
pytorch中resnet_Pytorch中的残差网络
一、torchvision中的resnettorchvision0.4.0 中预写好的resnet大类有九种,分别来自于三篇resnet相关论文[1][3][4]https://github.com/pytorch/vision/blob/v0.4.0/torchvision/models/resnet.py#L11-L21github.com其中resnet18,34,50,101,152来自
一、torchvision中的resnet
torchvision0.4.0 中预写好的resnet大类有九种,分别来自于三篇resnet相关论文[1][3][4]
https://github.com/pytorch/vision/blob/v0.4.0/torchvision/models/resnet.py#L11-L21github.com
其中resnet18,34,50,101,152来自[1], rsenext50_32x4d/8d来自[4], wide_resnet50_2/101_2来自[3]
二、原始Resnet网络总体结构
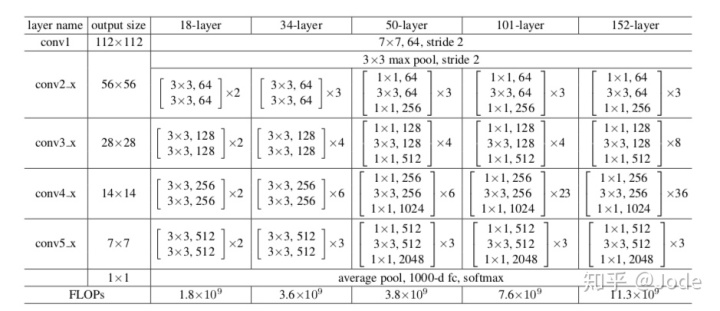
网络总体结构是一致的:五大层卷积,特征图尺寸逐层减半,通道数倍数增加。第一大层为 7x7, p=3, s=2的卷积,接bn,接relu,接3*3,s=2, p=1 maxpooling.
每大层间用1x1卷积调整通道数来匹配下一层输出的通道数,以传递恒等映射。18,34需要提升通道数,50,101,152需要减少通道数。
每大层的第一个residual unit中的卷积层设置s=2,p=1减半尺寸(准确的说是第一个3*3的卷积层),其他所有3x3的卷积设置p=1保证尺寸不再变化。
最后的输出层的average pool是global的,也就是每个通道的7*7的feature map取平均变成1*1,再塞进一层全连接输出。
在诸如conv2_x大层中,由基本的residual unit组成。
- resnet18/34使用的是两层3x3卷积,具体结构为:1. 3x3卷积接bn接relu 2. 3x3卷积接bn加identity接relu。在torchvision源码中称为'BasicBlock' https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py#L35-L73
- reset50/101/152使用的是三层卷积,具体结构为:1. 1x1卷积接bn接relu 2. 3x3卷积接bn接relu 3. 1x1卷积接bn加identity接relu。在[1]与源码中都称为'Bottleneck' https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py#L76-L117
三、ResNeXt
TODO(没用到懒得细看)
使用了分组卷积。融合了Resnet与Inception的idea。
四、WideResnet
TODO(没用到懒得细看)
增加了卷积层的channel数,可增强浅层模型的能力,即wide的含义
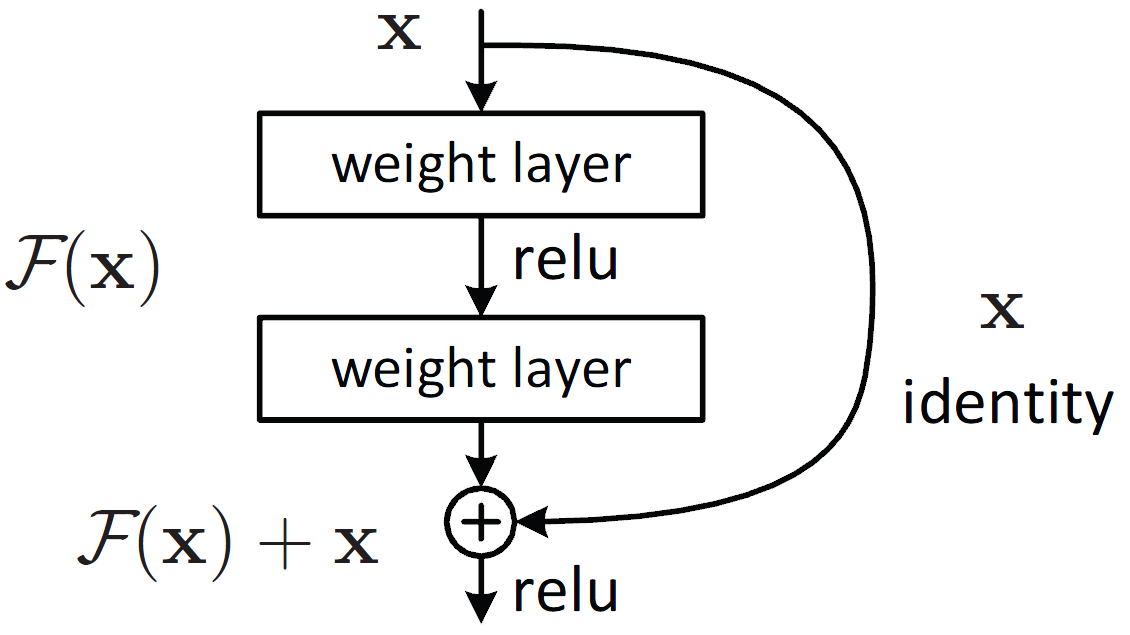
五、Residual Unit
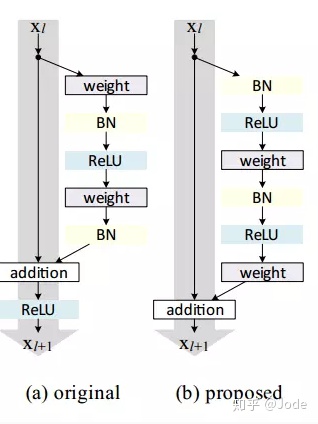
在 He, Kaiming, et al.[2] 提出了改进的residual unit,调换了"Basicblock"里的组织顺序。
从:
1. 3x3卷积接bn接relu
2. 3x3卷积接bn加identity接relu
变成了
1. bn接relu接3x3卷积 *2
2. 加identity
其中重要的变化:1. 改进后的结构输入卷积层的数据先经过BN,有助于泛化能力 2. 改进后的结构走shortcut的上层输出不再经过relu,更加接近identity(论文[2]中有详细说明)
torchvision中没有目前实现[2]提出的网络与结构。
总之, He, Kaiming, et al.[1] 提出了resnet的基本结构,其假设是在加深网络结构时,如果新增的结构能够更容易地转化成恒等映射,那么网络的深度至少不会损害已有的结构,比浅层网络更差(degeneration),也更容易优化。He, Kaiming, et al.[2]在公式上说明了skip connection的加性结构比传统的复合函数结构更容易传递梯度,以及保持恒等映射的重要性。并用大量对比实验证明了这点。
PS:
论文中并没有说不使用bias,但以上所有实现都没有bias
Reference
[1] He, Kaiming, et al. "Deep residual learning for image recognition."Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[2] He, Kaiming, et al. "Identity mappings in deep residual networks."European conference on computer vision. Springer, Cham, 2016.
[3] Zagoruyko, Sergey, and Nikos Komodakis. "Wide residual networks."arXiv preprint arXiv:1605.07146(2016).
[4] Xie, Saining, et al. "Aggregated residual transformations for deep neural networks."Proceedings of the IEEE conference on computer vision and pattern recognition. 2017.

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)