字识别在网络上并不复杂,而且训练集只是在万级别也不是很大,所以可以不必使用Dropout来提高准确率,这一节使用修改优化器的方式来优化识别。AdamOptimizer优化器def __init__(self, lear...
·
前言
上一节:tensorflow学习(7)- 使用Dropout优化手写数字识别
上一节使用Dropout优化手写数字识别,使得识别率已经达到95%以上,但是我们手写数字识别在网络上并不复杂,而且训练集只是在万级别也不是很大,所以可以不必使用Dropout来提高准确率,这一节使用修改优化器的方式来优化识别。
AdamOptimizer优化器
def __init__(self, learning_rate=0.001, beta1=0.9, beta2=0.999, epsilon=1e-8,
use_locking=False, name="Adam"):
这是优化器的初始化函数,我们可以看到即使不传递学习率的初始值这个优化器也是可以使用的,这一节中使用的是指数下降的学习率传入我们的优化器中作为学习率,在我们每一轮的学习中,我们不断的调小学习率,这样最开始的时候学习率较大收敛的越快,慢慢的接近极值的时候降低学习率使得不会出现跃过极值的可能。
代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("../MNIST_DATA", one_hot=True)
batch_size = 100 # 可优化
n_batch = int(mnist.train.num_examples / batch_size)
# 定义两个placeholder(训练数据集和标签)
x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10])
# dropout的所要训练神经元的比例
keep_prob = tf.placeholder(tf.float32)
# 学习率
lr = tf.Variable(0.001, dtype=tf.float32)
# 创建简单神经网络
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1))
b1 = tf.Variable(tf.zeros([500]) + 0.1)
L1 = tf.nn.tanh(tf.matmul(x, W1) + b1)
L1_drop = tf.nn.dropout(L1, keep_prob)
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1))
b2 = tf.Variable(tf.zeros([300]) + 0.1)
L2 = tf.nn.tanh(tf.matmul(L1_drop, W2) + b2)
L2_drop = tf.nn.dropout(L2, keep_prob)
W4 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1))
b4 = tf.Variable(tf.zeros([10]) + 0.1)
predict = tf.nn.softmax(tf.matmul(L2_drop, W4) + b4)
# 交叉熵代价函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(labels=y, logits=predict))
# 使用AdamOptimizer训练,使得loss最小(#可优化)
train_step = tf.train.AdamOptimizer(lr).minimize(loss)
# 初始化变量
init = tf.global_variables_initializer()
# 比较概率最大的标签是否相同,结果存放在一个布尔型列表中
correct_predict = tf.equal(tf.argmax(y, 1), tf.argmax(predict, 1)) # argmax返回一维张量中最大值所在的位置
# 求准确率
accuracy = tf.reduce_mean(tf.cast(correct_predict, tf.float32)) # reduce_mean求平均值
with tf.Session() as sess:
sess.run(init)
for epoch in range(51): # 可优化
sess.run(tf.assign(lr, 0.001 * (0.95 ** epoch)))# 指数降低学习率
for batch in range(n_batch): # 把所有图片训练一次
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
#使得keep_prob等于100%则表示不使用dropout
sess.run(train_step, feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.0})
learningRate = sess.run(lr)
# 用测试数据来检验训练好的模型
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.
# train_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob:
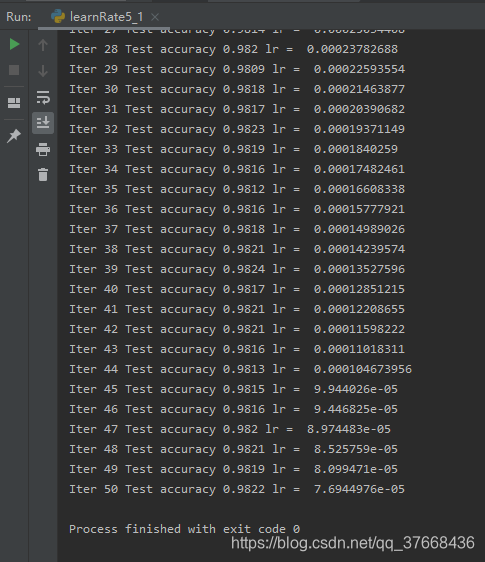
print("Iter " + str(epoch) + " Test accuracy " + str(test_acc) + " lr = " + str(learningRate))
运行结果

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)