
深度学习性能评价指标分析
基本定义下图中是机器学习训练后的模型性能常用指标,及其来源:分类正确的两类:true positive(简称TP):对象本来为正例,网络识别为正例true negative(简称TN):对象本来为负例,网络识别为负例分类错误的两类:false positive(简称FP):对象本来为负例,网络识别为正例,通常叫误报false negative(简称FN):对象本来为正例,网络识别为负例,通常叫漏报
基本定义
下图中是机器学习训练后的模型性能常用指标,及其来源:
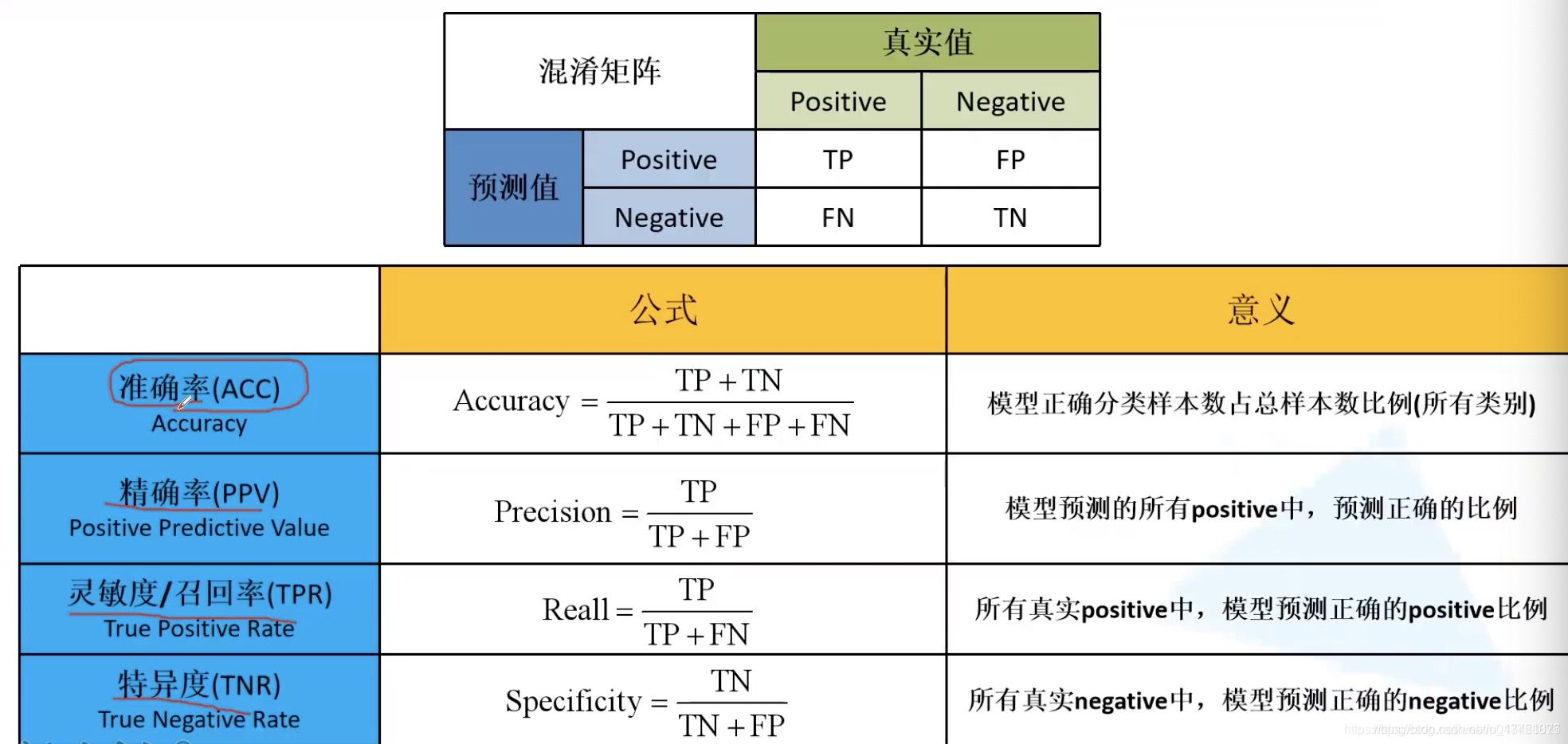
分类正确的两类:
true positive(简称TP):对象本来为正例,网络识别为正例
true negative(简称TN):对象本来为负例,网络识别为负例
分类错误的两类:
false positive(简称FP):对象本来为负例,网络识别为正例,通常叫误报
false negative(简称FN):对象本来为正例,网络识别为负例,通常叫漏报
什么是 Ground Truth
字面意思就是实际情况,也就是“数据集+标注”。我们可简单理解人工标注。
在统计TP\TN\FP\FN的时候,实际上就是用预测结果和Ground Truth比较。
精度和召回率
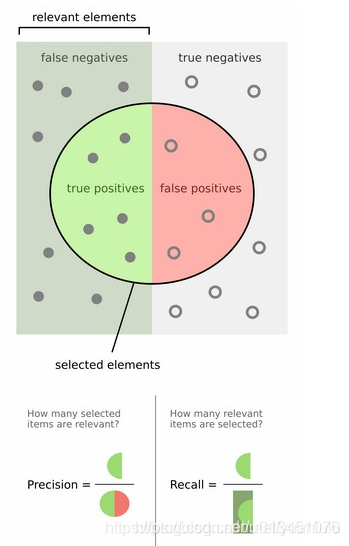
precision = TP / (TP + FP),即precision表示的是在识别出的所有正例中,识别正确的正例所占的比例。
recall = TP / (TP + FN),即recall表示的是在样本所有真正的正例中,识别正确的正例所占的比例。
其实下图就可以说明分类的精度和召回率的计算方式:
换成目标检测,也可以画成下面的样子

IOU
预测的边框 和 真实的边框 的交集和并集的比例 称为 IoU(Intersection over Union)。

ROC曲线
本段参考《ROC曲线 vs Precision-Recall曲线》和《ROC曲线与AUC》
ROC全称是“受试者工作特征”(Receiver Operating Characteristic)。
真正例率 TPR (True Positive Rate):所有正例中,有多少被正确地判定为正。
假正例率 FPR (False Positive Rate):所有负例中,有多少被错误地判定为正。

其实 TPR 就是 查全率/召回率(recall) 。
分类阈值,即设置判断样本为正例的阈值thr,预测为正样本的概率 P(y=1 | x) >= thr (常取thr=0.5) 则判定样本为正例。
阈值取不同值,TPR和FPR的值也不同,将它们的值画成曲线,就是ROC曲线。
ROC曲线是一个单调曲线,而且肯定经过点(0,0)与(1,1)。ROC曲线距离左上角越近,证明分类器效果越好。

举个例子,4个正样本,预测为正样本的概率分别是1、0.75、0.5、0.25,当我的阈值分别是0.9、0.6、0.4、0.2的情况下,查全率分别是0.25、0.5、0.75和1。如果样本有限的话,ROC曲线就是台阶一样,单整体是递增的。
人脸检测网络喜欢用ROC来对比性能(注意横轴是误检数,不是误检率)

上述说的都是二分类。对于多分类的问题,可以针对每个类都画出一个ROC,对每个类来说都是二分类(本类和其他类)。
ROC曲线下的面积就是AUC(Area Under the Curve)。AUC用于衡量“二分类问题”机器学习算法的性能。
AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。
0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
AUC = 0.5,跟随机猜测一样,模型没有预测价值。
AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)