
关于Zipf定律的理解和python实现
关于Zipf定律的理解和python实现Zipf定律含义二级目录三级目录Zipf定律含义二级目录三级目录
·
关于Zipf定律的理解和python实现
1、Zipf定律含义
我们可以轻松的百度到:
齐普夫定律是美国学者G.K.齐普夫于20世纪40年代提出的词频分布定律。它可以表述为:如果把一篇较长文章中每个词出现的频次统计起来,按照高频词在前、低频词在后的递减顺序排列,并用自然数给这些词编上等级序号,即频次最高的词等级为1,频次次之的等级为2,……,频次最小的词等级为D。若用f表示频次,r表示等级序号,则有fr=C(C为常数)。人们称该式为齐普夫定律。
齐普夫定律( Zipf’s law) 的表述为: 当文章作者给出的文献语料库中的词汇足够多时, 单词出现频率呈现出一定的分布规律.
研究发现: 不同的作者的用词取向和用词频度是不同的, 这种规律被称为“语言指纹”.
所谓用词频度( 词频) 是指每一个词在一定长度文件中出現的频率占总词数的比, 如对一个由 K 个词组成的总长度为 L 的语料库中, 词的出现频率由高到低排序为 r 的词频为 Pr. 而依词频从高到低将词排序的序号则是计量的另一个最基本的数量指标.
**下面代码来源于课题作业 **
1.1 Zipf第一定律
Zipf 第一定律——二八原则。在自然语言文本(集)中,按着词的出现频率(f)降序排序,那么频率和序(r)之间有近似幂律关系。
对数坐标:对变元取对数,“压缩”了变化范围。将一个数量级压缩在一个单位之内。因此,数量越大,压缩得越严重。
- python实现
import re
import collections
import matplotlib.pyplot as plt
def show_Zipf(word_dict):
'''
将词频结果按着由高到低的顺序排列,然后绘制Zipf定律
'''
print('词频排列如下')
freq=[v for v in sorted(word_dict.values(),reverse=True)]
plt.rcParams['figure.figsize'] = (10.0, 8.0)
plt.loglog(freq)#双对数坐标
plt.title('frequency-rank')
plt.xlabel('rank')
plt.ylabel('word frequency')
plt.show()
def count_pos(word_pos_list):
'''
统计词性的出现频次
word_pos_list:列表,以词/词性组成的元组为元素
---
返回词性频率字典:pos_dict
'''
word_dict={}
for i in word_pos_list:
if not word_dict.get(i[0]):
word_dict[i[0]]=1
else:
word_dict[i[0]]+=1
print('已分别建立词频词典,词性词频词典')
return word_dict
def fenci_jieba(text):
'''
text,是上面程序生成的列表,元素是句子
使用结巴分词,词性标注
'''
#列表,以词/词性组成的元组为元素
word_pos_list=[]
import jieba.posseg as pseg
for line in text:
if line:
line=pseg.lcut(line)
for word, flag in line:
word_pos_list.append((word, flag))
return word_pos_list
def file2sentences(Inp):
'''
文本分句,
返回分句后文本
'''
# 存放分句后的文本
text =[]
import re
f = open(Inp,encoding='gb2312',errors='ignore')
nums = 0
for line in f:
line = line.strip()
……分句过程省略,使用文中存在的标点符号,使用split()方法即可
for i in line:
if i:
text.append(i)
f.close()
print('文本已切分成句')
return text
def main1(Inp):
text = file2sentences(Inp)
word_pos_list,pos = fenci_jieba(text)
word_dict = count_pos(word_pos_list)
show_Zipf(word_dict)
Inp=r'……1648.txt'
main1(Inp)
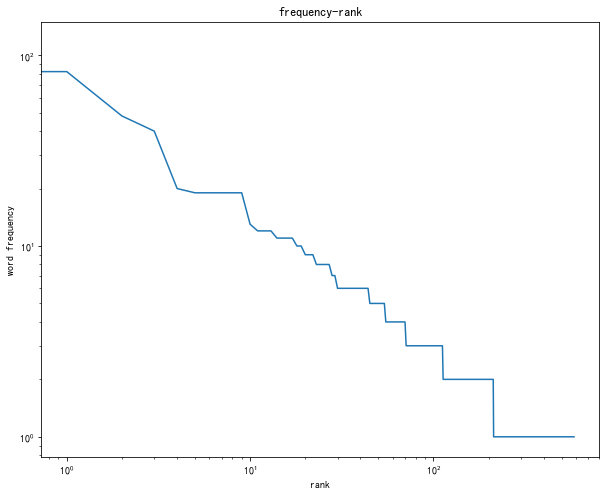
1.2 Zipf第二定律
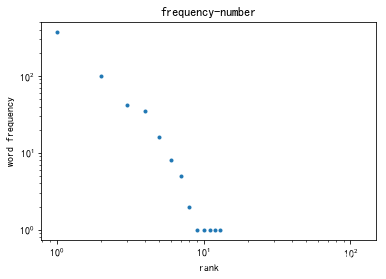
频率数量定律—横轴是词频,纵轴是词数。词频谱
def show_Zipf2(word_dict):
'''
将词频结果按着由高到低的顺序排列,然后绘制Zipf定律
'''
print('词频—数量关系曲线(Zipf第二定律)','\n')
print('词频排列如下')
word_freq=[v for v in sorted(word_dict.values(),reverse=True)]
freq_num=sorted([sum([1 for w in word_freq if word_freq[w]==n])for n in range(1,word_freq[0]+1)],reverse=True)
print(freq_num)
plt.loglog(range(1,word_freq[0]+1), freq_num,'.')
plt.title('frequency-number')
plt.xlabel('rank')
plt.ylabel('word frequency')
plt.show()

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)