
随机森林模型代码_机器学习随机森林模型与泰坦尼克号生存预测
集成学习集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯...

-
集成学习
-
随机森林模型如何工作:
-
森林中每棵树按照如下方式生长:
-
随机森林的预测错误率取决于以下两点:
-
案例分析:泰坦尼克号生存预测
泰坦尼克号沉船事故是世界上最著名的沉船事故之一。1912年4月15日,在她的处女航期间,泰坦尼克号撞上冰山后沉没,造成2224名乘客和机组人员中超过1502人的死亡。这一轰动的悲剧震惊了国际社会,并导致更好的船舶安全法规。
事故中导致死亡的一个原因是许多船员和乘客没有足够的救生艇。然而在被获救群体中也有一些比较幸运的因素;一些人群在事故中被救的几率高于其他人,比如妇女、儿童和上层阶级。
这个Case里,我们需要分析和判断出什么样的人更容易获救。最重要的是,要利用机器学习来预测出在这场灾难中哪些人会最终获救。
-
研究思路:导入数据——特征工程——数据缺失值处理——建构模型
1、导入数据
将数据分为训练集与测试集并导入
train = pd.read_csv(r"D:\kaggle\titanic\train.csv")test = pd.read_csv(r"D:\kaggle\titanic\test.csv")PassengerId = test["PassengerId"]all_data = pd.concat([train,test],ignore_index = True)查看数据基本信息
train.head()train.info()
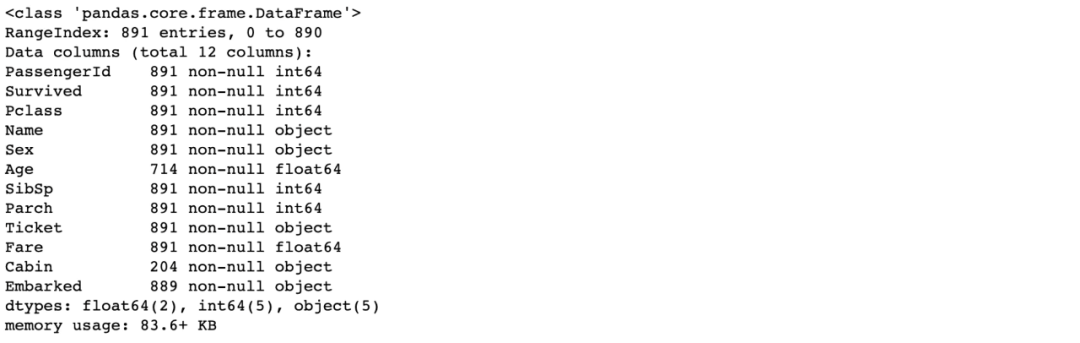
2、特征工程
sex features 女性比男性生存率高。
sns.barplot(x="Sex",y="Survived",data=train)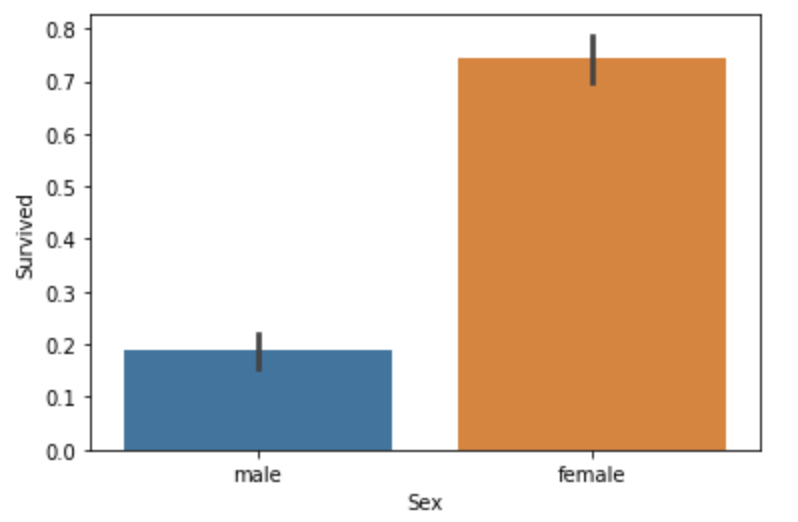
Pclass features 舱位等级越高,生存率越高。
sns.barplot(x="Pclass",y="Survived",data=train)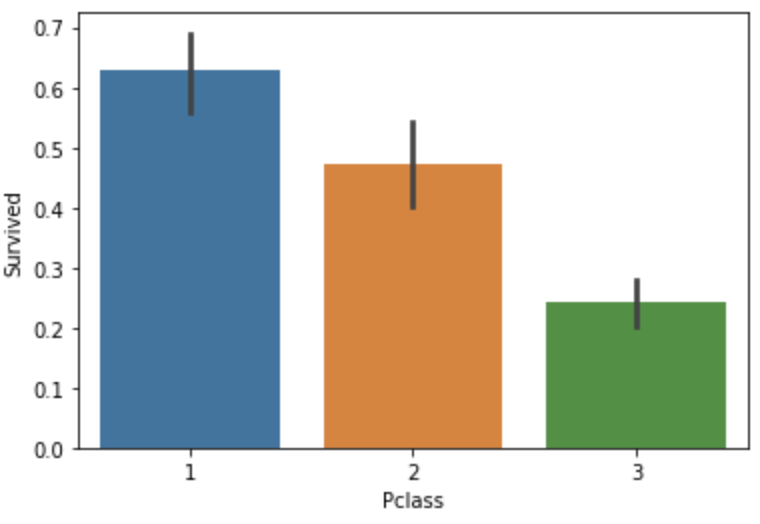
Sibsp features 兄弟姐妹数量在1与2之间的乘客生存率较高。
sns.barplot(x="SibSp",y="Survived",data=train)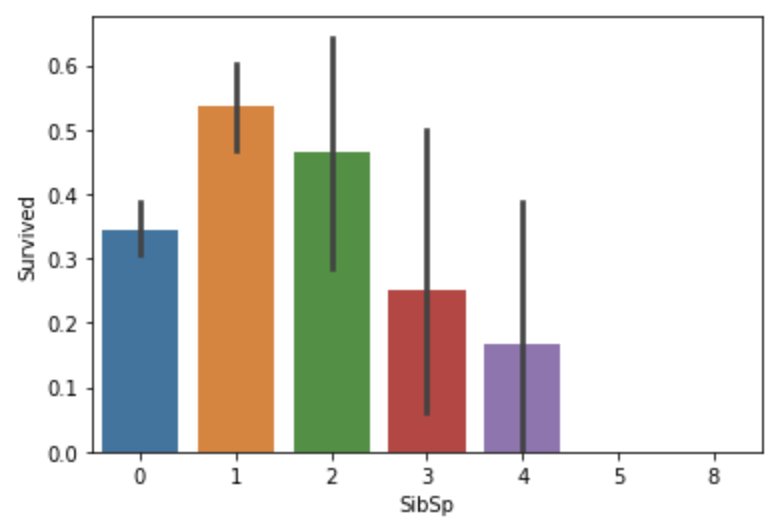
Parch features 父母与孩子数量在与乘客生存率无太大关系。
sns.barplot(x="Parch",y="Survived",data=train)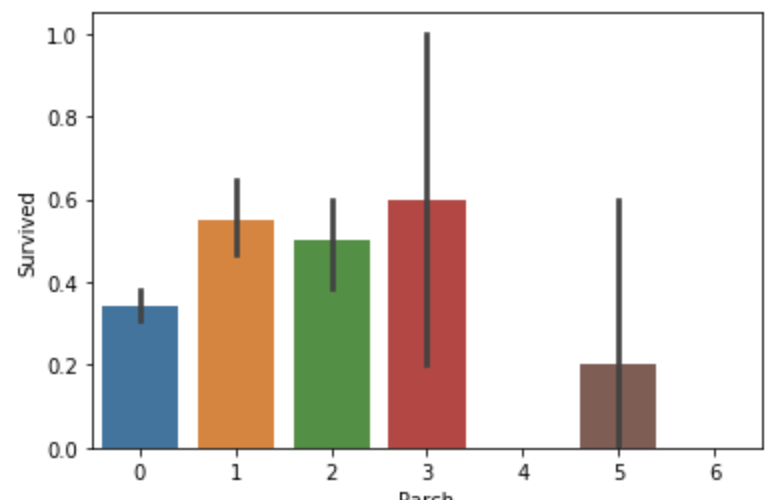
新建Title维度,基于name维度按照name中的前缀归纳出Title维度。
all_data["Title"] = all_data["Name"].apply(lambda x:x.split(",")[1].split(".")[0].strip())Title_Dict = {}Title_Dict.update(dict.fromkeys(['Capt', 'Col', 'Major', 'Dr', 'Rev'],"Officer"))Title_Dict.update(dict.fromkeys(['Don', 'Sir', 'the Countess', 'Dona', 'Lady'], 'Royalty'))Title_Dict.update(dict.fromkeys(['Mme', 'Ms', 'Mrs'], 'Mrs'))Title_Dict.update(dict.fromkeys(['Mlle', 'Miss'], 'Miss'))Title_Dict.update(dict.fromkeys(['Mr'], 'Mr'))Title_Dict.update(dict.fromkeys(['Master','Jonkheer'], 'Master'))all_data["Title"] = all_data["Title"].map(Title_Dict)sns.barplot(x="Title", y="Survived", data=all_data)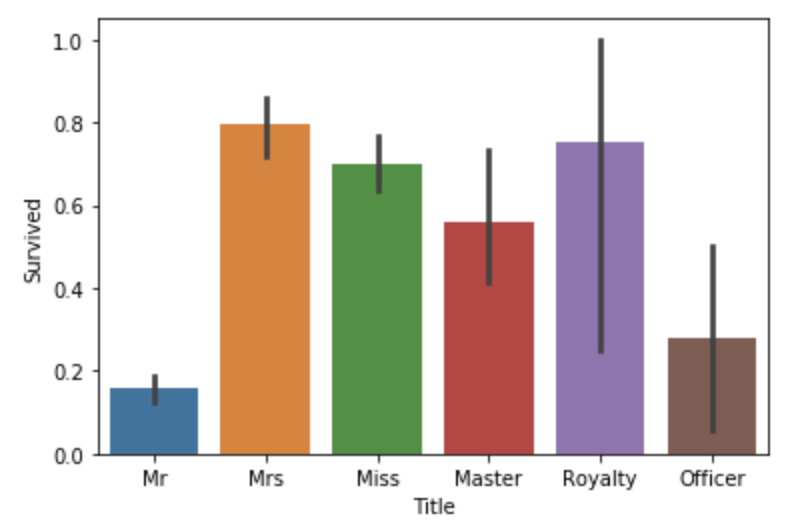
年龄与密度(在14岁左侧的生还率有明显差别,两图非交叉的面积很大;右侧则差别较小;因此考虑将14岁以下的区域分离)。
facet = sns.FacetGrid(train,hue="Survived",aspect=2) 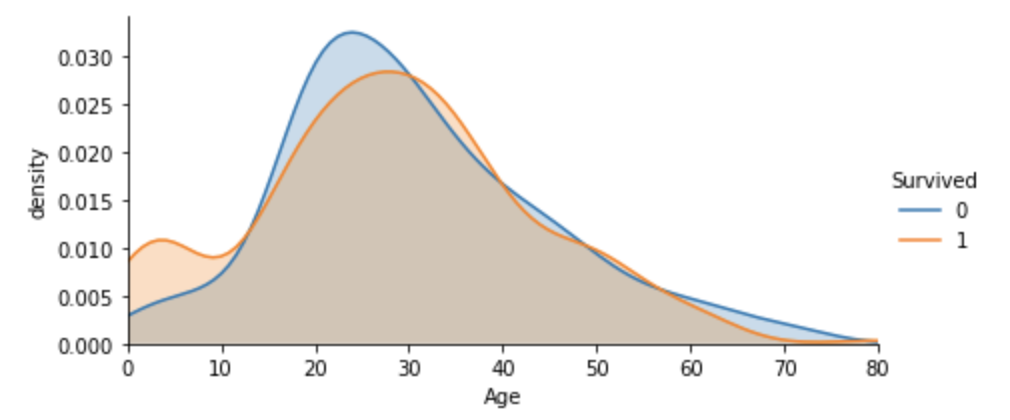
Embarked登船港口与生存情况 明显C地登船的生还率更高
sns.countplot('Embarked',hue='Survived',data=train)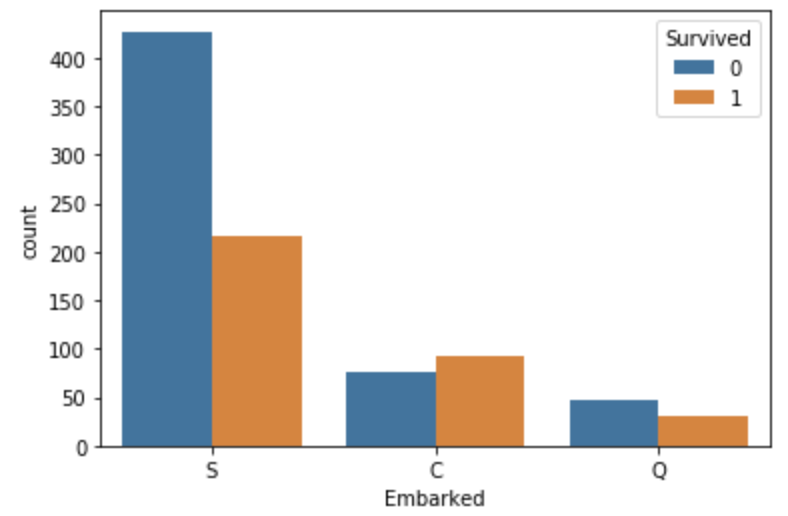
FamilyLabel Feature(New):家庭人数为2到4的乘客幸存率较高
all_data['FamilySize']=all_data['SibSp']+all_data['Parch']+1sns.barplot(x="FamilySize", y="Survived", data=all_data)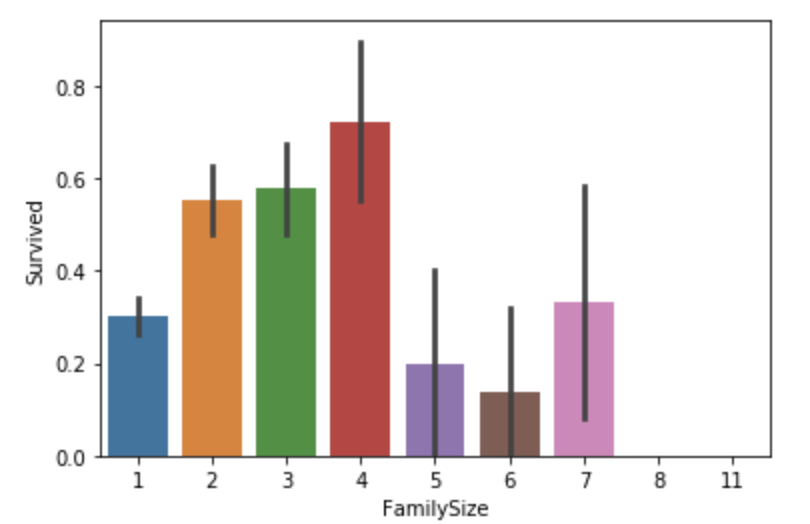
按生存率把FamilySize分为三类,构成FamilyLabel特征。
def SizeToLabel(s): if (s>=2)&(s<=4): return 2 elif((s>=5)&(s<=7))|(s == 1): return 1 elif(s>7): return 0all_data["FamilyLabel"] = all_data["FamilySize"].apply(SizeToLabel)sns.barplot(x="FamilyLabel", y="Survived", data=all_data)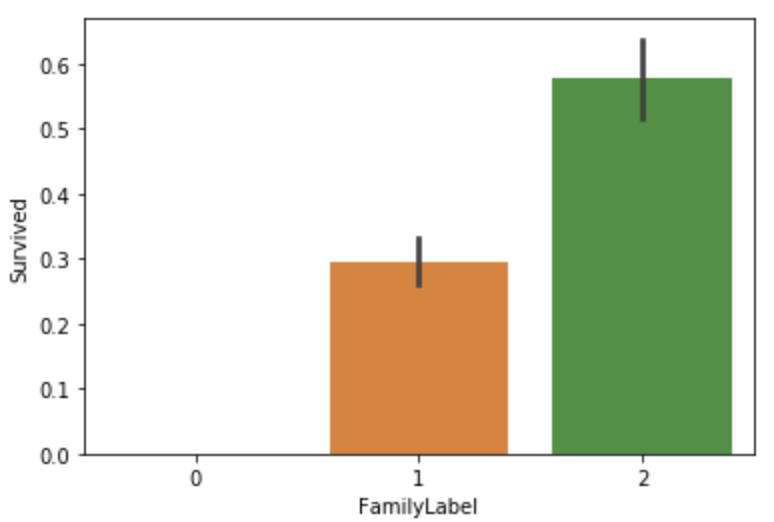
对于Deck Feature,把未知的填为unknow,已知的提取首字母。
all_data["Cabin"] = all_data["Cabin"].fillna("Unknown")all_data["Deck"] = all_data["Cabin"].str.get(0)sns.barplot(x="Deck",y="Survived",data=all_data)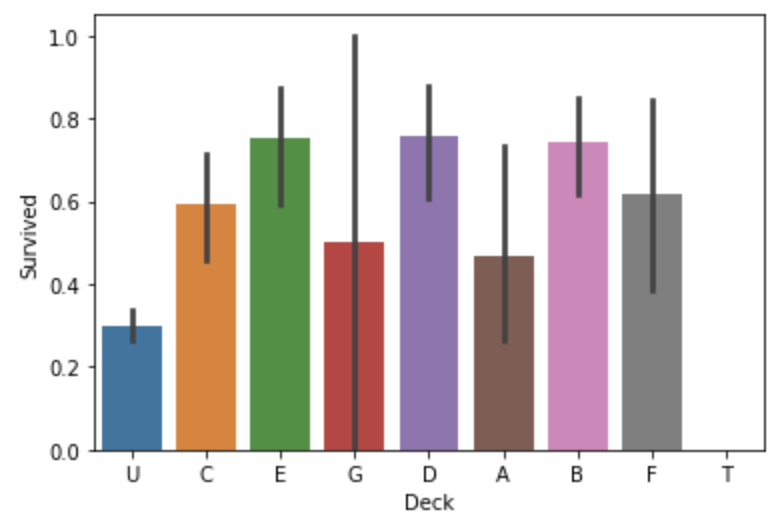
TicketGroup Feature(New):与2至4人共票号的乘客幸存率较高
Tick_Counts = dict(all_data['Ticket'].value_counts()) all_data["TicketGroup"] = all_data["Ticket"].apply(lambda x:Tick_Counts[x]) sns.barplot(x='TicketGroup', y='Survived', data=all_data)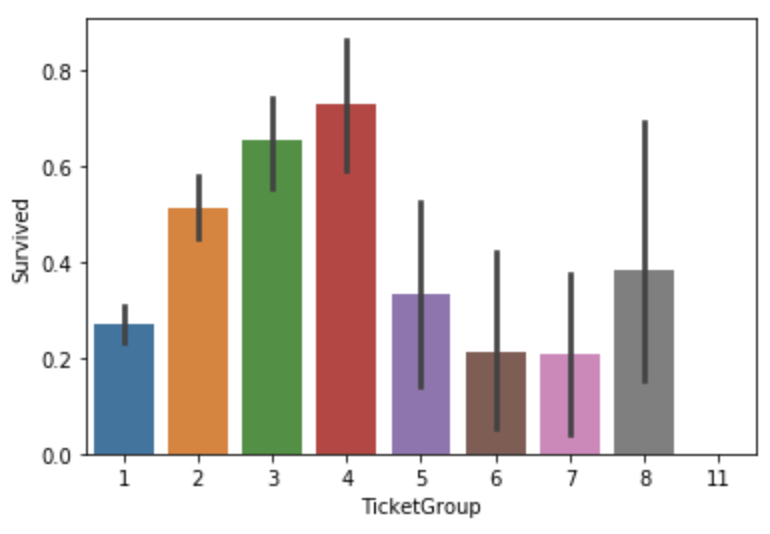
按生存率把TicketGroup分为三类 TicketLabel。
def GroupToLabel(s): if(s>=2)&(s<=4): return 2 elif((s>=5)&(s<=8))|(s==1): return 1 elif(s>8): return 0all_data["TicketLabel"] = all_data["TicketGroup"].apply(GroupToLabel)sns.barplot(x="TicketLabel",y="Survived",data=all_data)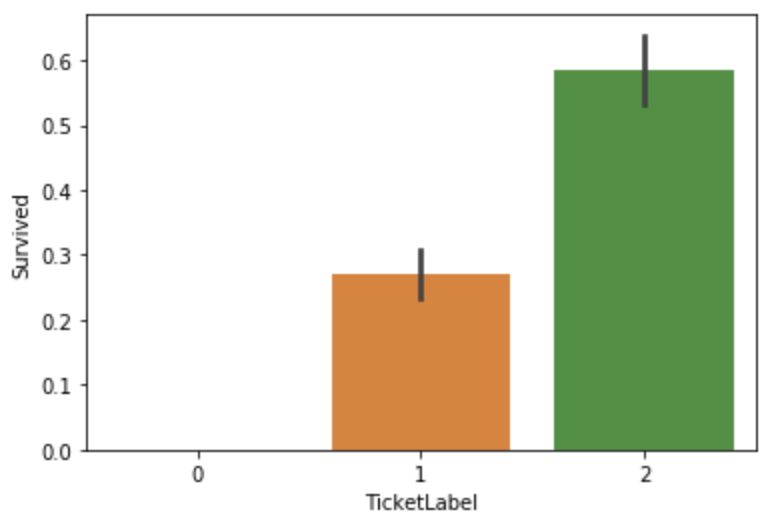
将SEX、TITLE、EMBARKED这三个维度进行哑变量处理。
def sex(s): if s=="male": return 1 else: return 0all_data["Sex"] = all_data["Sex"].apply(sex)def title(s): if s=="Officer": return 0 elif s=="Mr": return 1 elif s=="Mrs": return 2 elif s=="Miss": return 3 elif s=="Master": return 4 elif s=="Royalty": return 5all_data["Title"] = all_data["Title"].apply(title)def embarked(s): if s=="S": return 0 elif s=="C": return 1 elif s=="Q": return 2all_data["Embarked"] = all_data["Embarked"].apply(embarked)3、缺失值处理
由之前的数据查看阶段可知,Age缺失量为263,缺失量较大,因此构建随机森林模型,填充年龄缺失值。
Y_missing = all_data.loc[:,"Age"]nameList = ["Sex","Pclass","SibSp","Parch","Title"]X_missing = all_data.loc[:,nameList]Ytrain = Y_missing[Y_missing.notnull()]Ytest = Y_missing[Y_missing.isnull()]Xtrain = X_missing.iloc[Ytrain.index,:]Xtest = X_missing.iloc[Ytest.index,:]from sklearn.ensemble import RandomForestRegressorrfc = RandomForestRegressor(n_estimators=100)rfc = rfc.fit(Xtrain, Ytrain)Ypredict = rfc.predict(Xtest)all_data.loc[all_data.loc[:,"Age"].isnull(),"Age"] = Ypredictall_data["Age"] = all_data["Age"].apply(lambda x:round(x))nameList = ["Sex","Pclass","Fare","Title","Age","FamilyLabel","TicketLabel","Embarked"]df_data = all_data.loc[:,nameList]df_data = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(df_data)df_data = pd.DataFrame(df_data)查看数据,所有缺失值填充完毕,共1309个。
df_data.info()
4、构建模型
第一步,我们首先从处理好的数据中剥离出训练集和测试集。
Y = all_data.loc[:,"Survived"]Y_predict = Y[Y.isnull()]Y_train = Y[Y.notnull()]X_train = df_data.iloc[Y_train.index,:]X_predict = df_data.iloc[Y_predict.index,:]第二步,使用一般参数(n_estimators=100,random_state=90)代入模型,进行交叉验证,得到结果并不满意,需要继续调参。
rfc = RandomForestClassifier(n_estimators=100,random_state=90)score_pre = cross_val_score(rfc,X_train,Y_train,cv=10).mean()score_pre0.8092594484167519
第三步,调试参数n_estimators,尝试范围0—200,以10为步长,画出参数效果曲线。
score_list=[]for i in range(0,200,10): rfc = RandomForestClassifier(n_estimators=i+1,random_state=90,n_jobs=-1) score = cross_val_score(rfc,X_train,Y_train,cv=10).mean() score_list.append(score)print(max(score_list),(score_list.index(max(score_list))*10)+1)plt.figure(figsize=[20,5])plt.plot(range(1,201,10),score_list)plt.show()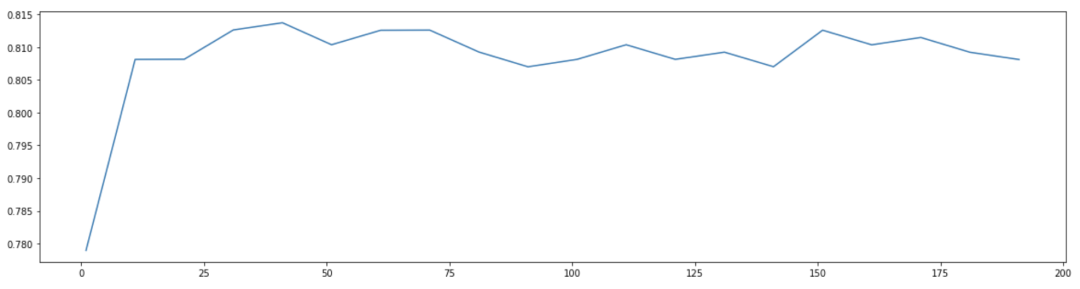
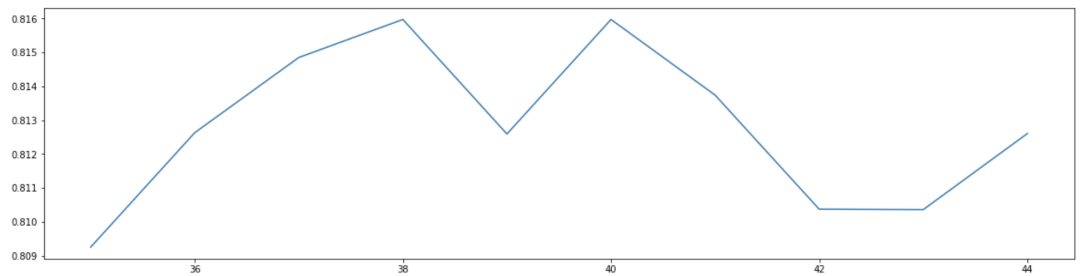
可以观察到,准确率最高值处于35——45之间,继续缩小范围。可以得到当n_estimators 为40时,取得最大值 0.8159760526614461。
score_list=[]for i in range(35,45): rfc = RandomForestClassifier( n_estimators=i, random_state=90, n_jobs=-1 )score = cross_val_score(rfc,X_train,Y_train,cv=10).mean()score_list.append(score)print(max(score_list),([*range(35,45)][score_list.index(max(score_list))]))plt.figure(figsize=[20,5])plt.plot(range(35,45),score_list)plt.show()0.8159760526614461 40
第四步,使用网格搜索方式,寻找最适合的 max_depth,min_samples_leaf,min_samples_split三个参数,并打印最优参数与最优结果。
from sklearn.model_selection import GridSearchCVparam_grid = {"max_depth":np.arange(1,20,1)}rfc = RandomForestClassifier( n_estimators=40, random_state=90 )GS = GridSearchCV(rfc,param_grid,cv=10)GS.fit(X_train,Y_train)
{'max_depth': 6}
0.8383838383838383
param_grid={'min_samples_leaf':np.arange(1,1+10,1)}rfc = RandomForestClassifier( n_estimators=40, random_state=90, max_depth=6)GS = GridSearchCV(rfc,param_grid,cv=10)GS.fit(X_train,Y_train)GS.best_params_GS.best_score_
{'min_samples_leaf': 3}
0.8417508417508418
param_grid={'min_samples_split':np.arange(2, 2+20, 1)}rfc = RandomForestClassifier( n_estimators=40, random_state=90, max_depth=6, min_samples_leaf=3)GS = GridSearchCV(rfc,param_grid,cv=10)GS.fit(X_train,Y_train)GS.best_params_GS.best_score_
{'min_samples_split': 2}
0.8417508417508418
所有最优参数已经被找到,将最优参数放入模型,并进行测试。得到预测结果0.84,比调参数前的结果提高了0.03.
rfc = RandomForestClassifier( n_estimators=40, random_state=90, max_depth=6, min_samples_leaf=3, max_features=2)score = cross_val_score(rfc,X_train,Y_train,cv=10).mean()0.8417815798433775
-
结语
灾难预测是Kaggle上比较热门和基础的算法竞赛题目;这篇文章主要给大家展示一整套数据挖掘流程和机器学习算法建模实例以及如何将数据结果可视化展示,对随机森林模型的使用与调参过程进行仔细展示。如果你在该赛题中应用本文思路,提交结果可以排名10%左右。
本文作者:



指导老师:

扫码关注大数据中心

扫码关注沈浩老师


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)