
ism模型python算法_python运筹优化(七):利用遗传算法为机器学习模型调参
作为一名熟练的机器学习调包侠和调参侠,面临的一个很大的问题就是机器学习模型有很多超参数需要人工去调参,超参数的设置很大程度上影响着模型最后预测结果的好坏。特征工程和调参是机器学习算法运用中最耗费人工的2个部分。那么如何利用遗传算法进行把调参变得“高大上”呢?这其实已经触碰到了时下最火热的AutoML(自动化机器学习)的领域了:自动化调参,不需要人工。本文的案例将使用svm算法做iris鸢尾花分类,
作为一名熟练的机器学习调包侠和调参侠,面临的一个很大的问题就是机器学习模型有很多超参数需要人工去调参,超参数的设置很大程度上影响着模型最后预测结果的好坏。特征工程和调参是机器学习算法运用中最耗费人工的2个部分。
那么如何利用遗传算法进行把调参变得“高大上”呢?这其实已经触碰到了时下最火热的AutoML(自动化机器学习)的领域了:自动化调参,不需要人工。
本文的案例将使用svm算法做iris鸢尾花分类,我们的任务就是优化SVM中的两个超参数C和Gamma。
这个问题的写法跟之前的单目标优化问题的写法很不一样,因为它不只是涉及决策变量C和Gamma,还涉及训练特征data_train。假设我们的预测值是:
那么我们的目标函数是最大化模型的预测结果的分类准确度:
一、geatpy数据结构
怎么利用geatpy做自动化调参呢?我们需要先了解geatpy的Phen、objV等数据结构长啥样,才能理解代码怎么写。当然这部分也可以不看直接看第二部分,但是会比较难理解第二部分中的实践代码。
1、种群染色体Chrom
Geatpy中,种群染色体是一个ap.array类型的二维矩阵,一般用Chrom命名,每一行对应一个个体的一条染色体。
我们一般把种群的规模(即种群的个体数)用Nind命名;把种群个体的染色体长度用Lind命名,则Chrom
的结构如下所示:

2、种群表现型Phen
种群表现型的数据结构跟种群染色体基本一致,也是numpy的array类型。我们一般用Phen来命名。是种群染色体矩阵Chrom经过解码后得到的基因表现型矩阵,每一行对应一个个体,每一列对应一个决策变量。若用N var表示变量的个数,则种群表现型矩阵Phen的结构如下图:

3、目标函数ObjV
目标函数是一个np.array,也就是每一个样本的分类结果的交叉验证得分。
Geatpy采用np.array类型矩阵来存储种群的目标函数值。一般命名为ObjV,每一行对应每一个个体,因此它拥有与Chrom相同的行数;每一列对应一个目标函数。

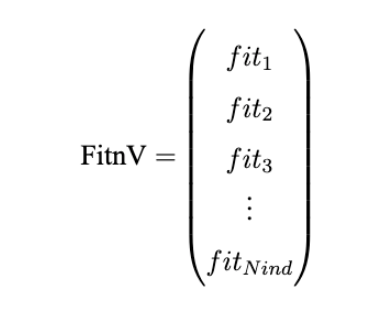
4、个体适应度FitnV
Geatpy采用列向量来存储种群个体适应度。一般命名为F itnV,它同样是np.array类型,每一行对应种群矩阵的每一个个体。因此它拥有与Chrom相同的行数。
5、违反约束程度CV
CV(Constraint Violation Value)来存储种群个踢违反各个约束条件的程度。一般命名为CV,它的每一行对应种群的每一个个体。每一列对应一个约束条件,因此若有一个约束条件。则CV矩阵的结构如下图所示:

CV矩阵的某个元素若小于或等于0,则表示该元素对应的个体满足对应的约束条件,也就是我们之前一直使用的"可行性法则"来定义约束条件。
6、译码矩阵FiledV
Geatpy使用译码矩阵(俗称区域描述器)来描述种群染色体的特征,如染色体中的每一位元素所表达的决策变量的范围、是否包含范围的边界、采用二进制还是格雷码、是否使用对数刻度、染色体解码后所代表的决策变量的是连续型变量还是离散型变量等等。

7、进化追踪器trace
在使用Geatpy进行进化算法编程时,常常建立一个进化追踪器(如pop_trace)来记录种群在进化的过程中各代的最优个体。其中MAXGEN是种群进化的代数。trace的每一列代表不同的指标,比如第一列记录各代种群的最佳目标函数值,第二列记录各代种群的平均目标函数值......trace的每一行对应每一代,如第一行代表第一代,第二行代表第二代......
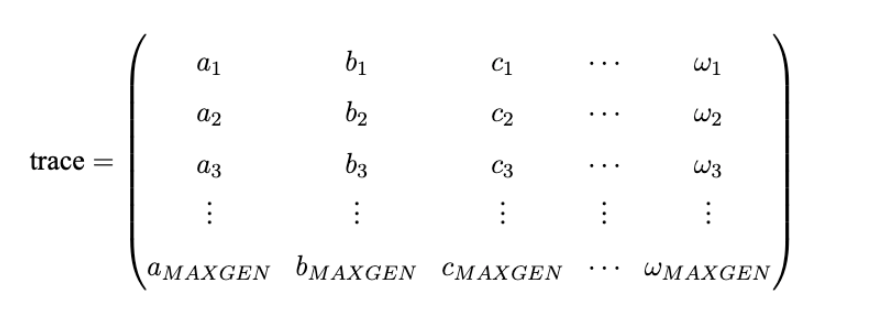
8、population类
在Geatpy提供的面向对象进化算法框架中,种群类(Population)是一个存储着与种群个体相关信息的类。它有以下基本属性:

二、遗传算法调参SVM
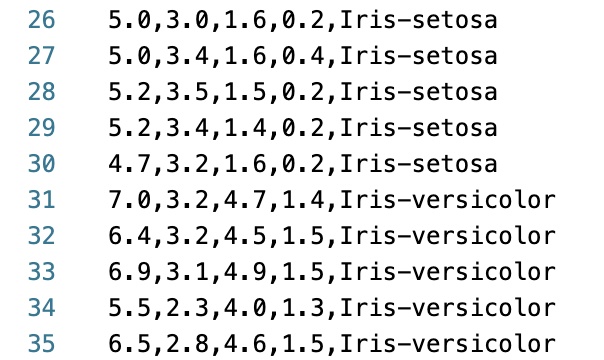
1、iris鸢尾花分类数据集
一个经典的分类问题数据集,数据集http://archive.ics.uci.edu/ml/datasets/Iris。训练集长这样子,前4列是特征,最后一列是鸢尾花的分类target:
2、geatpy工作流程
我们之前单目标优化问题的解决办法的大概流程是:
- 随机初始化第一代种群的个体Phen;
- 可行性约束CV;
- 计算个体的适应度(可以理解为目标函数上的表现好坏);
- 选择、交叉、变异、进化
- 得到最优种群的最优个体
在机器学习自动化调参中也是类似的,这里主要需要理解的是把每一次的模型训练(决策变量C和Gamma采用RI实整数编码)作为种群的一个个体!
- 种群数量NIND = 50代表第一代种群先进行50次的模型训练作为50个初始个体,每次训练的[C,G](当然每次训练的C和G还是随机初始化的)就是这个个体的的染色体;
- 目标函数就是训练集上的分类准确度(当然下面代码用的交叉验证分数,含义其实是一样的);
- 选择、交叉、变异、进化
- 最后末代种群中的最优个体得到我们想要的C和Gamma,把这两个参数代入到测试集上计算测试集结果
3、geatpy和sklearn.svm实践
# -*- coding: utf-8 -*-
import numpy as np
import geatpy as ea
from sklearn import svm
from sklearn import preprocessing
from sklearn.model_selection import cross_val_score
import multiprocessing as mp
from multiprocessing import Pool as ProcessPool
from multiprocessing.dummy import Pool as ThreadPool
"""
该案例展示了如何利用进化算法+多进程/多线程来优化SVM中的两个参数:C和Gamma。
在执行本案例前,需要确保正确安装sklearn,以保证SVM部分的代码能够正常执行。
本函数需要用到一个外部数据集,存放在同目录下的iris.data中,
并且把iris.data按3:2划分为训练集数据iris_train.data和测试集数据iris_test.data。
有关该数据集的详细描述详见http://archive.ics.uci.edu/ml/datasets/Iris
在执行脚本main.py中设置PoolType字符串来控制采用的是多进程还是多线程。
注意:使用多进程时,程序必须以“if __name__ == '__main__':”作为入口,
这个是multiprocessing的多进程模块的硬性要求。
"""
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self, PoolType): # PoolType是取值为'Process'或'Thread'的字符串
name = 'MyProblem' # 初始化name(函数名称,可以随意设置)
M = 1 # 初始化M(目标维数)
maxormins = [-1] # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 2 # 初始化Dim(决策变量维数)
varTypes = [0, 0] # 初始化varTypes(决策变量的类型,元素为0表示对应的变量是连续的;1表示是离散的)
lb = [2**(-8)] * Dim # 决策变量下界
ub = [2**8] * Dim # 决策变量上界
lbin = [1] * Dim # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] * Dim # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
# 目标函数计算中用到的一些数据
fp = open('iris_train.data')
datas = []
data_targets = []
for line in fp.readlines():
line_data = line.strip('n').split(',')
data = []
for i in line_data[0:4]:
data.append(float(i))
datas.append(data)
data_targets.append(line_data[4])
fp.close()
self.data = preprocessing.scale(np.array(datas)) # 训练集的特征数据(归一化)
self.dataTarget = np.array(data_targets)
# 设置用多线程还是多进程
self.PoolType = PoolType
if self.PoolType == 'Thread':
self.pool = ThreadPool(2) # 设置池的大小
elif self.PoolType == 'Process':
num_cores = int(mp.cpu_count()) # 获得计算机的核心数
self.pool = ProcessPool(num_cores) # 设置池的大小
def aimFunc(self, pop): # 目标函数,采用多线程加速计算
Vars = pop.Phen # 得到决策变量矩阵
args = list(zip(list(range(pop.sizes)), [Vars] * pop.sizes, [self.data] * pop.sizes, [self.dataTarget] * pop.sizes)) # pop.sizes就是种群的规模,args=[[种群大小],[决策变量*种群大小],[特征*种群大小],[分类target*种群大小]],args含义见下面subAimFunc(args)函数
if self.PoolType == 'Thread':
pop.ObjV = np.array(list(self.pool.map(subAimFunc, args))) # 目标函数是一个np.array,也就是每次调参的分类结果的交叉验证得分
elif self.PoolType == 'Process':
result = self.pool.map_async(subAimFunc, args)
result.wait()
pop.ObjV = np.array(result.get())
def test(self, C, G): # 代入优化后的C、Gamma对测试集进行检验
# 读取测试集数据
fp = open('iris_test.data')
datas = []
data_targets = []
for line in fp.readlines():
line_data = line.strip('n').split(',')
data = []
for i in line_data[0:4]:
data.append(float(i))
datas.append(data)
data_targets.append(line_data[4])
fp.close()
data_test = preprocessing.scale(np.array(datas)) # 测试集的特征数据(归一化)
dataTarget_test = np.array(data_targets) # 测试集的标签数据
svc = svm.SVC(C=C, kernel='rbf', gamma=G).fit(self.data, self.dataTarget) # 创建分类器对象并用训练集的数据拟合分类器模型
dataTarget_predict = svc.predict(data_test) # 采用训练好的分类器对象对测试集数据进行预测
print("测试集数据分类正确率 = %s%%"%(len(np.where(dataTarget_predict == dataTarget_test)[0]) / len(dataTarget_test) * 100))
def subAimFunc(args): # 计算每一次模型调参的分类结果的交叉验证得分,模型一共训练了pop.sizes次,每一次的模型训练作为一个种群的样本
i = args[0]
Vars = args[1]
data = args[2]
dataTarget = args[3]
C = Vars[i, 0] # 调参1
G = Vars[i, 1] # 调参2
svc = svm.SVC(C=C, kernel='rbf', gamma=G).fit(data, dataTarget) # 创建分类器对象并用训练集的数据拟合分类器模型
scores = cross_val_score(svc, data, dataTarget, cv=30) # 计算交叉验证的得分
ObjV_i = [scores.mean()] # 把交叉验证的平均得分作为目标函数值
return ObjV_i# -*- coding: utf-8 -*-
import numpy as np
import geatpy as ea # import geatpy
if __name__ == '__main__':
"""===============================实例化问题对象==========================="""
PoolType = 'Process' # 设置采用多进程,若修改为: PoolType = 'Thread',则表示用多线程
problem = MyProblem(PoolType) # 生成问题对象
"""=================================种群设置==============================="""
Encoding = 'RI' # 编码方式
NIND = 50 # 种群规模
Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges, problem.borders) # 创建区域描述器
population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被初始化,仅仅是完成种群对象的实例化)
"""===============================算法参数设置============================="""
myAlgorithm = ea.soea_DE_rand_1_bin_templet(problem, population) # 实例化一个算法模板对象
myAlgorithm.MAXGEN = 30 # 最大进化代数
myAlgorithm.trappedValue = 1e-6 # “进化停滞”判断阈值
myAlgorithm.maxTrappedCount = 10 # 进化停滞计数器最大上限值,如果连续maxTrappedCount代被判定进化陷入停滞,则终止进化
"""==========================调用算法模板进行种群进化======================="""
[population, obj_trace, var_trace] = myAlgorithm.run() # 执行算法模板
population.save() # 把最后一代种群的信息保存到文件中
problem.pool.close() # 及时关闭问题类中的池,否则在采用多进程运算后内存得不到释放
# 输出结果
best_gen = np.argmin(problem.maxormins * obj_trace[:, 1]) # 记录最优种群个体是在哪一代
best_ObjV = obj_trace[best_gen, 1]
print('最优的目标函数值为:%s'%(best_ObjV))
print('最优的控制变量值为:')
for i in range(var_trace.shape[1]):
print(var_trace[best_gen, i])
print('有效进化代数:%s'%(obj_trace.shape[0]))
print('最优的一代是第 %s 代'%(best_gen + 1))
print('评价次数:%s'%(myAlgorithm.evalsNum))
print('时间已过 %s 秒'%(myAlgorithm.passTime))
"""=================================检验结果==============================="""
problem.test(C = var_trace[best_gen, 0], G = var_trace[best_gen, 1])4、最优的调参结果
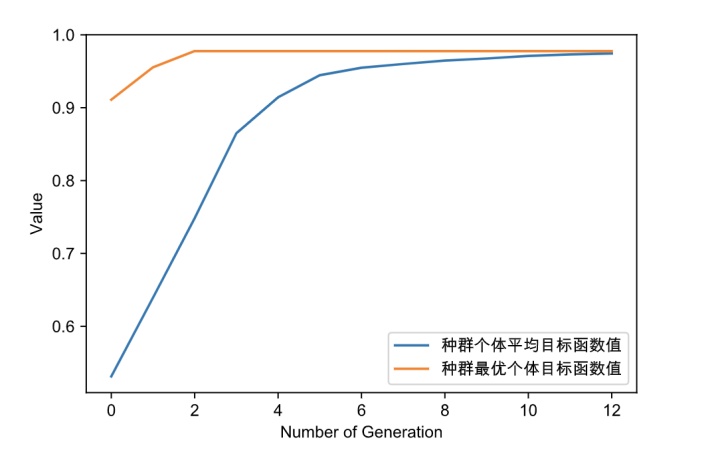
可以看到最优的C=31.07733,G=0.0039,此时训练集的分类正确率达到97.78%,训练好的模型在测试集的分类正确率是96.67%
种群信息导出完毕。
最优的目标函数值为:0.9777777777777777
最优的控制变量值为:
31.077336355576506
0.00390625
有效进化代数:13 #连续10代没有提升,因此停止继续迭代
最优的一代是第 3 代 评价次数:650
时间已过 11.694092035293579 秒
测试集数据分类正确率 = 96.66666666666667%参考
【1】geatpy数据结构:http://geatpy.com/index.php/2019/07/28/2-geatpy%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/
【2】geatpy_soea_demo6:https://github.com/geatpy-dev/geatpy/blob/master/geatpy/demo/soea_demo/soea_demo6/MyProblem.py

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)