
机器学习面试:决策树疑难杂症
adboost在干什么adboost能有什么思想呢?boost的思想非常简单,
文章目录
1. 决策树为何不适用时间序列
趋势性非常强的数据,gbdt是没有办法拟合的,以单tree为例,tree的叶子节点的值是已知标签的值的平均,而对于gbdt的集成模型而言,某个样本是其落在的所有子树的叶子上的值的加权平均(权重是学习率),这导致的问题就是我们的预测结果一定是介于序列数据的最大和最小值之间的,例如[1,2,3,4,5,6,…1000],使用tree或者集成决策树最终预测的结果在绝大部分情况下不会大于1000,这就意味着一旦我们未来的日子,销量突破新高,例如到达了2000或者3000.。。。等等,tree是预测不出来的,这也是为什么我使用原始标签进行预测总是发现模型预测的结果偏小,小了很多,因为我使用的是所有的历史数据。
gbdt不适用于什么样的时间序列问题 - 马东什么的文章 - 知乎
2. 决策树模型怎么处理异常值
-
随机森林把数值型变量(numerical variables)中的缺失值用其所对应的类别中(class)的中位数(median)替换,描述型变量(categorical variables)缺失的部分用所对应类别中出现最多的数值替代
-
xgboost把缺失值当做稀疏矩阵来对待,本身的在节点分裂时不考虑的缺失值的数值。缺失值数据会被分到左子树和右子树分别计算损失,选择较优的那一个。如果训练中没有数据缺失,预测时出现了数据缺失,那么默认被分类到右子树。这样的处理方法固然巧妙,但也有风险:即我们假设了训练数据和预测数据的分布相同,比如缺失值的分布也相同。
怎么理解决策树、xgboost能处理缺失值?而有的模型(svm)对缺失值比较敏感呢? - 微调的回答 - 知乎
3. 决策树受共线性影响吗
决策树本质上不受多重共线性的影响但是会对特征重要性分析(相关特征)中的极端情况产生影响。
例如,有两个特征完全相关的特征A和特征B,在筛选特征时,对于一棵特定的树,如果算法需要其中之一,它将随机选择。其他模型(例如逻辑回归)将同时使用这两个特征。
在Random Forests中,将对每棵树进行此随机选择,因为每棵树都彼此独立。因此,大约有50%的树将选择特征A,而另外50%的树将选择特征B。因此,A和B中包含的信息的重要性(这是相同的,因为它们完全相关) )稀释在A和B中。因此,将不容易知道此信息对于预测要预测的内容很重要!当您拥有10个相关功能时,情况更糟……
在增强算法中,当算法已经了解了特征和结果之间的特定联系时,它将尝试不重新关注它(理论上就是这样,现实并不总是那么简单)。因此,所有的重要性都将在特征A或特征B上(但不能同时在两者上)。
当两列之间的相关性为1时,xgboost会在计算模型之前删除多余的列,因此重要性不受影响。但是,当您添加部分与另一列相关的列,因此系数较低时,原始变量x的重要性降低。
例如,样本中有一列特征为 x x x,我们复制一列 x x x命名为 x 1 x_{1} x1,即 x = x 1 x=x_{1} x=x1,xgboost在计算时会直接删除一列,但是当我们新增一列 x 2 = x 2 x_{2}=x^{2} x2=x2时,两列的相关性较低时,原始变量 x x x的重要性将会降低。类似地,如果我添加相关系数 r = 0.4 , 0.5 , 0.6 r = 0.4,0.5,0.6 r=0.4,0.5,0.6的新变量, x x x的重要性会降低,尽管只是一点点。
Does XGBoost handle multicollinearity by itself?
4. 为什么GBDT的树深度较RF通常都比较浅
对于机器学习来说,泛化误差可以理解为两部分,分别是偏差(bias)和方差(variance);偏差指的是算法的期望预测与真实预测之间的偏差程度,反应了模型本身的拟合能力;方差度量了同等大小的训练集的变动导致学习性能的变化,刻画了数据扰动所导致的影响。当模型越复杂时,拟合的程度就越高,模型的训练偏差就越小;但此时如果换一组数据可能模型的变化就会很大,即模型的方差很大,所以模型过于复杂的时候会导致过拟合。
对于RF来说由于并行训练很多不同的分类器的目的就是降低这个方差(variance)。所以对于每个基分类器来说,目标就是如何降低这个偏差(bias),所以我们会采用深度很深甚至不剪枝的决策树。
而对于GBDT来说由于利用的是残差逼近的方式,即在上一轮的基础上更加拟合原数据,所以可以保证偏差(bias),所以对于每个基分类器来说,问题就在于如何选择 variance 更小的分类器,即更简单的分类器,所以我们选择了深度很浅的决策树。
5. GBDT的训练能否并行
GBDT是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。可以看到,GBDT每一次训练出来的弱分类器都会被用来进行下一个弱分类器的训练。因此,GBDT每个弱分类器是无法进行并行训练的。
6. 梯度提升树中为什么说目标函数关于当前模型的负梯度是残差的近似值?
我们希望找到一个 f ( x ) f(x) f(x)使得 L ( y , f ( x ) ) L(y,f(x)) L(y,f(x)) 最小,那么 f ( x ) f(x) f(x) 就得沿着使损失函数L减小的方向变化,即:
f n e w ( x ) = f o l d ( x ) − α ∗ ∂ L ( y , f ( x ) ) ∂ f ( x ) f_{new}(x)=f_{old}(x)-\alpha * \frac{\partial L(y,f(x))}{\partial f(x)} fnew(x)=fold(x)−α∗∂f(x)∂L(y,f(x))
同时,最新的学习器是由当前学习器 f ( x ) f(x) f(x) 与本次要产生的回归树 T 1 T_{1} T1相加得到的:
f n e w ( x ) = f o l d ( x ) + α ∗ T 1 f_{new}(x)=f_{old}(x)+\alpha*T_{1} fnew(x)=fold(x)+α∗T1
因此,为了让损失函数减小,需要令:
− ∂ L ( y , f ( x ) ) ∂ f ( x ) = T 1 -\frac{\partial L(y,f(x))}{\partial f(x)}=T_{1} −∂f(x)∂L(y,f(x))=T1
即用损失函数对f(x)的负梯度来拟合回归树。
我们从头来捋一下,给定一个数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) . . . ( x N , y N ) } T=\{(x_{1},y_{1}),(x_{2},y_{2})...(x_{N},y_{N})\} T={(x1,y1),(x2,y2)...(xN,yN)}我们是假设数据服从某一种分布,例如高斯分布,logstic分布等等,这个时候要做的就是估计参数。例如告诉你数据服从高斯分布,你就要根据当前的数据算出均值和方差,logstic的话需要计算系数(决策树是对数据空间的切分)。
很多时候我们不能很好的定义数据分布,那我们直接定义假设函数为 f ( x , y , w ) f(x,y,w) f(x,y,w),然后通过最大似然估计 m a x w f ( x i , y i , w ) max_{w}f(x_{i},y_{i},w) maxwf(xi,yi,w),求得 w w w。也可以用户函数拟合的思想去考虑,让 f ( x , w ) f(x,w) f(x,w)去逼近 y y y,差距越小,说明我们的函数拟合越好。这个时候需要定义一个指标来表示我们拟合的优劣,称作损失函数 L ( y , f ( x , w ) ) L(y,f(x,w)) L(y,f(x,w))。现在变成了求解最优化的问题
w ∗ = a r g m i n L ( y , f ( x , w ) ) w^{*}=argmin L(y,f(x,w)) w∗=argminL(y,f(x,w))
现在该如何求 w w w呢,这个时候就可以请出梯度下降算法求解最有值,根据定义知道,梯度是函数下降最快的方向,我们每次沿着梯度的方向走,最终就可以到达最优值
w t = w t − 1 − ∂ L ( y , f ( x , w ) ) ∂ w w_{t}=w_{t-1}-\frac{\partial L(y,f(x,w))}{\partial w} wt=wt−1−∂w∂L(y,f(x,w))
后面就会衍生出SGD和batch SGD我就不详细的展开了。
我们再进一步,不对参数进行求导了,直接对函数进行求导,直接更新函数
f t ( x ) = f t − 1 ( x ) − ∂ L ( y , f ( x ) ) ∂ f ( x ) f_{t}(x)=f_{t-1}(x)-\frac{\partial L(y,f(x))}{\partial f(x)} ft(x)=ft−1(x)−∂f(x)∂L(y,f(x))
到这里我们就发现了一个有趣的地方,梯度提升树和梯度下降好像一摸一样,不同的是一个对参数进行求导,一个直接是对函数进行求导。但是有一点是一样的,都是沿着梯度的方向进行更新。参数基本上都是一个值例如是5,梯度也很好求解,假设算出的梯度是2,那么更新后的参数就变成了5-2=3,这个非常好理解。
但 是 函 数 呢 ? 函 数 的 导 数 是 什 么 , 也 是 一 个 数 值 吗 ( 是 的 ) 但是函数呢?函数的导数是什么,也是一个数值吗(是的) 但是函数呢?函数的导数是什么,也是一个数值吗(是的)
这里就是我一直困惑的地方,其实这里并不是说要对函数进行求导,只是使用了梯度下降和boost的思想。boost的核心就是通过前向加法组合多个弱分类器,这里 T ( x ) T(x) T(x)是弱分类器
f m ( x ) = f m − 1 ( x ) + T ( x ) f_{m}(x)=f_{m−1}(x)+T(x) fm(x)=fm−1(x)+T(x)
使用boost时我们需要考虑的一个问题,每次用什么标准来添加若分类器,结合刚才梯度下降的思想,新添加的函数要是跟梯度一致就很好,这里就得到了
− ∂ L ( y , f ( x ) ) ∂ f ( x ) = T ( x ) -\frac{\partial L(y,f(x))}{\partial f(x)}=T(x) −∂f(x)∂L(y,f(x))=T(x)
如果做的是回归,损失函数定义成MSE
L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y,f(x))=(y-f(x))^{2} L(y,f(x))=(y−f(x))2
此时梯度就是
− ∂ L ( y , f ( x ) ) ∂ f ( x ) = − ( − ( y − f ( x ) ) ) = y − f ( x ) = T ( x ) -\frac{\partial L(y,f(x))}{\partial f(x)}=-(-(y-f(x)))=y-f(x)=T(x) −∂f(x)∂L(y,f(x))=−(−(y−f(x)))=y−f(x)=T(x)
定义 y y y和 f ( x ) f(x) f(x)为残差 r = y − f ( x ) r=y-f(x) r=y−f(x),也就是说我们要找的新的若分类需要拟合的梯度巧好是上一轮的残差。
7. GBDT是如何分类的
首先明确一点,gbdt 无论用于分类还是回归一直都是使用的CART 回归树。不会因为我们所选择的任务是分类任务就选用分类树,这里面的核心是因为gbdt 每轮的训练是在上一轮的训练的残差基础之上进行训练的。这里的残差就是当前模型的负梯度值 。这个要求每轮迭代的时候,弱分类器的输出的结果相减是有意义的。如果选用的弱分类器是分类树,类别相减是没有意义的。例如上一轮预测 x 是男性,本轮预测x是女性那么相减后得到的是????
回归的时候我们会选用mse损失函数,分类的时候会使用对数似然损失函数。
GBDT本身是一种思想,我们在构建若分类器的时候不一样非要使用决策树,也可以使用简单的神经网络,多分段的线形回归等等。
8. GBDT如何构建决策树
- 根据原始数据集T构建第一颗的树(都是cart树),
f 0 ( x ) = a r g m i n L ( y i , f ( x ) ) f_{0}(x)=argmin L(y_{i},f(x)) f0(x)=argminL(yi,f(x)) - 计算每个样本的梯度, g i = − ∂ L ( y , f ( x ) ) ∂ f ( x ) g_{i} = -\frac{\partial L(y,f(x))}{\partial f(x)} gi=−∂f(x)∂L(y,f(x))构建新的数据集 T = { ( x 1 , g 1 ) , ( x 2 , g 2 ) . . . ( x n , g n ) } T=\{(x_{1},g_{1}),(x_{2},g_{2})...(x_{n},g_{n})\} T={(x1,g1),(x2,g2)...(xn,gn)}
- 根据新的数据集构建一个新的树
- 迭代计算2,3步,得到最后的决策树
def __init__(self, n_estimators, learning_rate, min_samples_split,
min_impurity, max_depth, regression):
self.n_estimators = n_estimators
self.learning_rate = learning_rate
self.min_samples_split = min_samples_split
self.min_impurity = min_impurity
self.max_depth = max_depth
self.regression = regression
# 进度条 processbar
self.bar = progressbar.ProgressBar(widgets=bar_widgets)
self.loss = SquareLoss()
if not self.regression:
self.loss = SotfMaxLoss()
# 分类问题也使用回归树,利用残差去学习概率
self.trees = []
for i in range(self.n_estimators):
self.trees.append(RegressionTree(min_samples_split=self.min_samples_split,
min_impurity=self.min_impurity,
max_depth=self.max_depth))
def fit(self, X, y):
self.trees[0].fit(X, y) # 拟合第一颗树,现在没有梯度
y_pred = self.trees[0].predict(X) # 得到预测值
for i in self.bar(range(1, self.n_estimators)):
gradient = self.loss.gradient(y, y_pred) # 输入预测值与真实值求出梯度
self.trees[i].fit(X, gradient)
# 这里又一个学习率,通过更小步的迭代可以防止GBDT过拟合,跟参数空间中的学习率作用相同
y_pred -= np.multiply(self.learning_rate, self.trees[i].predict(X))
def fit(self, X, y):
# 让第一棵树去拟合模型
self.trees[0].fit(X, y)
y_pred = self.trees[0].predict(X)
for i in self.bar(range(1, self.n_estimators)):
gradient = self.loss.gradient(y, y_pred)
self.trees[i].fit(X, gradient)
y_pred -= np.multiply(self.learning_rate, self.trees[i].predict(X))
常用机器学习算法实现与讲解
从 AdaBoost 到 GBDT 梯度提升树
提升树模型:GBDT原理与实践

梯度提升树(GBDT)原理小结
CTR预估-GBDT与LR实现
9. 逻辑回归LR的特征为什么要先离散化
在工业界,很少直接将连续值作为特征喂给逻辑回归模型,而是将连续特征离散化为一系列0、1特征交给逻辑回归模型,这样做的优势有以下几点:
-
稀疏向量内积乘法运算速度快,计算结果方便存储,容易scalable(扩展)。
-
离散化后的特征对异常数据有很强的鲁棒性:比如一个特征是年龄>30是1,否则0。如果特征没有离散化,一个异常数据“年龄300岁”会给模型造成很大的干扰。
-
逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合。
-
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力。
-
特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。当然处于区间相邻处的样本会刚好相反,所以怎么划分区间是门学问。
模型是使用离散特征还是连续特征,其实是一个“海量离散特征+简单模型” 同 “少量连续特征+复杂模型”的权衡。既可以离散化用线性模型,也可以用连续特征加深度学习。就看是喜欢折腾特征还是折腾模型了。通常来说,前者容易,而且可以n个人一起并行做,有成功经验;后者目前看很赞,能走多远还须拭目以待。
大概的理解:
1)计算简单
2)简化模型
3)增强模型的泛化能力,不易受噪声的影响
连续特征的离散化:在什么情况下将连续的特征离散化之后可以获得更好的效果? - 严林的回答 - 知乎
10.GBDT+LR而非RF+LR呢?
RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,可以想象,不同的树,交叉的特征都是不相同的。而RF前后建树是没有什么相关性的,不同的树可能存在重复的特征交叉。
XGBOOST
xgb和gbdt本质是一样的,xgb使用的也是回归树(当然还有很多其他的)
xgboost与gbdt有一点很不相同,xgboost在计算叶子节点的时候是直接根据损失函数来的,求得的叶子节点值是当前损失函数的最优值,并且xgb在分裂节点的时候是根据损失函数来的,使得损失函数减小的节点才会进行分裂。而gbdt在计算叶子节点值的时候很不一样,gbdt的损失函数与节点分裂可以完全不同的,例如损失函数可以是mse,但是分裂的时候使用的是gini系数,这个mse完全不沾边,所以说gbdt分裂的时候其实使用的是启发式(虽然我也不太懂什么叫启发式)但是分裂后的叶子节点的值是根据损失函数计算的。
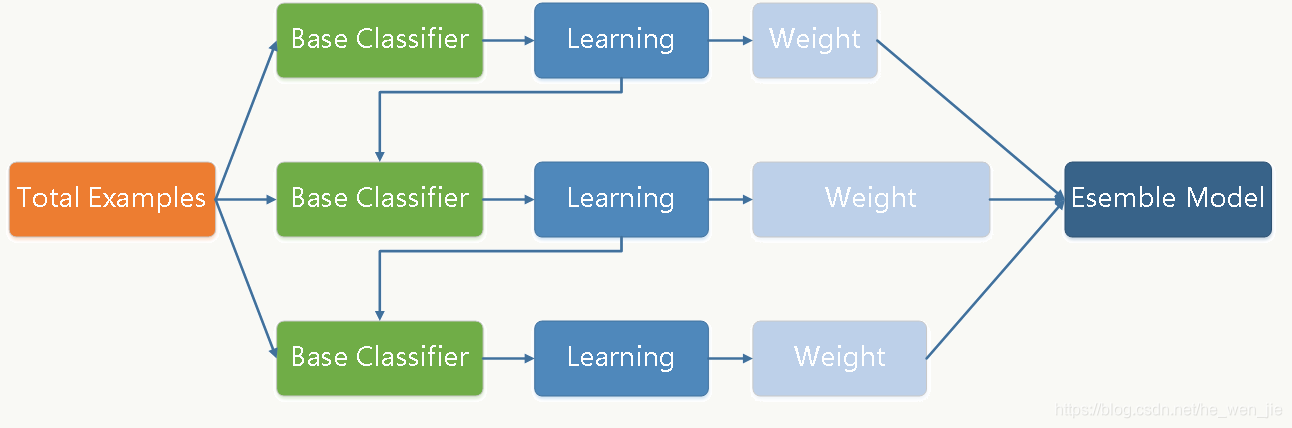
集成学习如何减小方差
在bagging和boosting框架中,通过计算基模型的期望和方差,我们可以得到模型整体的期望和方差。为了简化模型,我们假设基模型的权重、方差及两两间的相关系数相等。由于bagging和boosting的基模型都是线性组成的,那么有:
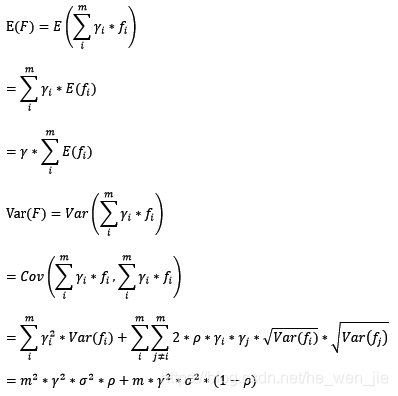
3.2 bagging的偏差和方差
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
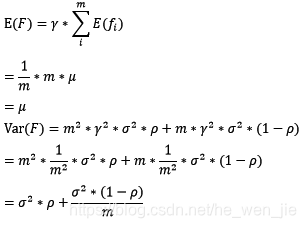
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
3.3 boosting的偏差和方差
对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
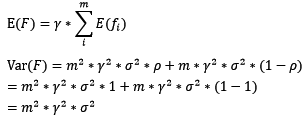
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同Random Forrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
3.4 模型的独立性
聪明的读者这时肯定要问了,如何衡量基模型的独立性?我们说过,抽样的随机性决定了模型的随机性,如果两个模型的训练集抽样过程不独立,则两个模型则不独立。这时便有一个天大的陷阱在等着我们:bagging中基模型的训练样本都是独立的随机抽样,但是基模型却不独立呢?
我们讨论模型的随机性时,抽样是针对于样本的整体。而bagging中的抽样是针对于训练集(整体的子集),所以并不能称其为对整体的独立随机抽样。那么到底bagging中基模型的相关性体现在哪呢?在知乎问答《为什么说bagging是减少variance,而boosting是减少bias?》中请教用户“过拟合”后,我总结bagging的抽样为两个过程:
样本抽样:整体模型F(X1, X2, …, Xn)中各输入随机变量(X1, X2, …, Xn)对样本的抽样
子抽样:从整体模型F(X1, X2, …, Xn)中随机抽取若干输入随机变量成为基模型的输入随机变量
假若在子抽样的过程中,两个基模型抽取的输入随机变量有一定的重合,那么这两个基模型对整体样本的抽样将不再独立,这时基模型之间便具有了相关性。
3.5 小结
还记得调参的目标吗:模型在训练集上的准确度和防止过拟合能力的大和谐!为此,我们目前做了一些什么工作呢?
使用模型的偏差和方差来描述其在训练集上的准确度和防止过拟合的能力
对于bagging来说,整体模型的偏差和基模型近似,随着训练的进行,整体模型的方差降低
对于boosting来说,整体模型的初始偏差较高,方差较低,随着训练的进行,整体模型的偏差降低(虽然也不幸地伴随着方差增高),当训练过度时,因方差增高,整体模型的准确度反而降低
整体模型的偏差和方差与基模型的偏差和方差息息相关
这下总算有点开朗了,那些让我们抓狂的参数,现在可以粗略地分为两类了:控制整体训练过程的参数和基模型的参数,这两类参数都在影响着模型在训练集上的准确度以及防止过拟合的能力。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)