毕业设计:python招聘数据分析可视化系统 招聘推荐 薪资预测 机器学习 爬虫 决策树回归模型 XGBoost回归模型 Flask框架 前程无忧(源码+文档)✅
毕业设计:python招聘数据分析可视化系统 招聘推荐 薪资预测 机器学习 爬虫 决策树回归模型 XGBoost回归模型 Flask框架 前程无忧(源码+文档)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
python语言、Flask框架、xgboost、前程无忧网站、requests爬虫 决策树回归模型、XGBoost回归模型。
招聘数据分析 爬虫 推荐 薪资预测 机器学习双模型 前程无忧 文档
2、项目界面
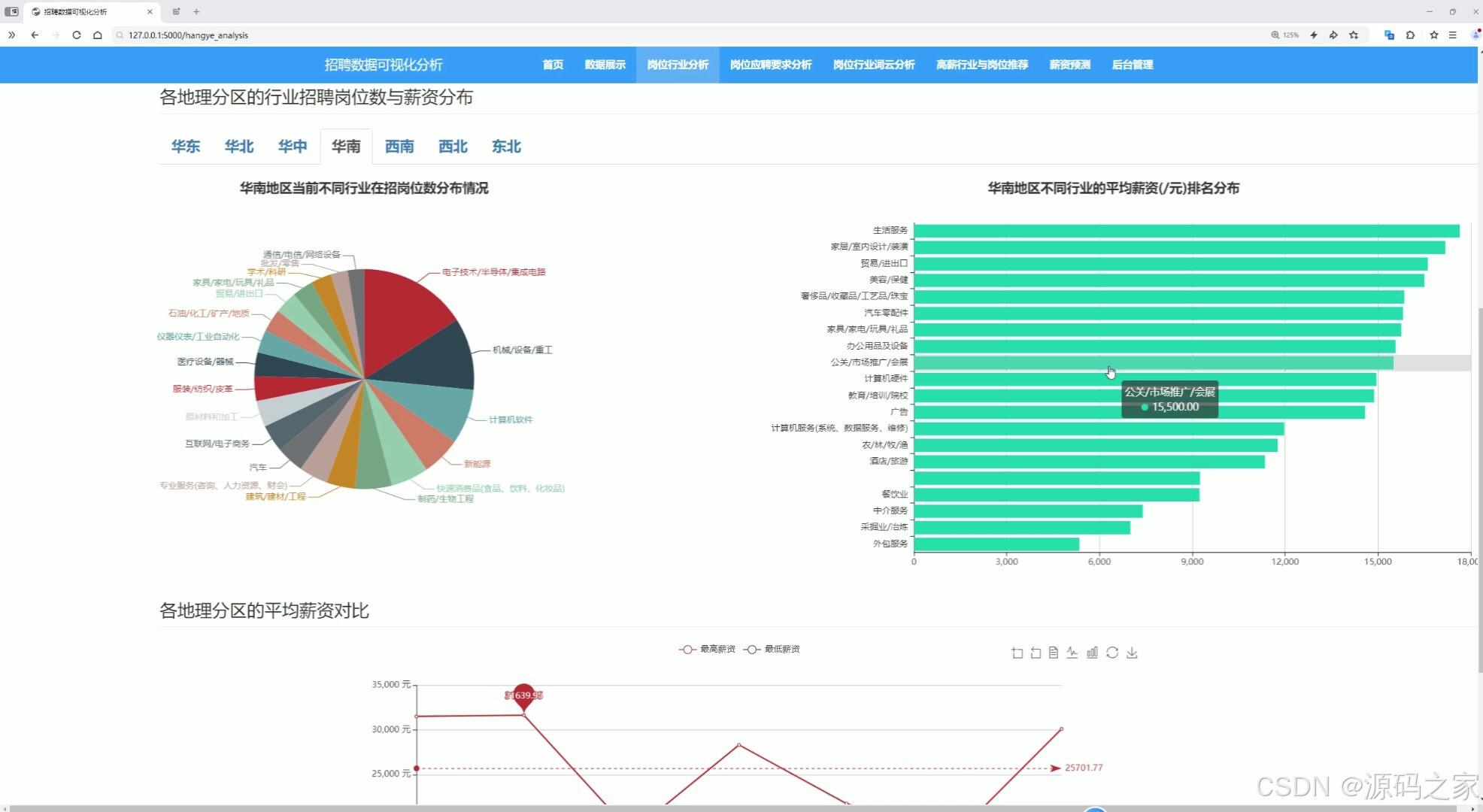
(1)岗位行业分析
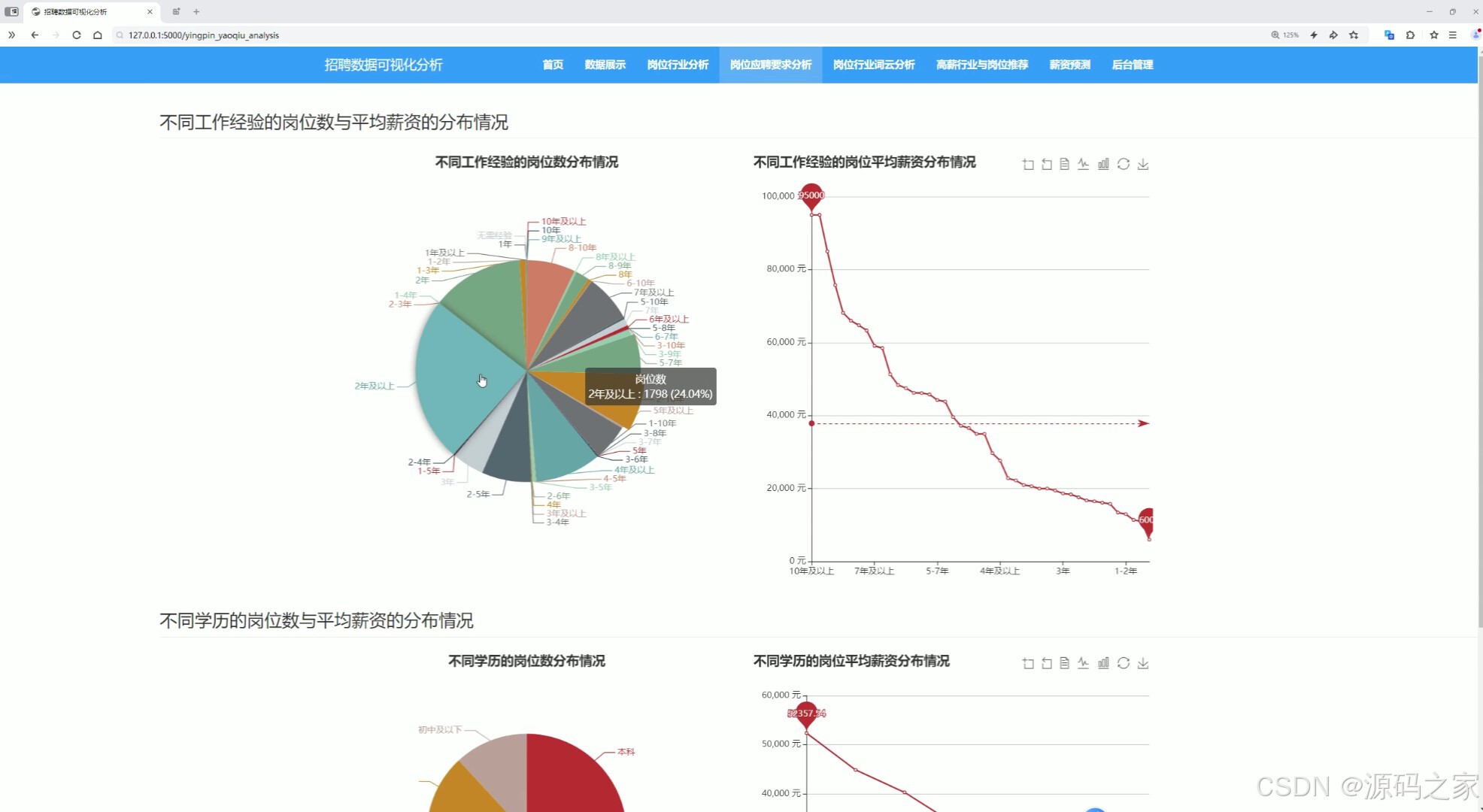
(2)岗位应聘要求分析
(3)数据中心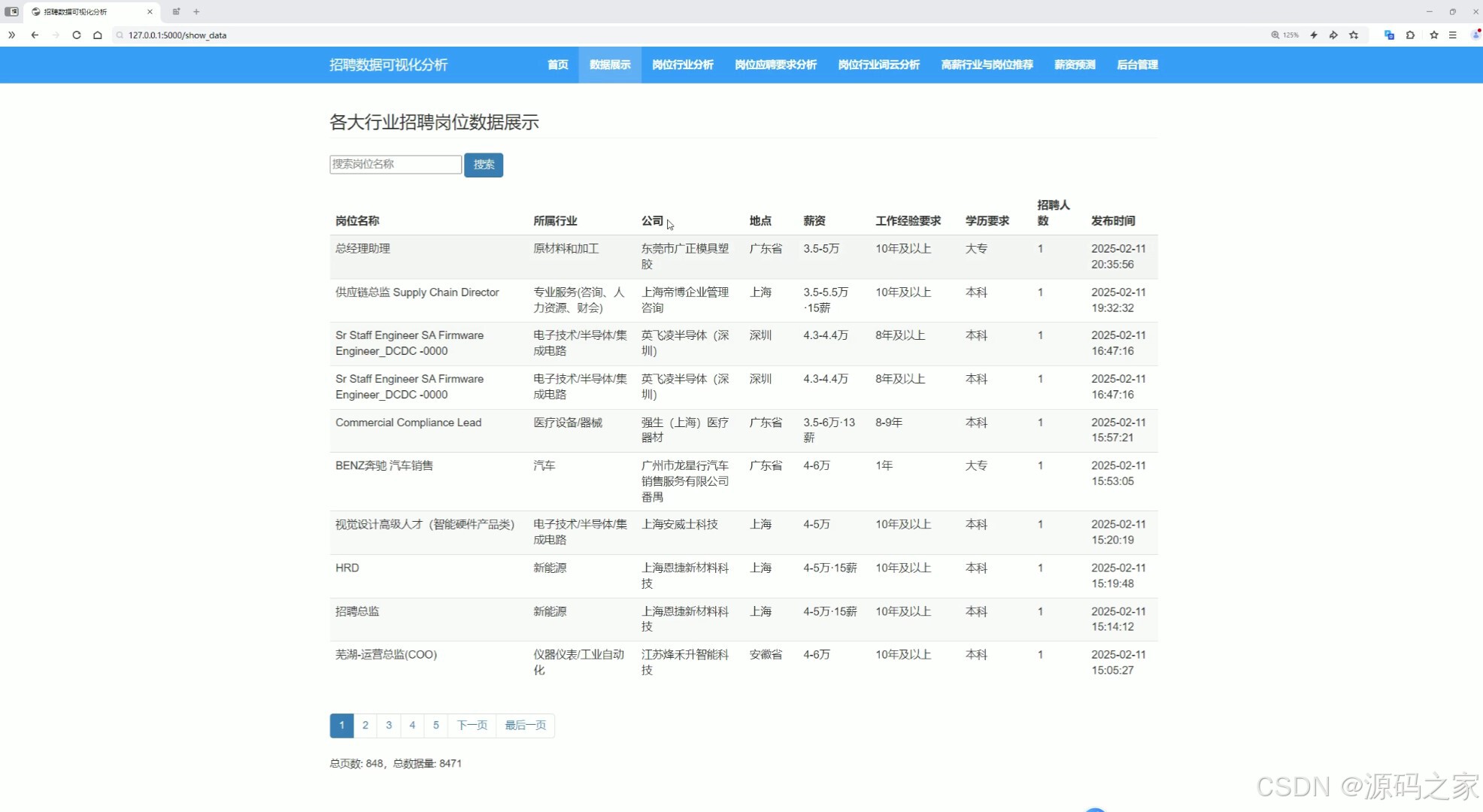
(4)词云图分析
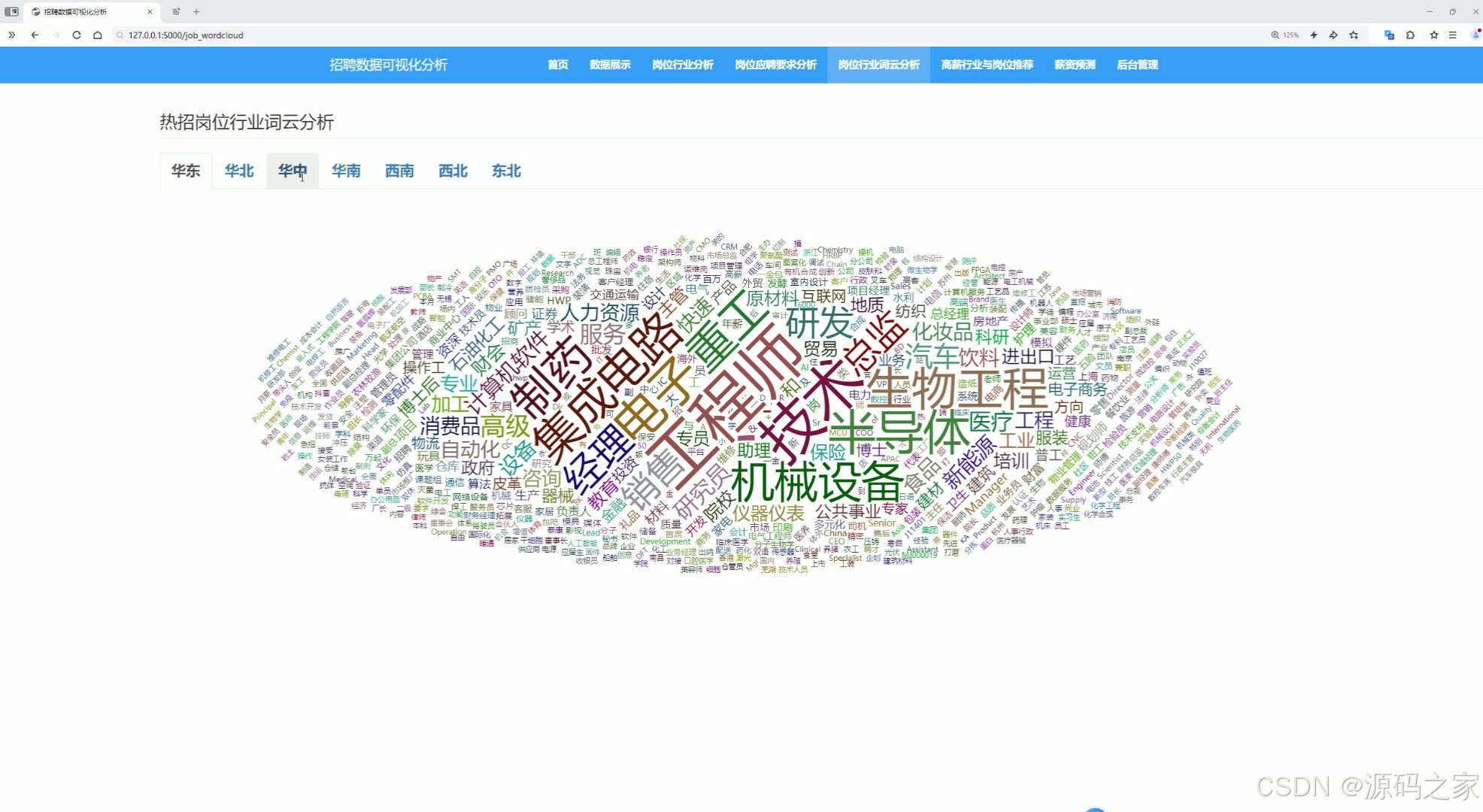
(5)高薪行业与岗位推荐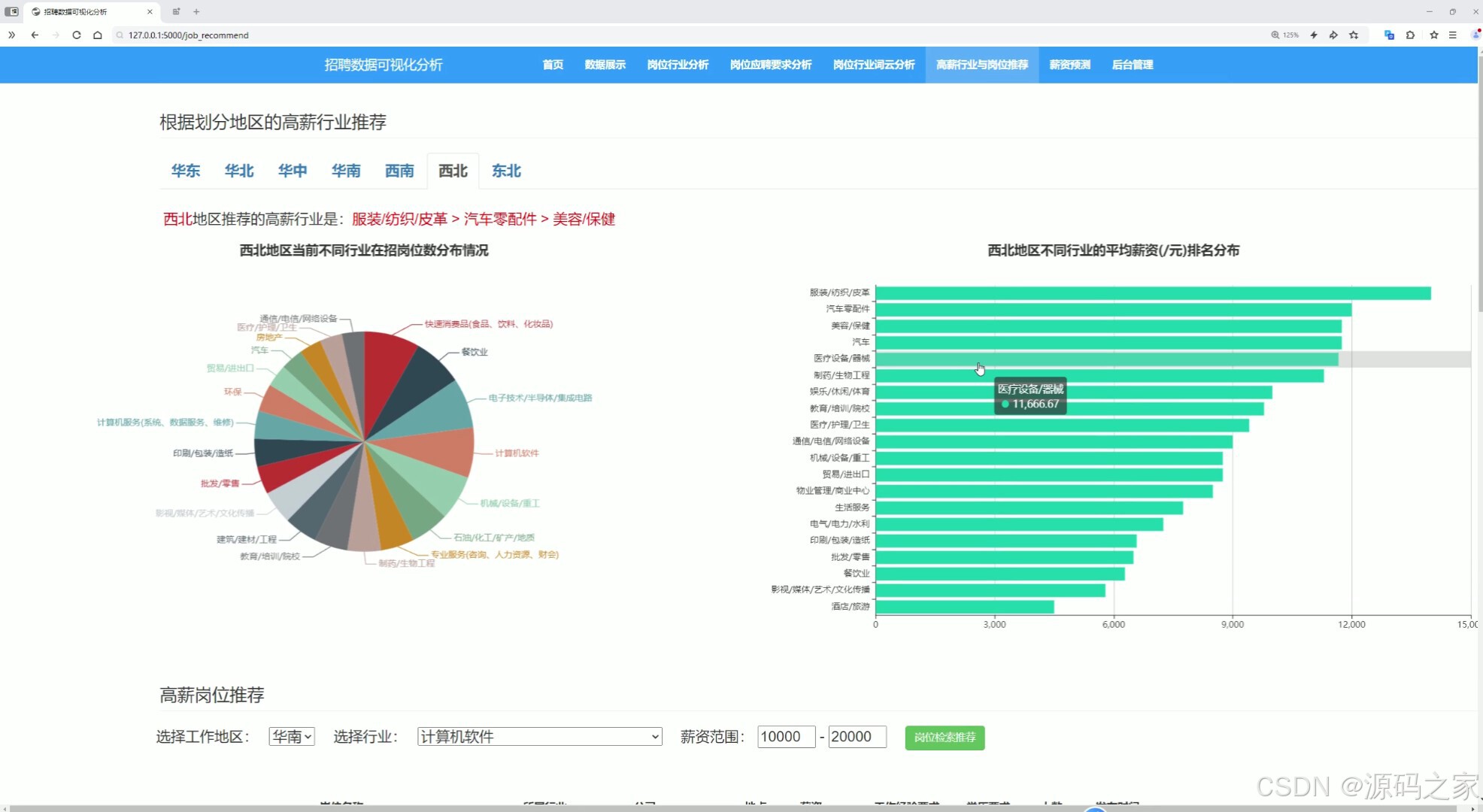
(6)薪资预测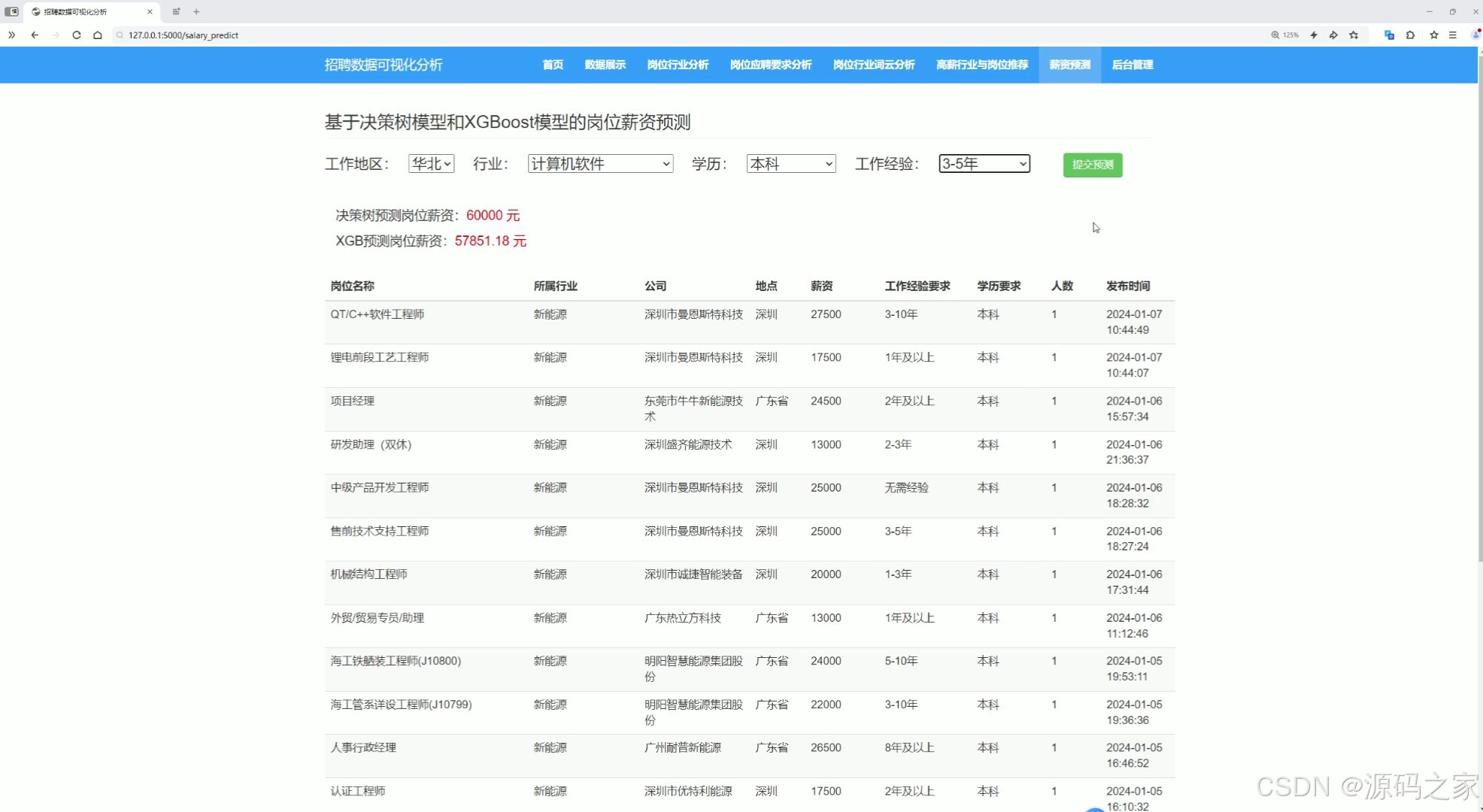
(7)后台管理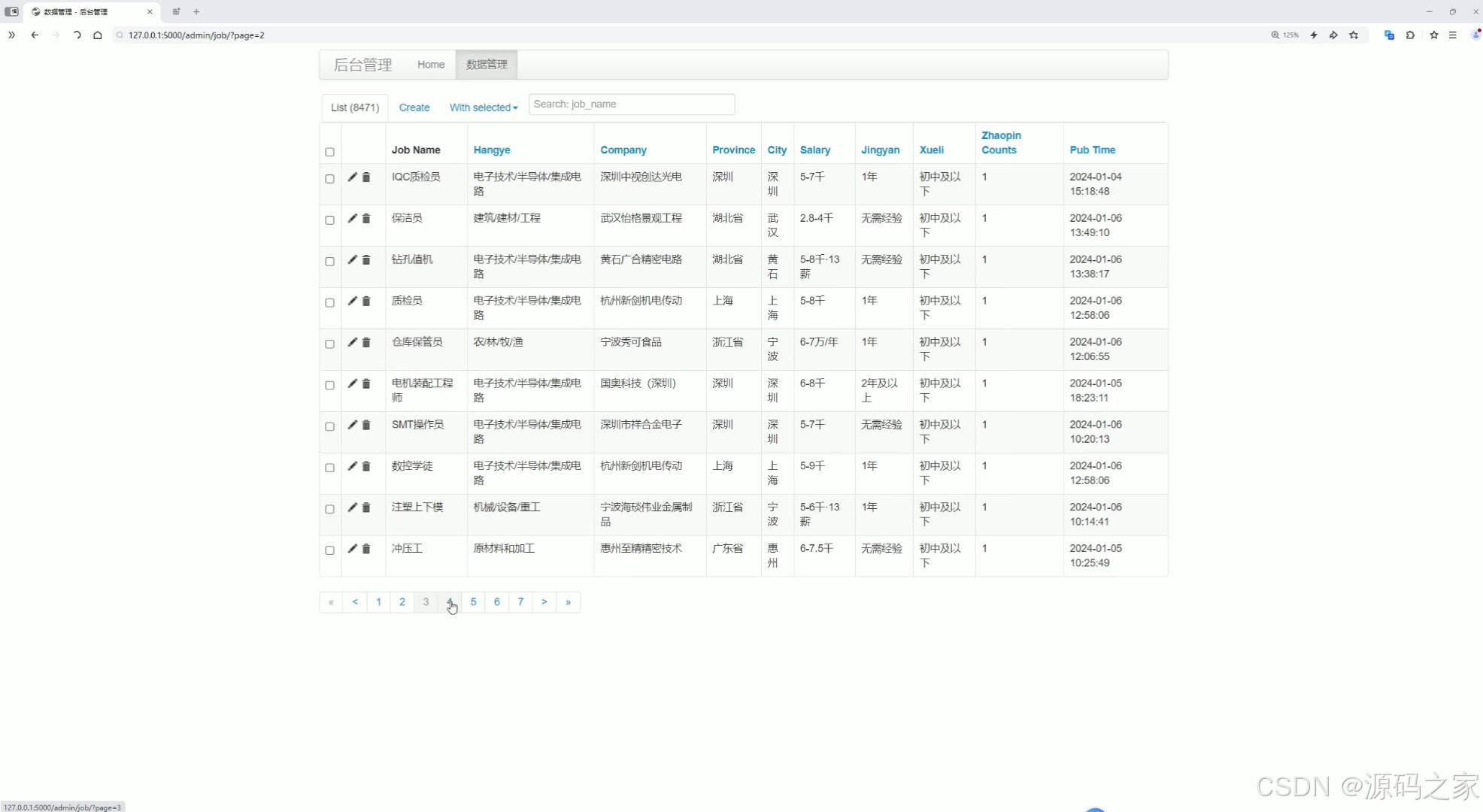
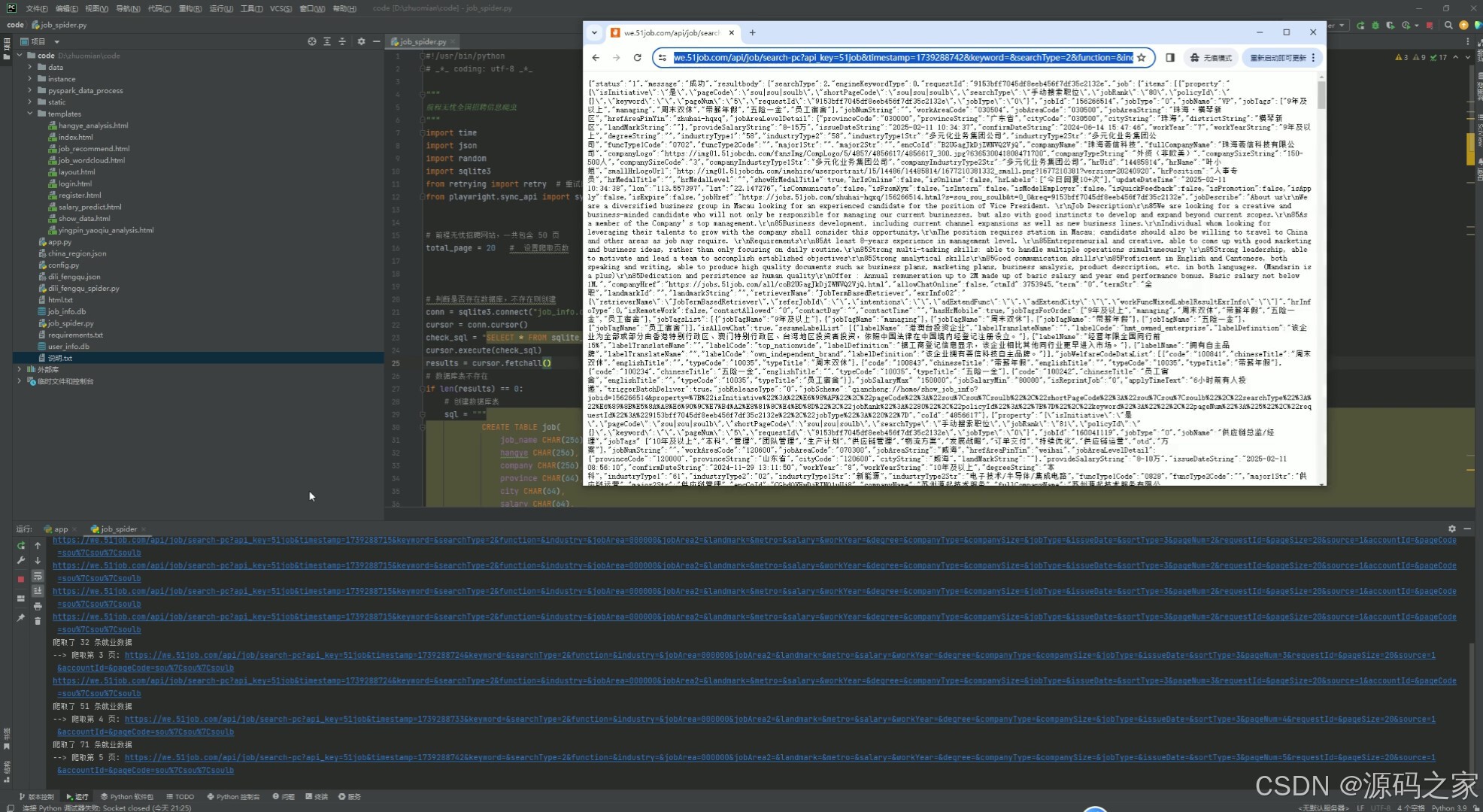
(8)数据采集
(9)注册登录
3、项目说明
本项目利用 Python 从前程无忧招聘网站抓取招聘数据,进行数据清洗和格式化后存储到关系型数据库中(如mysql、sqlite等),利用 Flask + Bootstrap + Echarts 搭建招聘信息可视化分析系统,
实现不同岗位的学历要求、工作经验、技能要求、薪资待遇等维度的可视化分析,并根据岗位所在地进行不同地域(华东、华北、华中、华南、西南、西北和东北)维度的细粒度分析。
同时依据用户需求实现热门岗位的推荐,并利用机器学习决策树模型和XGBoost模型的岗位薪资预测。
一、预测模块
利用机器学习决策树模型和XGBoost模型的岗位薪资预测。
完成了两个机器学习模型的训练和评估:决策树回归模型和XGBoost回归模型。
简要步骤如下:
1、数据预处理:
将类别数据映射为数值数据。
提取目标变量 y 和特征变量 X。
2、导入机器学习库:
导入必要的机器学习库。
3、训练决策树回归模型:
创建决策树回归模型。
划分训练集和测试集。
训练模型并评估性能(MAE 和 R²)。
4、训练 XGBoost 回归模型:
划分训练集和测试集。
创建 XGBoost 回归模型。
训练模型并评估性能(MAE 和 R²)。
5、调用函数:
调用函数训练两个模型。
4、核心代码
def calc_salary(salary):
"""
薪资数值化
"""
salary = salary.split('·')[0]
salary_data = salary.split('-')
if len(salary_data) != 2:
return None, None, None
min_salary, max_salary = salary.split('-')[0], salary.split('-')[1]
if '年' in salary:
return None, None, None
if max_salary.endswith('千'):
max_scale = 1000
max_salary = max_salary[:-1]
elif salary.endswith('万'):
max_scale = 10000
max_salary = max_salary[:-1]
else:
return None, None, None
if min_salary.endswith('千'):
min_scale = 1000
min_salary = min_salary[:-1]
elif min_salary.endswith('万'):
min_scale = 10000
min_salary = min_salary[:-1]
else:
min_scale = max_scale
# 计算平均薪资
max_salary = max_scale * float(max_salary)
min_salary = min_scale * float(min_salary)
salary = min_salary + max_salary / 2
return salary, min_salary, max_salary
# 薪资预测模型
sql = 'select hangye,xueli,city,jingyan,salary from job'
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
cursor.execute(sql)
jobs = cursor.fetchall()
train_datas = []
for job in jobs:
hangye, xueli, city, jingyan, salary = job
if city + '市' not in city_fenqu_maps:
continue
fengqu = city_fenqu_maps[city + '市']
salary, min_salary, max_salary = calc_salary(salary)
if salary:
train_datas.append([hangye, xueli, fengqu, jingyan, salary])
train_datas = pd.DataFrame(train_datas, columns=['hangye', 'xueli', 'fengqu', 'jingyan', 'salary'])
# 行业
hangye_mean = train_datas.groupby('hangye')['salary'].mean().reset_index().sort_values(by='salary', ascending=False)
all_hangye = hangye_mean['hangye'].values.tolist()
# 学历
xueli_mean = train_datas.groupby('xueli')['salary'].mean().reset_index().sort_values(by='salary', ascending=False)
all_xueli = xueli_mean['xueli'].values.tolist()
# 地区
fengqu_mean = train_datas.groupby('fengqu')['salary'].mean().reset_index().sort_values(by='salary', ascending=False)
all_fengqu = fengqu_mean['fengqu'].values.tolist()
# 工作经验
jingyan_mean = train_datas.groupby('jingyan')['salary'].mean().reset_index().sort_values(by='salary', ascending=False)
all_jingyan = jingyan_mean['jingyan'].values.tolist()
hangye_map = {hy: i for i, hy in enumerate(all_hangye)}
xueli_map = {hy: i for i, hy in enumerate(all_xueli)}
fengqu_map = {hy: i for i, hy in enumerate(all_fengqu)}
jingyan_map = {hy: i for i, hy in enumerate(all_jingyan)}
print(xueli_map)
print(hangye_map)
print(fengqu_map)
print(jingyan_map)
# 1、构造决策树机器学习模型
train_datas['hangye'] = train_datas['hangye'].map(hangye_map)
train_datas['xueli'] = train_datas['xueli'].map(xueli_map)
train_datas['fengqu'] = train_datas['fengqu'].map(fengqu_map)
train_datas['jingyan'] = train_datas['jingyan'].map(jingyan_map)
# 导入机器学习库
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
y = train_datas['salary'].values
del train_datas['salary']
def train_regr():
# 创建回归模型
regr = DecisionTreeRegressor(max_depth=19)
# 目标变量
X = train_datas.values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print('开始训练决策树回归模型。。。。。')
regr.fit(X, y)
pred = regr.predict(X)
mae = mean_absolute_error(y, pred)
r2 = r2_score(y, pred)
print(f'平均绝对误差MAE: {mae:.3f} 元')
print(f'拟合优度R^2: {r2:.3f}')
return regr
# 2、XGBOOST回归模型
def train_xgb():
# 构建目标变量
X = train_datas.values
# 划分训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
print("开始训练XGBOOST回归模型。。。。。")
xgb_models = xgb.XGBRegressor(
objective="reg:squarederror",
colsample_bytree=0.5,
subsample=0.8,
learning_rate=0.01,
max_depth=10,
alpha=10,
n_estimators=500,
min_child_weight=3,
gamma=2,
random_state=42
)
xgb_models.fit(X_train, y_train)
pred = xgb_models.predict(X_test)
mae = mean_absolute_error(y_test, pred)
r2 = r2_score(y_test, pred)
print(f'平均绝对误差MAE: {mae:.3f} 元')
print(f'拟合优度R^2: {r2:.3f}')
return xgb_models
regr = train_regr()
xgb_models = train_xgb()
@app.route('/get_selectors')
def get_selectors():
return jsonify({
'hangye': all_hangye,
'xueli': all_xueli,
'fengqu': all_fengqu,
'jingyan': all_jingyan,
})
@app.route('/tree_model_predict_salary')
def tree_model_predict_salary():
"""根据学历,工作经验,求职岗位等预测出对应的薪资情况"""
fengqu = request.args.get('fengqu')
hangye = request.args.get('hangye')
xueli = request.args.get('xueli')
jingyan = request.args.get('jingyan')
conn = sqlite3.connect(DATABASE)
cursor = conn.cursor()
check_sql = "SELECT * FROM job where hangye='{}' and xueli='{}'".format(hangye, xueli)
cursor.execute(check_sql)
jobs = cursor.fetchall()
hotjobs = []
job_set = set()
for job in jobs:
id,job_name, hangye, company, province, city, salary, jingyan, xueli, zhaopin_counts, pub_time = job
# job_name, hangye, company, province, city, salary, jingyan, xueli, zhaopin_counts, pub_time = job
# 地区筛选
if '市' not in city:
city = city + '市'
if city not in city_fenqu_maps:
continue
if city_fenqu_maps[city] != fengqu:
continue
try:
tmp = float(jingyan)
jingyan = '{}年工作经验'.format(jingyan)
except:
pass
# 薪资筛选
salary, min_salary, max_salary = calc_salary(salary)
if not salary:
continue
if f'{job_name}-{company}-{salary}-{pub_time}' not in job_set:
hotjobs.append((job_name, hangye, company, province, salary, jingyan, xueli, zhaopin_counts, pub_time))
job_set.add(f'{job_name}-{company}-{salary}-{pub_time}')
# 选取 top 20 的
top_salarys = hotjobs[:20]
hangye, xueli, fengqu, jingyan = hangye_map[hangye], xueli_map[xueli], fengqu_map[fengqu], jingyan_map[jingyan]
# 模型预测
pred_salary = regr.predict(np.array([hangye, xueli, fengqu, jingyan]).reshape(1, -1))
pred_salary = pred_salary[0]
xgb_pred_salary = xgb_models.predict(np.array([hangye, xueli, fengqu, jingyan]).reshape(1, -1))
xgb_pred_salary = xgb_pred_salary[0]
return jsonify({'pred_salary': pred_salary, 'recommend_jobs': top_salarys, "xgb_pred_salary":str(xgb_pred_salary)})
if __name__ == "__main__":
app.run(host='127.0.0.1')
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 21
21 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)