
毕业设计:python网络热点监测与舆情分析系统+情感分析+LDA主题分析 可视化+Flask框架✅
毕业设计:python网络热点监测与舆情分析系统+情感分析+LDA主题分析 可视化+Flask框架✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌感兴趣的可以先收藏起来,点赞、关注不迷路✌
毕业设计:2023-2024年计算机毕业设计1000套(建议收藏)
毕业设计:2023-2024年最新最全计算机专业毕业设计选题汇总
1、项目介绍
技术栈:
Flask框架、requests爬虫、Echarts可视化、SnowNLP情感分析、NLP情感分析算法、影响分析、舆情分析、LDA主题分析
网络热点监测与舆情分析系统
2、项目界面
(1)网络热点新闻主题词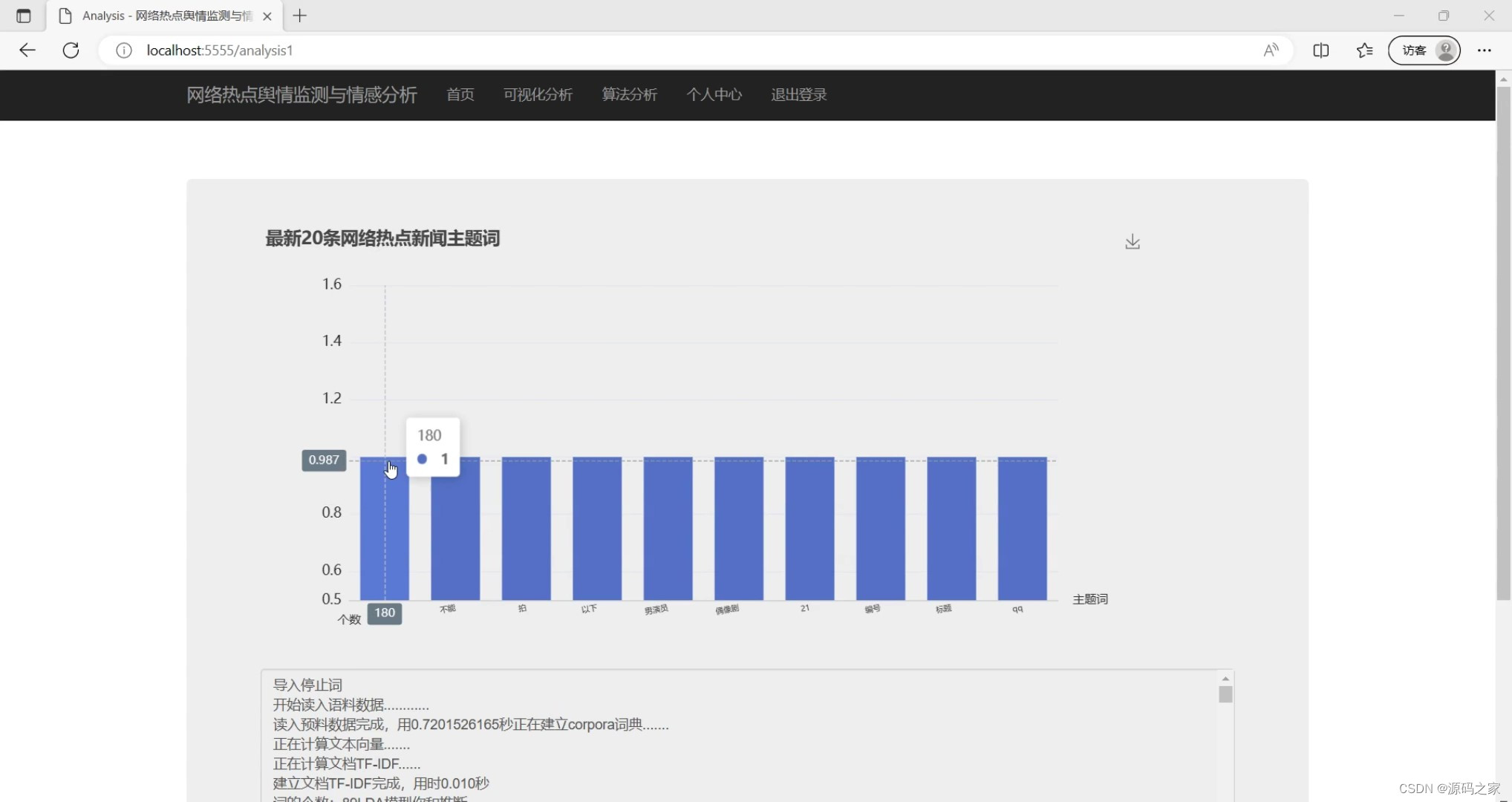
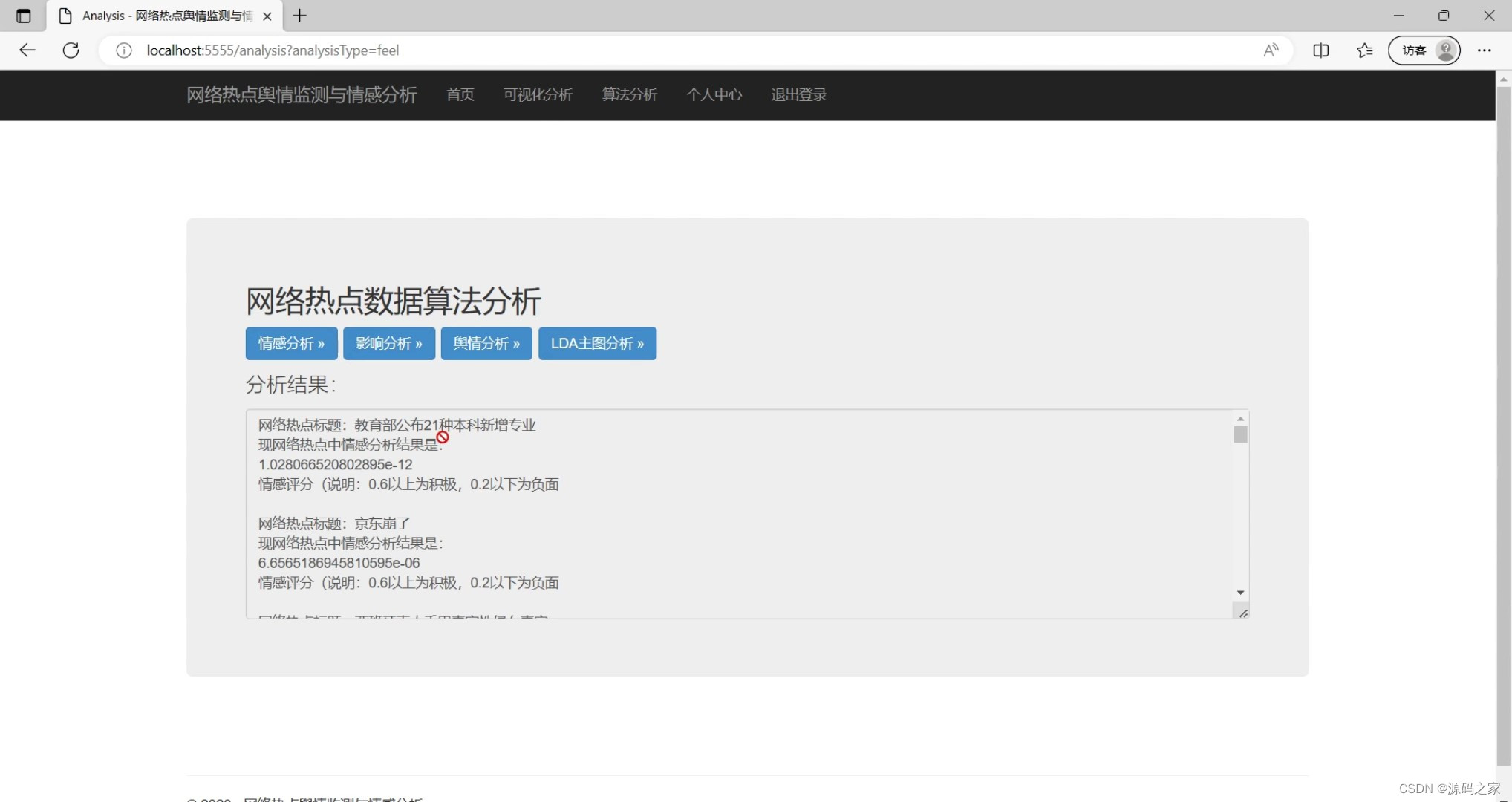
(2)网络热点情感分析
(3)热度分析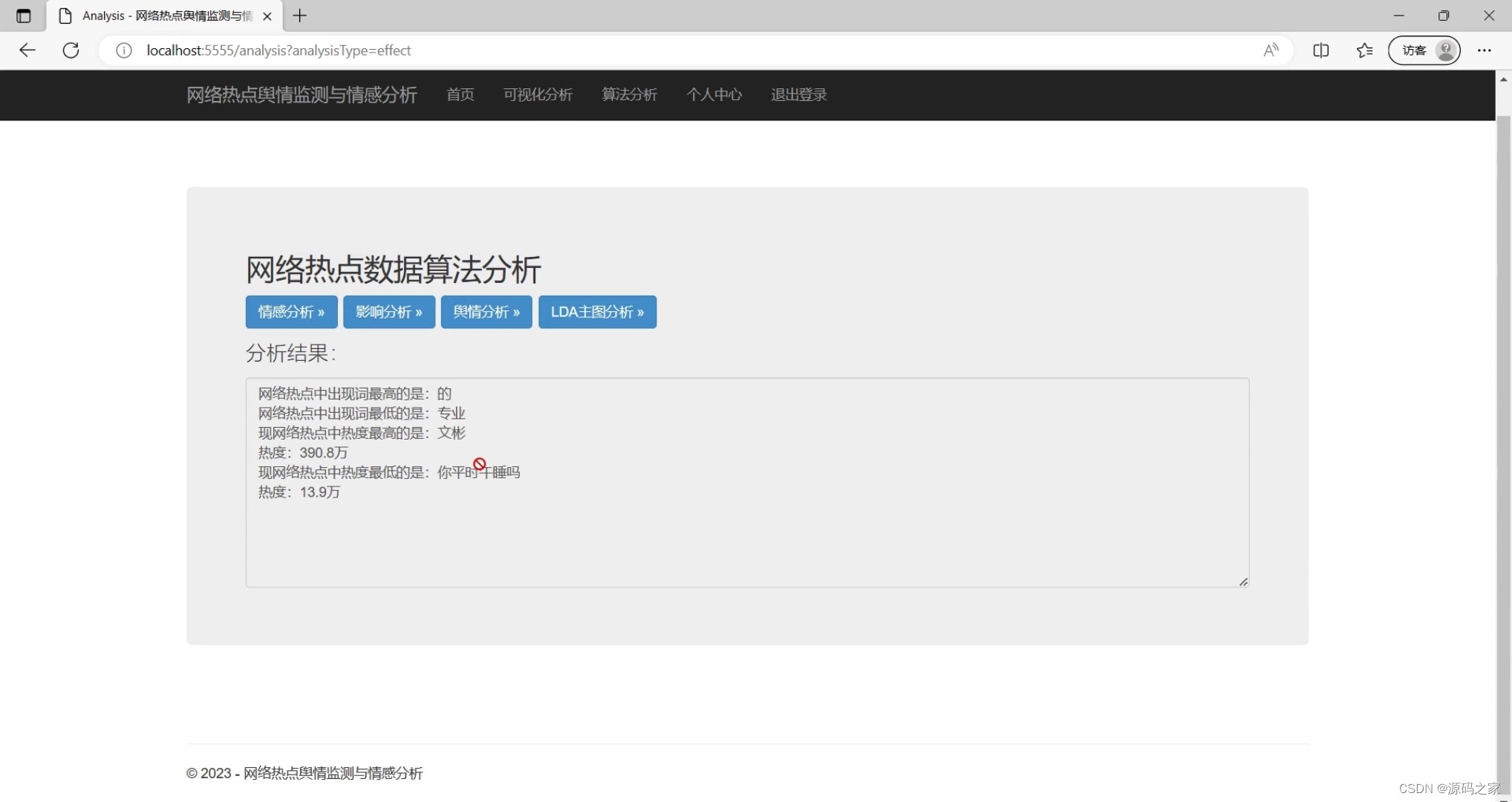
(4)舆情分析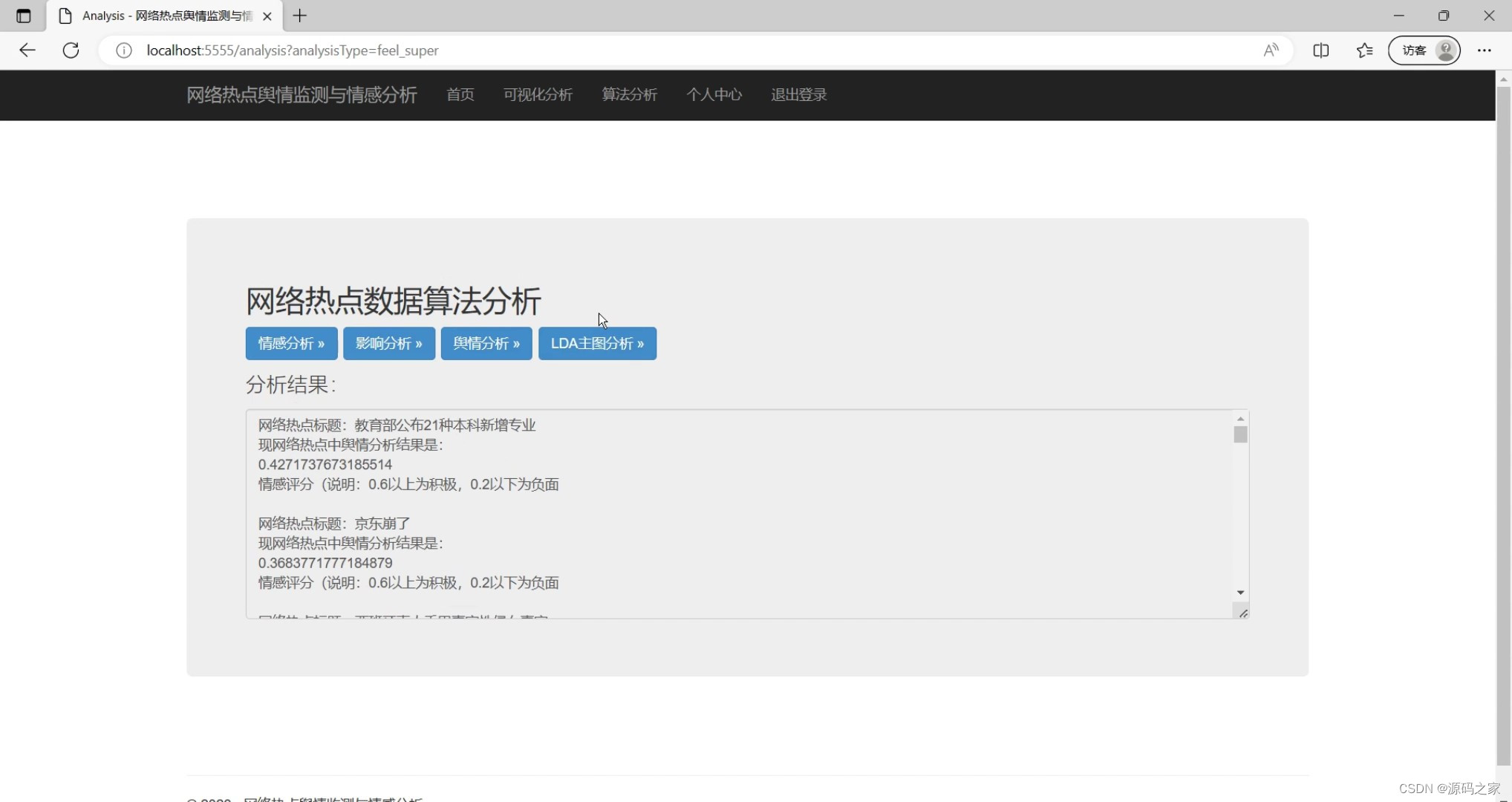
(5)TF-IDF分析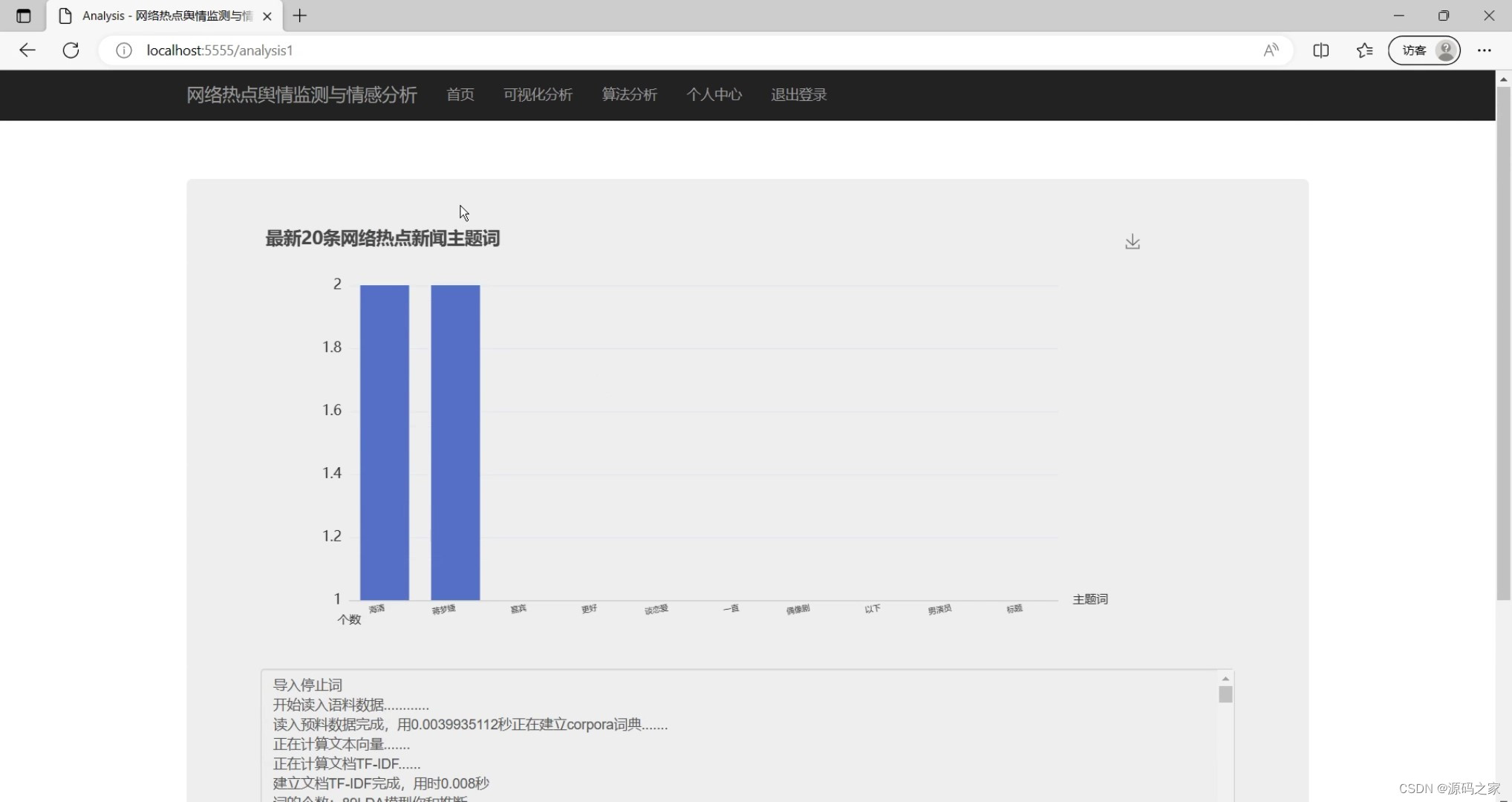
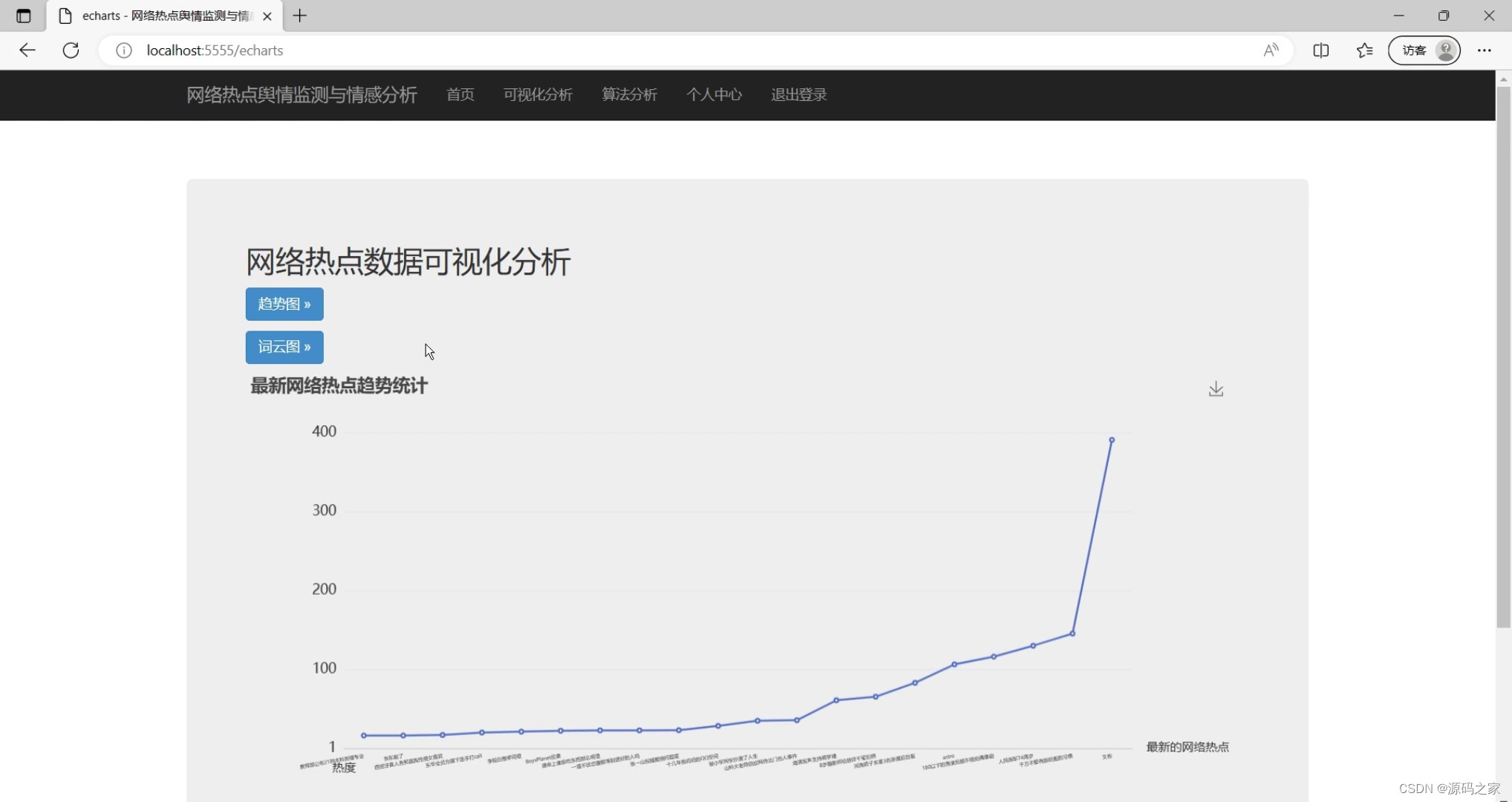
(6)网络热点趋势图
(7)网络热点词云图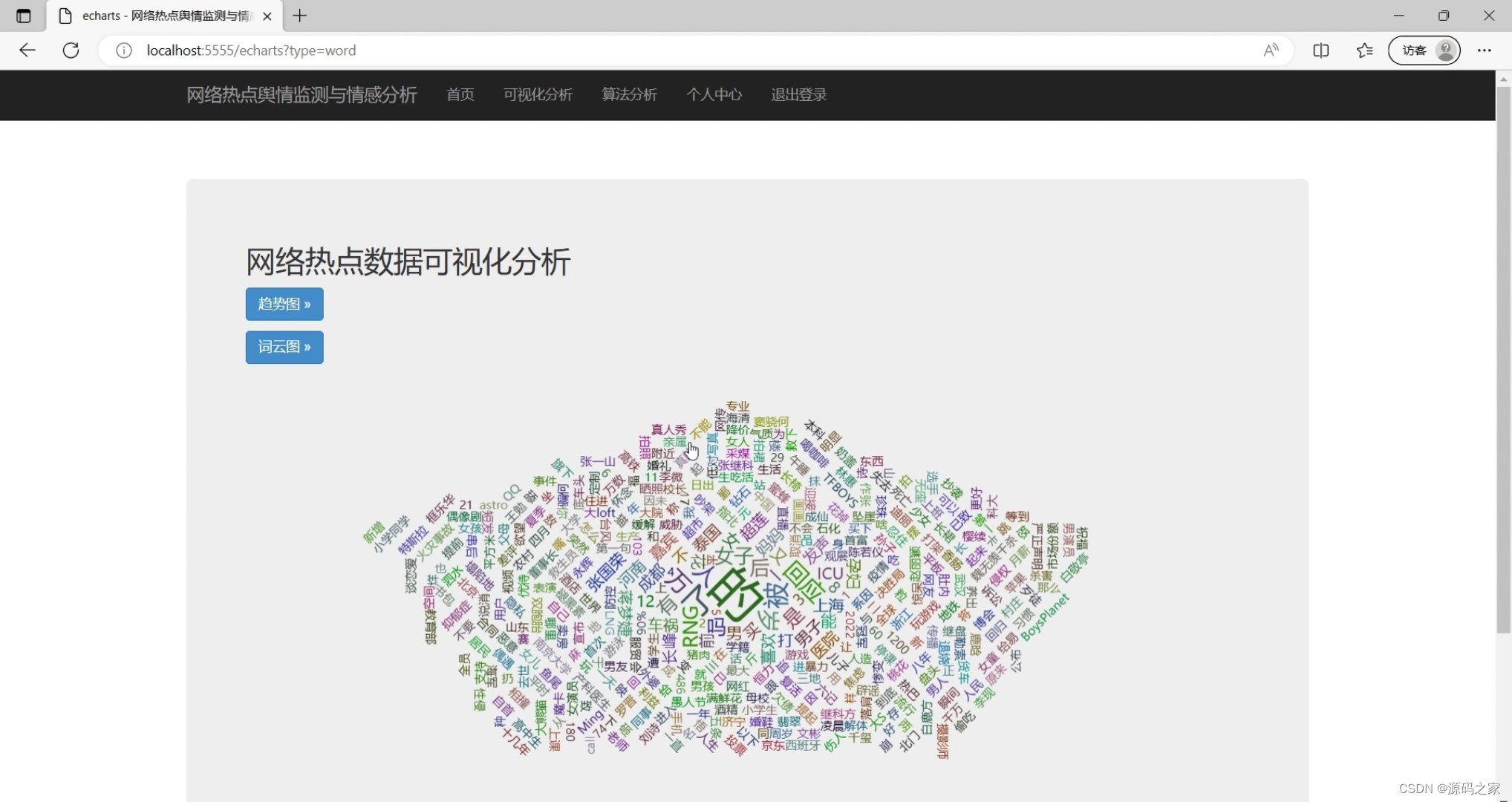
(8)热量热点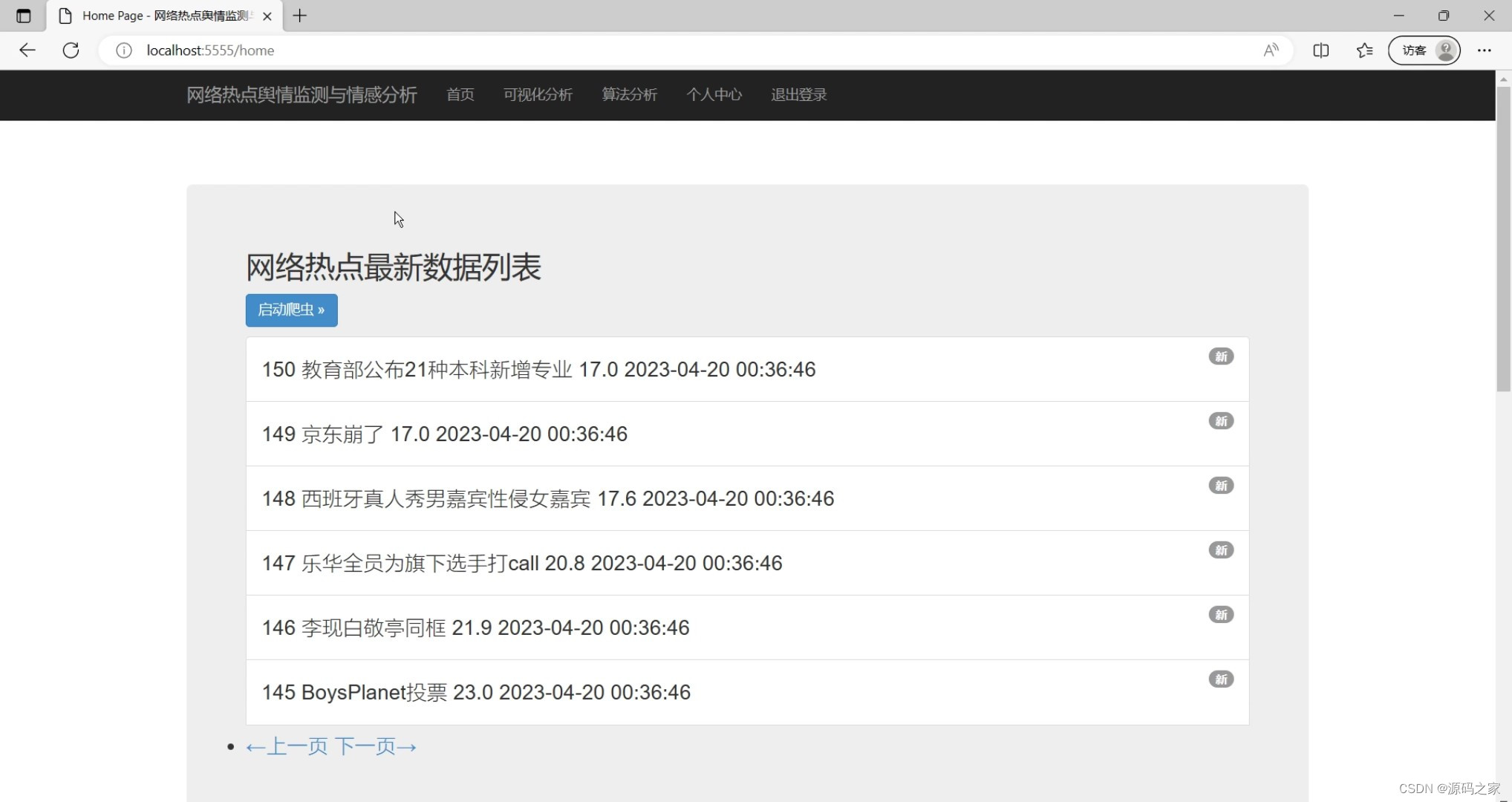
3、项目说明
网络热点监测与舆情分析系统是基于Flask框架开发的一种应用程序,主要用于实时监测和分析网络上的热点话题及对应的舆情情感。系统利用requests爬虫技术收集网络上的相关资讯,通过SnowNLP情感分析算法对文章进行情感分析,并使用Echarts可视化工具将分析结果以图表形式展示。
系统的主要功能包括:
-
热点话题监测:通过爬取网络上各大社交媒体、新闻网站等的热点话题,实时更新系统中的热点话题列表。
-
舆情情感分析:对于每个热点话题下的文章进行情感分析,判断文章的情感倾向,如正面、负面或中性。系统使用SnowNLP情感分析算法对中文文本进行情感分析。
-
影响分析:根据文章的情感倾向和传播范围等指标,对热点话题的影响力进行分析和评估。
-
舆情可视化:利用Echarts可视化工具,将热点话题的舆情分析结果以图表形式展示,便于用户了解舆情趋势和情感分布。
-
LDA主题分析:对热点话题下的文章进行主题分析,识别出文章中的主要话题,并将分析结果呈现给用户。
通过网络热点监测与舆情分析系统,用户可以及时了解网络上的热点话题及其舆情情感,帮助用户把握舆论动态,进行舆情监测和分析。此外,系统还可用于舆情预警、舆情管理等方面的应用。
4、核心代码
from datetime import datetime
from flask import render_template,redirect,url_for,request, make_response,Response,session
from AnalysisSystems import app
from AnalysisSystems.commond.Spiders import Spiders
from AnalysisSystems.commond.Services import Services
from AnalysisSystems.commond.SnowNLPQingGangFenXi import SnowNLPQingGangFenXi
from AnalysisSystems.commond.LDAModule import LDAModule
import decimal
services = Services()
spiders = Spiders()
snowNLPQingGangFenXi = SnowNLPQingGangFenXi()
#可视化板块
#获取最新20个数据,统计并在页面上显示
new_title = []
new_title_level = []
level = 1
new_title_hot = []
#调用Model获取最新的20个数据
fist20 = services.select_sql_fist20()
#代迭20个数据,并把它分别以split函数处理完添加到相应的集合中 new_title = [], new_title_level = [],new_title_hot = []
for x in fist20:
new_title.append(x.split(" ")[1]);
new_title_level.append(level);
new_title_hot.append(x.split(" ")[2]);
level = level+1
#所有事情处理完以后把结果信息返回给index.html界面中
return render_template(
'index.html',
title='Home Page',
year=datetime.now().year,
datas = data,
pre = pre_page,
next = next_page,
new_title = new_title,
new_title_level = new_title_level,
new_title_hot = new_title_hot
)
#爬虫
@app.route('/StartSpiders')
def StartSpiders():
#session 检测之前login存储用户登录信息
if (session['logged_in'] == None):
return redirect("/login")
#启动爬虫
spiders.start_spiders()
response = Response()
return response
#可视化分析页面
@app.route('/echarts')
def echarts():
"""Renders the contact page."""
#session 检测之前login存储用户登录信息
if (session['logged_in'] == None):
return redirect("/login")
#通过前端获取的类型画出不同的图形
parm = request.args.get("type");
#前端用于区分画出那个图形
echartType = ""
#如果是折线图
if parm == None or parm == "":
echartType = "line"
#获取最新20个数据,统计并在页面上显示
#新闻标题
new_title = []
new_title_level = []
level = 1
#新闻网络热点
new_title_hot = []
#将用户请求转发给相应的Model,从数据库中获取前20个数据
fist20 = services.select_sql_fist20()
#代迭20个数据,并把它分别以split函数处理完添加到相应的集合中 new_title = [], new_title_level = [],new_title_hot = []
for x in fist20:
new_title.append(x.split(" ")[1]);
new_title_level.append(level);
new_title_hot.append(x.split(" ")[2]);
level = level+1
#最后返回数据给前端
return render_template(
'echarts.html',
title = 'echarts',
year = datetime.now().year,
type = echartType,
new_title = new_title,
new_title_hot = new_title_hot
)
#如果是云图
else:
echartType = "word"
#将用户请求转发给相应的Model,从数据库中获取所有数据统计并在页面上显示云词
new_title_all = ""
all = services.select_sql_all()
for x in all:
#把所有人网络热点词,标题等组合到一个字符串变量中,最后通过分词算法
new_title_all += x.split(" ")[1];
#调用SnowNLPQingGangFenXi类中的stringToWordcloud获取云词数据
snowNLPQingGangFenXi = SnowNLPQingGangFenXi()
data = snowNLPQingGangFenXi.stringToWordcloud(new_title_all,"")
#最后返回数据给前端
return render_template(
'echarts.html',
title = 'echarts',
year = datetime.now().year,
type = echartType,
data = data)
#分析管理页面
@app.route('/analysis')
def analysis():
"""Renders the about page."""
#session 检测之前login存储用户登录信息
if (session['logged_in'] == None):
return redirect("/login")
#通过前端发送的数据,获取的类型然后分析步同的结果
analysis_type = request.args.get("analysisType")
#分析的结果
messages = "";
#获取所有数据
new_title_all = ""
#最小最大热度,最小的热度不能是0 所以需要默认定义一个值
new_min_hot = 50
new_max_hot = 0
#将用户请求转发给相应的Model,从数据库中获取所有网络热点信息
all = services.select_sql_all_row()
for x in all:
#把所有人网络热点词,标题等组合到一个字符串变量中,最后通过分词算法
new_title_all += x[1];
temp = float(str(decimal.Decimal(x[2]).quantize(decimal.Decimal('0.00'))))
#这里是查询最大和最小网络热点度
if new_min_hot > temp:
new_min_hot = temp
if new_max_hot < temp:
new_max_hot = temp
#情感分析
if analysis_type == 'feel':
#将用户请求转发给相应的Model,从数据库中获取前20个数据
all = services.select_sql_fist20()
for x in all:
new_title_all = x.split(" ")[1]
#拼接分析的结果到messages
messages += "网络热点标题:"+new_title_all+"\r\n"
messages += "现网络热点中情感分析结果是:\r\n"
messages += str(snowNLPQingGangFenXi.feel(new_title_all))
messages += "\r\n"
messages += "情感评分(说明:0.6以上为积极,0.2以下为负面\r\n\r\n"
#舆情分析
elif analysis_type == 'feel_super':
#将用户请求转发给相应的Model,从数据库中获取前20个数据
all = services.select_sql_fist20()
for x in all:
new_title_all = x.split(" ")[1]
#拼接分析的结果到messages
messages += "网络热点标题:"+new_title_all+"\r\n"
messages += "现网络热点中舆情分析结果是:\r\n"
messages += str(snowNLPQingGangFenXi.feel_super(new_title_all))
messages += "\r\n"
messages += "情感评分(说明:0.6以上为积极,0.2以下为负面\r\n\r\n"
#影响分析
elif analysis_type == 'effect':
#拼接分析的结果到messages
messages = snowNLPQingGangFenXi.effect(new_title_all)
messages += "现网络热点中热度最高的是:" + services.select_sql_max_hot(new_max_hot)[0][1]+ "\r\n"
messages += "热度:"+ str(new_max_hot)+ "万\r\n"
messages += "现网络热点中热度最低的是:" + services.select_sql_min_hot(new_min_hot)[0][1]+"\r\n"
messages += "热度:"+ str(new_min_hot)+ "万\r\n"
#当处理完不同分支语句以后返回结果信息到界面显示
return render_template(
'analysis.html',
title='Analysis',
year=datetime.now().year,
messages=messages)
#分析主题前20个新闻标题分析页面
@app.route('/analysis1')
def analysis1():
"""Renders the about page."""
#session 检测之前login存储用户登录信息
if (session['logged_in'] == None):
return redirect("/login")
#分析的结果
messages = "";
#获取最新的20个所有数据
lists = []
#最小最大热度,最小的热度不能是0 所以需要默认定义一个值
#将用户请求转发给相应的Model,从数据库中获取所有网络热点信息
all = services.select_sql_fist20()
for x in all:
lists.append(x.split(" ")[1])
ldaModule = LDAModule()
ldaModule.load_data(lists)
contents,dicts = ldaModule.start_data()
types_title = ""
x = []
y = []
types_title="LDA主题模型分析报告"
types_title="LDA主题词的个数分析"
i = 0
for item in dicts:
if i == 10:
break
if item[0] == ',' or item[0] == '.' or item[0] == ',' or item[0] == '。':
continue
x.append(item[0])
y.append(item[1])
i = i +1
#当处理完不同分支语句以后返回结果信息到界面显示
return render_template(
'analysis1.html',
title='Analysis',
year=datetime.now().year,
contents = contents,
x = x,
y = y,
messages=messages)
#密码重置管理页面
@app.route('/pwdchange',methods=['GET', 'POST'])
def pwdchange():
"""Renders the about page."""
#session 检测之前login存储用户登录信息
if (session['logged_in'] == None):
return redirect("/login")
#获取http提交方式
if request.method == 'GET':
#直接返回视图的界面
return render_template(
'pwdchange.html',
)
else:
newpwd = request.form.get('newpwd')
confirmpwd = request.form.get('confirmpwd')
services.changepwd_sql_login(newpwd,confirmpwd)
#当处理完不同分支语句以后返回结果信息到界面显示
session['logged_in'] = None
return redirect("/login")
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 33
33 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)