
tensorflow基础
首先需要建立一个saver,然后在session中通过saver的save即可将模型保存起来。#之前是各种构建模型graph的操作(矩阵相乘,sigmoid等)saver = tf.train.Saver() #生成saversess.run(tf.global_variables_initializer()) #先对模型初始化#然后将数据丢入模型进行训练blablabla#训练完以后,使用sav
tensorflow基础
(一)编程模型
TensorFlow的命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算。TensorFlow是张量从图像的一端流动到另一端的计算过程,这也是TensorFlow的编程模型。
(1)编程模型中的运行机制
TensorFlow的运行机制属于“定义”与“运行”相分离。从操作层面可以抽象成两种:模型构建和模型运行。
模型构建中的概念
表中定义的内容都是在一个叫做“图”的容器中完成的。关于“图”,有以下几点需要理解
● 一个“图”代表一个计算任务。
● 在模型运行的环节中,“图”会在会话(session)里被启动。
● session将图的OP分发到如CPU或GPU之类的设备上,同时提供执行OP的方法。这些方法执行后,将产生的tensor返回。在Python语言中,返回的tensor是numpy ndarray对象;在C和C++语言中,返回的tensor是TensorFlow::Tensor实例。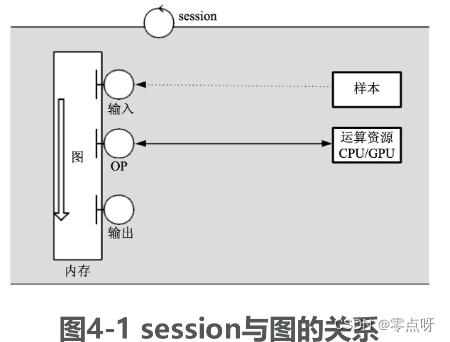
(2)编写hello world程序
import tensorflow as tf
#1.定义一个常量
hello=tf.constant("hello")
# 2.定义session
sess=tf.Session()
# 3.使用sess进行运行
print(sess.run(hello))
sess.close()
"""
使用with 进行改进
"""
with tf.Session() as sess:
print(sess.run(hello))
(3)使用注入机制进行代码编写
使用注入机制,将具体的实参注入到相应的placeholder中。feed只在调用它的方法内有效,方法结束后feed就会消失。
a=tf.placeholder(tf.float32)
b=tf.placeholder(tf.float32)
z=tf.multiply(a,b)
with tf.Session() as sess:
print(sess.run(z,feed_dict={a:3,b:5}))
使用tf.placeholder为这些操作创建占位符,然后使用feed_dict把具体的值放到占位符里。
(4)保存和载入模型的方法介绍
(4.1)保存模型
首先需要建立一个saver,然后在session中通过saver的save即可将模型保存起来。代码如下:
#之前是各种构建模型graph的操作(矩阵相乘,sigmoid等)
saver = tf.train.Saver() #生成saver
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #先对模型初始化
#然后将数据丢入模型进行训练blablabla
#训练完以后,使用saver.save来保存
saver.save(sess, "save_path/file_name")
#file_name如果不存在,会自动创建
(4.2)载入模型
将模型保存好以后,载入也比较方便。在session中通过调用saver的restore()函数,会从指定的路径找到模型文件,并覆盖到相关参数中。代码如下:
saver = tf.train.Saver()
with tf.Session() as sess:
#参数可以进行初始化,也可不进行初始化。即使初始化了,初始化的值也会被restore的
值给覆盖
sess.run(tf.global_variables_initializer())
saver.restore(sess, "save_path/file_name")
#会将已经保存的变量值resotre到变量中。
(5)检查点(Checkpoint)
保存模型并不限于在训练之后,在训练之中也需要保存,因为TensorFlow训练模型时难免会出现中断的情况。我们自然希望能够将辛苦得到的中间参数保留下来,否则下次又要重新开始。这种在训练中保存模型,习惯上称之为保存检查点。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
#定义生成loss可视化的函数
plotdata = { "batchsize":[], "loss":[] }
def moving_average(a, w=10):
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in
enumerate(a)]
#生成模拟数据
train_X = np.linspace(-1, 1, 100)
train_Y = 2*train_X + np.random.randn(*train_X.shape)*0.3
# y=2x,但是加入了噪声
#图形显示
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.legend()
plt.show()
tf.reset_default_graph()
# 创建模型
# 占位符
X = tf.placeholder("float")
Y = tf.placeholder("float")
# 模型参数
W = tf.Variable(tf.random_normal([1]), name="weight")
b = tf.Variable(tf.zeros([1]), name="bias")
# 前向结构
z = tf.multiply(X, W)+ b
#反向优化
cost =tf.reduce_mean( tf.square(Y - z))
learning_rate = 0.01
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) #梯度下降
# 初始化所有变量
init = tf.global_variables_initializer()
# 定义学习参数
training_epochs = 20
display_step = 2
"""
tf.train.Saver(max_to_keep=1)代码创建saver时传入的参数max_to_keep=1代表:
在迭代过程中只保存一个文件。这样,在循环训练过程中,新生成的模型就会覆盖以前的模型。
"""
saver = tf.train.Saver(max_to_keep=1) # 生成saver
savedir = "log/"
# 启动图
with tf.Session() as sess:
sess.run(init)
# 向模型中输入数据
for epoch in range(training_epochs):
for (x, y) in zip(train_X, train_Y):
sess.run(optimizer, feed_dict={X: x, Y: y})
#显示训练中的详细信息
if epoch % display_step == 0:
loss = sess.run(cost, feed_dict={X: train_X, Y:train_Y})
print ("Epoch:", epoch+1, "cost=", loss, "W=", sess.run(W), "b=",sess.run(b))
if not (loss == "NA" ):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
saver.save(sess, savedir+"linermodel.cpkt", global_step=epoch)
print (" Finished! ")
print ("cost=", sess.run(cost, feed_dict={X: train_X, Y: train_Y}),
"W=", sess.run(W), "b=", sess.run(b))
#显示模型
plt.plot(train_X, train_Y, 'ro', label='Original data')
plt.plot(train_X, sess.run(W)* train_X + sess.run(b), label='Fitted Wline')
plt.legend()
plt.show()
plotdata["avgloss"] = moving_average(plotdata["loss"])
plt.figure(1)
plt.subplot(211)
plt.plot(plotdata["batchsize"], plotdata["avgloss"], 'b--')
plt.xlabel('Minibatch number')
plt.ylabel('Loss')
plt.title('Minibatch run vs. Training loss')
plt.show()
#重启一个session ,载入检查点
load_epoch=18
with tf.Session() as sess2:
sess2.run(tf.global_variables_initializer())
saver.restore(sess2, savedir+"linermodel.cpkt-" + str(load_epoch))
print ("x=0.2, z=", sess2.run(z, feed_dict={X: 0.2}))
使用MonitoredTrainingSession函数来自动管理检查点文件
import tensorflow as tf
tf.reset_default_graph()
global_step = tf train.get_or_create_global_step()
step = tf.assign_add(global_step, 1)
#设置检查点路径为log/checkpoints
with tf.train.MonitoredTrainingSession(checkpoint_dir='log/checkpoints',
save_checkpoint_secs = 2) as sess:
print(sess.run([global_step]))
while not sess.should_stop(): #启用死循环,当sess不结束时就不停止
i = sess.run( step)
print( i)
注意:(1)如果不设置save_checkpoint_secs参数,默认的保存时间间隔为10分钟。这种按照时间保存的模式更适用于使用大型数据集来训练复杂模型的情况。(2)使用该方法时,必须要定义global_step变量,否则会报错误。
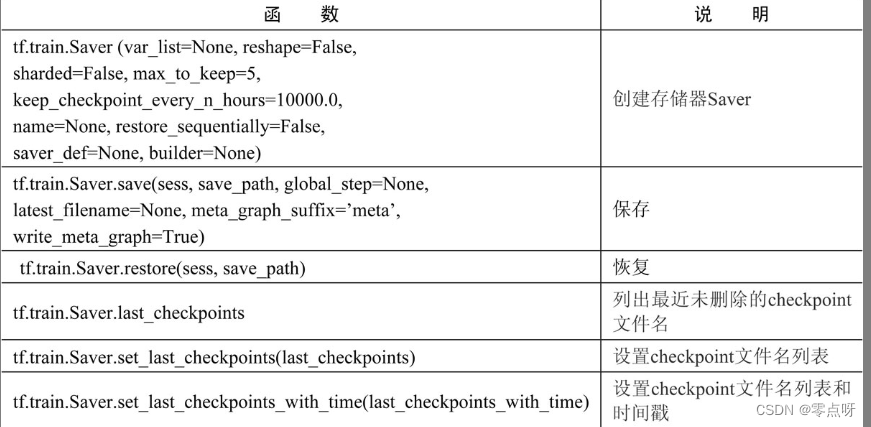
(6)模型操作常用函数总结
(二)基础类型定义及操作函数
(1)张量及操作
(1.1)张量介绍
TensorFlow程序使用tensor数据结构来代表所有的数据。计算图中,操作间传递的数据都是Tensor。可以把tensor看为一个n维的数组或列表,每个tensor中包含了类型(type)、阶(rank)和形状(shape)。
(1)类型
tensor类型与python中的类型区别如下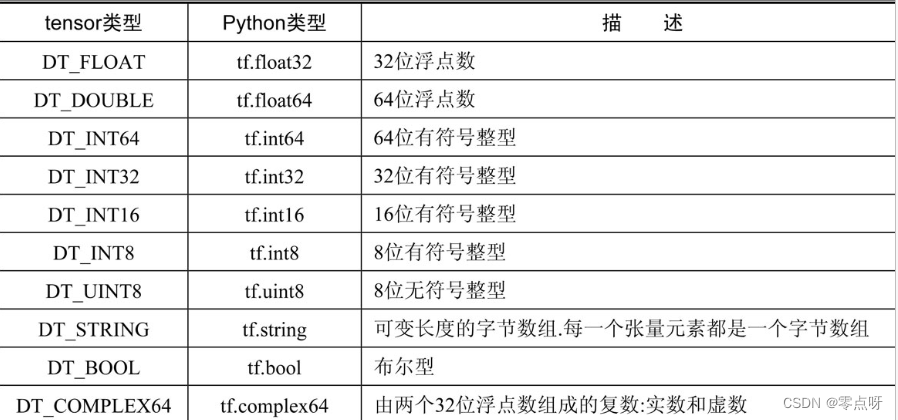
(2)rank(阶)
rank(阶)指的就是维度。但张量的阶和矩阵的阶并不是同一个概念,主要是看有几层中括号。例如,对于一个传统意义上的3阶矩阵a=[[1,2,3],[4,5,6], [7,8,9]]来讲,在张量中的阶数表示为2阶(因为它有两层中括号)。
下图为标量、向量、矩阵的阶数。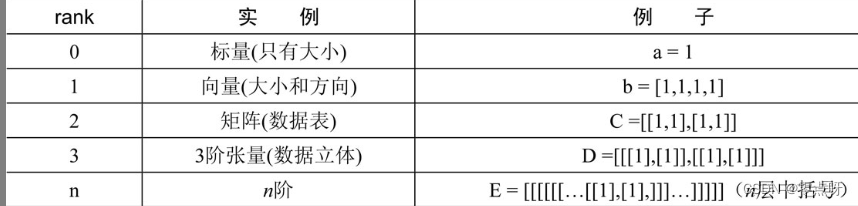
(3)shape(形状)
shape(形状)用于描述张量内部的组织关系。“形状”可以通过Python中的整数列表或元组(int list或tuples)来表示,也可以用TensorFlow中的相关形状函数来表示。
举例: 一个二阶张量a = [[1, 2, 3], [4, 5, 6]]形状是两行三列,描述为(2,3)。
(1.2)张量相关操作
张量的相关操作包括类型转换、数值操作、形状变化、数据操作
(1)类型转换
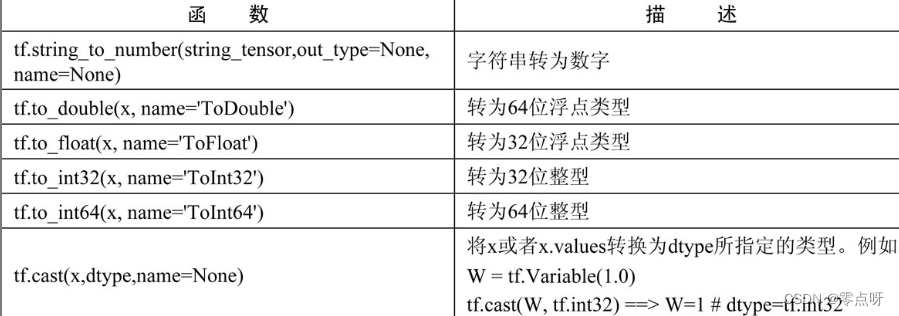
(2)数值操作
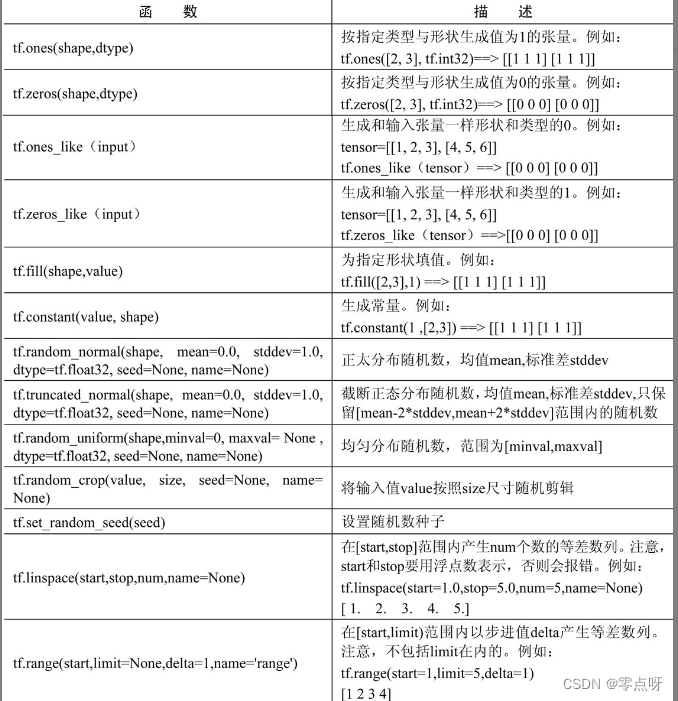
(3) 形状变换

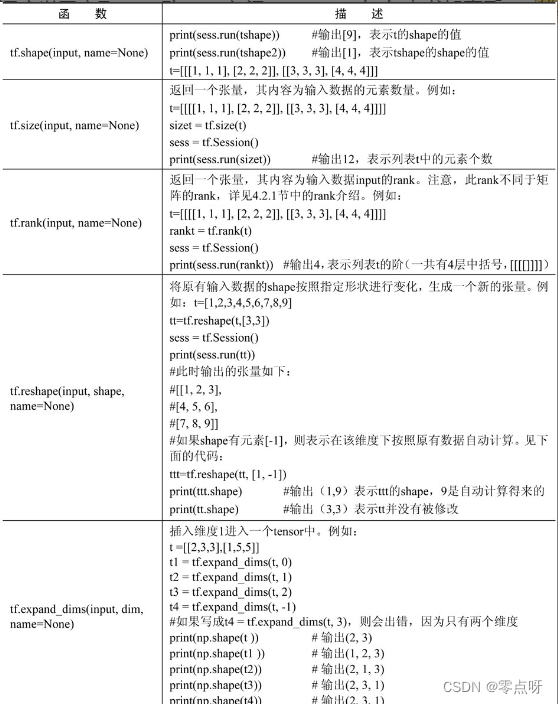

(4)数据操作
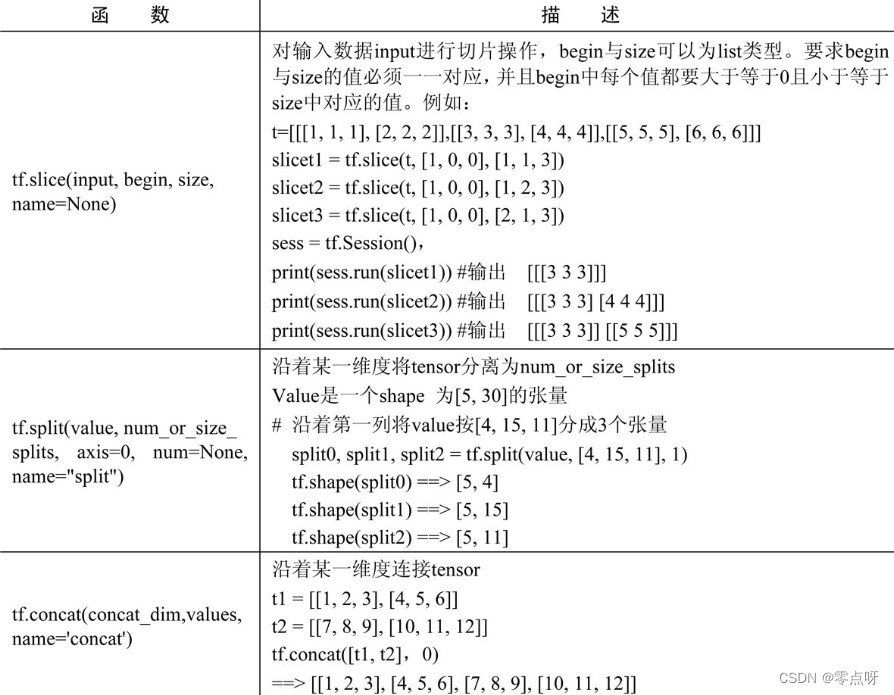
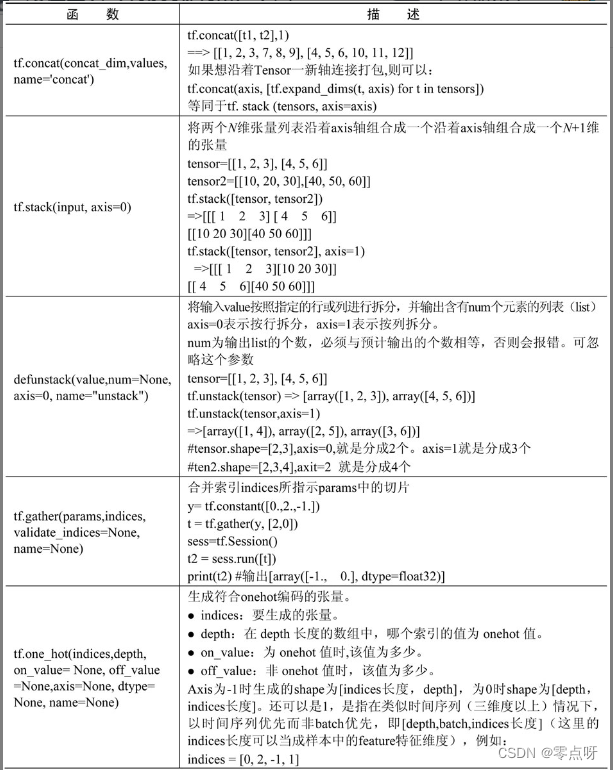

(2)算术运算函数

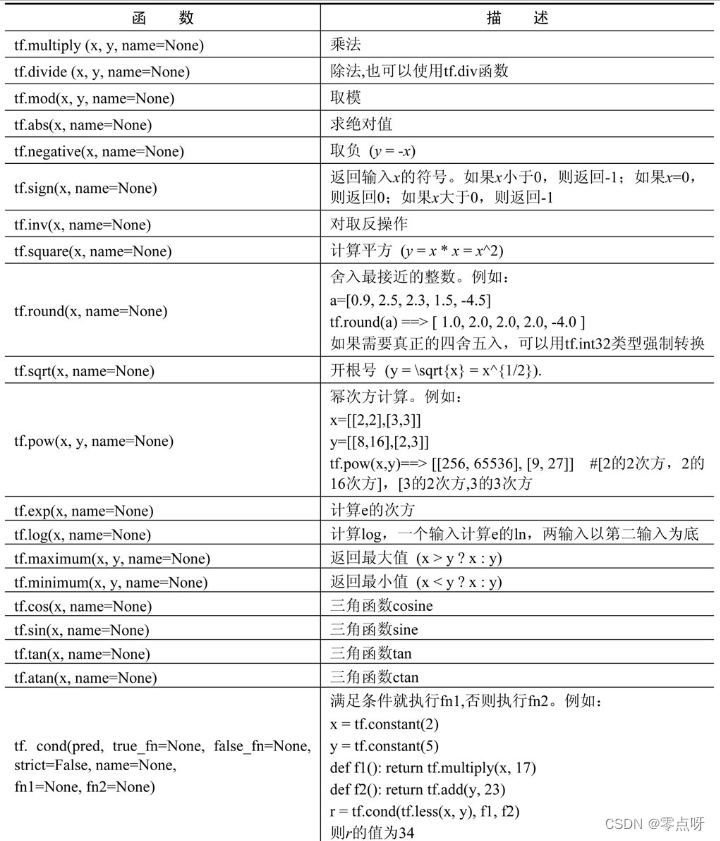
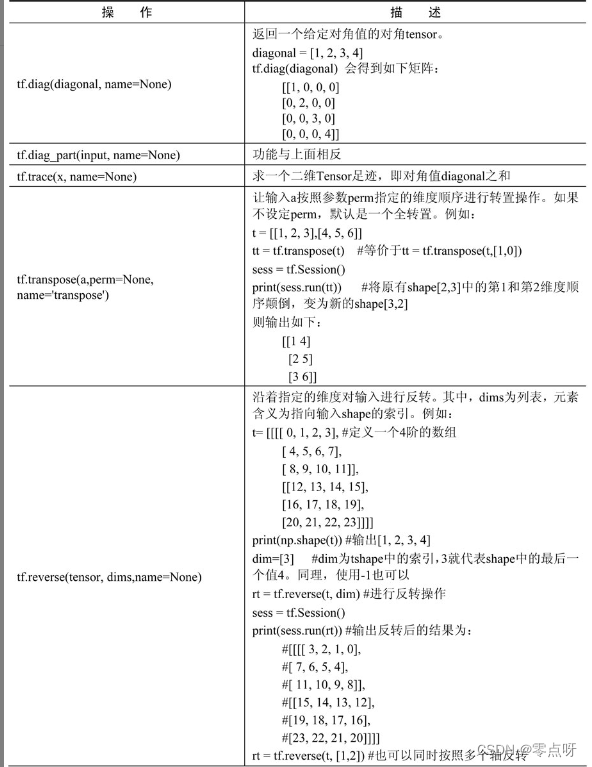
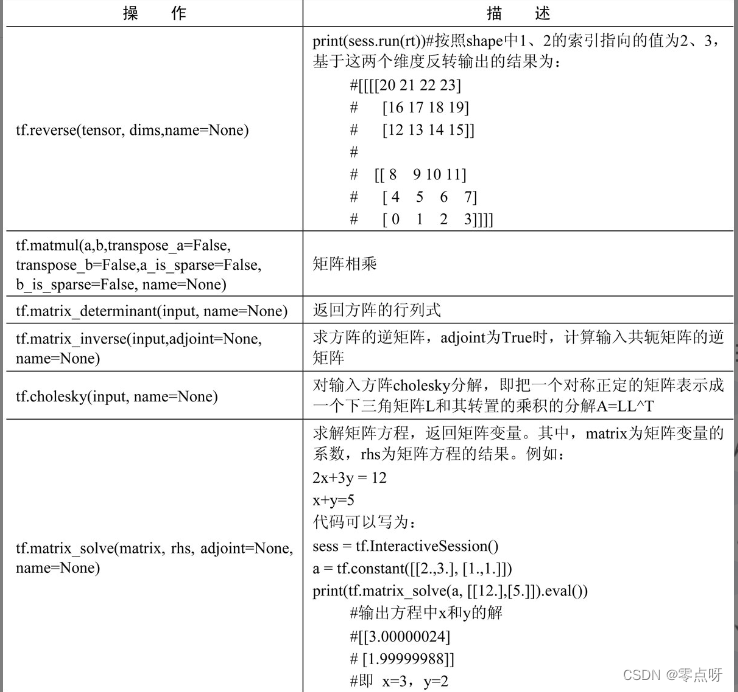
(3) 矩阵相关的运算
(4) 复数操作函数
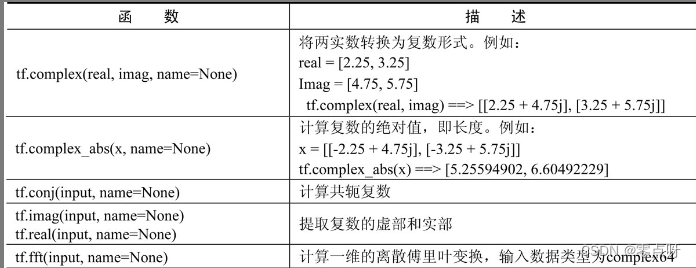
(5) 规约计算
规约计算的操作都会有降维的功能,在所有reduce_xxx系列操作函数中,都是以xxx的手段降维,每个函数都有axis这个参数,即沿某个方向,使用xxx方法对输入的Tensor进行降维。
提示:axis的默认值是None,即把input_tensor降到0维,即一个数。
对于二维input_tensor而言:axis=0,则按列计算;axis=1,则按行计算。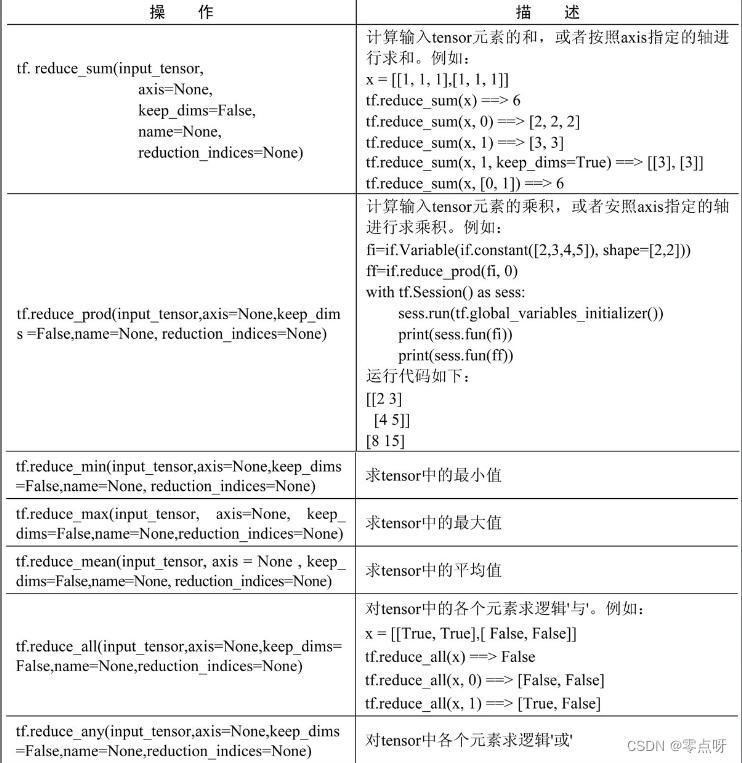
(6) 分割
分割操作是TensorFlow不常用的操作,在复杂的网络模型里偶尔才会用到。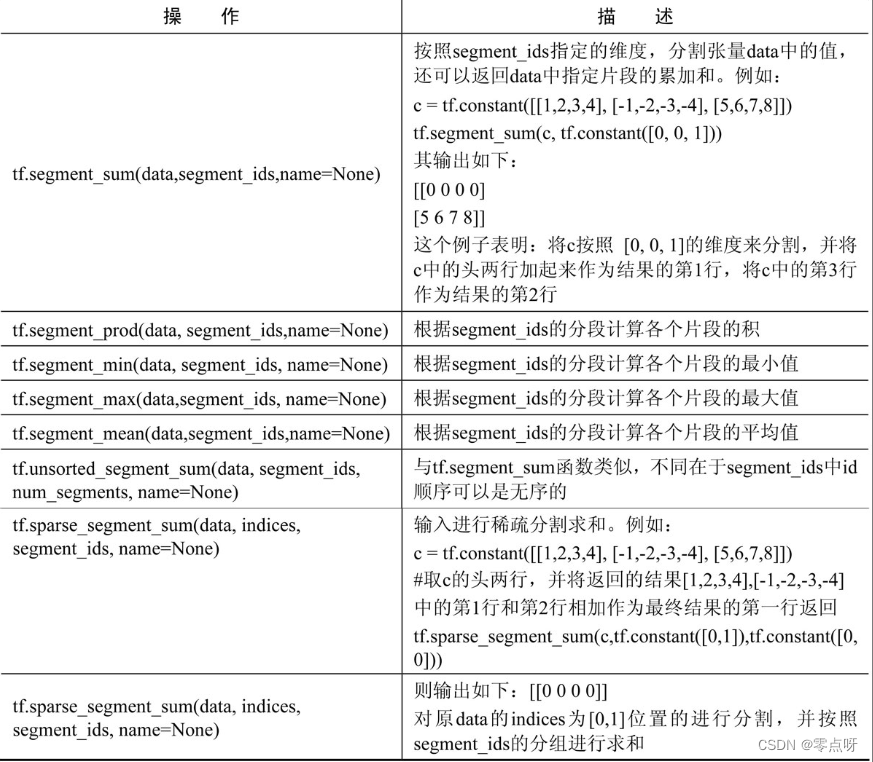
(7) 序列比较与索引提取

(8) 错误类
作为一个完整的框架,有它自己的错误处理。TensorFlow中的错误类如表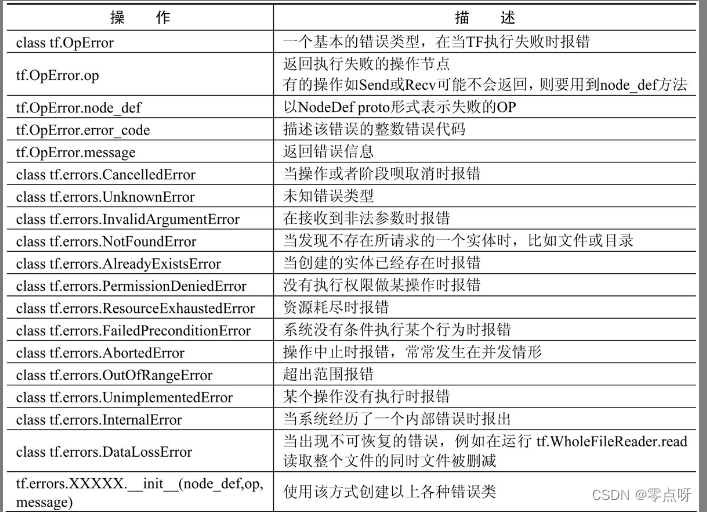

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)