
机器学习——主动学习之ALEC
文章目录一、主动学习1. 主动学习2. 半监督学习:二、三支主动学习1. 关于Density Peak的聚类2. ALEC算法三、 具体实现学习来源:主动学习: 从三支决策到代价敏感日撸 Java 三百行(61-70天,决策树与集成学习)摘要:主动学习通过人机交互,使用更少的标签获得良好的分类能力。使用三支决策,在每轮将样本分为查询、分类、待处理三个区域,并在交互过程中不断减少待处理区域数据量,最
学习来源: 主动学习: 从三支决策到代价敏感
日撸 Java 三百行(61-70天,决策树与集成学习)
摘要:主动学习通过人机交互,使用更少的标签获得良好的分类能力。使用三支决策,在每轮将样本分为查询、分类、待处理三个区域,并在交互过程中不断减少待处理区域数据量,最终获得分类结果。在实际应用中,需要综合考虑测试代价、标签查询代价、误分类代价的折中,以最小化总代价为目标,获得最优解决方案。
一、主动学习
1. 主动学习
主动学习是半监督学习的一个子类。
输入M个没有标签的数据,机器可以主动选择这其中N个数据交给专家去打标签,然后机器会根据这N个标签去建立模型。但是后续进行数据分时,根据分类数据的不同又分为了:
- 封闭环境(close world),对剩余的P个样本进行分类
- 开放环境(open world),对于全新给出的k个外界样本进行分类
主动学习过程中对于标签的询问并不是乱问的,往往我们可能会考虑“ 不确定性 ”的标签去询问,或者通过先前对于M个数据的内部清理,从而筛选出了若干“ 有代表性 ”的问题去询问。
另外这里的专家标记可能不是依次就标记了N个,这个过程可能是一个循环往复的过程,会多次咨询专家并且多次去学习。最终使得人类的经验知识越来越丰富,模型的泛化性能也越来越好,人机交互,各自获得较好的收益。
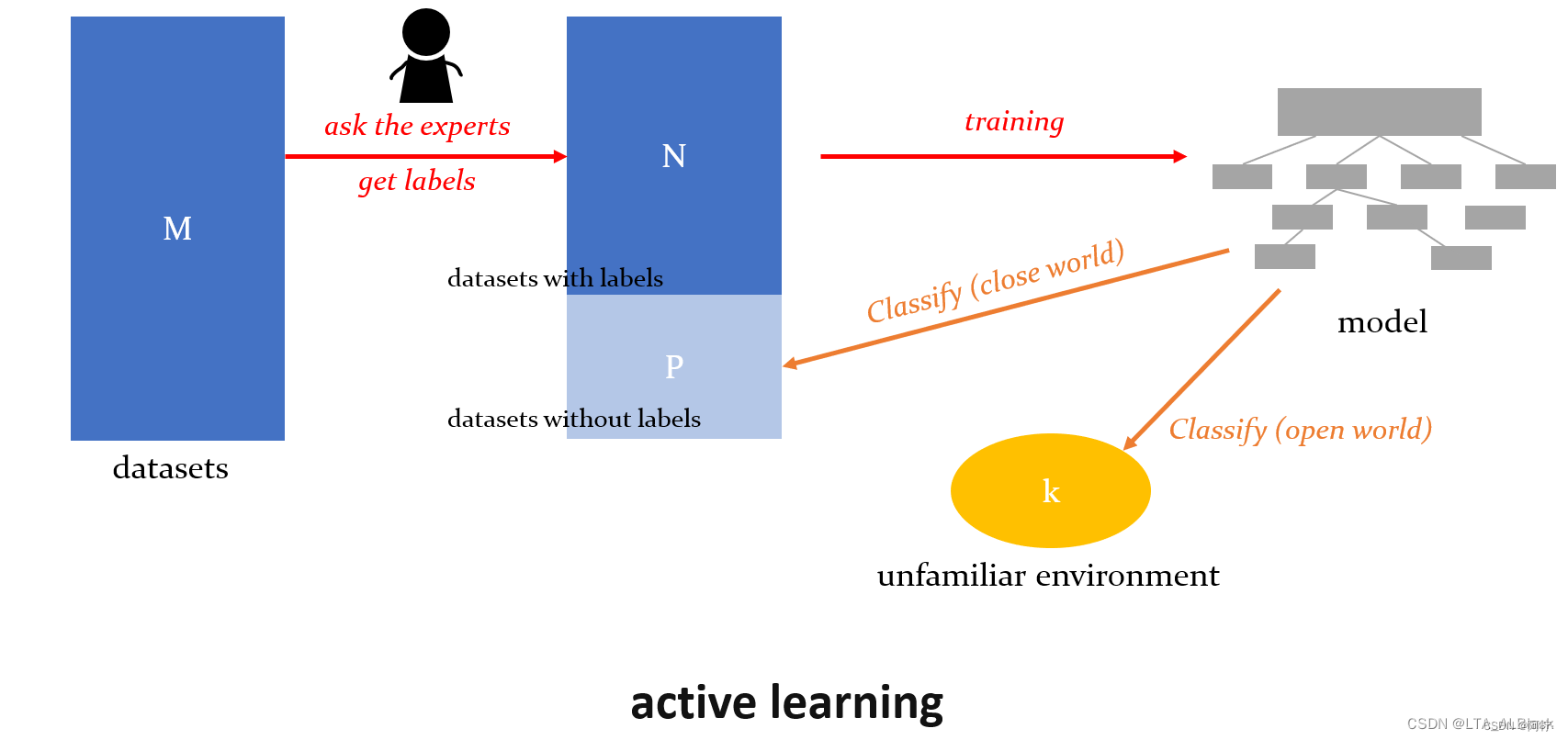
图 1. 主 动 学 习 图 1. 主动学习 图1.主动学习
2. 半监督学习
- 半监督学习是一种介于监督学习和无监督学习之间的一种学习方法
- 在监督学习中,样本的类别标签都是已知的,学习的目的是找到样本的特征与类别标签之间的联系。训练样本的数量越多,训练得到的分类器的分类精度也会越高。
- 但是在很多现实问题当中,一方面是由于人工标记样本的成本很高,导致有标签的数据十分稀少。而另一方面,无标签的数据很容易被收集到,其数量往往是有标签样本的上百倍。
- 半监督学习(这里仅针对半监督分类),就是要利用大量的无标签样本和少量带有标签的样本来训练分类器,解决有标签样本不足的难题。
二、三支主动学习
- 基于聚类的主动学习
样本处于三种状态: 被查询、被分类、延迟处理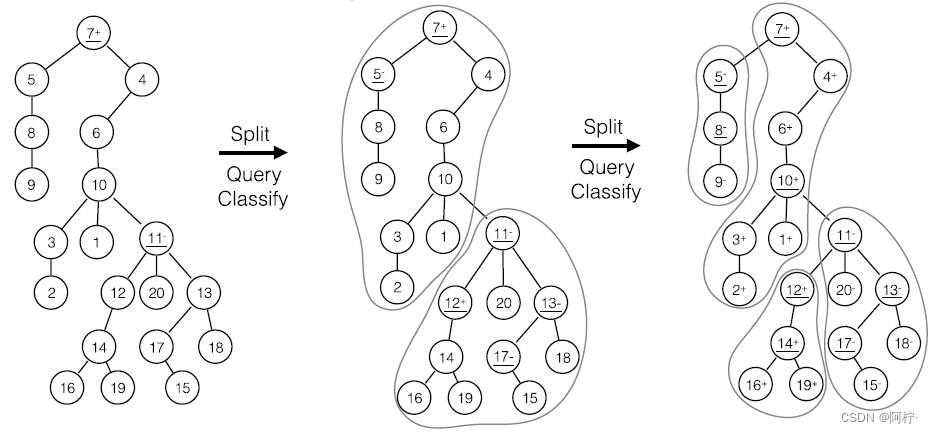
图 2. 三 支 主 动 学 习 图 2. 三支主动学习 图2.三支主动学习
1. 关于Density Peak的聚类
Density Peak的度量方法大致如下:
- 以样本x为中心,dc为半径可以得到一个圆域,任何一个落入这个圆域的点都被纳入样本x的统计中,最终确定落入圆域中点的密度值Densityx.
- 所有点集都能以dc为大小确定自己的圆域并且统计密度值Density,然后确定一个样本x及其密度。若先有一个样本y,这个样本的密度值要高于x,同时距离x最近。取这个距离为l。
- 定义样本x的密度值Density代表了这个点的重要性(importance),距离l代表了样本x的独立性(independence),而这重要性与独立性的乘积是样本x的代表性(representative)。
2. ALEC算法
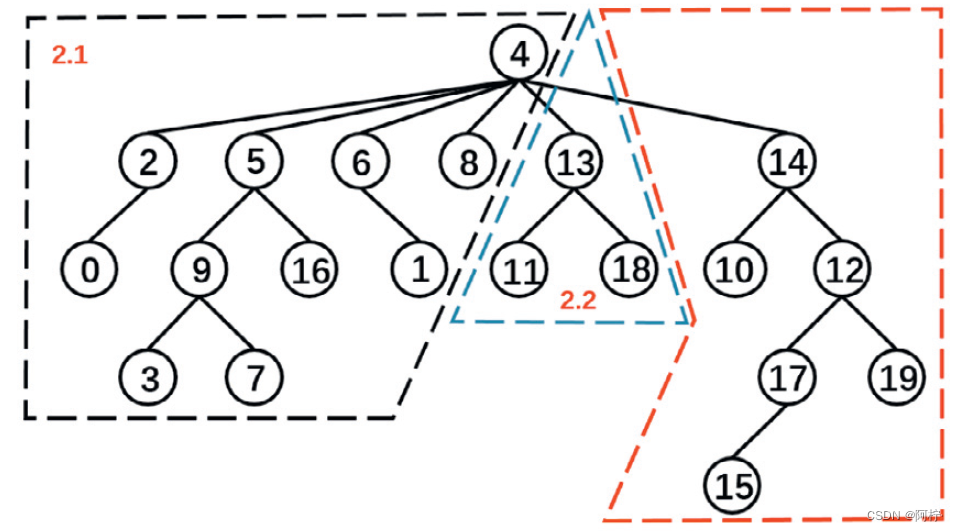
图 3. A L E C 算 法 运 行 示 例 图 3. ALEC 算法运行示例 图3.ALEC算法运行示例
- Step 1. 根据 Density peaks 将数据组织成一棵树, 同时计算每个对象的代表性;
- Step 2. 查询当前块代表性最高的若干样本;
- Step 3. 如果被查询样本具有同样的标签, 则认为当前块纯了, 将其余样本全部打上同样标签;
- Step 4. 否则将当前块分裂为两块, 递归到下一级的 Step 2;
三、 具体实现
基于聚类主动学习的基本思想如下:
Step 1. 将对象按代表性递减排序;
Step 2. 假设当前数据块有 N N N个对象, 选择最具代表性的 N \sqrt{N} N 个查询其标签 (类别).
Step 3. 如果这 N \sqrt{N} N个标签具有相同类别, 就认为该块为纯的, 其它对象均分类为同一类别. 结束.
Step 4. 将当前块划分为两个子块, 分别 Goto Step 3.
- 今天只抄到 280 行.
- mergeSortToIndices 是排序算法在本论文中的灵活运用. 它起到了关键的作用.
- distance 仅实现了欧氏距离.
- computeMaximalDistance 获得数据集的直径.
- computeDensitiesGaussian 使用了高斯对Density Peak进行了优化 论文里面是截断距离 cutoff, 导致很多对象的密度相同, 难于区分其重要程度. 高斯则有效避免这个问题.
package machinelearning.activelearning;
import java.io.FileReader;
import java.util.Arrays;
import weka.core.Instances;
/**
*
* @author Ling Lin E-mail:linling0.0@foxmail.com
*
* @version 创建时间:2022年5月17日 下午4:38:53
*
*/
public class Alec {
/**
* The whole dataset.
*/
Instances dataset;
/**
* The maximal number of queries that can be provided.
*/
int maxNumQuery;
/**
* The actual number of queries.
*/
int numQuery;
/**
* The radius, also dc in the paper. It is employed for density computation.
*/
double radius;
/**
* The densities of instances, also rho in the paper.
*/
double[] densities;
/**
* distanceToMaster
*/
double[] distanceToMaster;
/**
* Sorted indices, where the first element indicates the instance with the
* biggest density.
*/
int[] descendantDensities;
/**
* Priority
*/
double[] priority;
/**
* The maximal distance between any pair of points.
*/
double maximalDistance;
/**
* Who is my master?
*/
int[] masters;
/**
* Predicted labels.
*/
int[] predictedLabels;
/**
* Instance status. 0 for unprocessed, 1 for queried, 2 for classified.
*/
int[] instanceStatusArray;
/**
* The descendant indices to show the representativeness of instances in a
* descendant order.
*/
int[] descendantRepresentatives;
/**
* Indicate the cluster of each instance. It is only used in
* clusterInTwo(int[]);
*/
int[] clusterIndices;
/**
* Blocks with size no more than this threshold should not be split further.
*/
int smallBlockThreshold = 3;
/**
**********************************
* The constructor.
*
* @param paraFilename
* The data filename.
**********************************
*/
public Alec(String paraFilename) {
try {
FileReader tempReader = new FileReader(paraFilename);
dataset = new Instances(tempReader);
dataset.setClassIndex(dataset.numAttributes() - 1);
tempReader.close();
} catch (Exception ee) {
System.out.println(ee);
System.exit(0);
} // Of fry
computeMaximalDistance();
clusterIndices = new int[dataset.numInstances()];
}// Of the constructor
/**
**********************************
* Merge sort in descendant order to obtain an index array. The original
* array is unchanged. The method should be tested further. <br>
* Examples: input [1.2, 2.3, 0.4, 0.5], output [1, 0, 3, 2]. <br>
* input [3.1, 5.2, 6.3, 2.1, 4.4], output [2, 1, 4, 0, 3].
*
* @param paraArray
* the original array
* @return The sorted indices.
**********************************
*/
public static int[] mergeSortToIndices(double[] paraArray) {
int tempLength = paraArray.length;
int[][] resultMatrix = new int[2][tempLength];// For merge sort.
// Initialize
int tempIndex = 0;
for (int i = 0; i < tempLength; i++) {
resultMatrix[tempIndex][i] = i;
} // Of for i
// Merge
int tempCurrentLength = 1;
// The indices for current merged groups.
int tempFirstStart, tempSecondStart, tempSecondEnd;
while (tempCurrentLength < tempLength) {
// Divide into a number of groups.
// Here the boundary is adaptive to array length not equal to 2^k.
for (int i = 0; i < Math.ceil((tempLength + 0.0) / tempCurrentLength / 2); i++) {
// Boundaries of the group
tempFirstStart = i * tempCurrentLength * 2;
tempSecondStart = tempFirstStart + tempCurrentLength;
tempSecondEnd = tempSecondStart + tempCurrentLength - 1;
if (tempSecondEnd >= tempLength) {
tempSecondEnd = tempLength - 1;
} // Of if
// Merge this group
int tempFirstIndex = tempFirstStart;
int tempSecondIndex = tempSecondStart;
int tempCurrentIndex = tempFirstStart;
if (tempSecondStart >= tempLength) {
for (int j = tempFirstIndex; j < tempLength; j++) {
resultMatrix[(tempIndex + 1) % 2][tempCurrentIndex] = resultMatrix[tempIndex % 2][j];
tempFirstIndex++;
tempCurrentIndex++;
} // Of for j
break;
} // Of if
while ((tempFirstIndex <= tempSecondStart - 1) && (tempSecondIndex <= tempSecondEnd)) {
if (paraArray[resultMatrix[tempIndex % 2][tempFirstIndex]] >= paraArray[resultMatrix[tempIndex
% 2][tempSecondIndex]]) {
resultMatrix[(tempIndex + 1) % 2][tempCurrentIndex] = resultMatrix[tempIndex
% 2][tempFirstIndex];
tempFirstIndex++;
} else {
resultMatrix[(tempIndex + 1) % 2][tempCurrentIndex] = resultMatrix[tempIndex
% 2][tempSecondIndex];
tempSecondIndex++;
} // Of if
tempCurrentIndex++;
} // Of while
// Remaining part
for (int j = tempFirstIndex; j < tempSecondStart; j++) {
resultMatrix[(tempIndex + 1) % 2][tempCurrentIndex] = resultMatrix[tempIndex % 2][j];
tempCurrentIndex++;
} // Of for j
for (int j = tempSecondIndex; j <= tempSecondEnd; j++) {
resultMatrix[(tempIndex + 1) % 2][tempCurrentIndex] = resultMatrix[tempIndex % 2][j];
tempCurrentIndex++;
} // Of for j
} // Of for i
tempCurrentLength *= 2;
tempIndex++;
} // Of while
return resultMatrix[tempIndex % 2];
}// Of mergeSortToIndices
/**
*********************
* The Euclidean distance between two instances. Other distance measures
* unsupported for simplicity.
*
*
* @param paraI
* The index of the first instance.
* @param paraJ
* The index of the second instance.
* @return The distance.
*********************
*/
public double distance(int paraI, int paraJ) {
double resultDistance = 0;
double tempDifference;
for (int i = 0; i < dataset.numAttributes() - 1; i++) {
tempDifference = dataset.instance(paraI).value(i) - dataset.instance(paraJ).value(i);
resultDistance += tempDifference * tempDifference;
} // Of for i
resultDistance = Math.sqrt(resultDistance);
return resultDistance;
}// Of distance
/**
**********************************
* Compute the maximal distance. The result is stored in a member variable.
**********************************
*/
public void computeMaximalDistance() {
maximalDistance = 0;
double tempDistance;
for (int i = 0; i < dataset.numInstances(); i++) {
for (int j = 0; j < dataset.numInstances(); j++) {
tempDistance = distance(i, j);
if (maximalDistance < tempDistance) {
maximalDistance = tempDistance;
} // Of if
} // Of for j
} // Of for i
System.out.println("maximalDistance = " + maximalDistance);
}// Of computeMaximalDistance
/**
******************
* Compute the densities using Gaussian kernel.
*
* @param paraBlock
* The given block.
******************
*/
public void computeDensitiesGaussian() {
System.out.println("radius = " + radius);
densities = new double[dataset.numInstances()];
double tempDistance;
for (int i = 0; i < dataset.numInstances(); i++) {
for (int j = 0; j < dataset.numInstances(); j++) {
tempDistance = distance(i, j);
densities[i] += Math.exp(-tempDistance * tempDistance / radius / radius);
} // Of for j
} // Of for i
System.out.println("The densities are " + Arrays.toString(densities) + "\r\n");
}// Of computeDensitiesGaussian
}// Of class Alec
续:
- computeDistanceToMaster 是密度聚类的核心. 节点的父节点 (master), 是比它密度大的节点中, 距离最近那个. 到父节点的距离越远, 表示独立性越强.
- computePriority 综合考虑密度 (能力) 与距离 (独立性). 这两者乘积越大的节点 (对象), 代表性越强.
- coincideWithMaster 在聚类算法中使用, 需要用例子来跟踪才能明白其作用. 简单而言, 节点应与其父节点拥有同样的簇编号.
- clusterInTwo 将一个块分成两块, 其根节点依次是第一个与第二个 (注意到每个块都是按节点的代表性递减排序).
- vote 根据已经查询的标签, 对一个块中其它对象进行投票分类.
- clusterBasedActiveLearning(double, double, int) 为核心算法提供初始化服务.
- clusterBasedActiveLearning(int[]) 是核心算法, 它是递归的.各种情况的处理要小心.
- descendantDensities 按照密度将对象排序 (降序). 该数组第一个元素所指定的对象具有最大的密度.
- descendantRepresentatives 按照代表性将对象排序 (降序). 这样, 在为某一块挑选样本的时候, 只需要根据这个顺序从前向后选择即可.
/**
**********************************
* Compute distanceToMaster, the distance to its master.
**********************************
*/
public void computeDistanceToMaster() {
distanceToMaster = new double[dataset.numInstances()];
masters = new int[dataset.numInstances()];
descendantDensities = new int[dataset.numInstances()];
instanceStatusArray = new int[dataset.numInstances()];
descendantDensities = mergeSortToIndices(densities);
distanceToMaster[descendantDensities[0]] = maximalDistance;
double tempDistance;
for (int i = 1; i < dataset.numInstances(); i++) {
// Initialize.
distanceToMaster[descendantDensities[i]] = maximalDistance;
for (int j = 0; j <= i - 1; j++) {
tempDistance = distance(descendantDensities[i], descendantDensities[j]);
if (distanceToMaster[descendantDensities[i]] > tempDistance) {
distanceToMaster[descendantDensities[i]] = tempDistance;
masters[descendantDensities[i]] = descendantDensities[j];
} // Of if
} // Of for j
} // Of for i
System.out.println("First compute, masters = " + Arrays.toString(masters));
System.out.println("descendantDensities = " + Arrays.toString(descendantDensities));
}// Of computeDistanceToMaster
/**
**********************************
* Compute priority. Element with higher priority is more likely to be
* selected as a cluster center. Now it is rho * distanceToMaster. It can
* also be rho^alpha * distanceToMaster.
**********************************
*/
public void computePriority() {
priority = new double[dataset.numInstances()];
for (int i = 0; i < dataset.numInstances(); i++) {
priority[i] = densities[i] * distanceToMaster[i];
} // Of for i
}// Of computePriority
/**
*************************
* The block of a node should be same as its master. This recursive method
* is efficient.
*
* @param paraIndex
* The index of the given node.
* @return The cluster index of the current node.
*************************
*/
public int coincideWithMaster(int paraIndex) {
if (clusterIndices[paraIndex] == -1) {
int tempMaster = masters[paraIndex];
clusterIndices[paraIndex] = coincideWithMaster(tempMaster);
} // Of if
return clusterIndices[paraIndex];
}// Of coincideWithMaster
/**
*************************
* Cluster a block in two. According to the master tree.
*
* @param paraBlock
* The given block.
* @return The new blocks where the two most represent instances serve as
* the root.
*************************
*/
public int[][] clusterInTwo(int[] paraBlock) {
// Reinitialize. In fact, only instances in the given block is
// considered.
Arrays.fill(clusterIndices, -1);
// Initialize the cluster number of the two roots.
for (int i = 0; i < 2; i++) {
clusterIndices[paraBlock[i]] = i;
} // Of for i
for (int i = 0; i < paraBlock.length; i++) {
if (clusterIndices[paraBlock[i]] != -1) {
// Already have a cluster number.
continue;
} // Of if
clusterIndices[paraBlock[i]] = coincideWithMaster(masters[paraBlock[i]]);
} // Of for i
// The sub blocks.
int[][] resultBlocks = new int[2][];
int tempFistBlockCount = 0;
for (int i = 0; i < clusterIndices.length; i++) {
if (clusterIndices[i] == 0) {
tempFistBlockCount++;
} // Of if
} // Of for i
resultBlocks[0] = new int[tempFistBlockCount];
resultBlocks[1] = new int[paraBlock.length - tempFistBlockCount];
// Copy. You can design shorter code when the number of clusters is
// greater than 2.
int tempFirstIndex = 0;
int tempSecondIndex = 0;
for (int i = 0; i < paraBlock.length; i++) {
if (clusterIndices[paraBlock[i]] == 0) {
resultBlocks[0][tempFirstIndex] = paraBlock[i];
tempFirstIndex++;
} else {
resultBlocks[1][tempSecondIndex] = paraBlock[i];
tempSecondIndex++;
} // Of if
} // Of for i
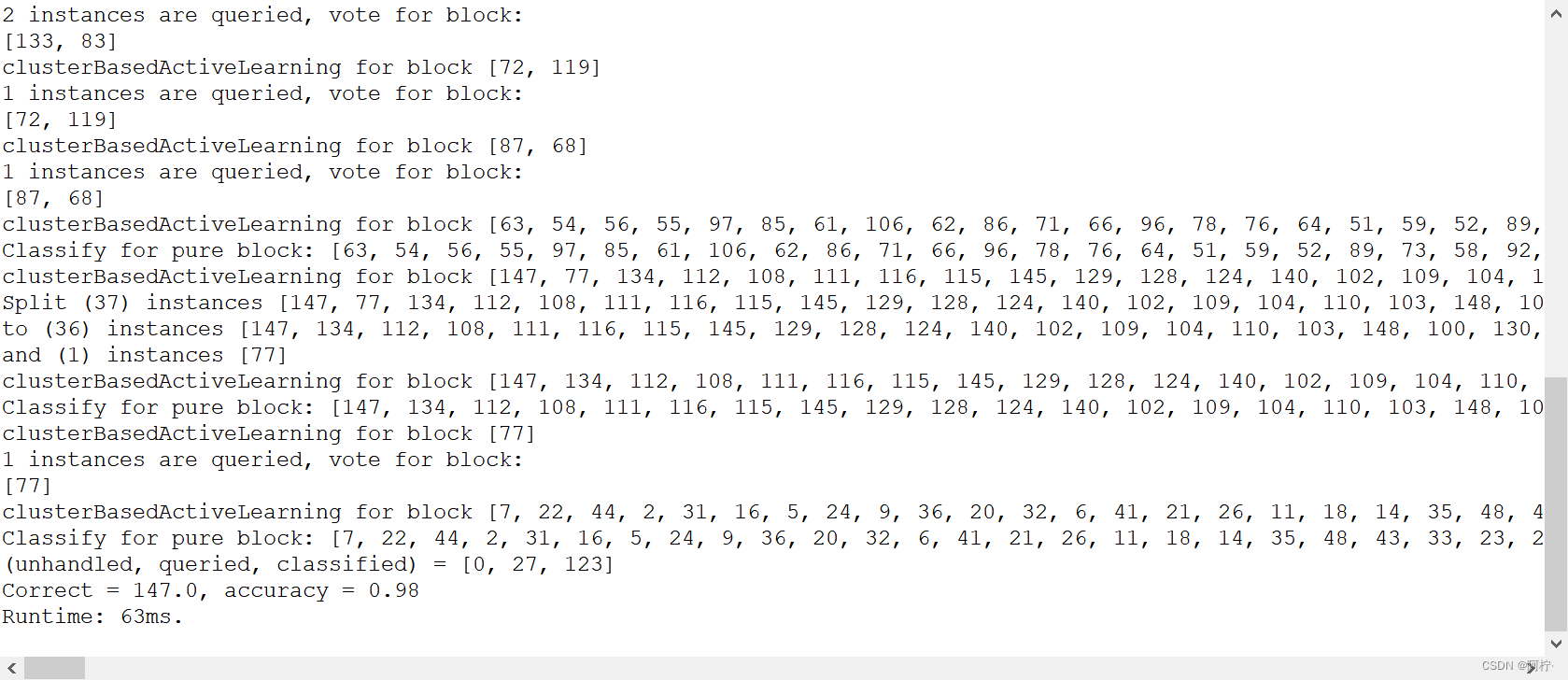
System.out.println("Split (" + paraBlock.length + ") instances " + Arrays.toString(paraBlock) + "\r\nto ("
+ resultBlocks[0].length + ") instances " + Arrays.toString(resultBlocks[0]) + "\r\nand ("
+ resultBlocks[1].length + ") instances " + Arrays.toString(resultBlocks[1]));
return resultBlocks;
}// Of clusterInTwo
/**
**********************************
* Classify instances in the block by simple voting.
*
* @param paraBlock
* The given block.
**********************************
*/
public void vote(int[] paraBlock) {
int[] tempClassCounts = new int[dataset.numClasses()];
for (int i = 0; i < paraBlock.length; i++) {
if (instanceStatusArray[paraBlock[i]] == 1) {
tempClassCounts[(int) dataset.instance(paraBlock[i]).classValue()]++;
} // Of if
} // Of for i
int tempMaxClass = -1;
int tempMaxCount = -1;
for (int i = 0; i < tempClassCounts.length; i++) {
if (tempMaxCount < tempClassCounts[i]) {
tempMaxClass = i;
tempMaxCount = tempClassCounts[i];
} // Of if
} // Of for i
// Classify unprocessed instances.
for (int i = 0; i < paraBlock.length; i++) {
if (instanceStatusArray[paraBlock[i]] == 0) {
predictedLabels[paraBlock[i]] = tempMaxClass;
instanceStatusArray[paraBlock[i]] = 2;
} // Of if
} // Of for i
}// Of vote
/**
**********************************
* Cluster based active learning. Prepare for
*
* @param paraRatio
* The ratio of the maximal distance as the dc.
* @param paraMaxNumQuery
* The maximal number of queries for the whole dataset.
* @parm paraSmallBlockThreshold The small block threshold.
**********************************
*/
public void clusterBasedActiveLearning(double paraRatio, int paraMaxNumQuery, int paraSmallBlockThreshold) {
radius = maximalDistance * paraRatio;
smallBlockThreshold = paraSmallBlockThreshold;
maxNumQuery = paraMaxNumQuery;
predictedLabels = new int[dataset.numInstances()];
for (int i = 0; i < dataset.numInstances(); i++) {
predictedLabels[i] = -1;
} // Of for i
computeDensitiesGaussian();
computeDistanceToMaster();
computePriority();
descendantRepresentatives = mergeSortToIndices(priority);
System.out.println("descendantRepresentatives = " + Arrays.toString(descendantRepresentatives));
numQuery = 0;
clusterBasedActiveLearning(descendantRepresentatives);
}// Of clusterBasedActiveLearning
/**
**********************************
* Cluster based active learning.
*
* @param paraBlock
* The given block. This block must be sorted according to the
* priority in descendant order.
**********************************
*/
public void clusterBasedActiveLearning(int[] paraBlock) {
System.out.println("clusterBasedActiveLearning for block " + Arrays.toString(paraBlock));
// Step 1. How many labels are queried for this block.
int tempExpectedQueries = (int) Math.sqrt(paraBlock.length);
int tempNumQuery = 0;
for (int i = 0; i < paraBlock.length; i++) {
if (instanceStatusArray[paraBlock[i]] == 1) {
tempNumQuery++;
} // Of if
} // Of for i
// Step 2. Vote for small blocks.
if ((tempNumQuery >= tempExpectedQueries) && (paraBlock.length <= smallBlockThreshold)) {
System.out.println(
"" + tempNumQuery + " instances are queried, vote for block: \r\n" + Arrays.toString(paraBlock));
vote(paraBlock);
return;
} // Of if
// Step 3. Query enough labels.
for (int i = 0; i < tempExpectedQueries; i++) {
if (numQuery >= maxNumQuery) {
System.out.println("No more queries are provided, numQuery = " + numQuery + ".");
vote(paraBlock);
return;
} // Of if
if (instanceStatusArray[paraBlock[i]] == 0) {
instanceStatusArray[paraBlock[i]] = 1;
predictedLabels[paraBlock[i]] = (int) dataset.instance(paraBlock[i]).classValue();
// System.out.println("Query #" + paraBlock[i] + ", numQuery = "
// + numQuery);
numQuery++;
} // Of if
} // Of for i
// Step 4. Pure?
int tempFirstLabel = predictedLabels[paraBlock[0]];
boolean tempPure = true;
for (int i = 1; i < tempExpectedQueries; i++) {
if (predictedLabels[paraBlock[i]] != tempFirstLabel) {
tempPure = false;
break;
} // Of if
} // Of for i
if (tempPure) {
System.out.println("Classify for pure block: " + Arrays.toString(paraBlock));
for (int i = tempExpectedQueries; i < paraBlock.length; i++) {
if (instanceStatusArray[paraBlock[i]] == 0) {
predictedLabels[paraBlock[i]] = tempFirstLabel;
instanceStatusArray[paraBlock[i]] = 2;
} // Of if
} // Of for i
return;
} // Of if
// Step 5. Split in two and process them independently.
int[][] tempBlocks = clusterInTwo(paraBlock);
for (int i = 0; i < 2; i++) {
// Attention: recursive invoking here.
clusterBasedActiveLearning(tempBlocks[i]);
} // Of for i
}// Of clusterBasedActiveLearning
/**
*******************
* Show the statistics information.
*******************
*/
@Override
public String toString() {
int[] tempStatusCounts = new int[3];
double tempCorrect = 0;
for (int i = 0; i < dataset.numInstances(); i++) {
tempStatusCounts[instanceStatusArray[i]]++;
if (predictedLabels[i] == (int) dataset.instance(i).classValue()) {
tempCorrect++;
} // Of if
} // Of for i
String resultString = "(unhandled, queried, classified) = " + Arrays.toString(tempStatusCounts);
resultString += "\r\nCorrect = " + tempCorrect + ", accuracy = " + (tempCorrect / dataset.numInstances());
return resultString;
}// Of toString
/**
**********************************
* The entrance of the program.
*
* @param args:
* Not used now.
**********************************
*/
public static void main(String[] args) {
long tempStart = System.currentTimeMillis();
System.out.println("Starting ALEC.");
String arffFilename = "D:/00/data/iris.arff";
// String arffFilename = "D:/data/mushroom.arff";
Alec tempAlec = new Alec(arffFilename);
// The settings for iris
tempAlec.clusterBasedActiveLearning(0.15, 30, 3);
// The settings for mushroom
// tempAlec.clusterBasedActiveLearning(0.1, 800, 3);
System.out.println(tempAlec);
long tempEnd = System.currentTimeMillis();
System.out.println("Runtime: " + (tempEnd - tempStart) + "ms.");
}// Of main

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)