
pytorch搭建神经网络:从入门到精通,细节 make your network more perfect
1. 前言入坑深度学习已快一年,写过不少代码,也复现过不少论文,因为代码这块一直都是自己摸索着前行,走了不少弯路,甚至现在,也偶尔会发现一些自己一直忽略的细节。我们写一份代码,复现一篇论文,都希望它是完全正确的。但是从博客或文章中参考到的网络结构都是比较粗糙的,即使你能从某些地方获取到源码,也很难对某些细节做出说明。特别地,深度学习发展到成熟的今天,你的一行代码,一个符号都可能导致另一个不一致或更
原文连接:pytorch搭建神经网络
1. 前言
入坑深度学习已快一年,写过不少代码,也复现过不少论文,因为代码这块一直都是自己摸索着前行,走了不少弯路,甚至现在,也偶尔会发现一些自己一直忽略的细节。我们写一份代码,复现一篇论文,都希望它是完全正确的。但是从博客或文章中参考到的网络结构都是比较粗糙的,即使你能从某些地方获取到源码,也很难对某些细节做出说明。特别地,深度学习发展到成熟的今天,你的一行代码,一个符号都可能导致另一个不一致或更差的结果。
因此,本文以神经网络实现的一些细节为出发点,以常用分类数据集cifar10的分类为任务,手把手带你编写一份更完美的深度学习代码。
2. 任务分析
CIFAR10是kaggle计算机视觉竞赛的一个图像分类项目。该数据集共有60000张32*32彩色图像,一共分为"plane", "car", "bird","cat", "deer", "dog", "frog","horse","ship", "truck" 10类,每类6000张图。有50000张用于训练,构成了5个训练批,每一批10000张图;10000张用于测试,单独构成一批。可点击直接下载。

3. 数据集下载与预处理
一些经典的数据集,如Imagenet, CIFAR10, MNIST都可以通过torchvision来获取,并且torchvision还提供了transforms类可以用来正规化处理数据。
(1)数据集
数据集可分为训练集、验证集和训练集,训练集用于训练,验证集用于验证训练期间的模型,测试集用于测试最终模型的表现。这是基本的理解。验证集可用来设计一些交叉验证方法,在数据量较少的情况下能够提高模型的鲁棒性,通常任务分为训练集和测试集即可。
(2)数据预处理。
常用数据预处理方法可概述为2类,数据标准化处理和数据增广。
最常用的数据标准化处理就是数据的归一化,原数据可能数据量很大,维数很,计算机处理起来时间复杂度很高,预处理可以降低数据维度。同时,把数据都规范到0到1,这样使得它们对模型的影响具有同样的尺度。
数据扩增是对数据进行扩充的方法的总称。数据扩增可以增加训练集的样本,可以有效缓解模型过拟合的情况,也可以给模型带来的更强的泛化能力。即数据扩增的目的就是使得训练数据尽可能的接近测试数据,从而提高预测精度。另外数据扩增可以迫使网络学习到更鲁棒性的特征,从而使模型拥有更强的泛化能力。更多可参考数据增广的详细理解。代码如下:
#引入必须的包
import torch
import torchvision
import torchvision.transforms as transforms
data_path='./dataset'#数据保存路径
#数据的预处理操作
training_transform=transforms.Compose([
transforms.RandomCrop(32, padding=4),#数据增广
transforms.RandomHorizontalFlip(),#数据增广
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616]),#数据归一化
])
validation_transforms=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],std=[0.2471, 0.2435, 0.2616]),
])
#训练集
train_dataset = torchvision.datasets.CIFAR10(root=data_path,#数据下载和加载
train=True,
transform=training_transform,
download=True)#若已下载改为False
#测试集
val_dataset = torchvision.datasets.CIFAR10(root=data_path,
train=False,
transform=validation_transforms,
download=True)
x,y= train_dataset[0]
print(x.size(),y) 运行后输出输入图像的尺寸及其标签序号;

一些torch自带的数据集,如Imagenet, CIFAR10, MNIST都可以通过类似方式获取,此外,其他图像数据集还可以通过ImageFolder包引入,如下:
train_dataset = torchvision.datasets.ImageFolder(traindir,
transforms.Compose([
transforms.RandomResizedCrop(64),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize ]))只需将下载好的数据集放到traindir文件夹下,注意:ImageFolder默认traindir文件夹下的每个子文件夹代表一个类,所以,若使用该方式,你还需将每个类的图像移动到一个单独的子文夹杂下。
4. 超参数设置
在机器学习的上下文中,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。比如学习率、神经网络的深度、隐藏层层数、优化策略、训练次数、训练批次大小等。目前超参数往往只能人工基于经验来设置,以及采用暴力枚举的方式来尝试以寻求最优的超参数。但经验也是有规律可言的。
(1)优化器选择
优化器的目的是为了让损失函数尽可能的小,从而找到合适的参数来完成某项任务。最常用的优化器有SGD、RMSProp、Adam、AdaDelt等,推荐使用带momentum的SGD优化器,这会带来更高的收敛精度,带momentum的SGD优化器有两个劣势,其一是收敛速度慢,其二是初始学习率的设置需要依靠大量的经验,然而如果初始学习率设置得当并且迭代轮数充足,该优化器也会在众多的优化器中脱颖而出,使得其在验证集上获得更高的准确率。一些自适应学习率的优化器如Adam、RMSProp等,收敛速度往往比较快,但是最终的收敛精度会稍差一些。
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)(2)学习率
学习率是通过损失函数的梯度调整网络权重的超参数的速度。学习率越低,损失函数的变化速度就越慢。虽然使用低学习率可以确保不会错过任何局部极小值,但也意味着将花费更长的时间来进行收敛,还容易引起局部拟合。
当使用平方和误差作为成本函数时,随着数据量的增多,学习率应该被设置为相应更小的值。adam一般初始化为0.001,sgd 0.1,随着batchsize增大,学习率一般也要增大根号n倍。
(3)学习率下降策略
在整个训练过程中,我们不能使用同样的学习率来更新权重,否则无法到达最优点,所以需要在训练过程中调整学习率的大小。在训练初始阶段,由于权重处于随机初始化的状态,损失函数相对容易进行梯度下降,所以可以设置一个较大的学习率。在训练后期,由于权重参数已经接近最优值,较大的学习率无法进一步寻找最优值,所以需要设置一个较小的学习率。
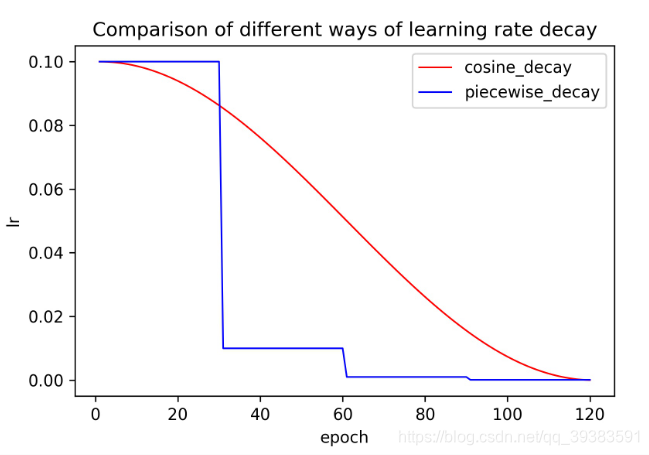
比较几种下降策略:piecewise_decay(阶梯式下降学习率)、polynomial_decay(多项式下降)、exponential_decay(指数下降),cosine_decay(余弦下降)。
最常用的是阶梯式下降策略,如我们在cifar10训练resnet18网络使用的是分别在[60,120,160]epoch时调整学习率,通过手动设置调整学习率的阶段可以根据经验得出一个更好的效果,更重要的是方便模型的对比。使用相同的阶梯式下降策略是最能评估两个模型好坏的学习策略;
余弦下降策略无需调整超参数,鲁棒性也比较高,所以成为现在提高模型精度首选的学习率下降方式。两种策略对比如下:
(4)权重衰减:weight_decay
过拟合是机器学习中常见的一个名词,简单理解即为模型在训练数据上表现很好,但在测试数据上表现较差,在卷积神经网络中,同样存在过拟合的问题,为了避免过拟合,很多正则方式被提出,其中,weight_decay是其中一个广泛使用的避免过拟合的方式。Weight_decay等价于在最终的损失函数后添加L2正则化,L2正则化使得网络的权重倾向于选择更小的值,最终整个网络中的参数值更趋向于0,模型的泛化性能相应提高。在训练ImageNet的任务中,大多数的网络将该参数值设置为1e-4,在一些小的网络如MobileNet系列网络中,为了避免网络欠拟合,该值设置为1e-5~4e-5之间。简单来说,数据集越大越复杂,模型越简单,相应调小;数据集小、模型越复杂,相应调大。
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[80,120], gamma=0.1)(5)warmup策略
如果使用较大的batch_size训练神经网络时,我们建议您使用warmup策略。Warmup策略顾名思义就是让学习率先预热一下,在训练初期我们不直接使用最大的学习率,而是用一个逐渐增大的学习率去训练网络,当学习率增大到最高点时,再使用学习率下降策略中提到的学习率下降方式衰减学习率的值。实验表明,在batch_size较大时,warmup可以稳定提升模型的精度。
from torch.optim.lr_scheduler import _LRScheduler
class WarmUpLR(_LRScheduler):
"""warmup_training learning rate scheduler
Args:
optimizer: optimzier(e.g. SGD)
total_iters: totoal_iters of warmup phase
"""
def __init__(self, optimizer, total_iters, last_epoch=-1):
self.total_iters = total_iters
super().__init__(optimizer, last_epoch)
def get_lr(self):
"""we will use the first m batches, and set the learning
rate to base_lr * m / total_iters
"""
return [base_lr * self.last_epoch / (self.total_iters + 1e-8) for base_lr in self.base_lrs]我们在此将warmup中的epoch设置为1,即先在1epoch内将学习率从0增加到初始值,再去做相应的学习率衰减。
5. 网络结构
网络结构这里就不编了,我直接拿resnet模型来修改讲解。
值得注意的是,为了适应cifar10数据集,我们将resnet模型的第一层卷积改小了卷积核(7*7到3*3),并且取消了下采样,如下:
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=places, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)这是因为cifar10数据集图像分辨率只有32*32,若按源resnet代码,会在第一层卷积进行2次下采样,变成8*8,造成大量的像素特征丢失,对结果的影响是巨大的。
(1)卷积操作
卷积操作是神经网络的最重要组成成分,有1d、2d、3d、空洞卷积等。主要参数包括in_channels:输入通道, out_channels:输出通道, kernel_size:卷积核尺寸, stride:步长, padding:填充, bias:偏置,其中:
输入通道:一般根据上层输入设置,如输入RGB图像的第一层卷积in_channels=3;
输出通道:也可称为输出神经元个数、卷积核个数、输出特征数量等,用来表示要学习的输出特征的数量,根据网络而定,越大能够学习到更多的特征,但也会导致更多的参数和存储占用,更容易过拟合;
卷积核尺寸:一般设置为1*1,3*3,5*5,7*7等单数,因为填充padding=(kernel_size-1)/2。越大的尺寸表示更大的感受野,能够学习到更多的特征,但不能盲目增大,这带来的提升往往不如代价。因此一般使用3*3卷积,1*1通常用于升降维度,以及给网络增加非线性。常用的组合为[3*3,3*3],[1*1,3*3,1*1]。
步长:默认为1,需要下采样时设为2,特征图尺寸相应会减半;
偏置:一般后面接BN层设置为False,因为bias不能与bn共存;其他可设为True。
(2)正则化
BatchNorm是神经网络所必须的,也是神经网络做得越深越宽的基石,通常只需设置输出通道即可,momentum默认为0.1,即每次都从上一次的BN层继承90%的参数。
(3)激活函数
常用的特征层激活函数relu,输出层激活函数softmax、sigmoid,激活函数是一种非线性函数,它是衡量网络深度的标准,多层感知器(卷积层)的叠加若没有激活函数(非线性函数),那么它在神经网络的作用就相当于只有一层。类似与特征多项式一样,相同维度的多个多项式的叠加跟一个的作用是相同的。
这是我认为一些难以注意到的细节,其他网络上应有不少,更多可自行查阅。
模型的完整代码如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
def Conv1(in_planes, places, stride=2):
return nn.Sequential(
nn.Conv2d(in_channels=in_planes, out_channels=places, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
# 经过处理后的x要与x的维度相同(尺寸和深度)
# 如果不相同,需要添加卷积+BN来变换为同一维度
if stride != 1 or in_planes != self.expansion * planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion * planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion * planes)
)
def forward(self, x):
# print(x.size())
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = Conv1(in_planes=3, places=64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifer = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size()[0], -1) # 4, 2048
x = self.classifer(x)
return x
def ResNet18(**kwargs):
return ResNet(BasicBlock, [2, 2, 2, 2],**kwargs)
net = ResNet18(num_classes=10)
y = net(torch.randn(1, 3, 32, 32))
print(y.size())
6. 训练和测试
(1)根据上述设置超参
#超参数
warm=1
epoch=160
batch_size=128
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.1, momentum=0.9, weight_decay=1e-4)
train_scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[80,120], gamma=0.1) #learning rate decay
from torch.utils.data import DataLoader
trainloader = DataLoader(train_dataset, batch_size, shuffle=True, num_workers=5, pin_memory=True)
valloader = DataLoader(val_dataset, batch_size, shuffle=False, num_workers=5, pin_memory=True)
iter_per_epoch = len(trainloader)
warmup_scheduler = WarmUpLR(optimizer, iter_per_epoch * warm)
(2)准确率计算函数
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k""" # [128, 10],128
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True) # [128, 5],indices
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred)) # 5,128
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0, keepdim=True)
wrong_k = batch_size - correct_k
res.append(wrong_k.mul_(100.0 / batch_size))
return res(3)训练
def train(trainloader, model, criterion, optimizer, epoch):
losses = AverageMeter()
top1 = AverageMeter()
model.train()
for i, (input, target) in enumerate(trainloader):
# measure data loading time
input, target = input.cuda(), target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec = accuracy(output, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec.item(), input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
return top1.avg(4)测试
def validate(val_loader, model, criterion):
losses = AverageMeter()
top1 = AverageMeter()
model.eval()
with torch.no_grad():
for i, (input, target) in enumerate(val_loader):
input, target = input.cuda(), target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
# measure accuracy and record loss
prec = accuracy(output, target)[0]
losses.update(loss.item(), input.size(0))
top1.update(prec.item(), input.size(0))
print(' * Prec {top1.avg:.3f}% '.format(top1=top1))
return top1.avg(5)最后
best_prec = 0
for e in range(epoch):
train_scheduler.step( e)
# train for one epoch
train(trainloader, net, loss_function, optimizer, e)
# evaluate on test set
prec = validate(valloader, net, loss_function)
# remember best precision and save checkpoint
is_best = prec > best_prec
best_prec = max(prec,best_prec)
print(best_prec)
汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)