
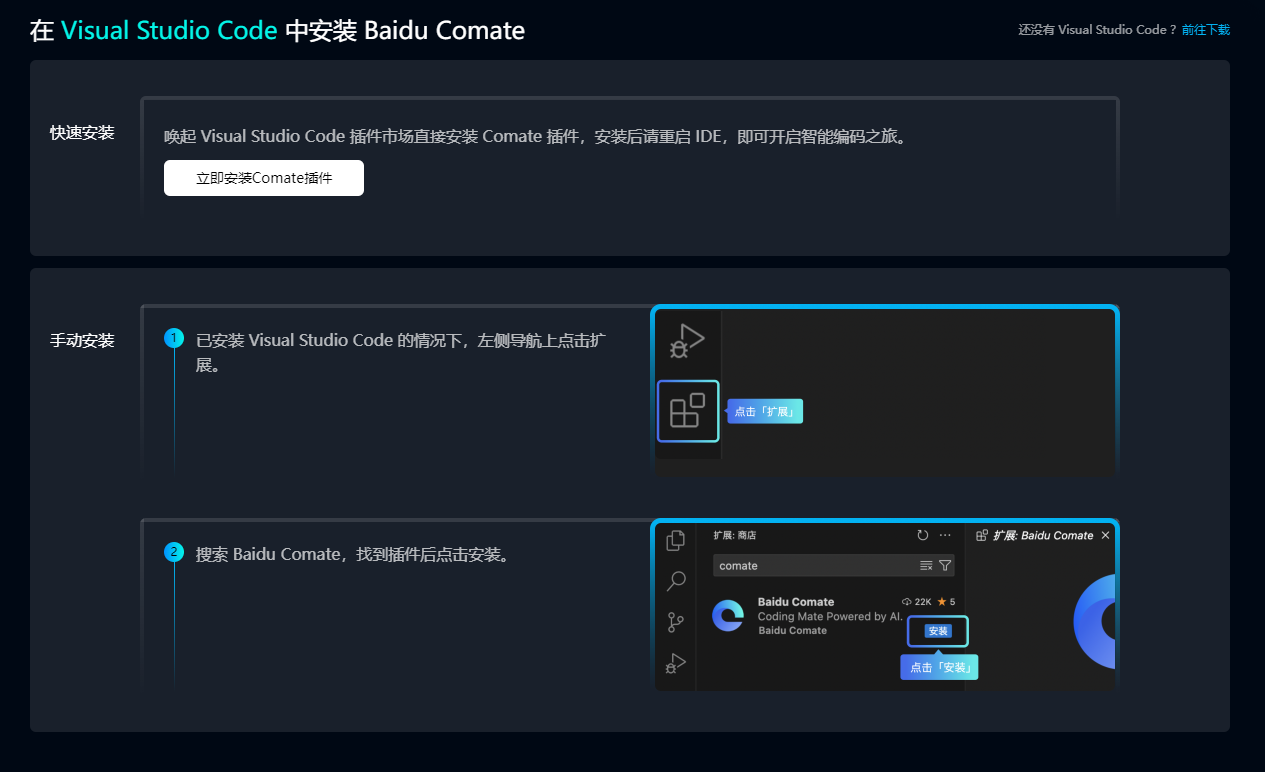
python 多帧 超分辨_基于深度学习的多帧自适应融合的视频超分辨方法与流程
本发明涉及一种基于卷积神经网络的视频超分辨算法,涉及一种多帧自适应融合的视频图像配准算法。背景技术:高分辨率的视频会给用户带来更清晰、更舒适的视觉体验,因此与之相关的技术研究也受到学者们的广泛重视。近些年发展迅猛的视频超分辨技术作为一种低成本获得高清图像的新技术,在安防、金融、现代物流等多个行业蕴含巨大的商业价值,成为了很多大公司竞相角逐的前沿科技。超分辨技术的基本任务是从原始的低分辨率(low-
本发明涉及一种基于卷积神经网络的视频超分辨算法,涉及一种多帧自适应融合的视频图像配准算法。
背景技术:
高分辨率的视频会给用户带来更清晰、更舒适的视觉体验,因此与之相关的技术研究也受到学者们的广泛重视。近些年发展迅猛的视频超分辨技术作为一种低成本获得高清图像的新技术,在安防、金融、现代物流等多个行业蕴含巨大的商业价值,成为了很多大公司竞相角逐的前沿科技。超分辨技术的基本任务是从原始的低分辨率(low-resolution,简称lr)图像或视频重构出对应的高分辨率(high-resolution,简称hr)图像或视频,这是一个典型的病态问题。目前,已有学者们提出了一些解决方案。
现有的超分辨算法主要通过以下两种途径实现:1)利用图片中结构或内容的先验知识对重构的过程添加约束来实现,例如利用图像的平滑性实现超分辨率效果;2)以数据驱动模式学习低分辨率图像到高分辨图像之间的映射,该方法也是目前重构效果最佳算法的实现模式。具体实现方式有字典学习策略,随机森林策略和神经网络策略。单帧超分辨技术是指输入为一张图像的超分辨技术。而多帧超分辨则是指通过多个连续低分辨的视频帧重构出一张高分辨视频帧的技术。相比于单帧超分辨技术,多帧超分辨算法认为帧影像之间的信息是互补的,算法可以利用这些冗余的信息来提高超分辨的效果。
多帧超分辨率算法设计的核心问题是找到有效的方法实现连续视频帧之间的配准。最新研究表明,将卷积神经网络(cnn)与运动补偿原理相结合,能够融合多个相邻低分辨率帧的信息,进而实现图像配准。目前主流的多帧超分辨率算法通常是利用一组固定帧数的连续低分辨率图像生成一个单帧的高分辨图像。然而,这种基于固定帧数的多帧超分辨率算法存在以下两方面问题:1)当相邻帧之间的图像内容差别非常大时,如果选取的帧数过大,这给图像配准带来了极大的困难,且融合后的视频极易出现不良的闪烁现象而影响用户的体验;2)当帧数选取过小,又不能充分利用相邻帧的冗余信息。如何自适应融合的不同帧数预测的图像信息就显得十分重要。
技术实现要素:
针对传统固定帧数融合的多帧超分辨率算法在多帧图像有效利用方面存在的不足,本发明提出了一种自适应融合不同帧数预测图像的多帧超分辨率算法。由于该算法能较好的适配相邻帧之间图像内容差异大小的波动,因此可获得更稳定、清晰的超分辨率效果。技术方案如下:
一种基于深度学习的多帧自适应融合的视频超分辨方法,包括下列步骤:
第一步,构建训练本发明的网络所需的数据集
将已有视频数据集中的视频逐帧读取成图像并保存,记作高分辨率图像集yhr,然后将高分辨率图像集yhr中的每一张图像做下采样得到对应的低分辨率图像集ylr。
第二步,通过深度学习框架tensorflow搭建多帧自适应融合的视频超分辨网络
多帧自适应融合的视频超分辨网络被划分为两个部分:多帧自适应配准网络和超分辨网络,其中多帧自适应配准网络能够将需要超分辨的关键帧的相邻帧进行扭曲,使其和关键帧的内容趋于相同,以提供给算法更多的细节信息,而超分辨网络则将多帧自适应配准网络的输出超分辨为高分辨率帧图像,包括步骤如下:
(1)多帧自适应配准网络根据视频帧长度的不同被划分为三个子部分:分别为关键帧直接输出部分,三帧运动配准部分和五帧运动配准部分;其中三帧运动配准部分和五帧运动配准部分各由八层卷积神经网络构成,记作fnet,每个卷积层之后都选取relu函数作为激活函数,前三层卷积神经网络通过两倍最大池化实现图像的下采样功能,之后的三层卷积神经网络通过双三次插值实现上采样功能,设所需超分辨的关键帧为第n帧,记为in,下面为多帧自适应配准网络的数学模型:
fout=[α·fnet(in-2,in-1,in,in+1,in+2)+β·fnet(in-1,in,in+1)+γ·fnet(in)]
其中fout代表多帧自适应配准网络的输出,α,β,γ分别代表五帧运动配准部分,三帧运动配准部分和关键帧直接输出部分所对应的权重,in-2,in-1,in+1,in+2则分别代表关键帧的前两帧图像和后两帧图像;
(2)超分辨网络fsr共包含多个卷积层,每个卷积层后都接有一个relu函数作为激活函数,网络的最后通过连接两个反卷积层实现图像的上采样,将网络的输入和输出直接进行连接防止在训练过程中发生梯度弥散问题,iout为超分辨网络fsr的输出,超分辨网络的数学模型如下:
yout=fsr(fout)
第三步,用第一步获得的高分辨率图像集yhr和低分辨率图像集ylr对所设计网络进行训练,网络的损失定义为l2损失:
loss=(yout-yhr)2
其中yout超分辨网络的输出,训练完成后保存网络的结构和参数;
第四步,设所需超分辨的低分辨率视频为v,将低分辨率视频v作为第三步保存的网络的输入,对应输出则为所需的高分辨率视频,至此完成视频超分辨过程。
优选地,第三步中,网络优化器设置为adam;一个训练批次设置为128张图像;网络的初始学习率设置为0.01;当损失连续100个epoch没有明显的下降时将其降低10倍,最终的学习率设置为10-5;训练epoch设置为5000。
本发明同时提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述程序时实现上述的方法步骤。
本发明所设计的基于深度学习的多帧自适应融合的视频超分辨算法,相比于传统固定帧数的视频超分辨模型,在相邻帧之间图像内容差异波动大的情况下具有更强的鲁棒性。有效的解决了传统的固定帧数的视频超分辨算法所带来的图像配准难度增大和难以充分利用相邻帧之间冗余信息的问题,并且有效的避免了超分辨结果的闪烁。
本发明所设计的模型可广泛的用于对低质量视频的超分辨处理,本发明可以充分的考虑相邻视频帧内容之间的差异进而选取更适宜的网络参数对目标视频进行超分辨处理。
附图说明
图1为多帧自适应融合的视频超分辨网络的整体结构
图2为多帧配准网络的结构
图3为本发明的算法对同一个视频帧进行超分辨的结果,四幅图像分别为:原始低分辨图像,双三次上采样的结果,vespcn视频超分辨网络的结果和本发明的结果
图4为本发明算法的流程图
表1为多帧配准网络的参数
表2为图像超分辨网络的参数
具体实施方式
下面结合实例与附图对本专利的基于深度学习的多帧自适应融合的视频超分辨算法的数学模型与具体实施方案做出详细说明,具体的流程图由图4给出:
第一步,构建训练本发明的网络所需的数据集,即将vimeo-90k视频数据集中的视频逐帧读取成图像并保存,记作高分辨率图像集yhr,然后通过matlab将高分辨率图像集yhr中的每一张图像做下采样得到对应的低分辨率图像集ylr。
第二步,通过深度学习框架tensorflow搭建多帧自适应融合的视频超分辨网络。如图1所示,该图为本发明网络的整体框架,多帧自适应融合的视频超分辨网络被划分为两个部分:多帧自适应配准网络和超分辨网络。其中多帧自适应配准网络能够将需要超分辨的关键帧的相邻帧进行扭曲,使其和关键帧的内容趋于相同,以提供给算法更多的细节信息。而超分辨网络则将多帧自适应配准网络的输出超分辨为高分辨率帧图像,具体如下:
(1)多帧自适应配准网络根据视频帧长度的不同被划分为三个子部分:分别为关键帧直接输出部分,三帧运动配准部分和五帧运动配准部分。其中三帧运动配准部分和五帧运动配准部分各由八层卷积神经网络构成,记作fnet。fnet的结构由图2所示,具体参数由表1给出,每个卷积层之后都选取relu函数作为激活函数,前三层卷积神经网络通过两倍最大池化实现图像的下采样功能,之后的三层卷积神经网络通过双三次插值实现上采样功能。假设所需超分辨的关键帧为第n帧(记为in),下面为多帧自适应配准网络的数学模型:
fout=[α·fnet(in-2,in-1,in,in+1,in+2)+β·fnet(in-1,in,in+1)+γ·fnet(in)]
其中fout代表多帧自适应配准网络的输出,α,β,γ分别代表五帧运动配准部分,三帧运动配准部分和关键帧直接输出部分所对应的权重,in-2,in-1,in+1,in+2则分别代表关键帧的前两帧图像和后两帧图像。
(3)超分辨网络fsr的结构由图1的右半部分,具体参数由表2给出,它共包含12个卷积层,每个卷积层后都接有一个relu函数作为激活函数,网络的最后通过连接两个反卷积层实现图像的上采样。在结构上,本发明将网络的输入和输出直接进行连接防止在训练过程中发生梯度弥散问题。iout为超分辨网络fsr的输出,超分辨网络的数学模型如下:
iout=fsr(fout)
第三步,用第一步获得的高分辨率图像集yhr和低分辨率图像集ylr对所设计网络进行训练,网络的损失定义为l2损失,具体如下:
loss=(yout-yhr)2
其中yout超分辨网络的输出。网络优化器设置为adam;一个训练批次设置为128张图像;网络的初始学习率设置为0.01;当损失连续100个epoch没有明显的下降时将其降低10倍,最终的学习率设置为10-5;训练epoch设置为5000。训练完成后保存网络的结构和参数。
第四步,假设所需超分辨的低分辨率视频为v,仅需将低分辨率视频v作为第三步保存的网络的输入,对应输出则为所需的高分辨率视频,至此完成视频超分辨过程。
本发明将同一个低分辨率帧图像作为该网络的输入,并将输出的结果与其他经典方法进行对比,对比结果如图3所示。从结果可以看出我们的算法相比其他的算法取得了更好的效果。
表1
表2

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)