
使用keras和sklearn做类别标签到独热码(one-hot code)转换的区别
1、导入需要的库from keras.utils.np_utils import to_categoricalfrom sklearn import preprocessing2、当使用keras默认参数时(num_classes=None)x = [1, 2, 3]y= to_categorical(x)发现把x分为了4个类别,0、1、2、33、当使用keras自定义参数时(num_classe
1、导入需要的库
from keras.utils.np_utils import to_categorical
from sklearn import preprocessing
2、当使用keras默认参数时(num_classes=None)
x = [1, 2, 3]
y= to_categorical(x)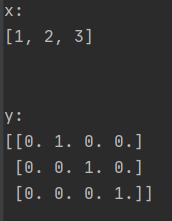
发现把x分为了4个类别,0、1、2、3
3、当使用keras自定义参数时(num_classes=num)
x = [1, 2, 3]
y= to_categorical(x, num_classes=5)
发现把x分为了5个类别,0、1、2、3、4
4、当使用skearn时
lb = preprocessing.LabelBinarizer()
x = [1, 2, 3]
y = lb.fit_transform(x)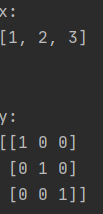
发现把x分为了3个类别,0、1、2
换一个x:
lb = preprocessing.LabelBinarizer()
x = [1, 2, 3]
y = lb.fit_transform(x)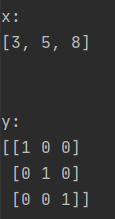
发现还是把x分为了3个类别,0、1、2
5、总结
1、无参数定义时,keras会把原始类别数字中最大的+1当做独热码处理后类别数
2、有参数定义时,keras会把num_classes当做独热码处理后类别数
3、sklearn则完全不同,它是把原始类别数字不同的个数当做独热码处理后类别数
4、对于连续数据类别可以使用keras(类别数字必须从0开始,条件有些苛刻),也可使用sklearn(无要求)
5、对于离散数据类别建议使用sklearn
6、本人在日常使用中发现sklearn更好用,如果误用keras可能会出错

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)