
用python实现识别图像中的文字
主要使用的是paddleocr库(一个基于PaddlePaddle的OCR(光学字符识别)库),安装这个库之前还需要安装其依赖项lmbd(是一个C库,用于存储键值对的数据库),而安装lmdb,又需要安装一个名为patch-ng。
·
环境配置
主要使用的是paddleocr库(一个基于PaddlePaddle的OCR(光学字符识别)库),安装这个库之前还需要安装其依赖项lmbd(是一个C库,用于存储键值对的数据库),而安装lmdb,又需要安装一个名为patch-ng的Python模块,这是用于编译C库的必要工具,所以安装过程如下:
pip install paddlepaddle
pip install patch-ng
pip install lmdb
pip install paddleocr实现代码
from paddleocr import PaddleOCR
#实例化OCR模型
ocr=PaddleOCR()
#识别图片中的文字
result=ocr.ocr('D:\\work_zxt\\code\\长恨歌.jpg')
# print('识别结果:',result)
with open('D:\\work_zxt\\code\\text.txt','w',encoding='utf-8') as file:
for line in result:
for word in line:
text_line=word[-1] #提取出识别数据中的文字元组
text=text_line[0] #从文字元组中提取文字内容
print("text:",text)
file.write(text+'\n') #将文字内容写入文件中
print("文字写入成功!")
解释说明:其中word是一个列表,包含图中每一句的位置信息(通常是一个四元组,形式为 (xmin, ymin, xmax, ymax)),置信度(表示文字被正确识别的概率),文字内容,其他信息(文字的类型、语言等)
结果展示
识别图像:

识别结果:
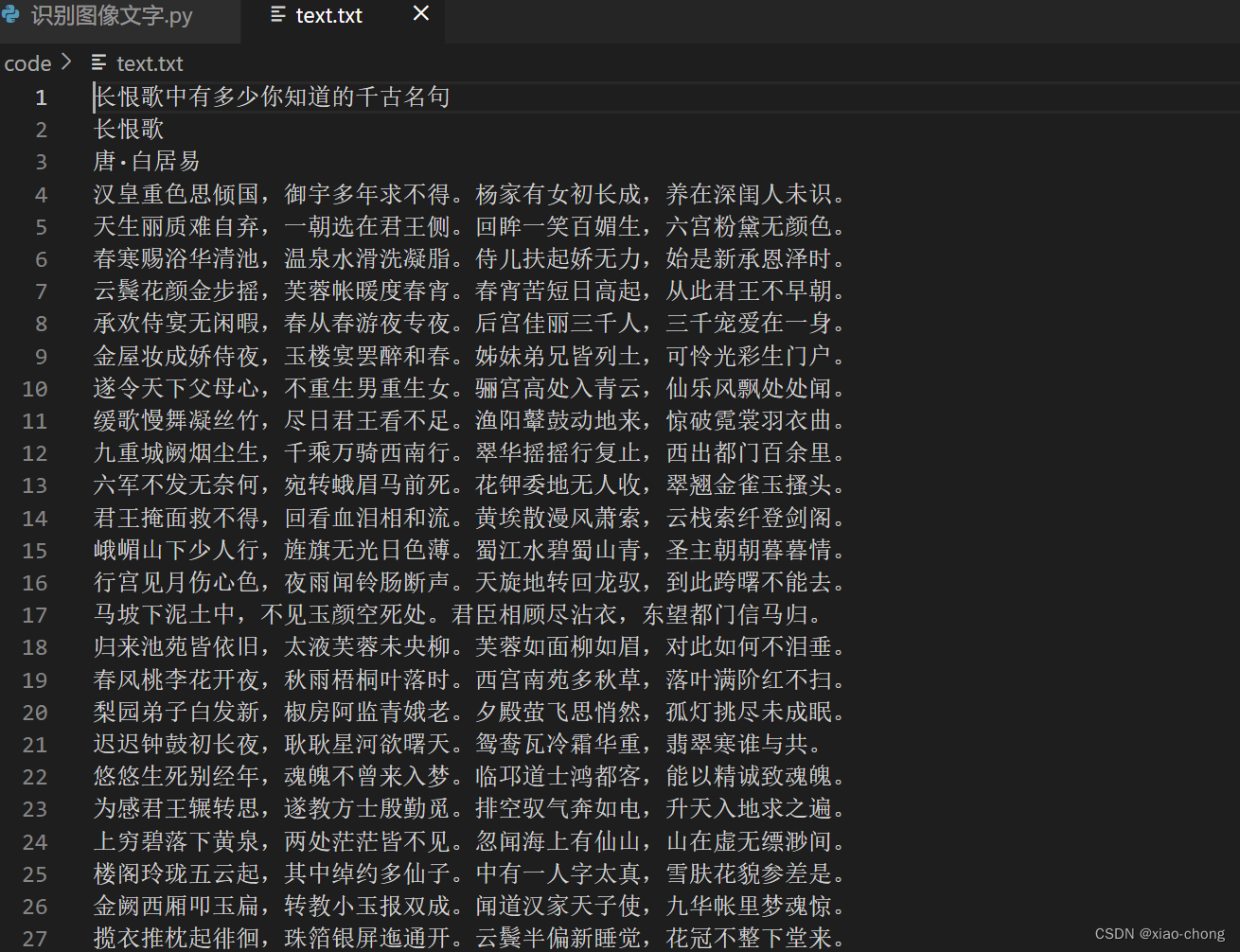
实现起来也挺简单的,可以试试玩哦。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)