
吉林大学22级机器学习B期末复习
初步理解 概率论加线性代数课。
第一步,新建文件夹 持续更新中..不知道什么时候能整完> <
初步理解 概率论加线性代数课
只给这门课留了一周时间实在是有点紧张啊。。。
李航老师统计学习方法答案汇总_统计学习方法李航答案-CSDN博客
【一起入门MachineLearning】中科院机器学习期末考试*总复习*-考前押题+考后题目回忆_中科大机器学习期末试卷-CSDN博客
推荐大二下学期选修 计算方法 这门课,开卷考试不过比较难,但是很有用,大三上后悔已经来不及了
简答题
1.线性回归的基本思想?
2.简要说明梯度下降法的过程?
(梯度下降vs最小二乘)
3.BGD vs. SGD?
4.学习率α的选择?
5.欠拟合vs过拟合?
6.硬分类vs软分类
7.准确率vs精确率vs召回率
8.SVM的过程?
引入拉格朗日算子、原始问题转换对偶问题、求对偶问题的解、对偶问题的解转为原问题的解
9.求解线性可分支持向量机的步骤?
利用拉格朗日乘子法,构造拉格朗日函数;利用强对偶性(KKT条件)将优化问题进行转化,并求解;利用最优的𝑤∗和𝑏∗构建分类器。
10.SMO的思想?
11.非线性SVM的解法?
12.SVRvsSVM
13.聚类问题是什么?
聚类(Clustering)是最常见的无监督学习算法,它指的是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。
14.聚类过程中需要解决哪些问题?
定义数据间的距离/相似度度量;使用相应的算法对数据集进行分割; 度量聚类结果的性能。
15.聚类主要类型
划分聚类(K-means、K-medoids等) 层次聚类(凝聚法、分裂法) 密度聚类(DBScan、 基于密度峰值算法) 网格法(STING、CLIQUE)模型法(概率模型:高斯混合模型Gaussian MixtureModels ;神经网络模型:SOM;吸引子传播算法:AP聚类)谱聚类
16.K-means的流程
随机选择 K 个簇中心点(可以选已有的数据作为中心点,也可直接选高维空间中的位置); 样本被分配到离其最近的中心点; K 个簇中心点根据所在簇样本,以求平均值的方式重新计算; 开始迭代,重复第2步和第3步直到所有样本的分配不再改变
17.K-means的优缺点
优点:简单快速,对大数据集保持伸缩性和高效性,对密集结果簇效果好
缺点:只适合数值型数据,需要事先给出K,且对初值敏感,不适合于发现非凸面形状的簇或者大小差别很大的簇,对噪声和孤立点数据敏感
18.什么是数据降维?
降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维空间。该过程与信息论中有损压缩概念相似,完全无损的降维是不存在。 降维方法又分为线性降维和非线性降维,非线性降维又分为基于核函数和基于流形等方法
19.为什么要降维?
数据降维可以使得数据集更易使用、确保变量之间彼此独立、降低算法计算运算成本、去除噪音。 数据降维常应用于文本处理、人脸识别、图片识别、自然语言处理等领域。
20.常见的几种核函数?
线性核, Gauss径向基核, 多项式核,S形核(双曲正切核)
证明题
证明题想不出来怎么出..因为老师说公式的推导不需要重点关注。猜测和简答题差不多吧
1.最小二乘法的正规方程
重点公式
线性回归
1.拟合函数
![]()
2.代价函数
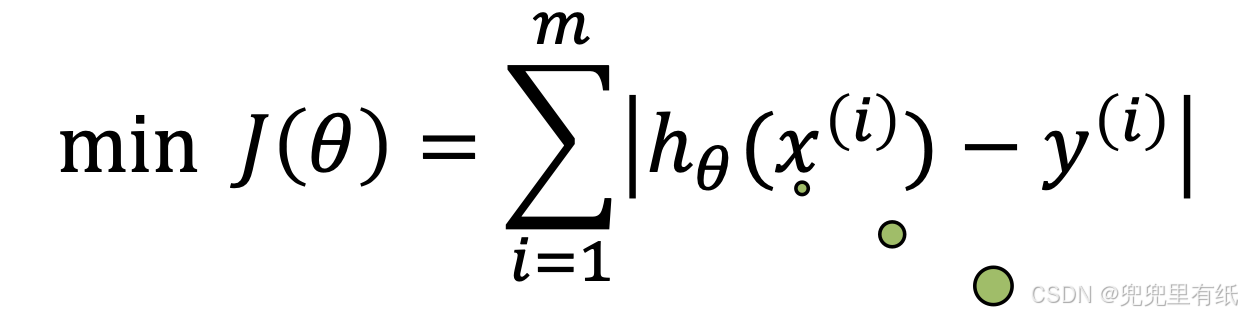
3.平方和误差(最小二乘法目标函数)
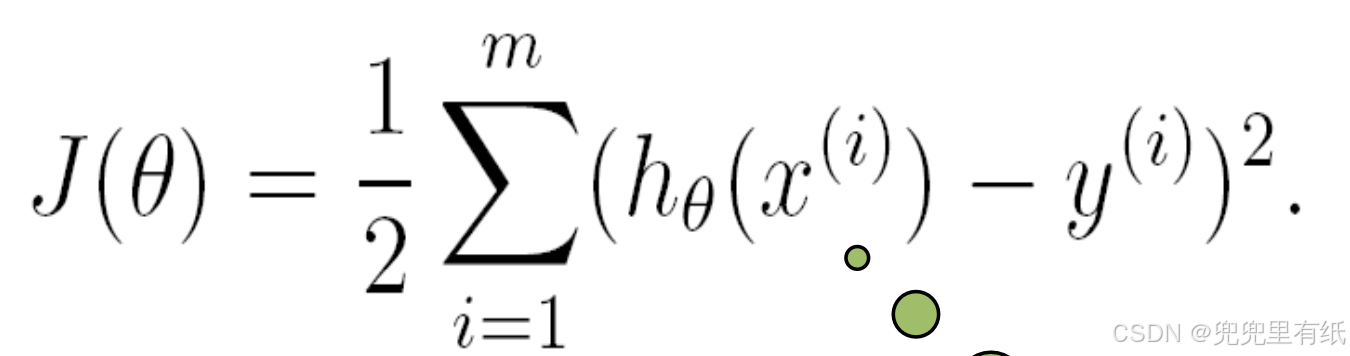
4.最小二乘法矩阵形式
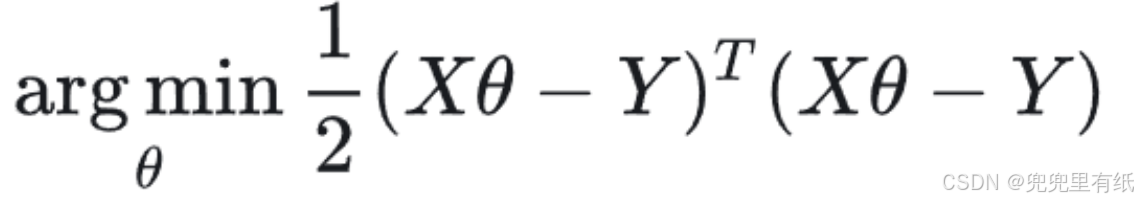
5.最小二乘法封闭解
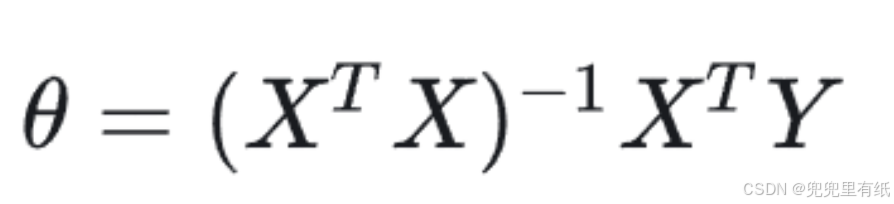
6.BGD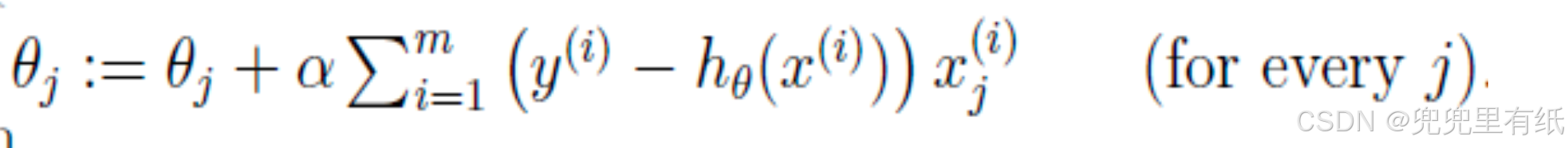
7.SGD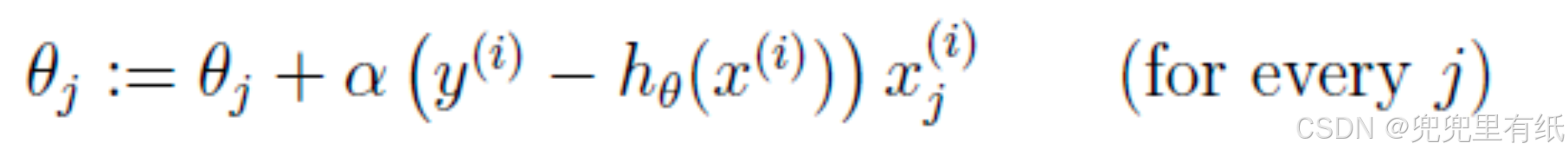
逻辑回归
1.sigmoid函数
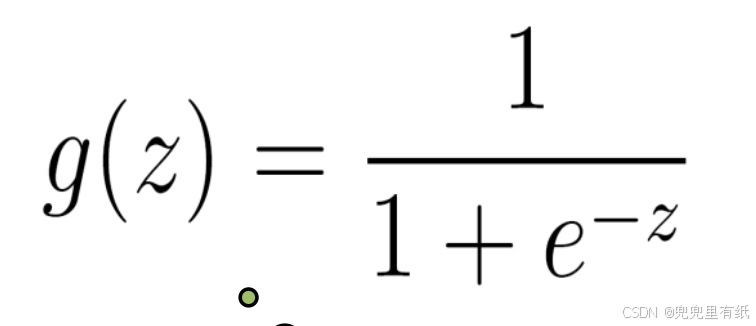
2.拟合函数
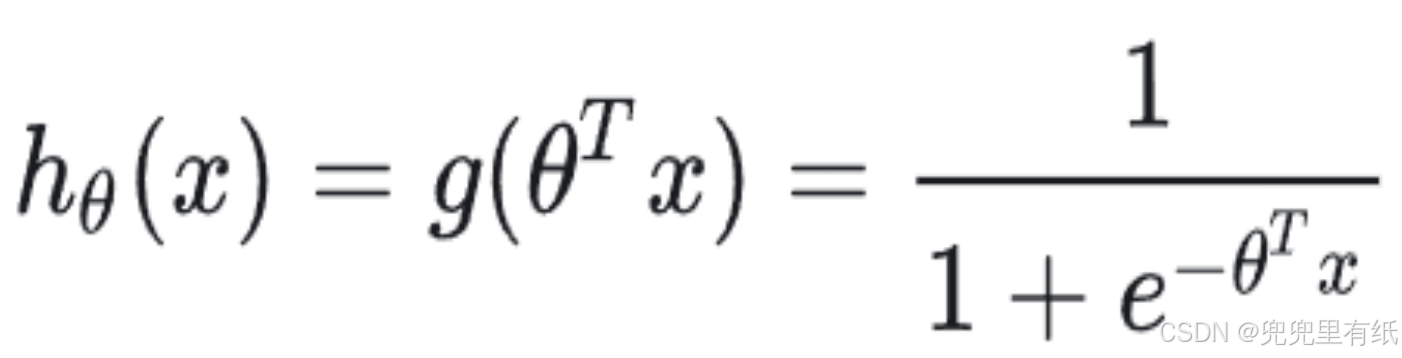
3.最大化似然目标函数
![]()
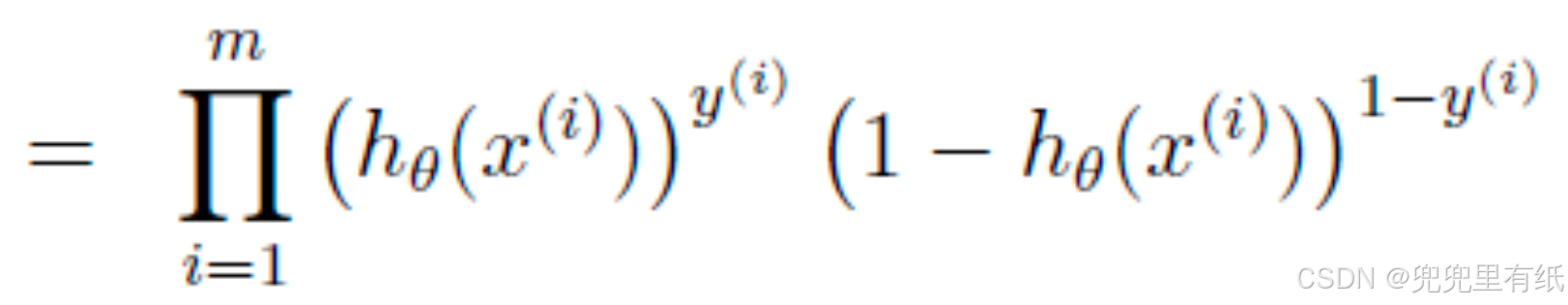
4.牛顿迭代公式
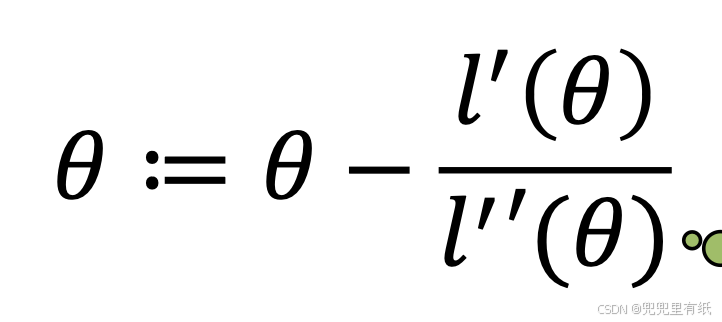
5.准确率
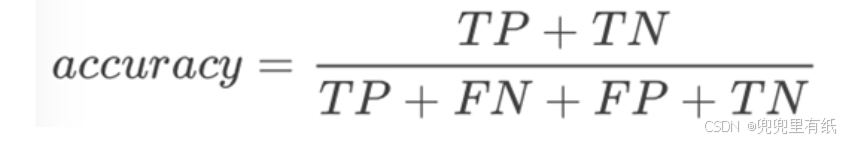
6.精确率
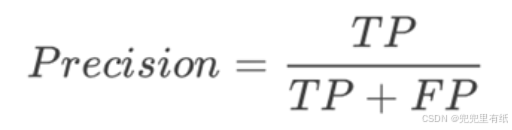
7.召回率
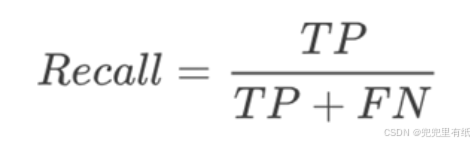
8.F1-score
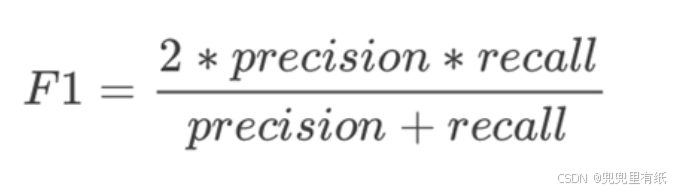
9.AUC
![]()
![]()
支持向量机
1.初始优化目标
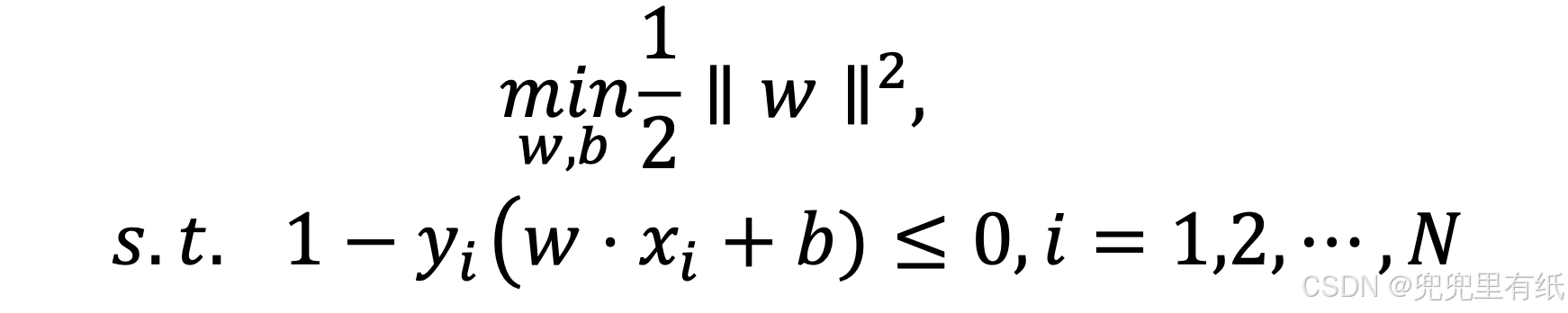
2.拉格朗日函数
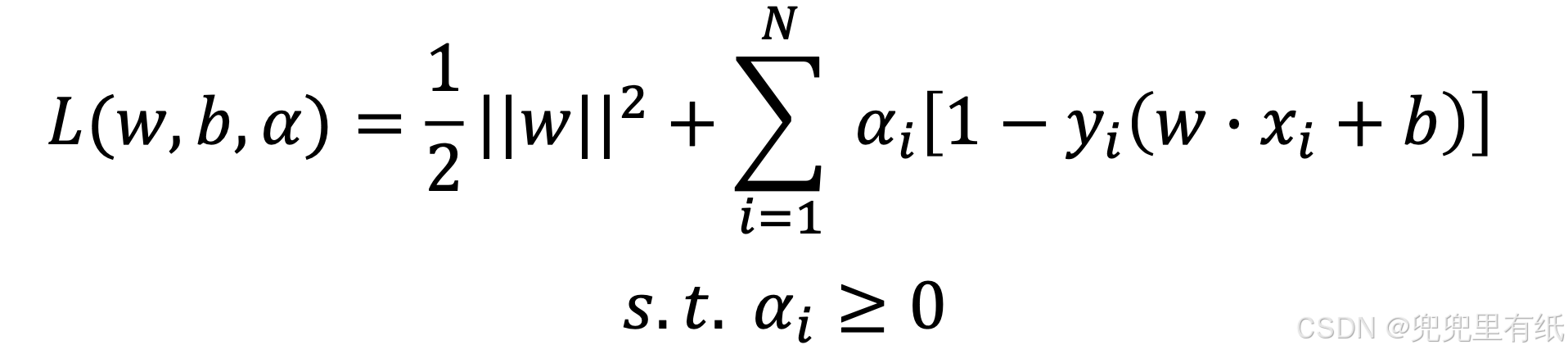
3.目标函数
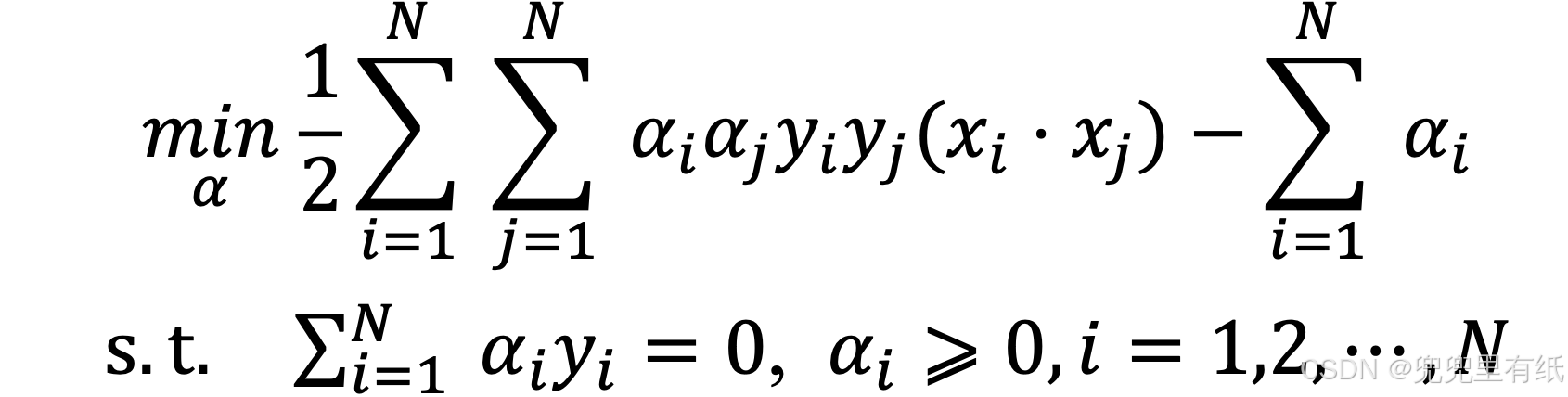
4.最优超分类曲面
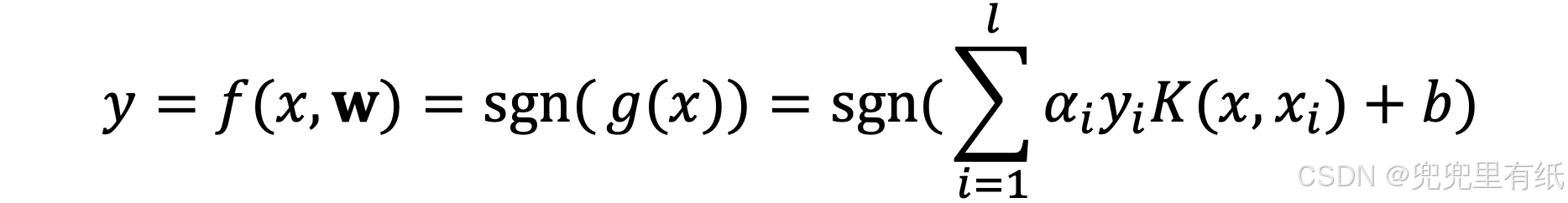
计算题
线性回归 梯度下降法
逻辑回归 最大似然函数 牛顿法
感觉出大题的概率稍微小一点,因为统计学习方法里面没有应用题(可能会考推导?)
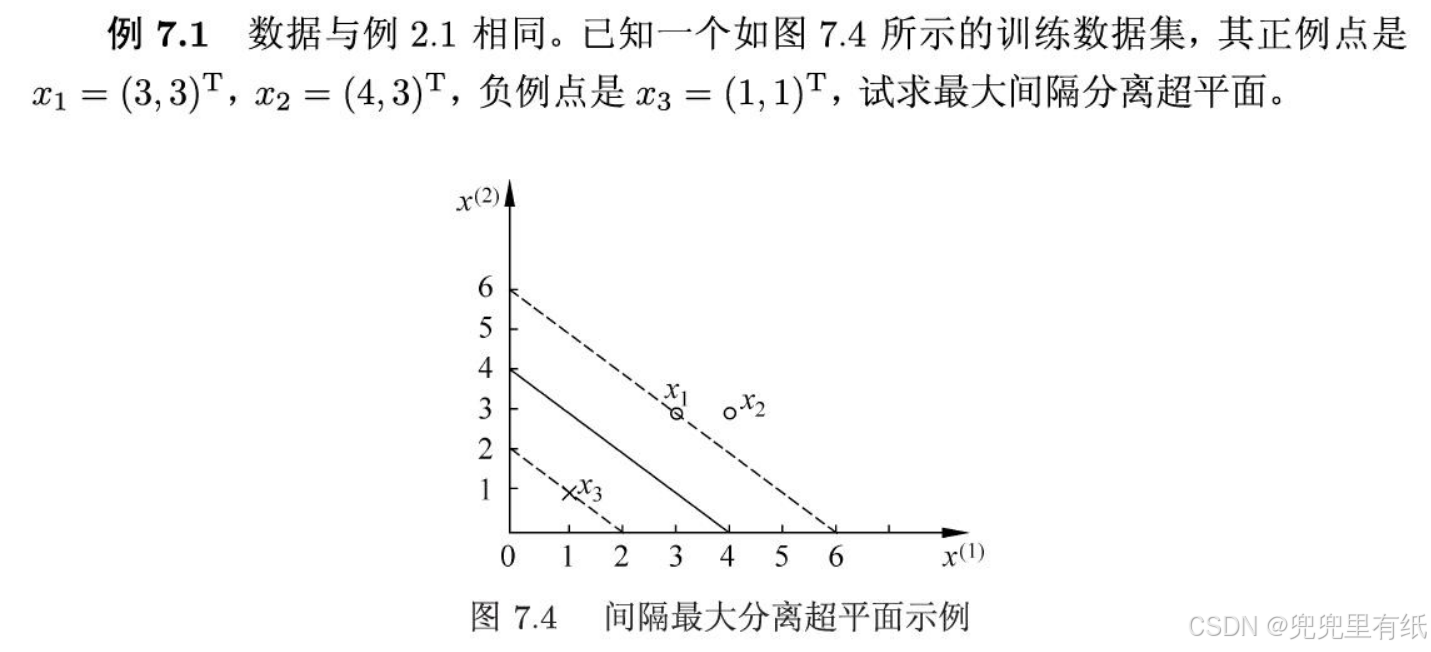
SVM求最大间隔分离超平面和分类决策函数
(计算题概率大一些,核方法的推导也有可能会考)
1.

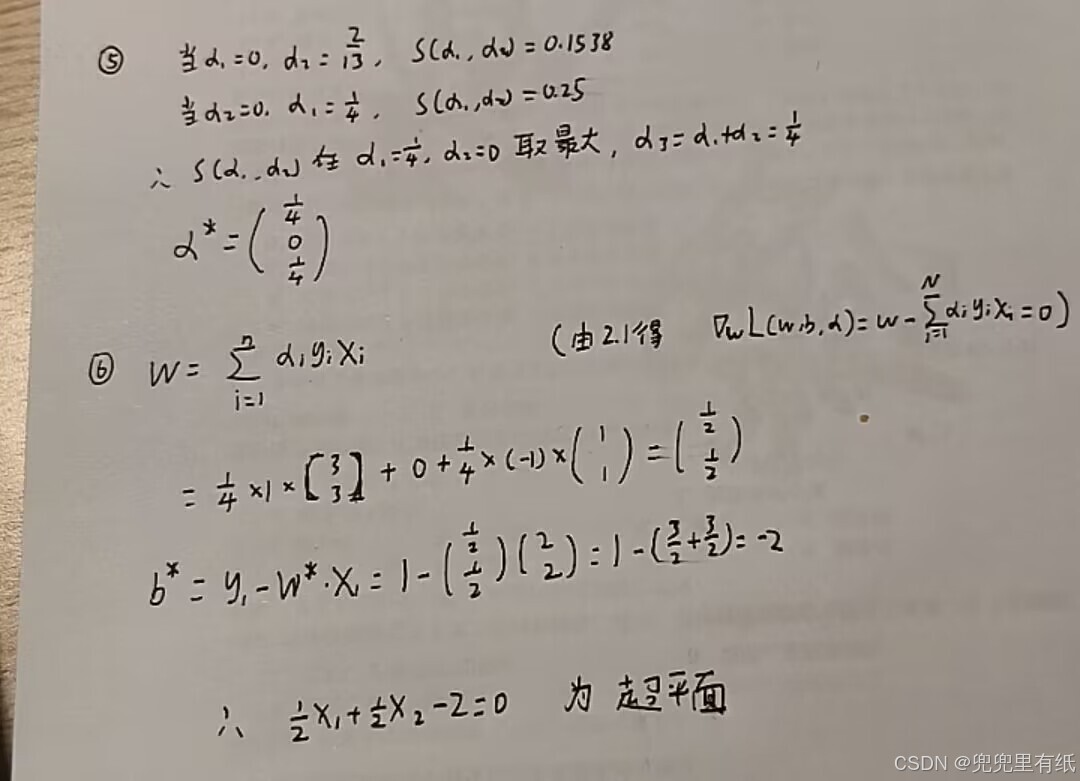
求b*笔误修正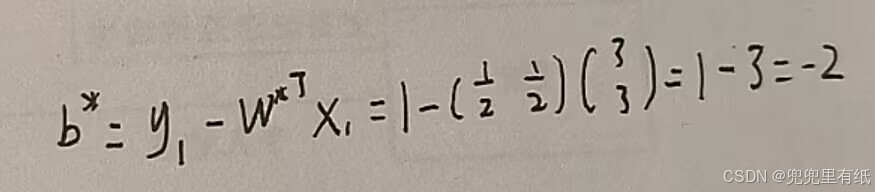
其实还可以用高中方法解决,就是①的那三个约束直接画图,然后取边界点
2.
3.
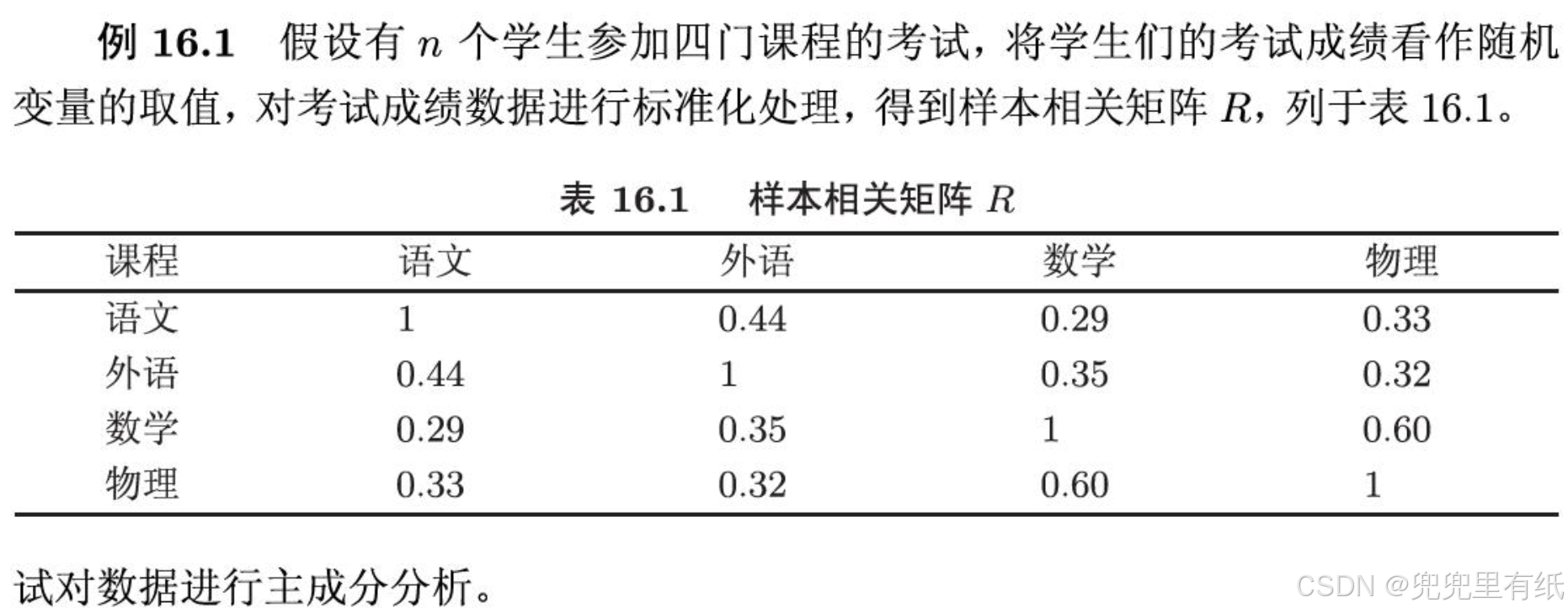
PCA
出题概率很大,PPT上为数不多的例题
第一章 绪论
机器学习的基本流程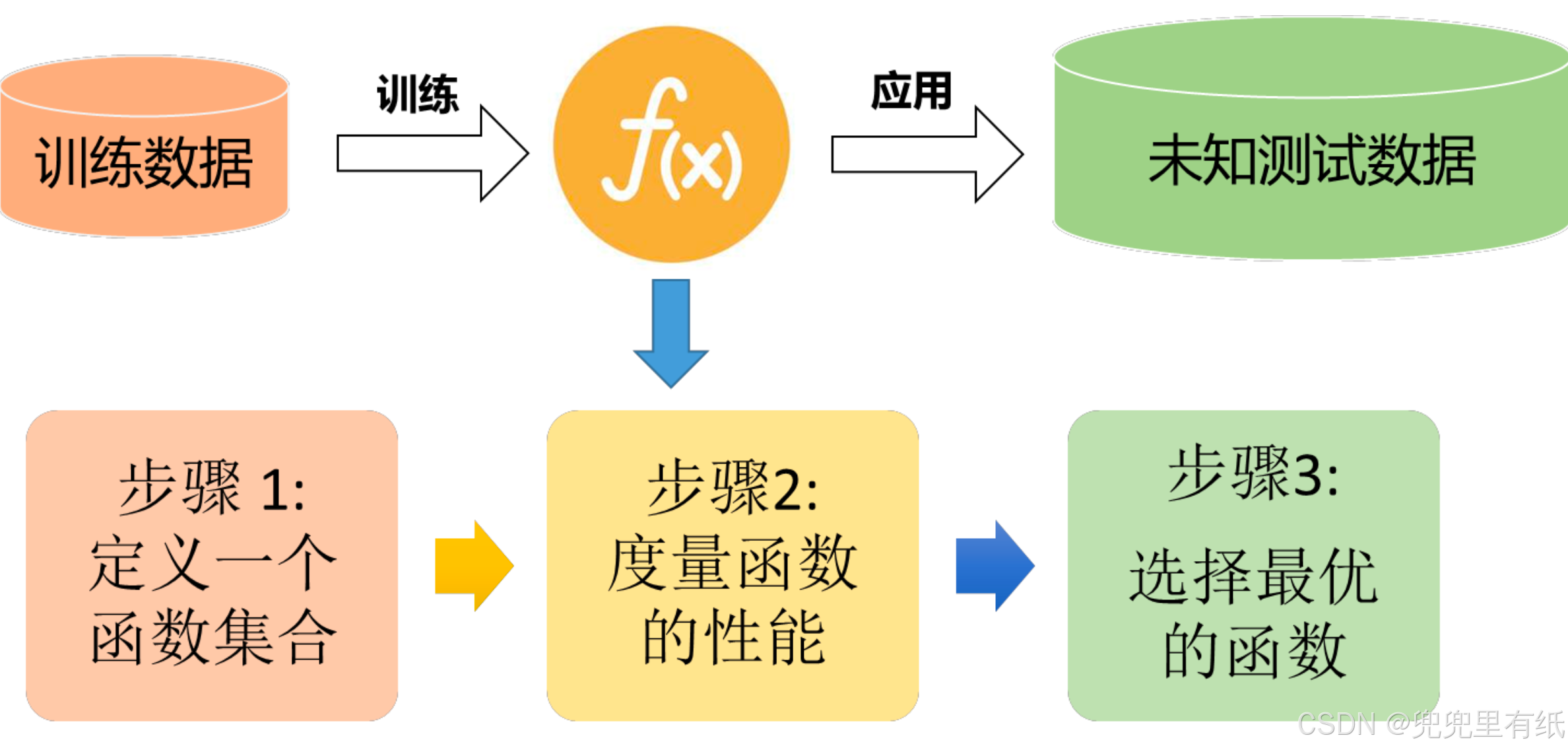
步骤1: 选择具体的模型
步骤2:定义目标函数
步骤3:选择最优的函数
机器学习算法的类型
监督学习
◼ 回归
◼ 分类
• 无监督学习
◼ 聚类
◼ 降维
• 半监督学习
• 自监督学习
• 强化学习
第二章 线性回归(重点)
线性回归
目标形式
代价函数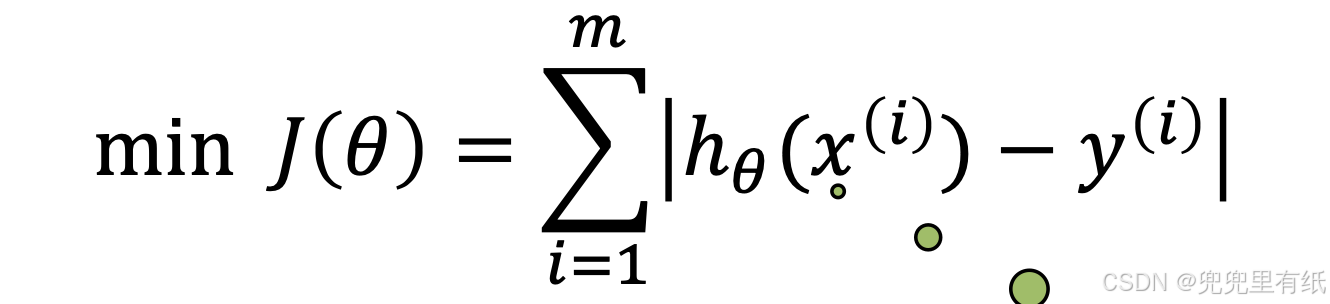
要求误差和最小,问题转化为求解【绝对误差】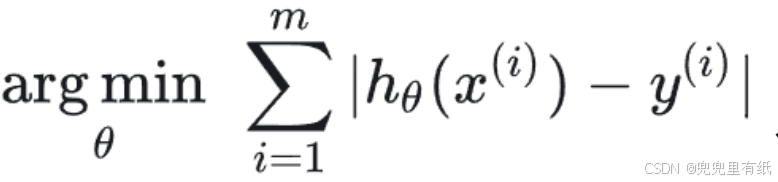
为了方便后续求解,损失函数采用【误差平方和】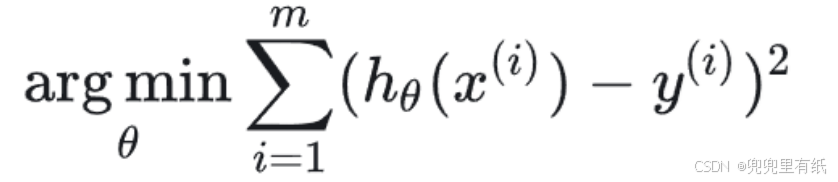
线性回归的过程
第一步:建模
线性模型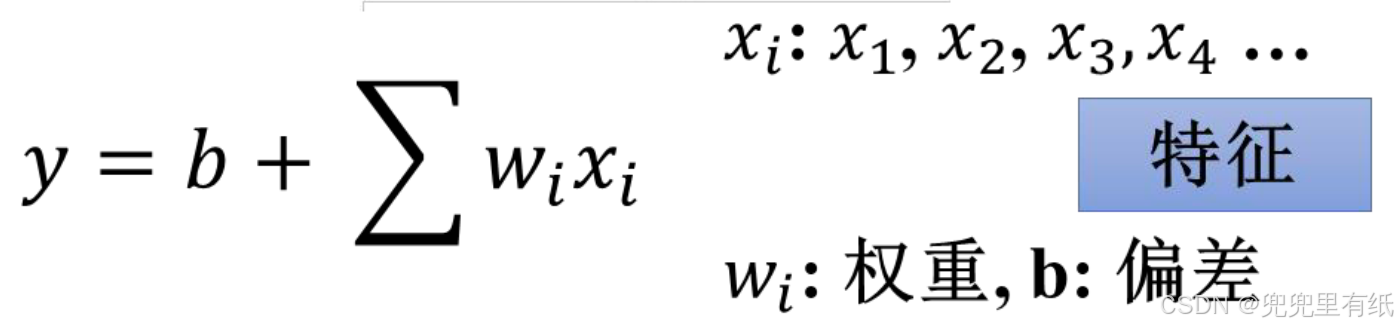
第二步:评估模型
估计误差


第三步:寻找最优函数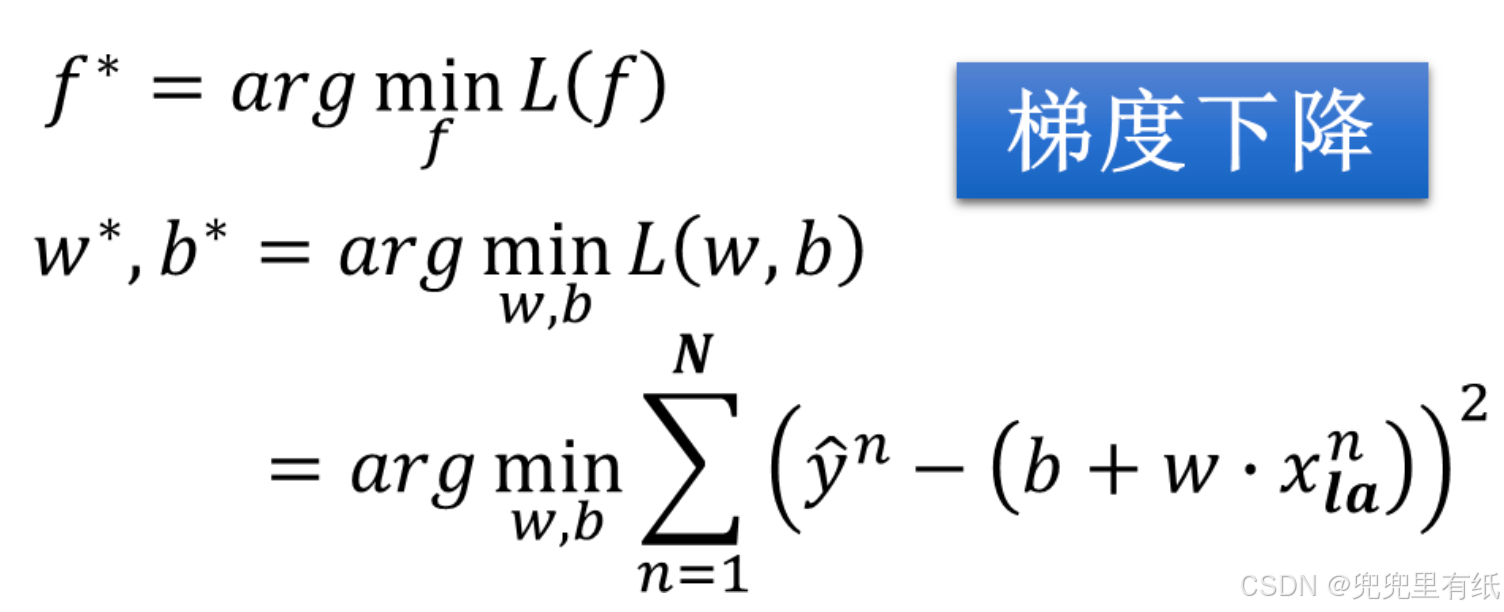
特征规范化
目的:各个特征变量的范围要保持相近

最小二乘目标函数(大题)
为了方便使用梯度下降法求解模型参数
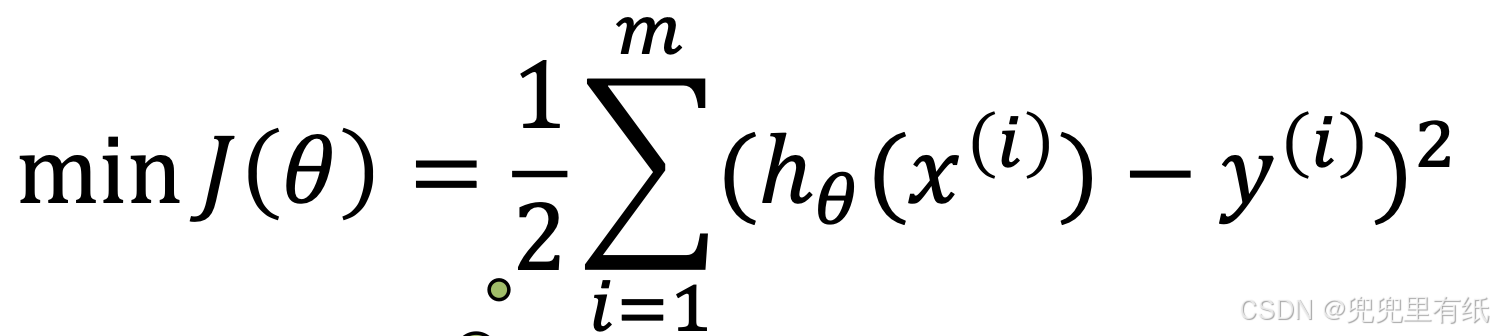
以闭合形式求出使 J(θ) 最小的 θ 值。

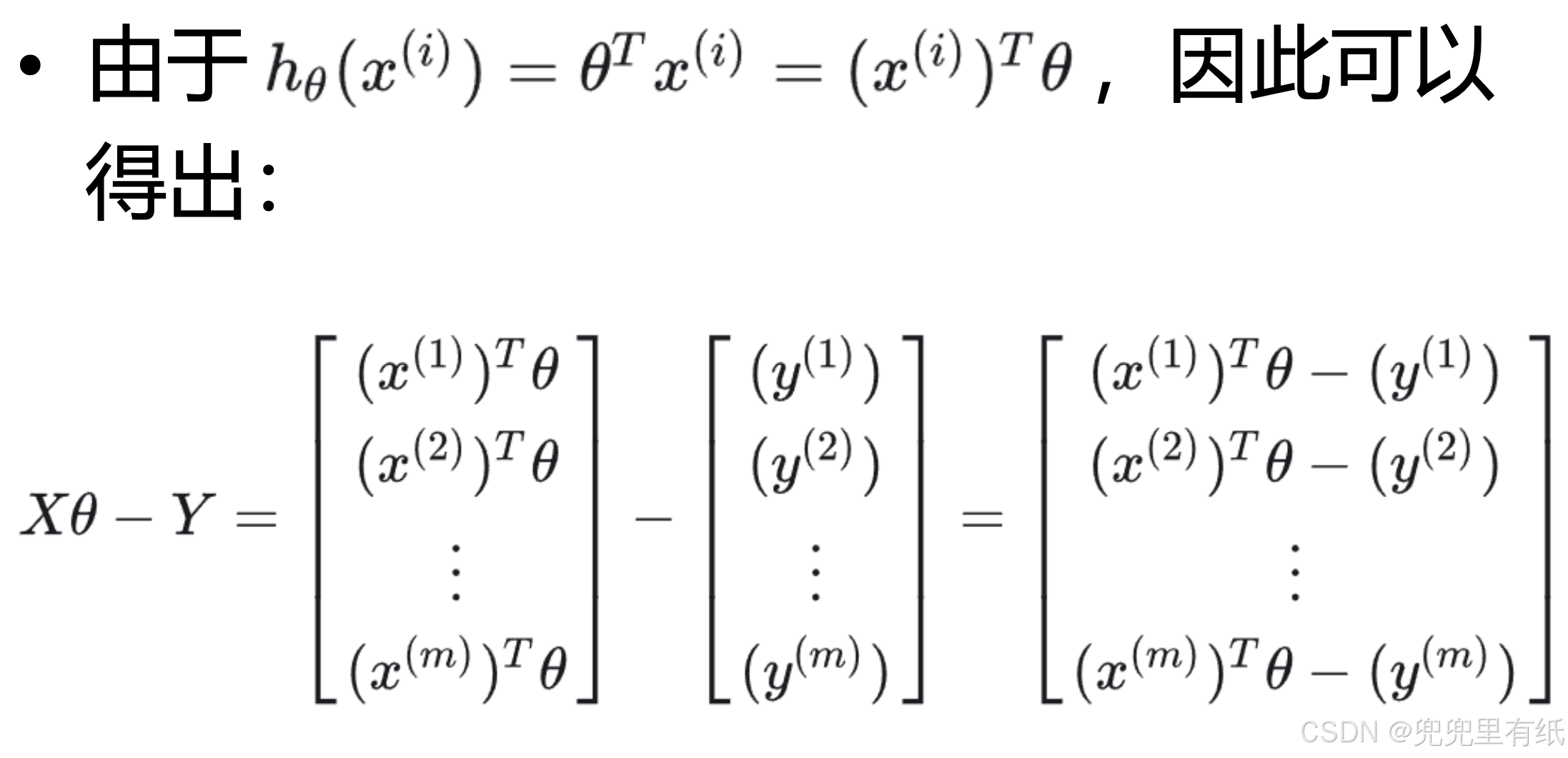

最小化 J(θ),令J(θ)关于θ 的偏导数为0,
得到θ的闭式解。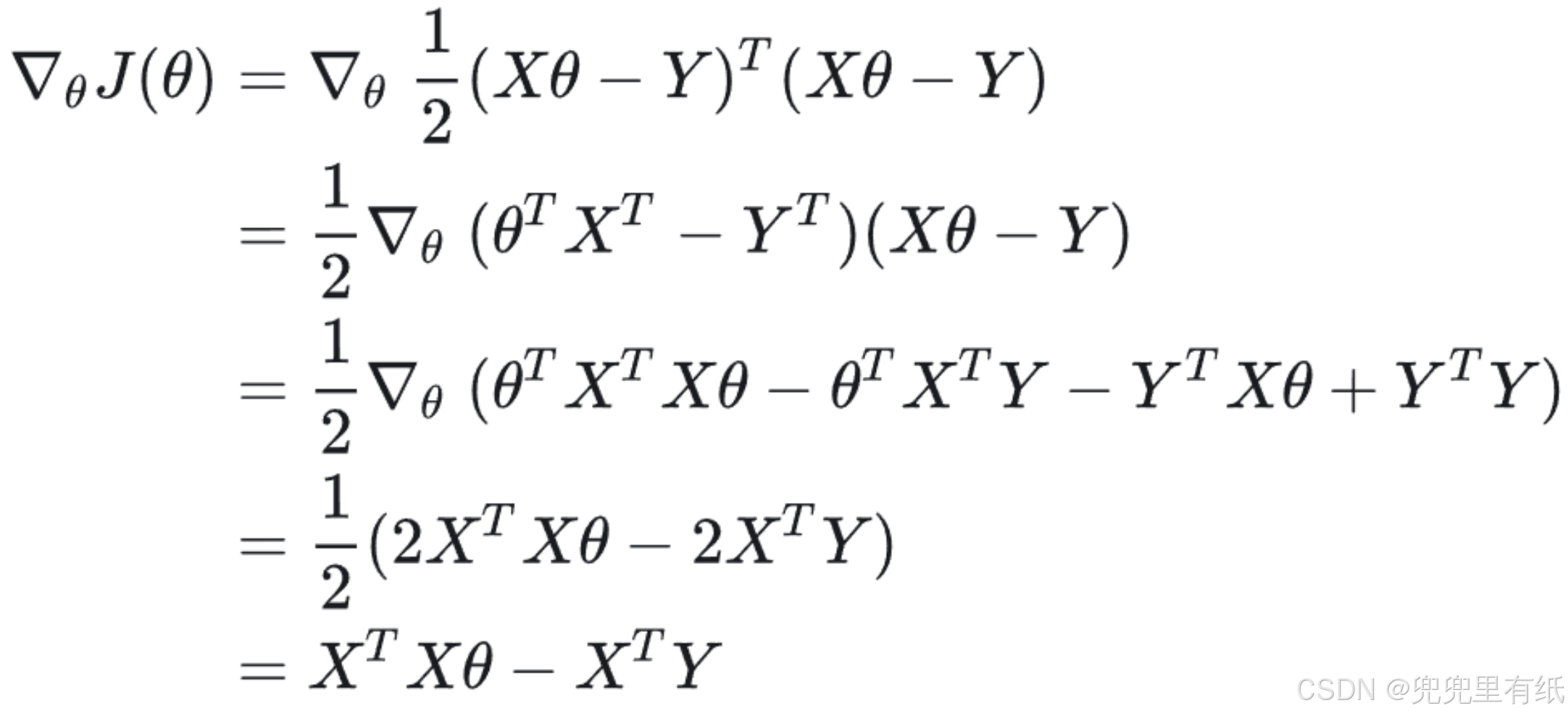
正规方程
示例
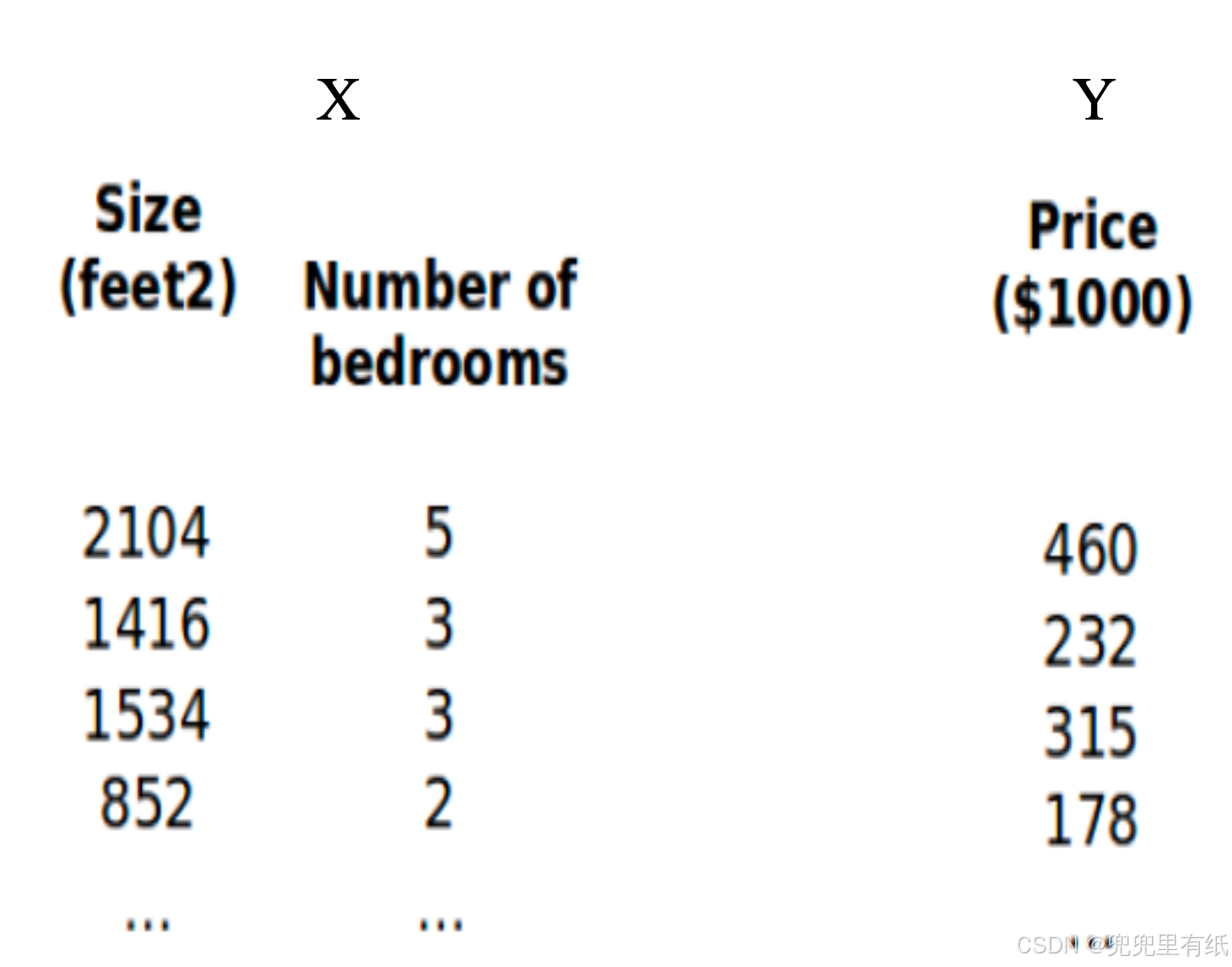

增广矩阵

X'是转置

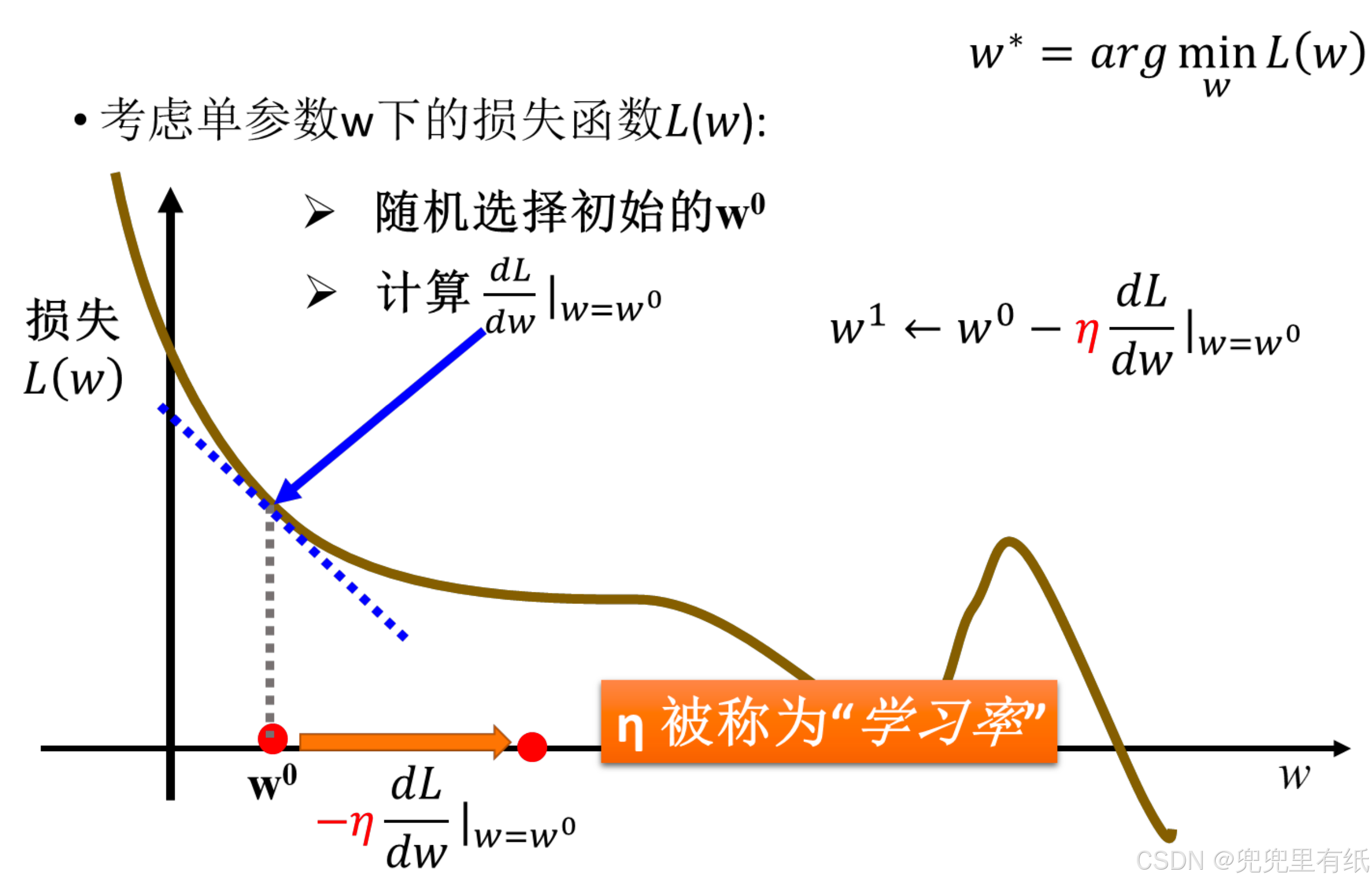
梯度下降法
最小化优化【梯度下降法】
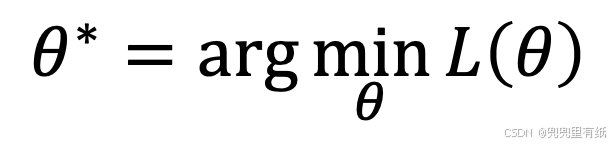
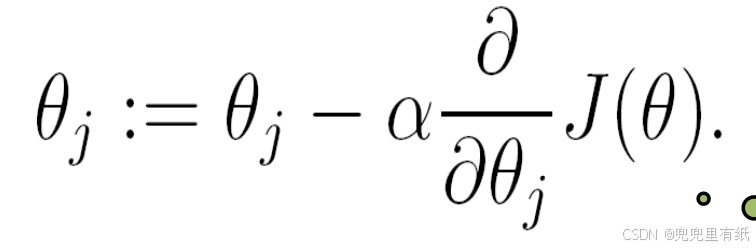
最大化优化【梯度上升法】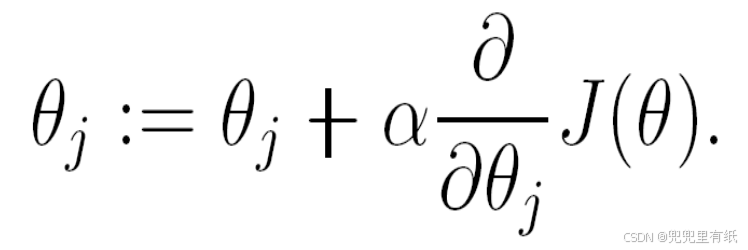
只有一个训练样本: 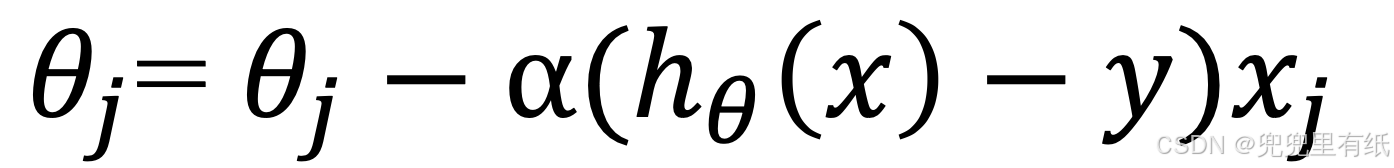
其中,0 ≤ 𝑗 ≤ 𝑛
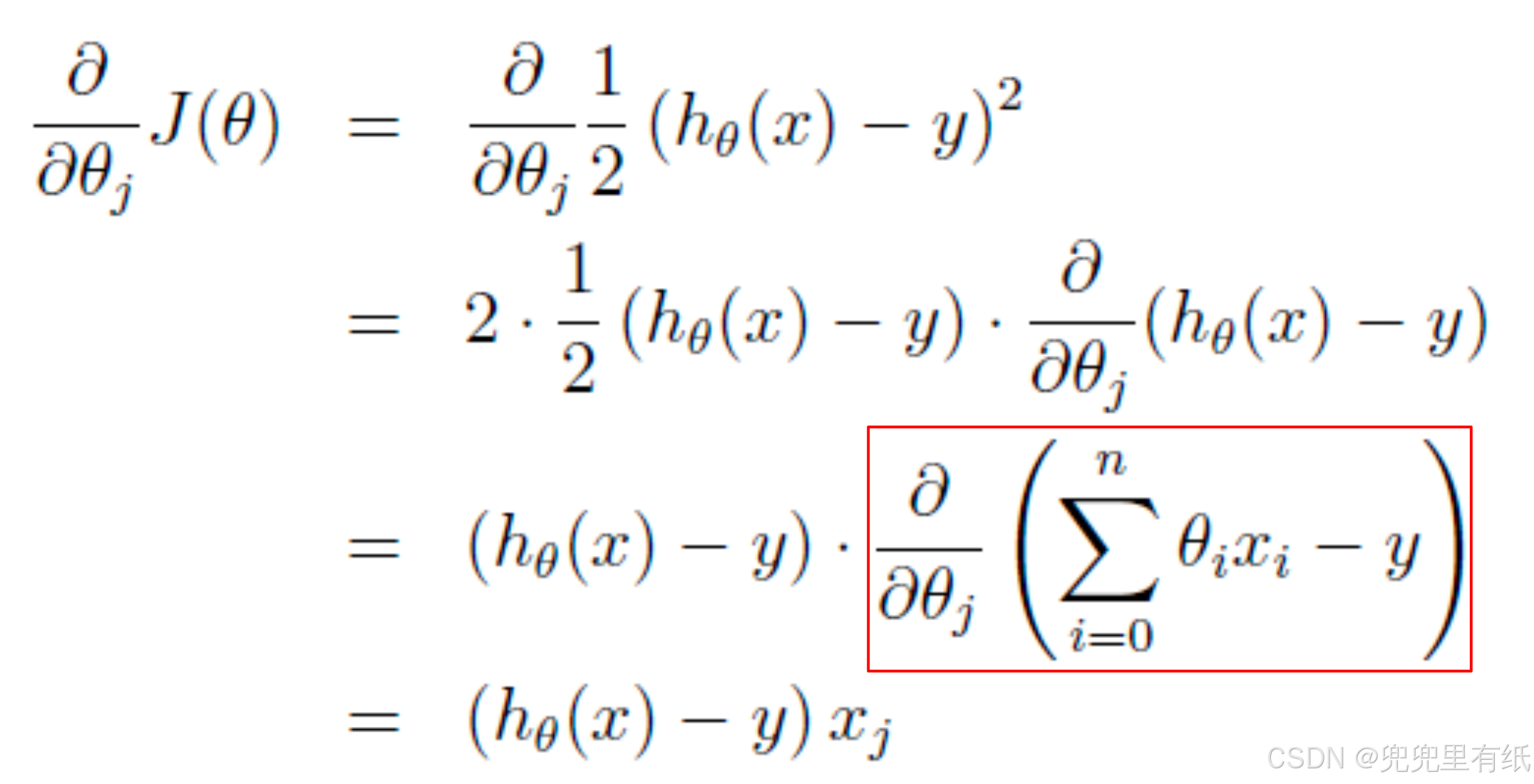
多个样本
批量梯度下降
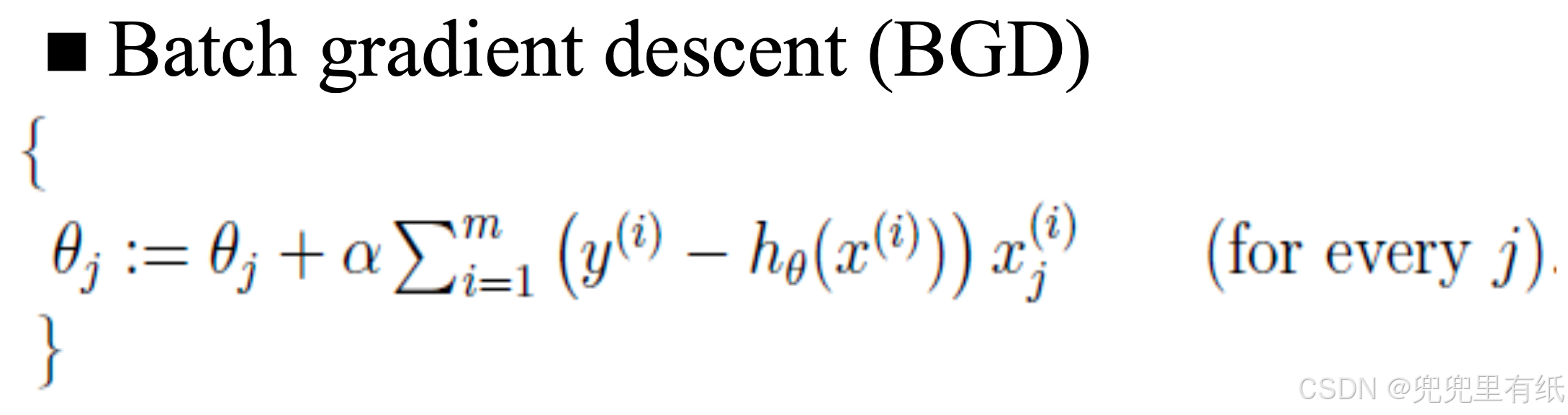
随机梯度下降
(BGD vs. SGD)
◼ BGD 扫描整个训练集后再更新参数
◼ SGD 遇到一个样本后立即更新参数
◼ 对于大样本问题,BGD收敛较慢
◼ 但SGD有可能发生震荡,而无法收敛到极小值
◼ mini-batch梯度下降:如果不是每拿到一个样本即更改梯度,而是若干个样本的平均梯度作为更新方向,则是 mini-batch梯度下降算法
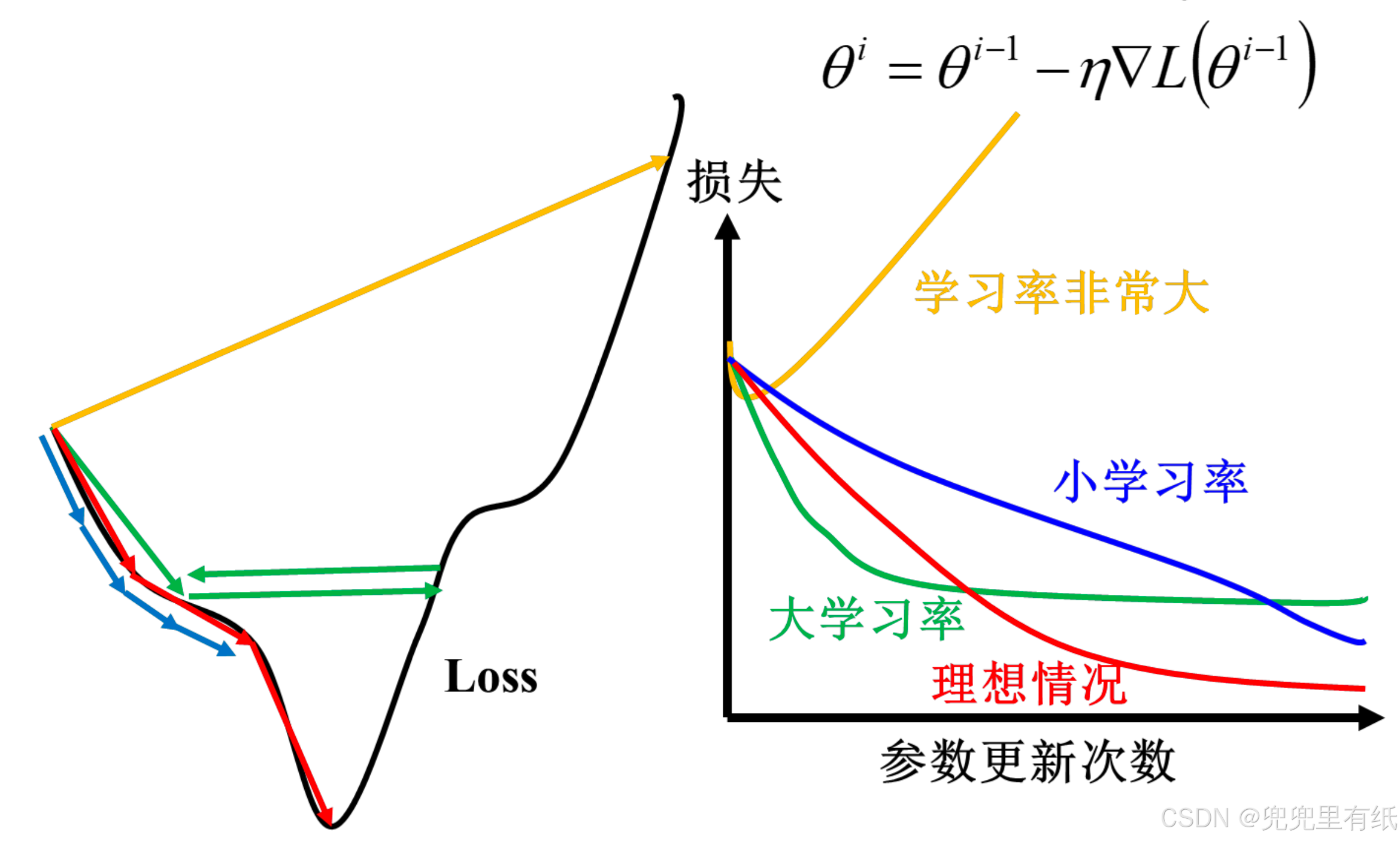
学习率很重要【局部最小vs全局最小】
学习率α过小,达到收敛所需的迭代次数高;
学习率α过大,每次迭代可能会越过极小值,导致无法收敛。
总结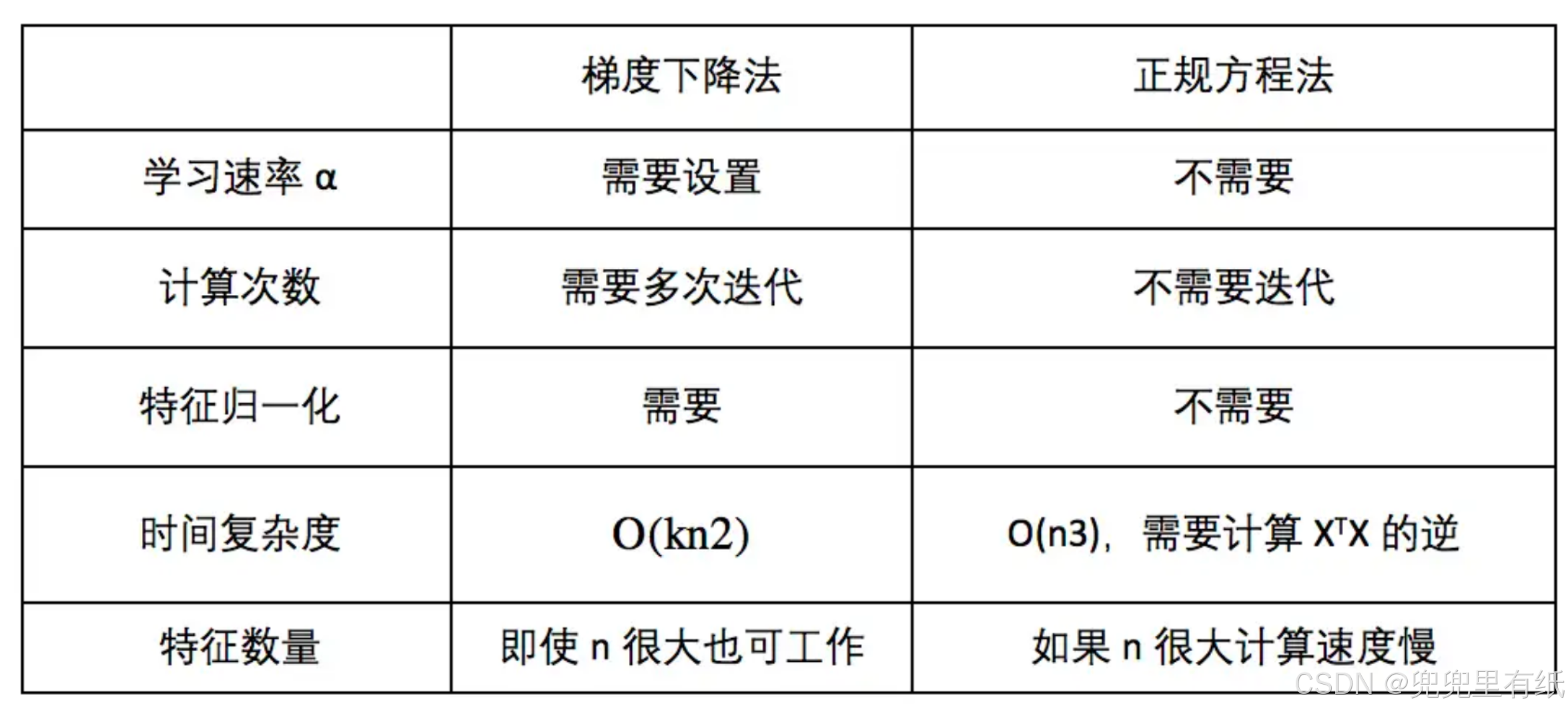
线性回归的概率解释
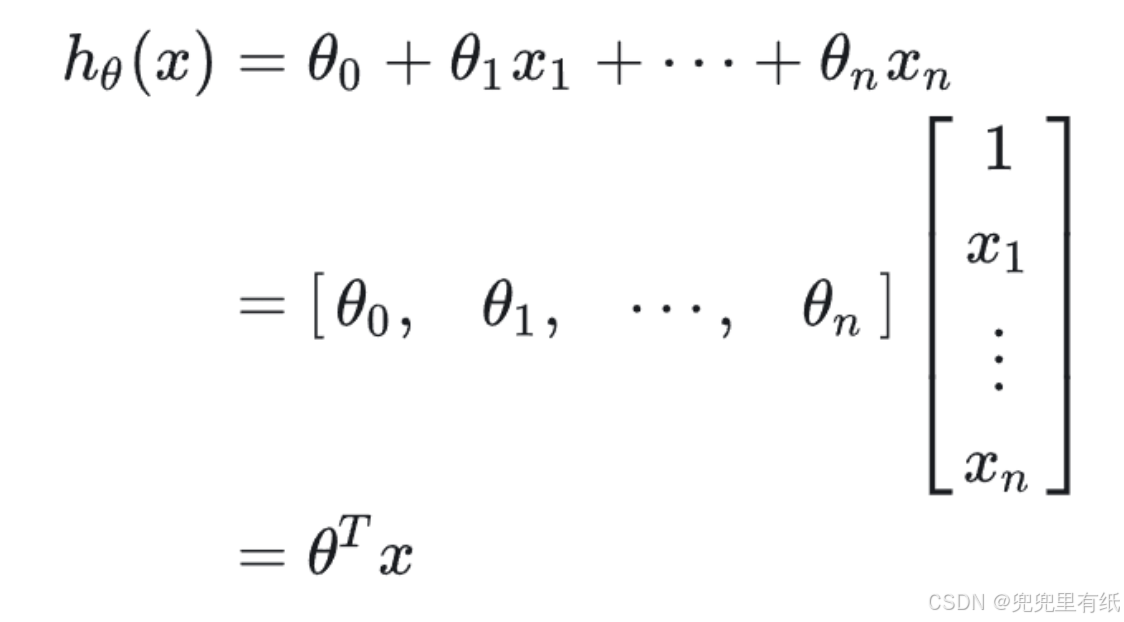


极大似然估计
取对数
求解最大化对数似然函数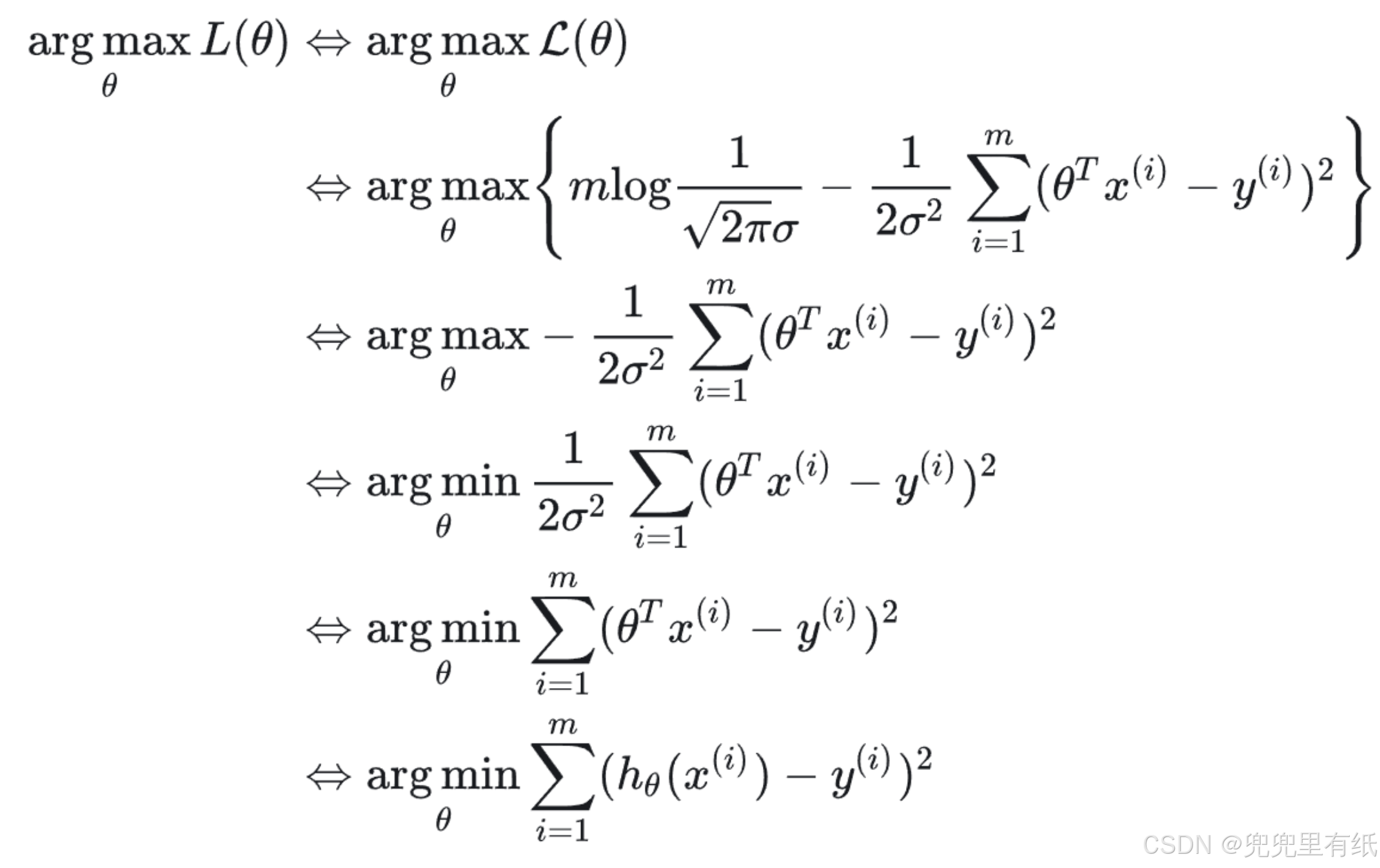

欠拟合与过拟合
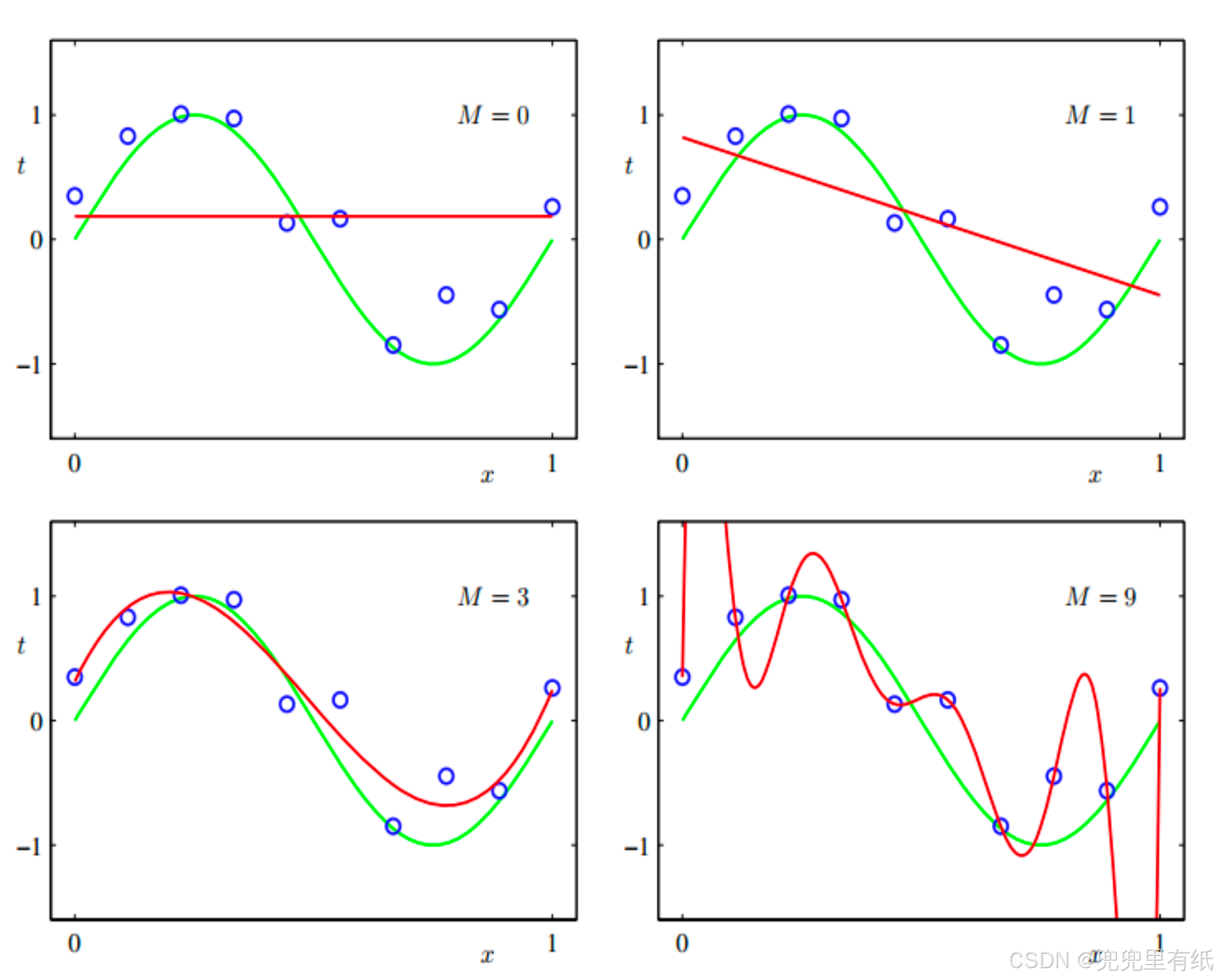
如果关于同一个问题有许多种理论,每一种都能作出同样准确的预言,那么应该挑选其中使用假定最少的
正则化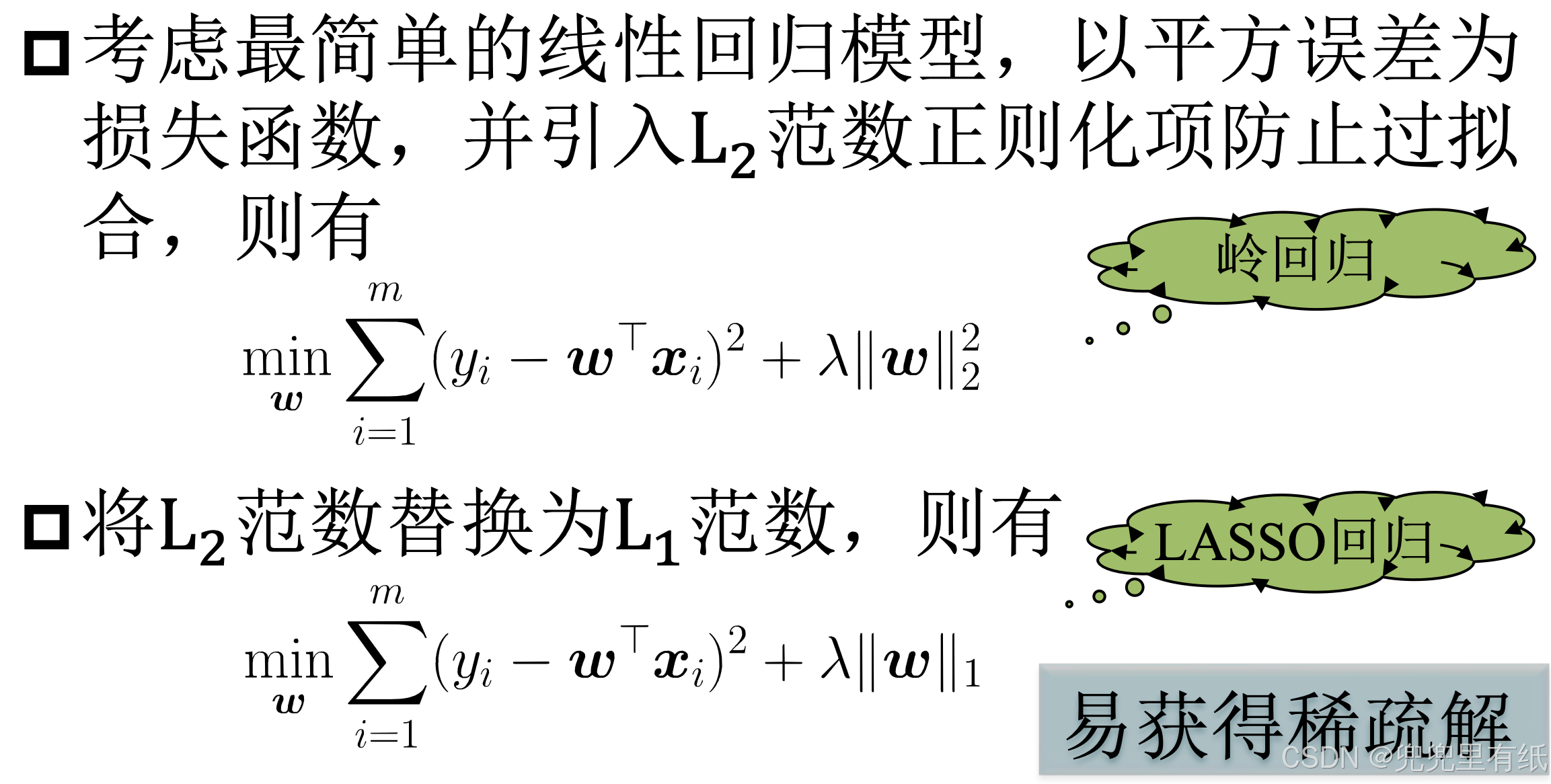
L1范数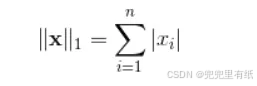 L2范数
L2范数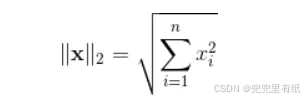
第三章 逻辑回归(重点)
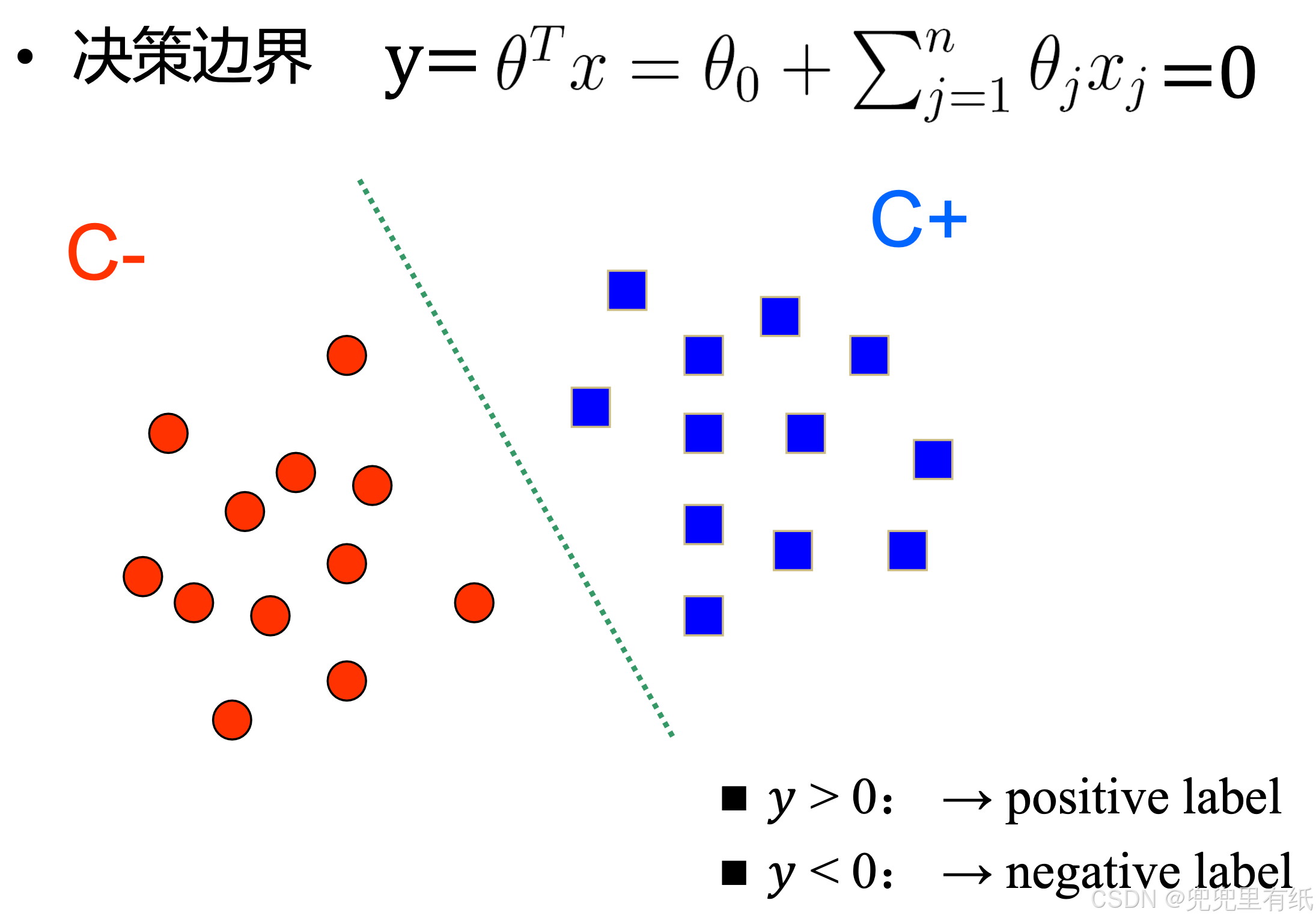
分类问题
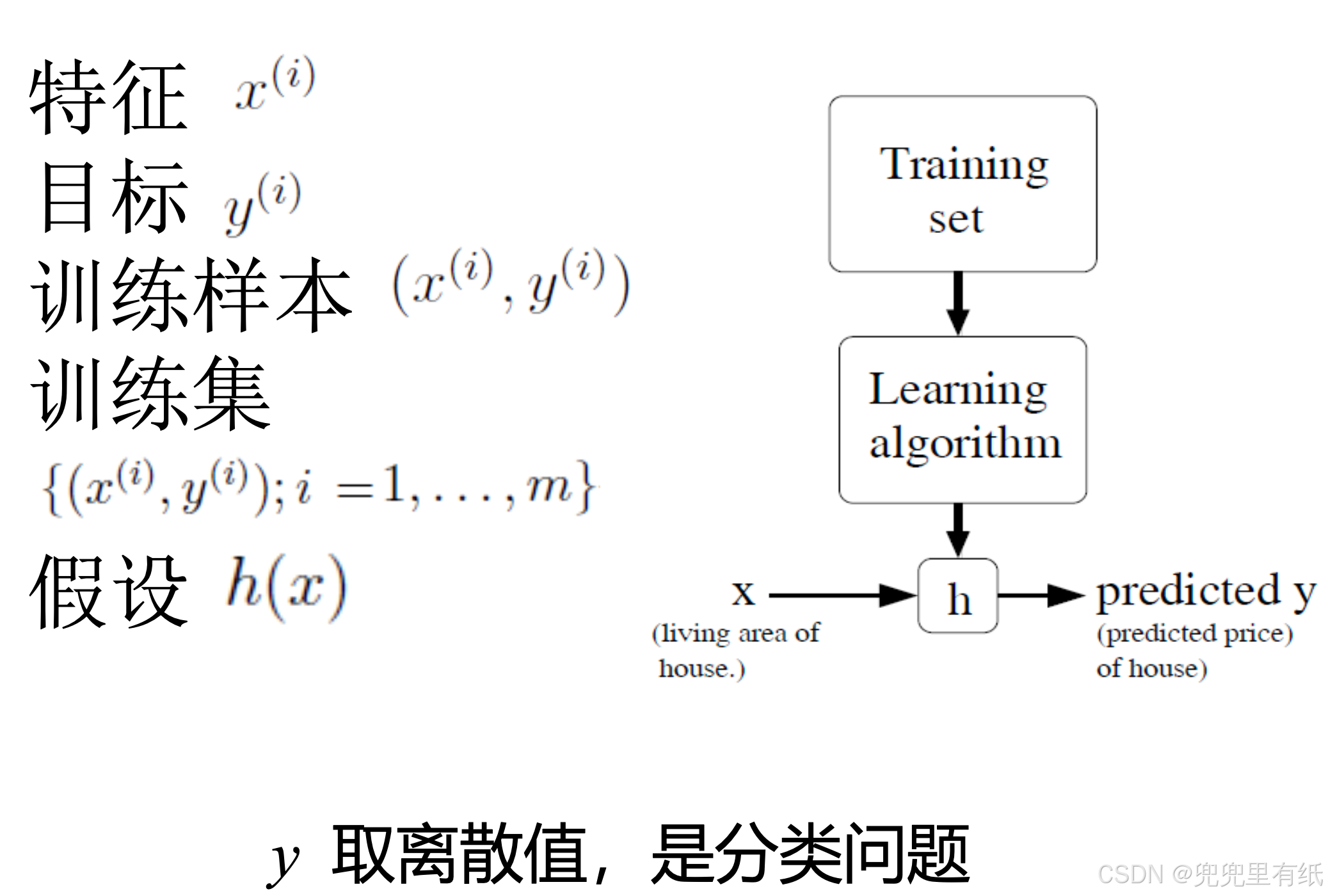
Logistics regression
单位阶跃函数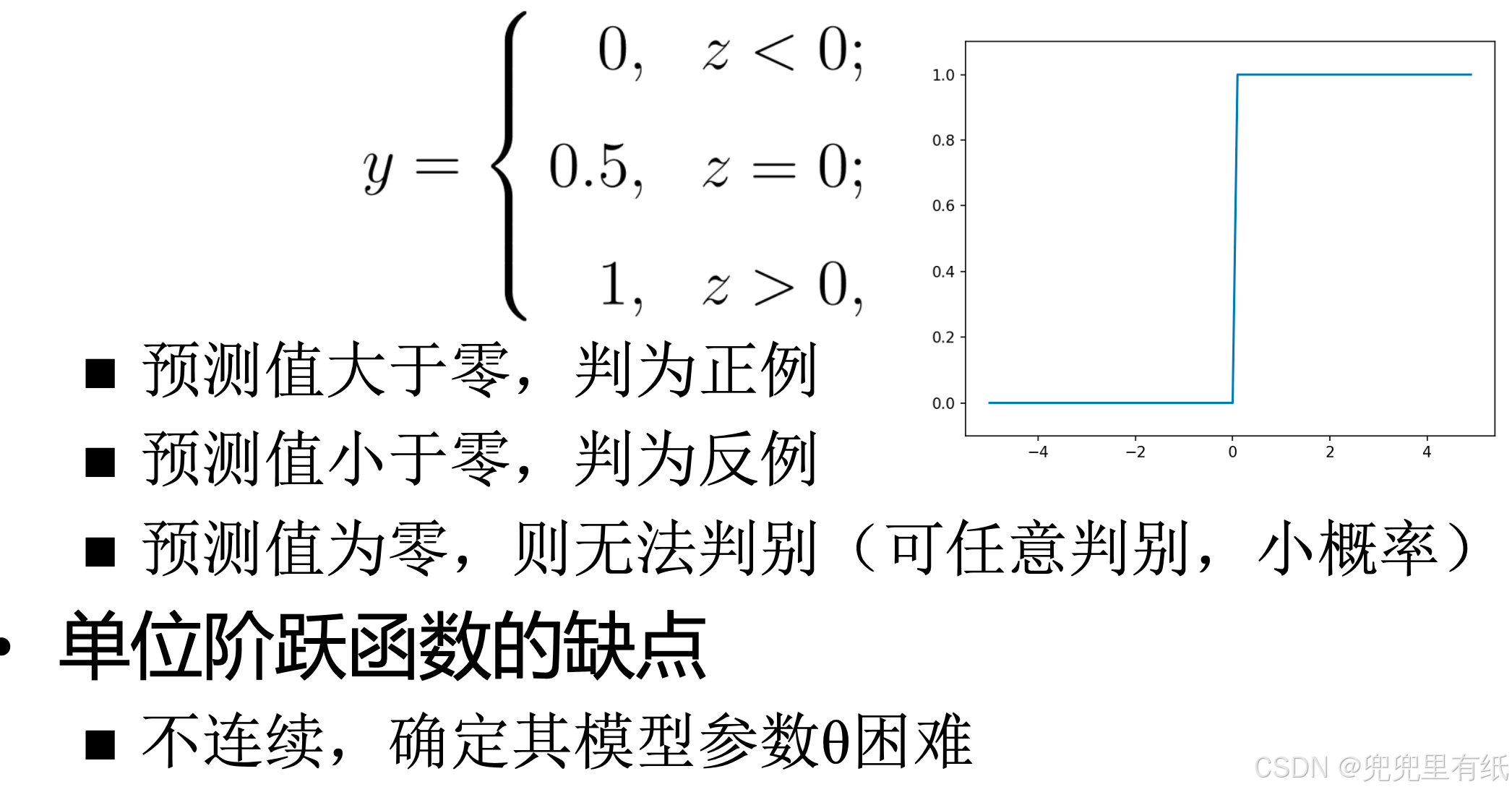
硬分类:离散、类别标签
软分类:连续、概率值(P(Y|X))
Logistics regression
刚开始学的时候觉得PPT的逻辑不是很清晰,而且半中文半英文比较影响阅读,推荐先看这个逻辑回归(logistics regression)原理-让你彻底读懂逻辑回归-腾讯云开发者社区-腾讯云
单位阶跃函数 vs. Sigmoid function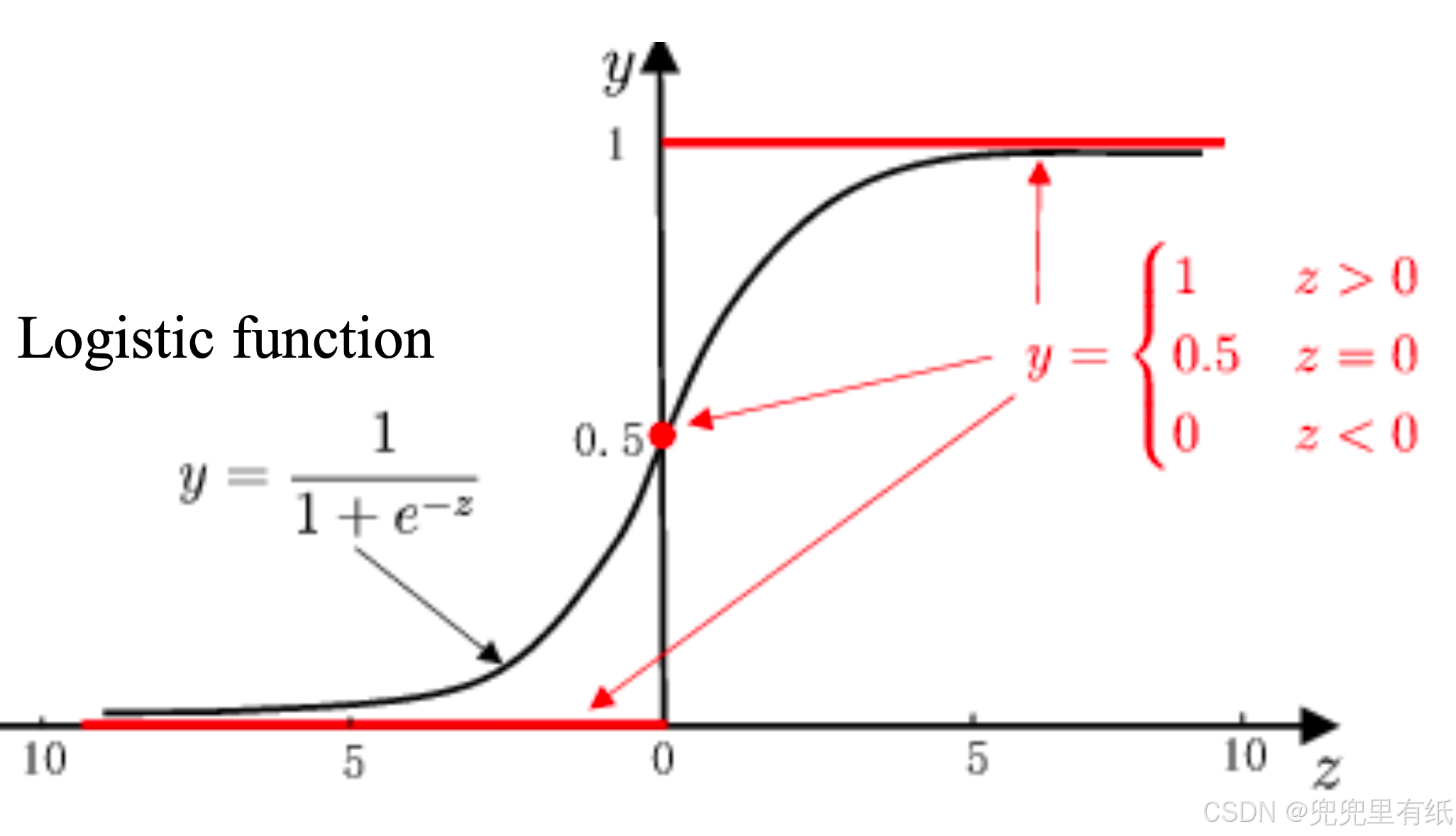
Logistic(sigmoid)函数(分布)的性质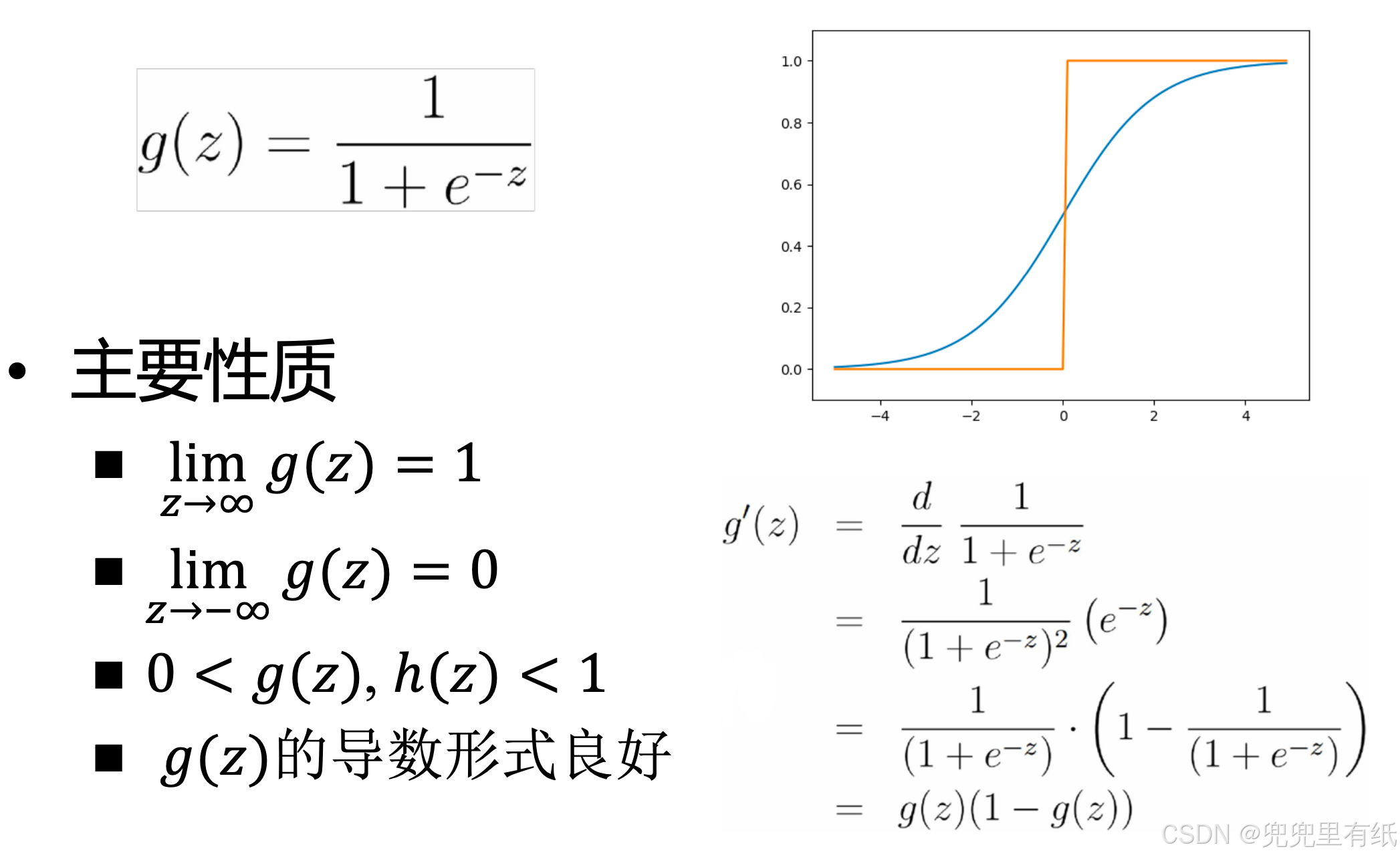
Odds(几率、几率比)
◼ 在统计和概率理论中,一个事件或者一个陈述的发生比是该事件发生和不发生的比率,又称几率、几率比,公式为: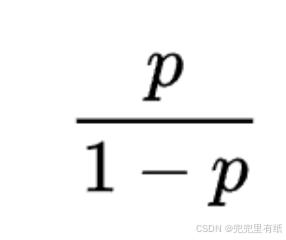
似然函数
1. 似然与概率的区别
似然 (likehood) 与概率 (probability) 在英语语境中是可以互换的。但是在统计学中,二者有截然不同的用法。概率描述了已知参数时的随机变量的输出结果;似然则用来描述已知随机变量输出结果时,未知参数的可能取值。
区别似然和概率的直接方法为,“XXX的概率"中XXX只能是事件,也就是,事件(发生)的概率是多少;而“XXX的似然"中的XXX只能是参数,比如说,参数等于某个值时的似然是多少。
2. 似然与概率的联系

3.最大似然估计(大题?)
最大似然估计是似然函数最初也是最自然的应用。似然函数取得最大值表示相应的参数能够使得统计模型最为合理。从这样一个想法出发,最大似然估计的做法是:首先选取似然函数(一般是概率密度函数或概率质量函数),整理之后求最大值。实际应用中一般会取似然函数的对数作为求最大值的函数,这样求出的最大值和直接求最大值得到的结果是相同的。似然函数的最大值不一定唯一,也不一定存在。
最大化对数似然目标函数【交叉熵损失函数】这个公式的推导可以看下面这个(PPT上都是英文)逻辑回归和极大似然估计有什么关系呢_哔哩哔哩_bilibili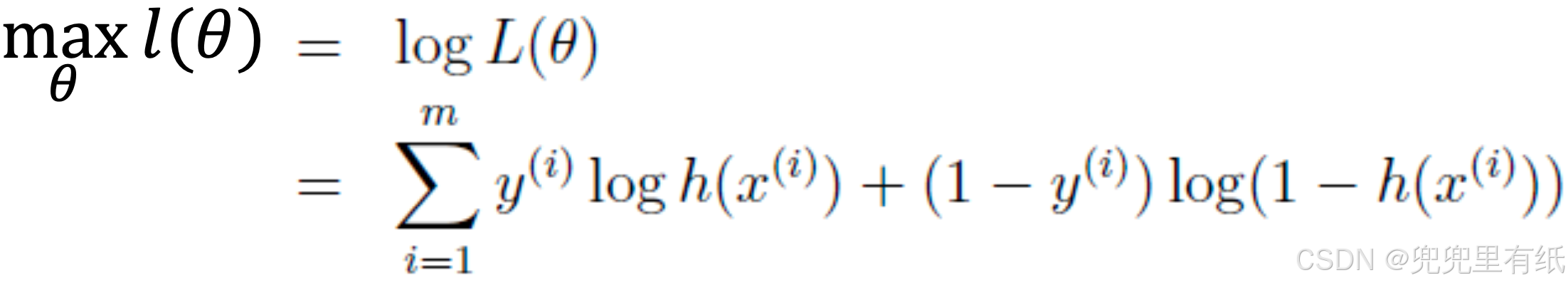
单样本梯度下降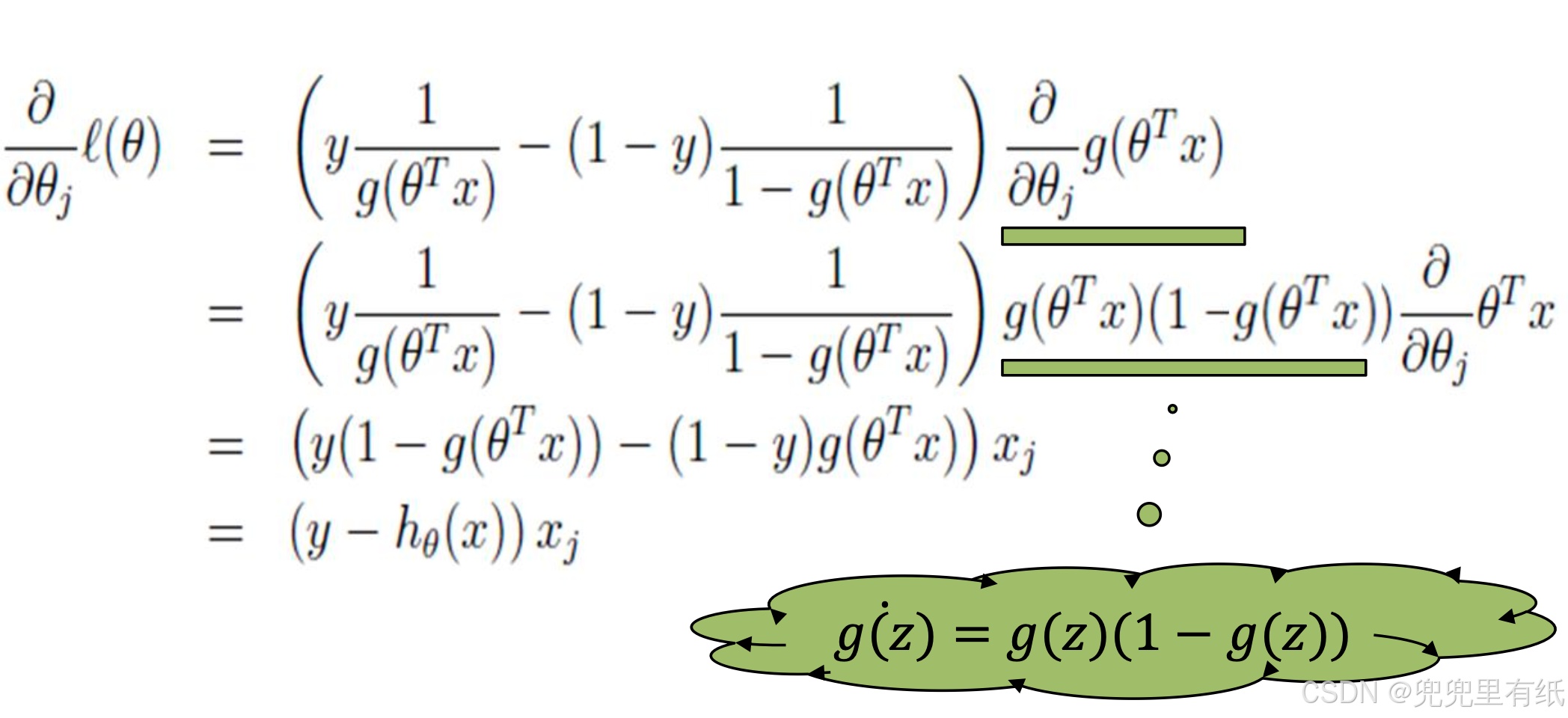
牛顿法(大题)
 本质:迭代逐步逼近
本质:迭代逐步逼近
求解过程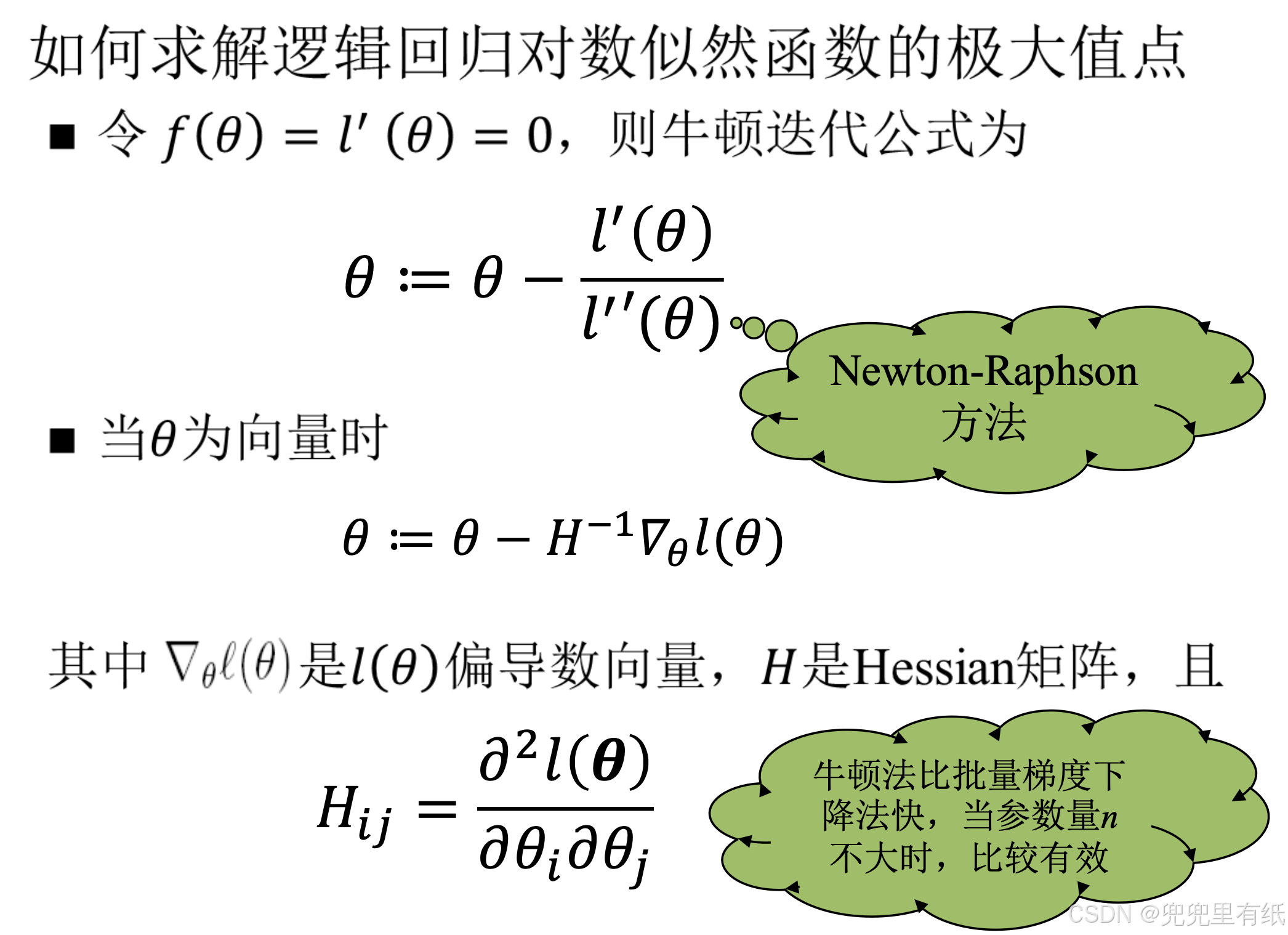
贴下上面的对数似然函数(要记住哦)(h是sigmod)
模型评估方法和性能评价指标
过拟合和欠拟合
训练集,验证集,测试集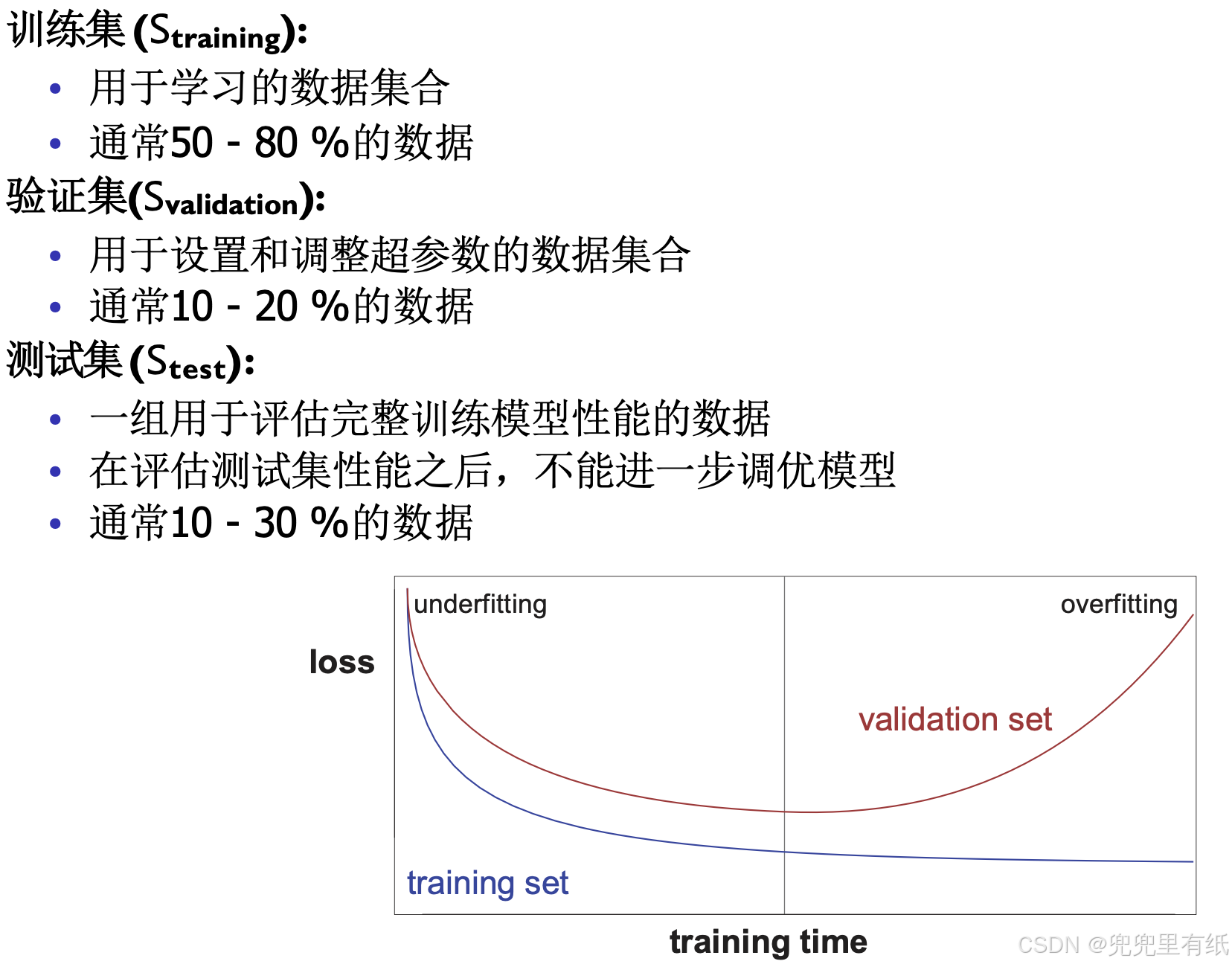
样本集的划分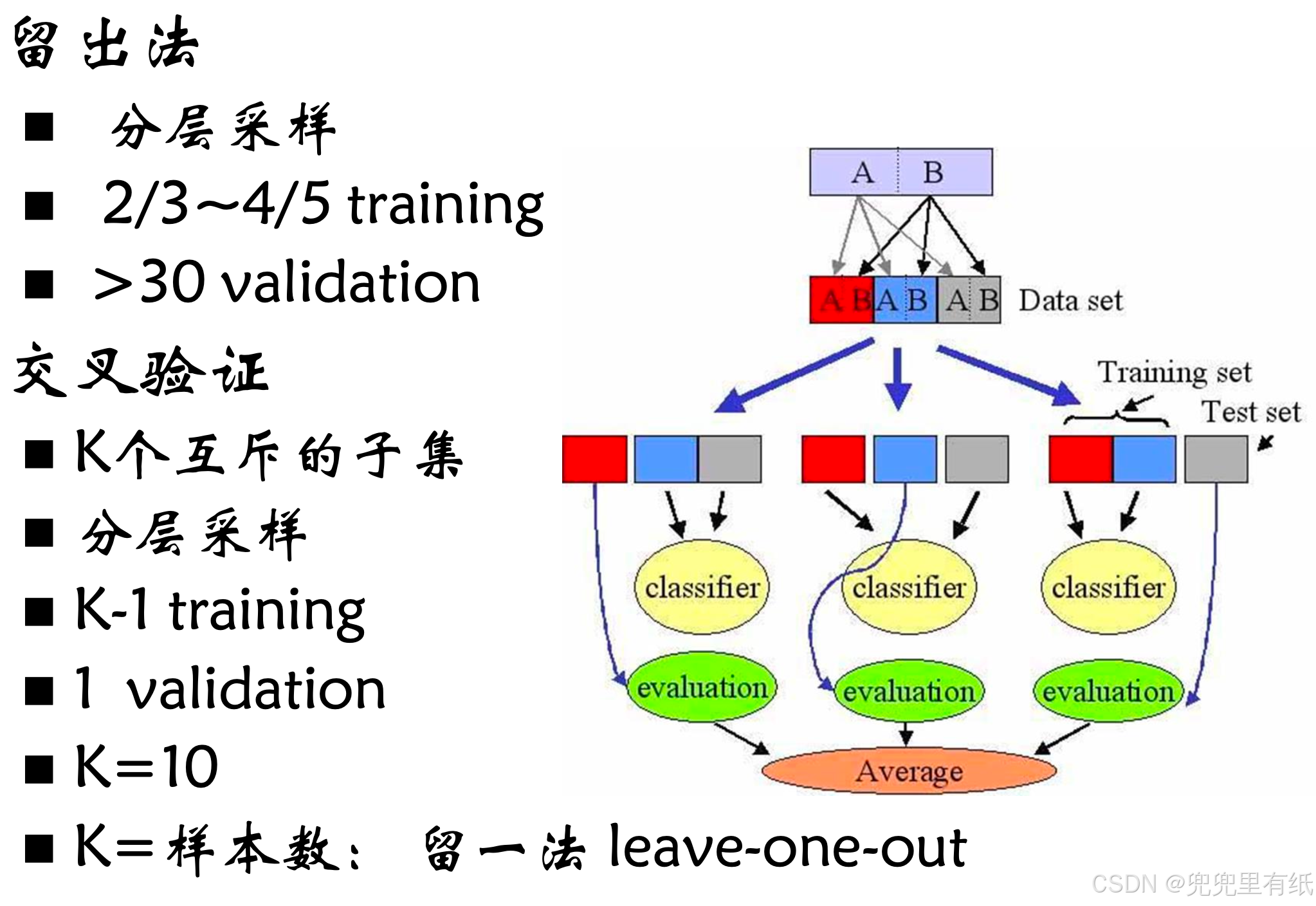

性能评价指标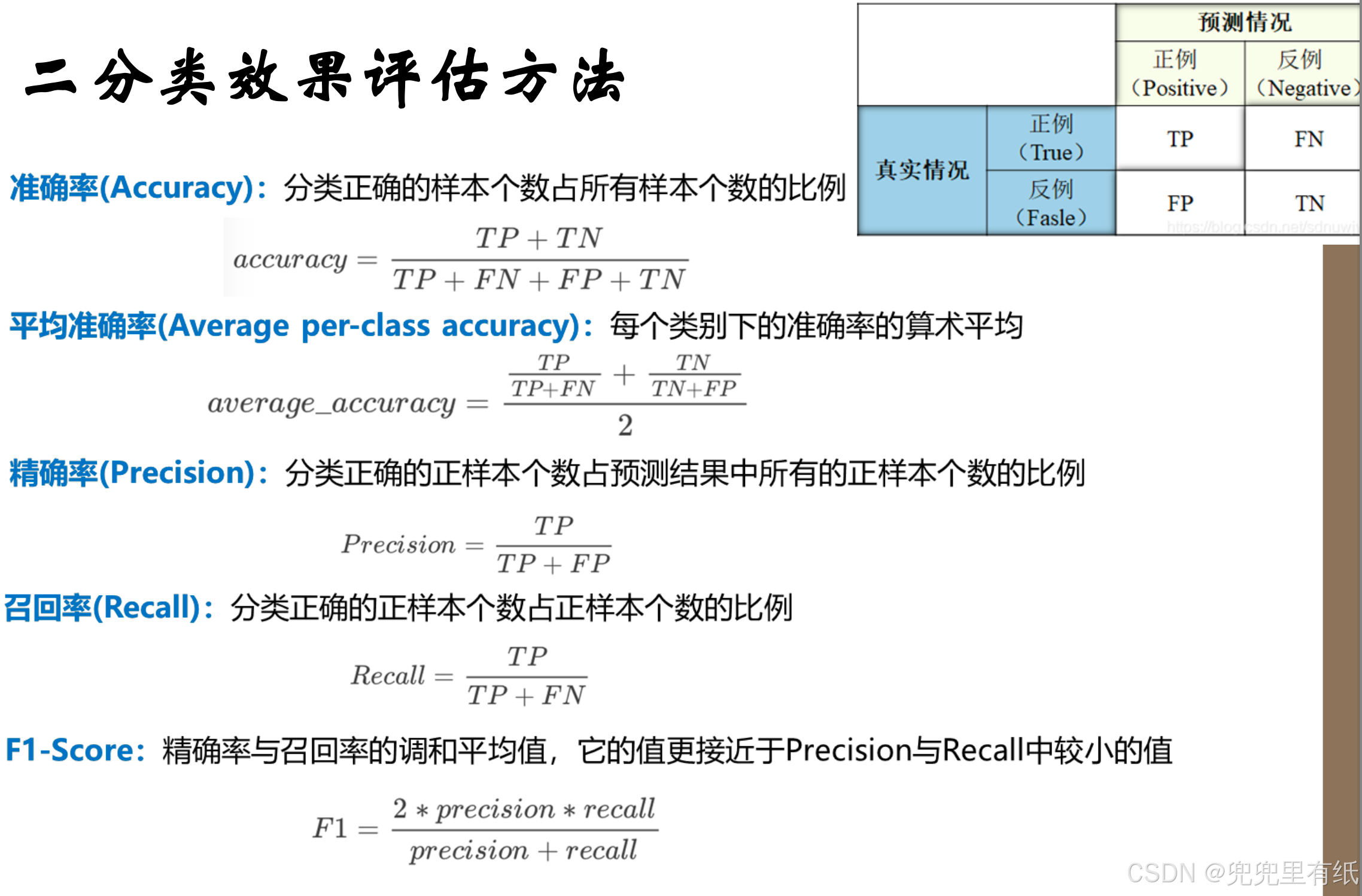
AUC和ROC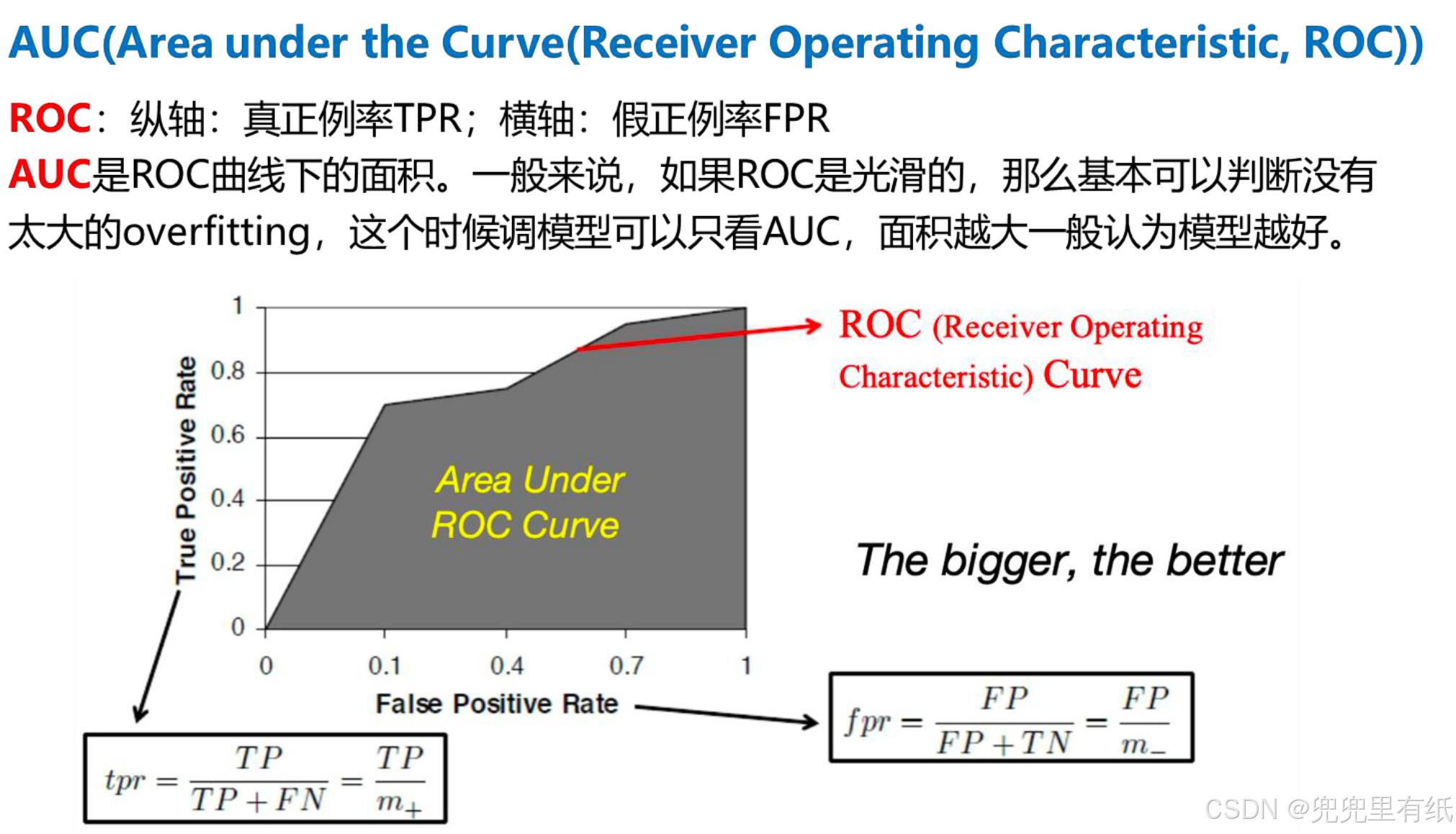

第四章 神经网络
什么是神经网络?
人工神经网络是一个并行、分布处理结构,它由处理单元及其称为联接的无向讯号通道互连而成。
神经网络的特点
◼ 并行结构和并行处理
◼ 知识的分布存储
在神经网络中,知识不是存储在特定的存储单元,而是
分布在整个系统中,要存储多个知识就需要很多连接。
要获得存储的知识则采用“联想”的办法,这类似于人
类和动物的记忆。
联想记忆的两个主要特点:
✓存储大量复杂数据的能力
✓自适应的特征抽取能力
✓快速的推理能力
◼ 容错性
◼ 自适应性
M-P模型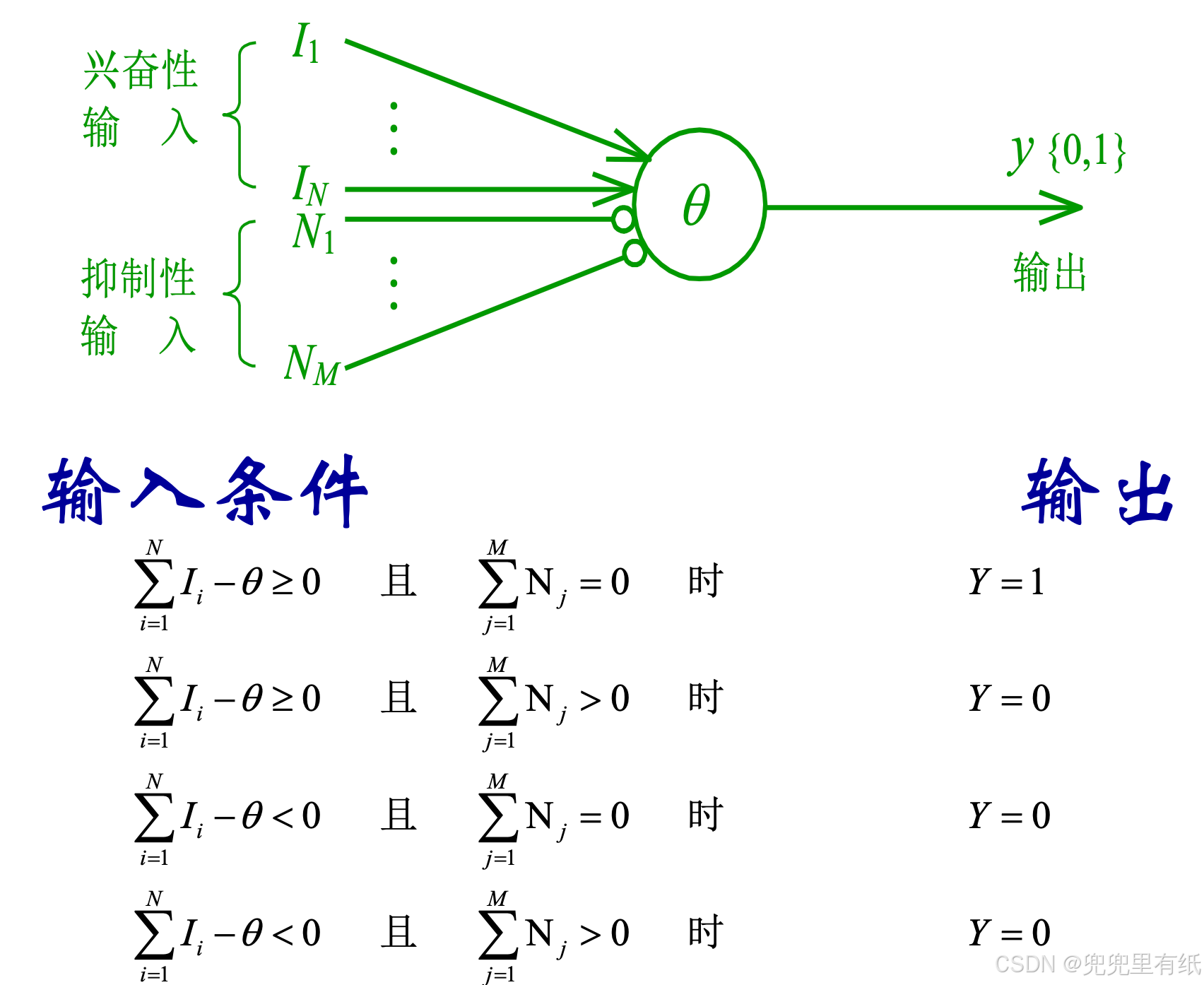
线性加权模型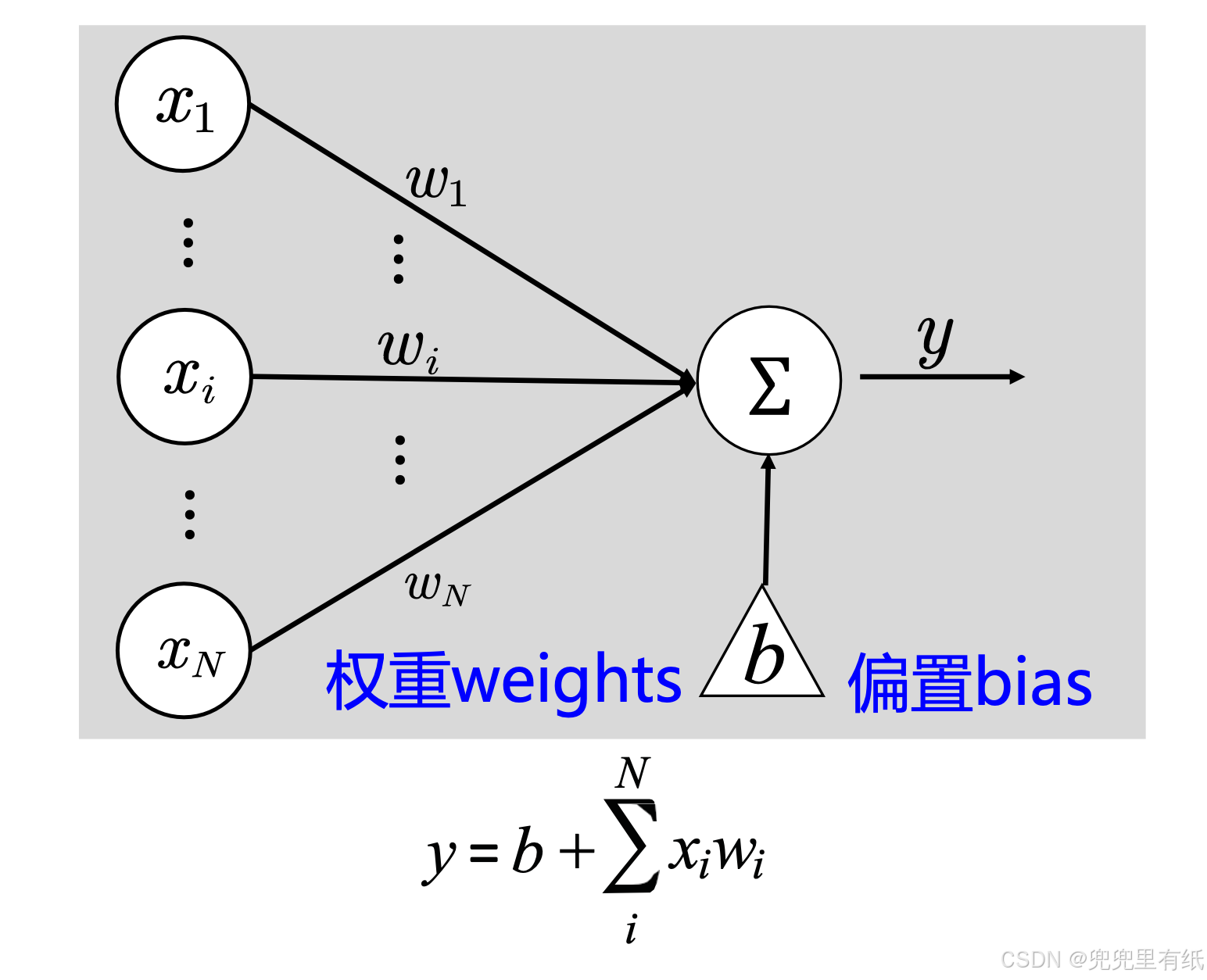
阶跃阈值模型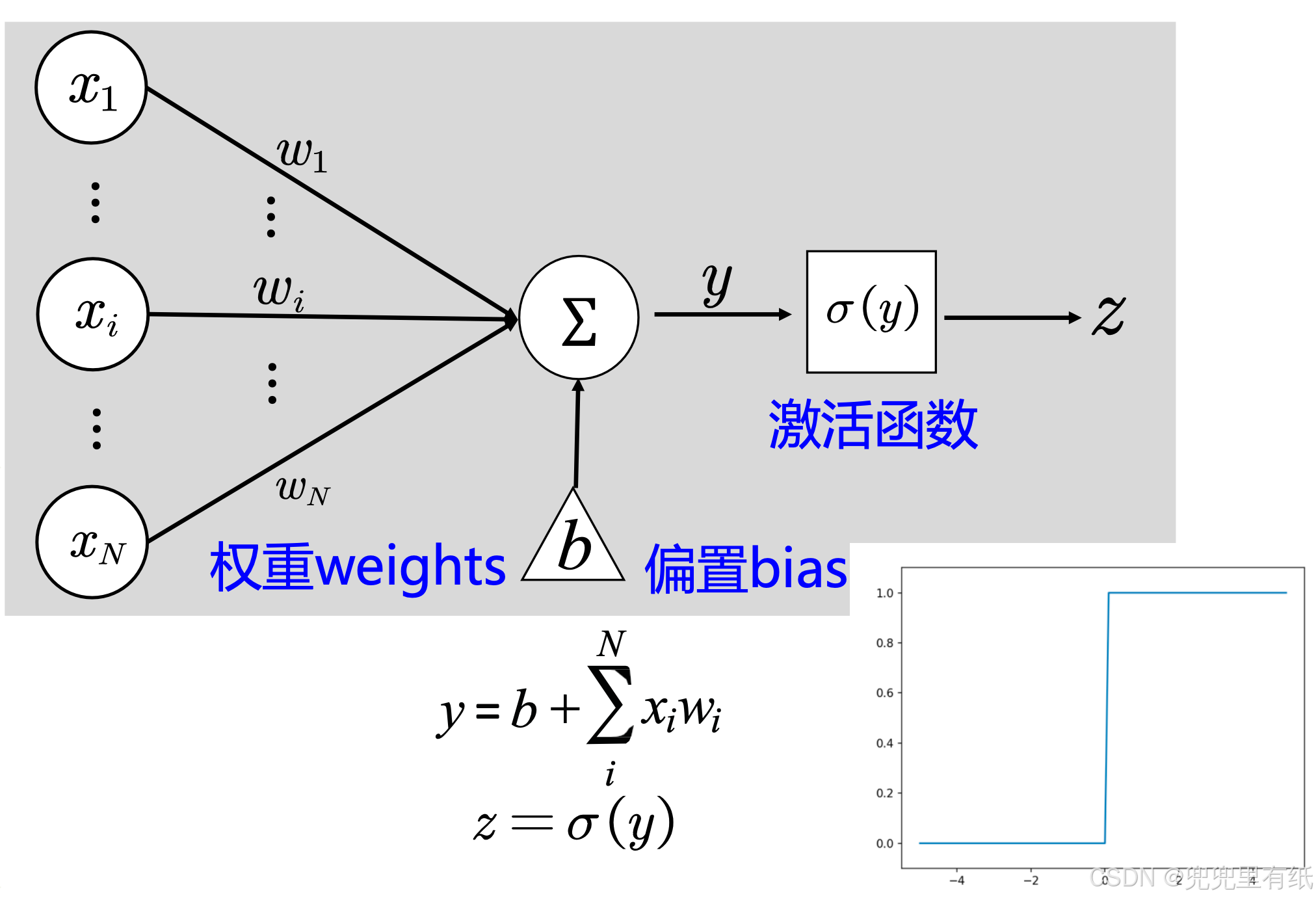
感知机
损失函数
第五章 径向基函数与自组织特征映射神经网络
完全径向基(RBF)神经网络主要解决插值问题
第六章 支持向量机(重重点)
支持向量机(SVM)的概念与原理
基本模型是定义在特征空间上的间隔最大的线性分类器
支持向量机还包括核技巧,这使它成为实质上的非线性分类器。
支持向量机的学习策略就是间隔最大化,可形式化为一个求解凸二次规划(convex quadraticprogramming)的问题
SVM的类型
核函数(kernel function)表示将输入从输入空间映射到特征空间得到的特征向量之间的内积;
• 通过使用核函数可以学习非线性支持向量机,等价于隐式地在高维的特征空间中学习线性支持向量机,这样的方法称为核技巧;

传统的统计模式识别方法在进行机器学习时,强调经验风险最小化。而单纯的经验风险最小化会产生“过学习问题”,其推广能力较差。
推广能力: 模型(即预测函数,或称学习函数、学习模型)对未来输出进行正确预测的能力。
过学习问题:模型训练精度高,而测试精度低、推广能力差的现象。
SVM如何克服过拟合问题
线性可分支持向量机
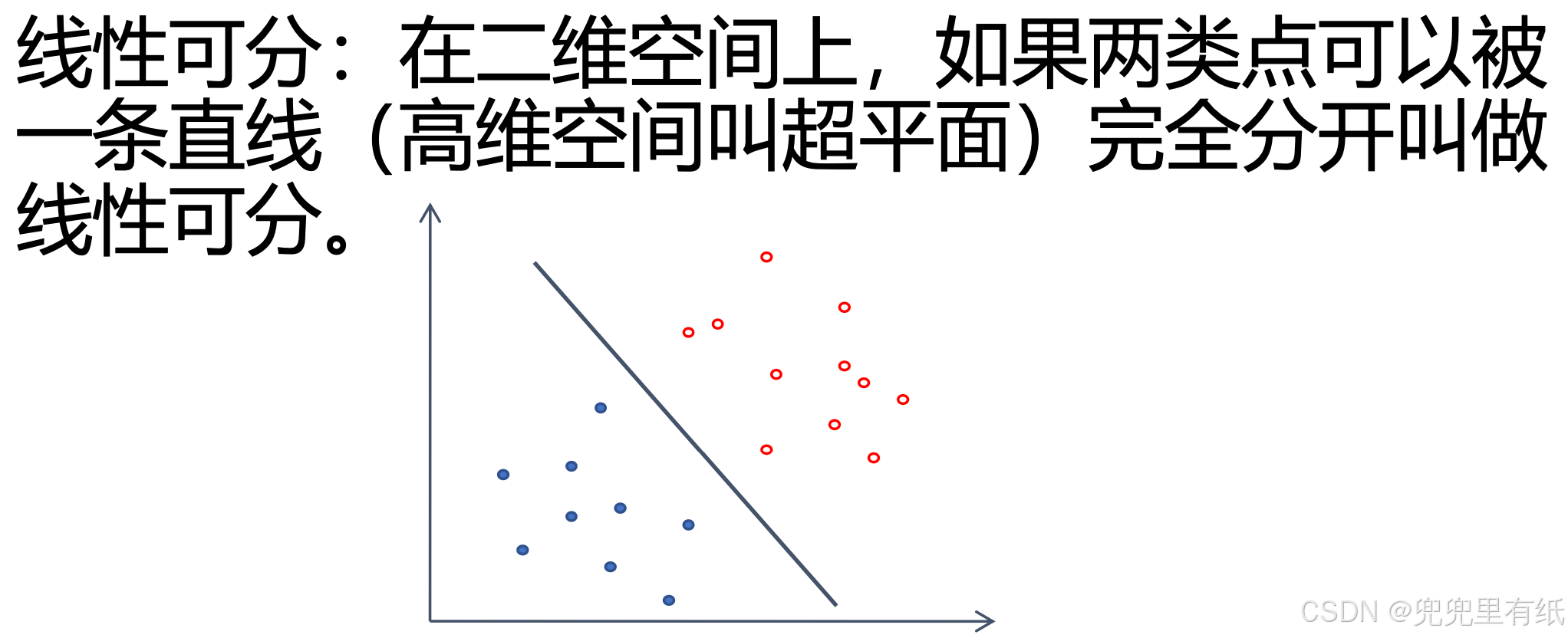
目标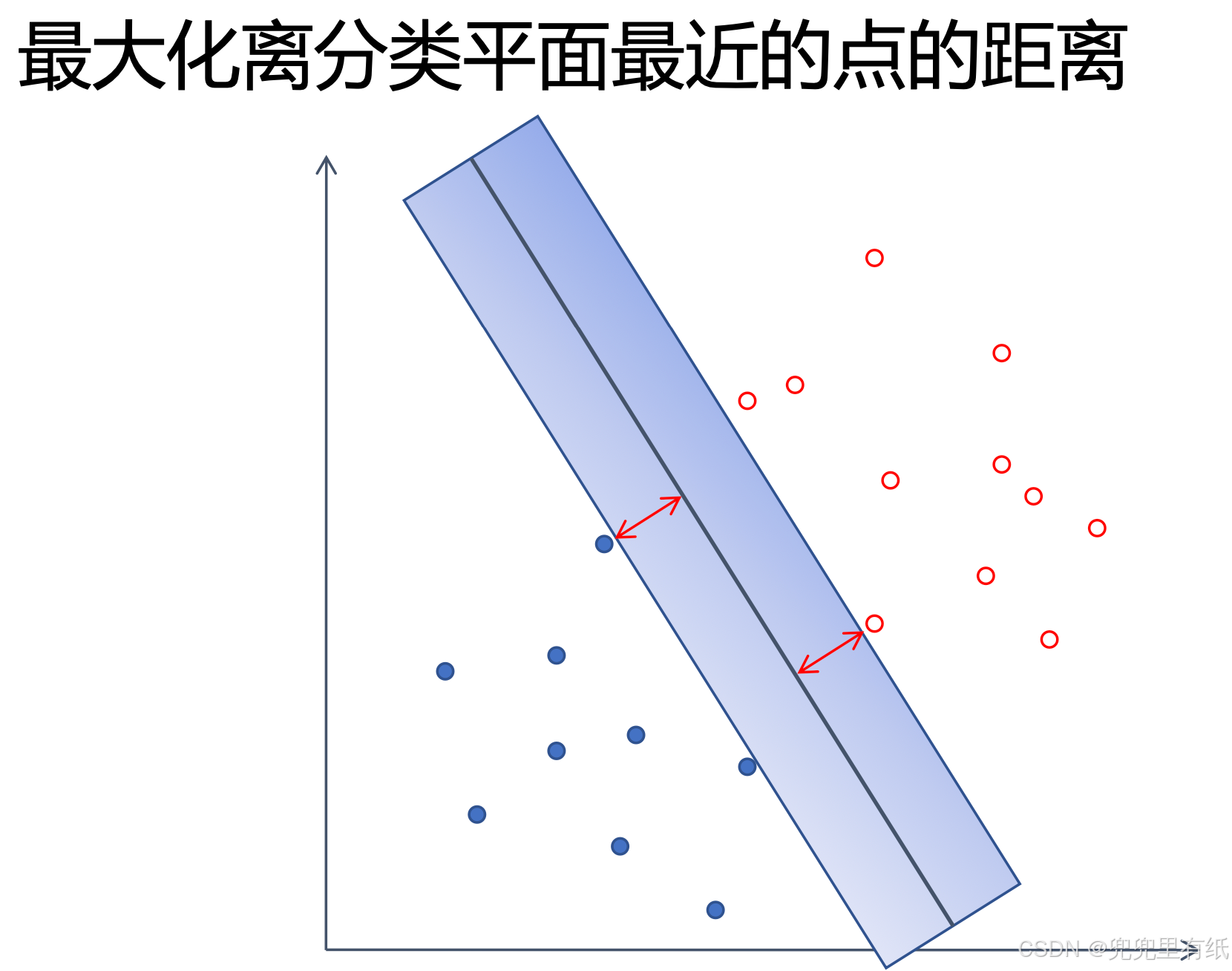
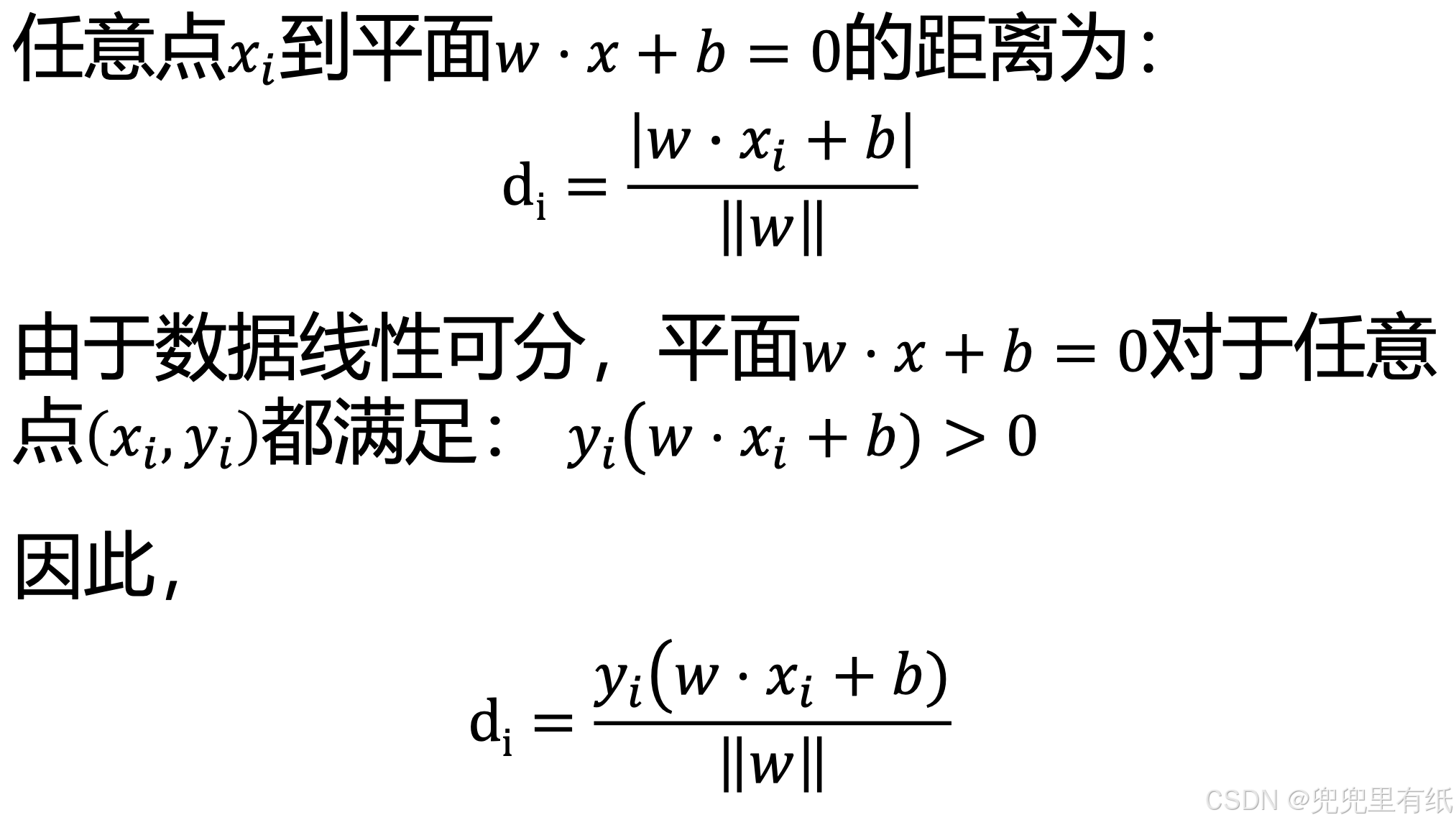
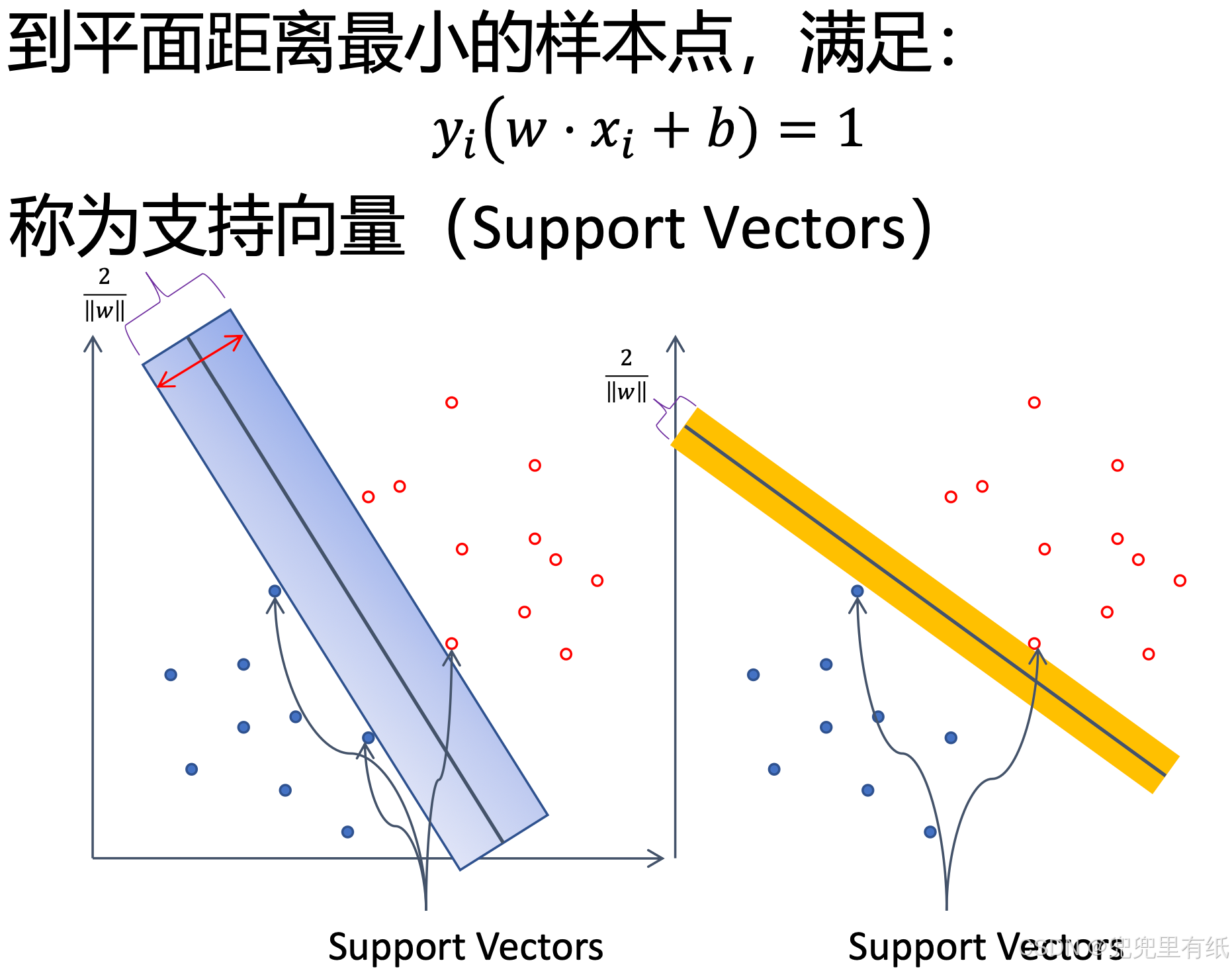
 (关键公式↑)
(关键公式↑)
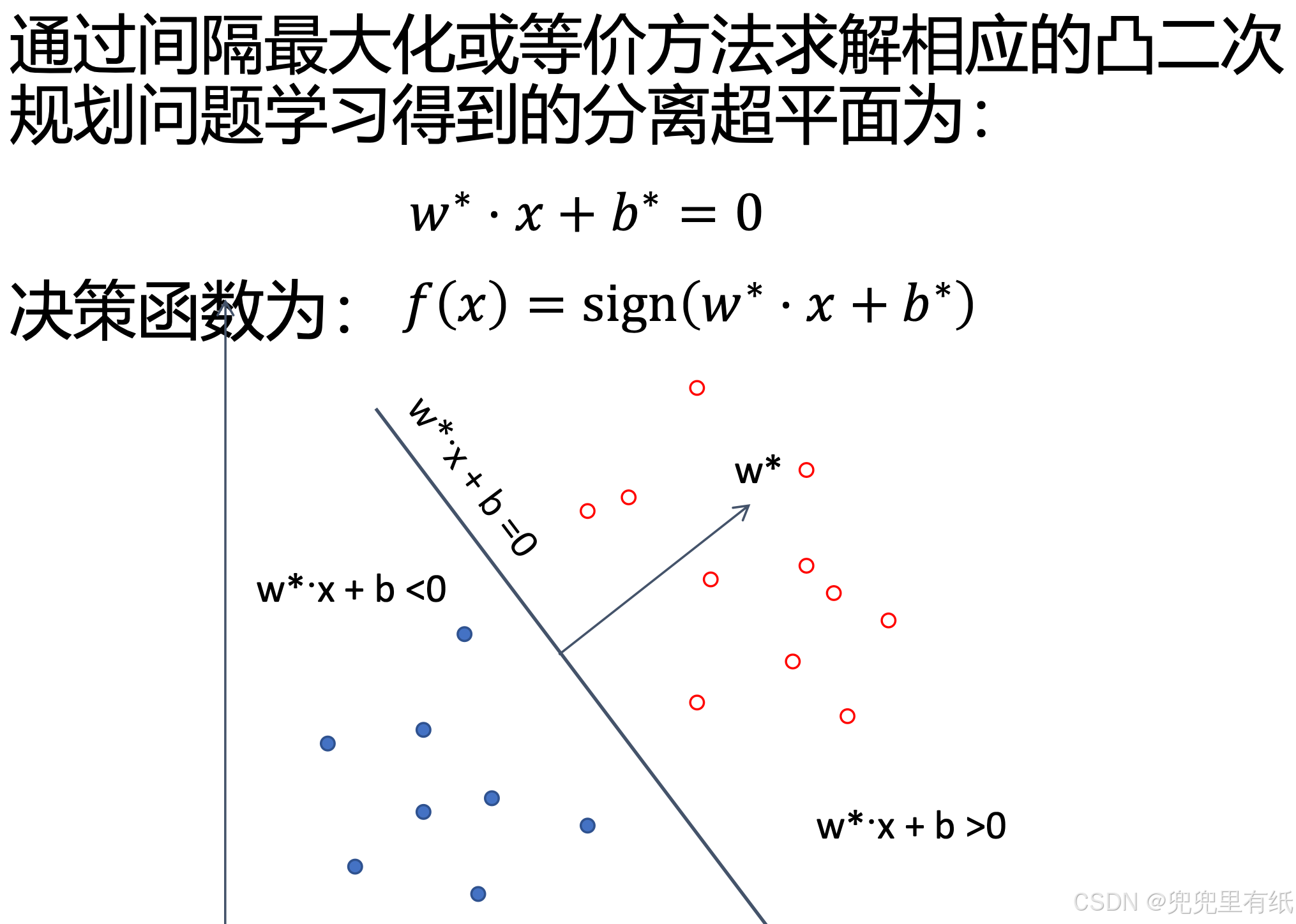
支持向量机的优化算法(大题)
求解对偶问题
求解线性可分支持向量机的步骤
1. 利用拉格朗日乘子法,构造拉格朗日函数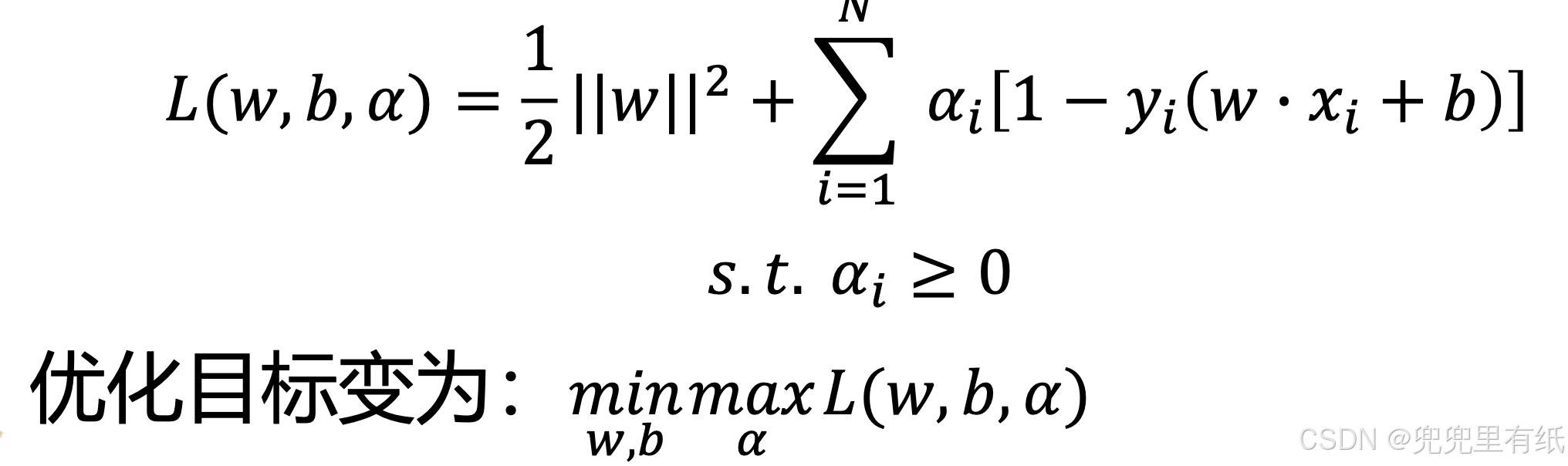
这一步其实真的很难理解,不过看样子PPT并没有把他当做重点来讲,而是一笔带过,不过还是推荐看一下详细的原理解释【数之道25】机器学习必经之路-SVM支持向量机的数学精华_哔哩哔哩_bilibili
2. 利用强对偶性(KKT)将优化问题进行转化,并求解
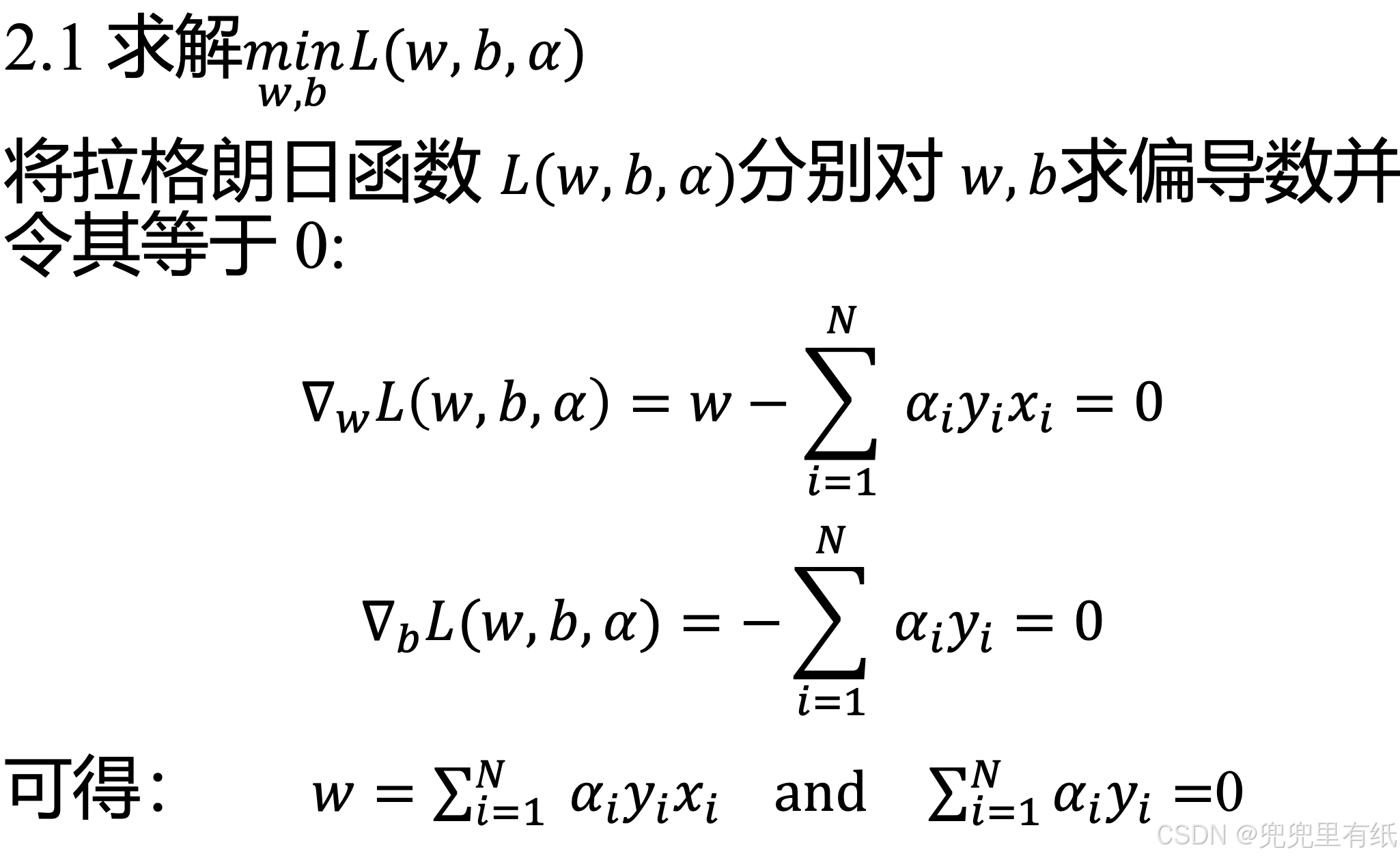
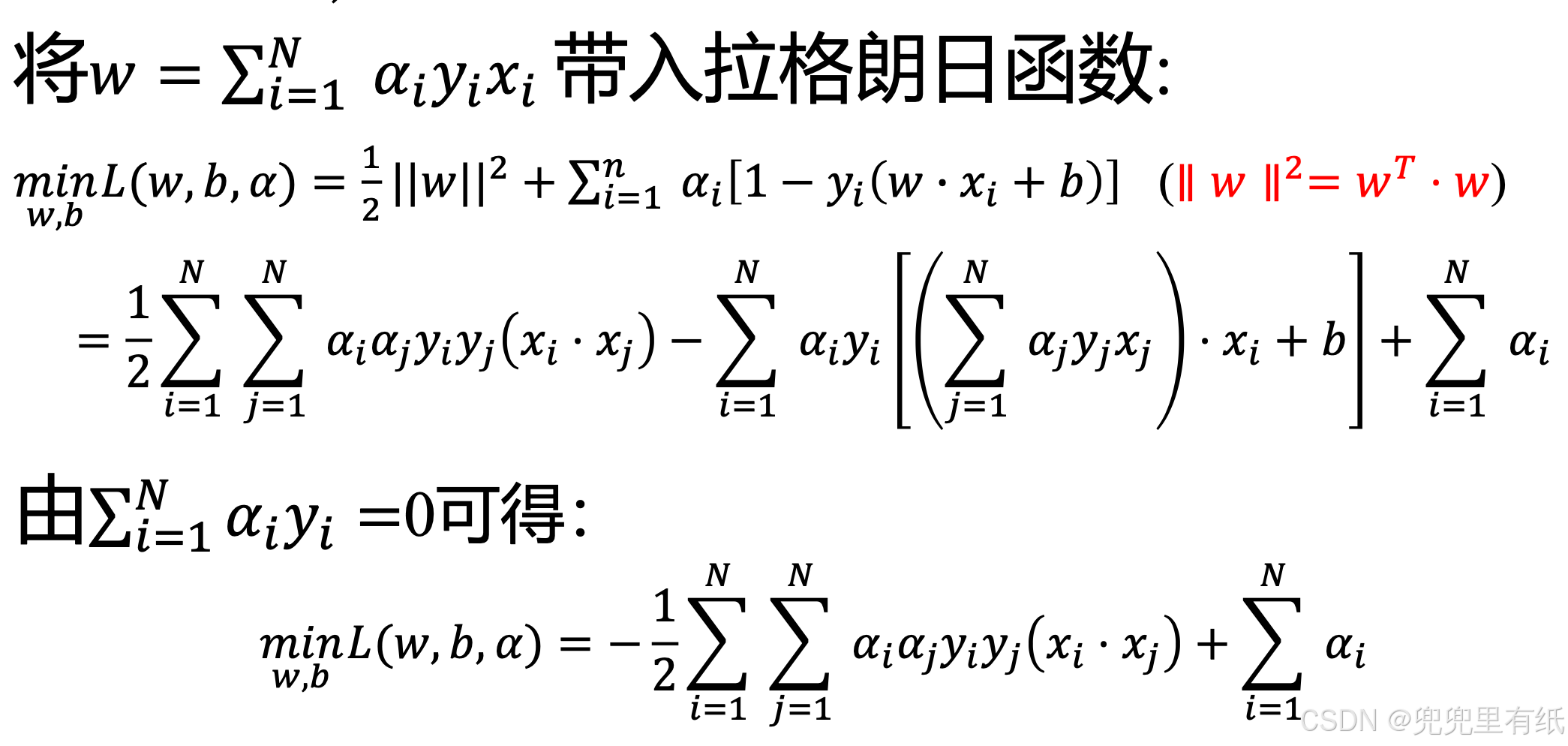


SVM的分解算法
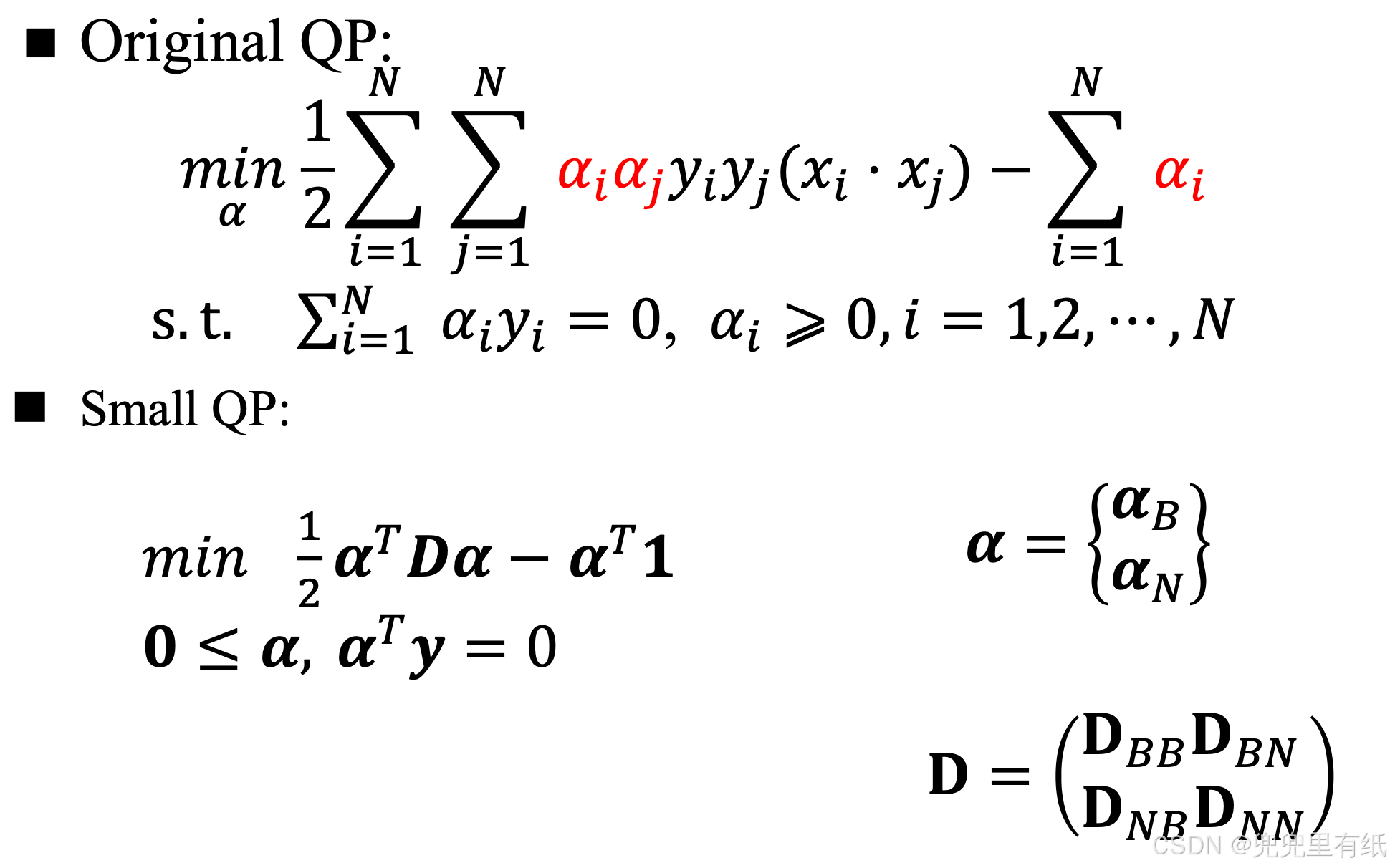
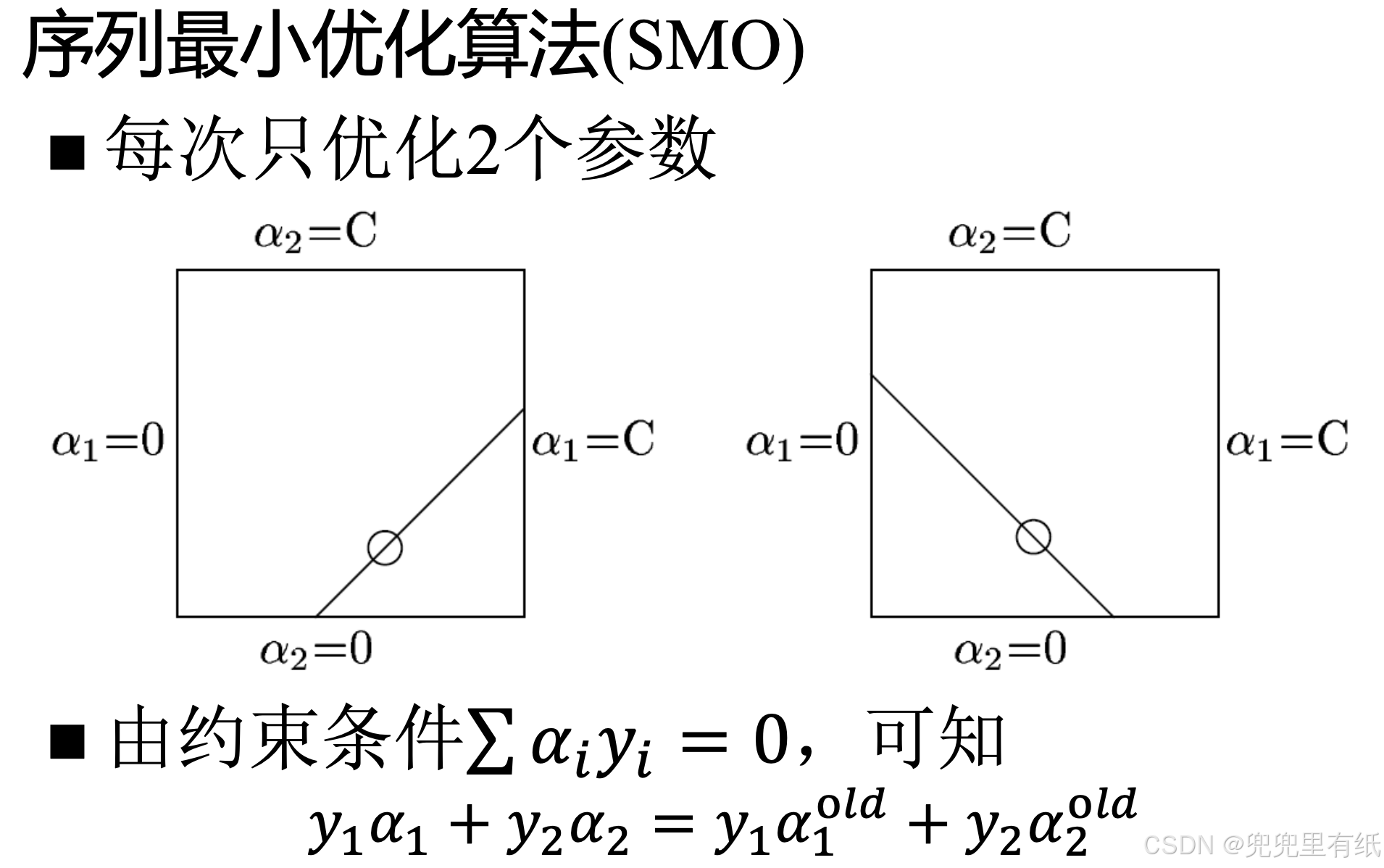
S'M'O's'm

线性支持向量机—软间隔最大化
软间隔最大化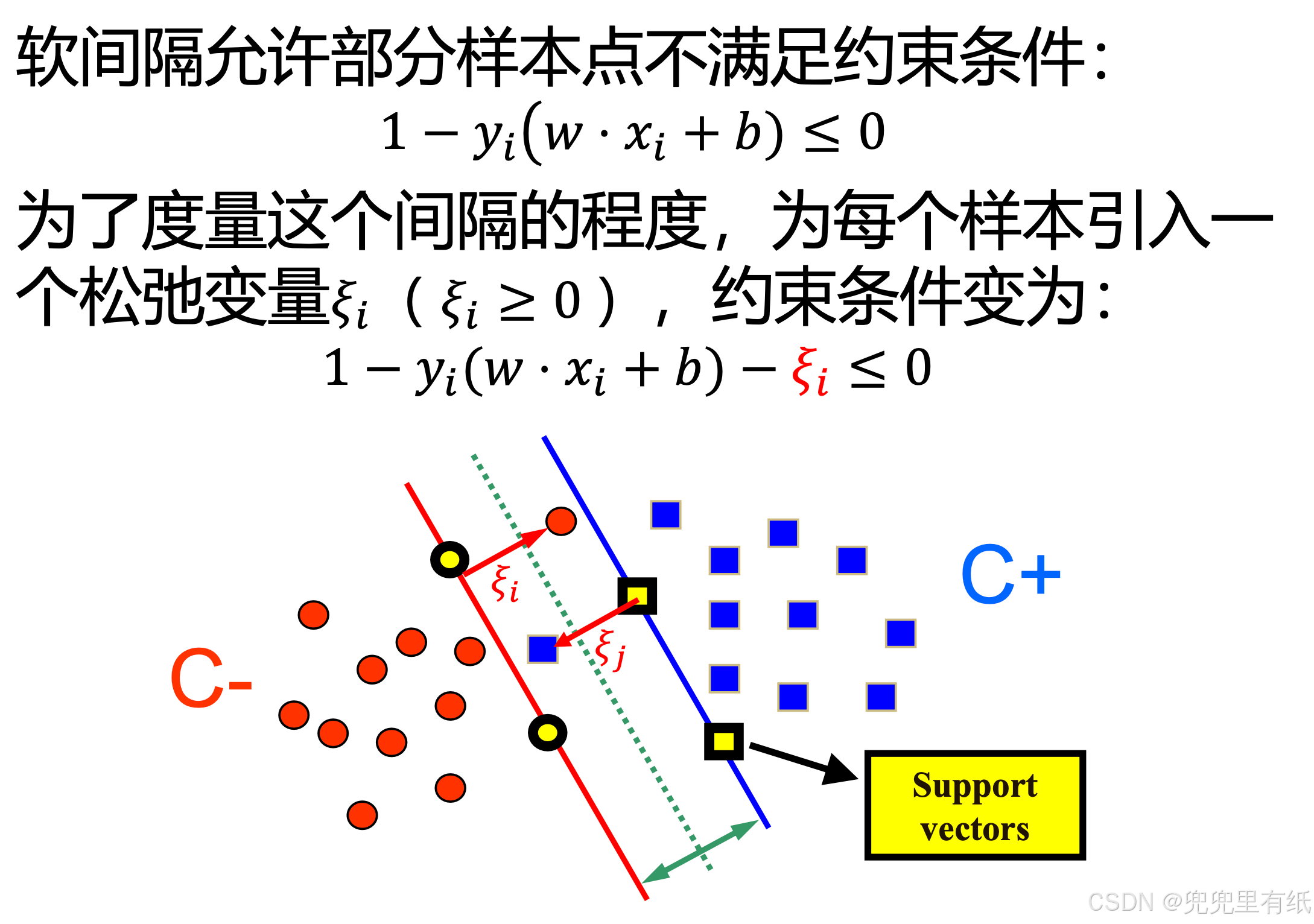





非线性支持向量机——核方法(大题)
可以先看一下这个SVM核方法--这是我见过最好的一个视频。。核技巧核函数_哔哩哔哩_bilibili

#先跳一下,实在是太难理解了
SVR回归
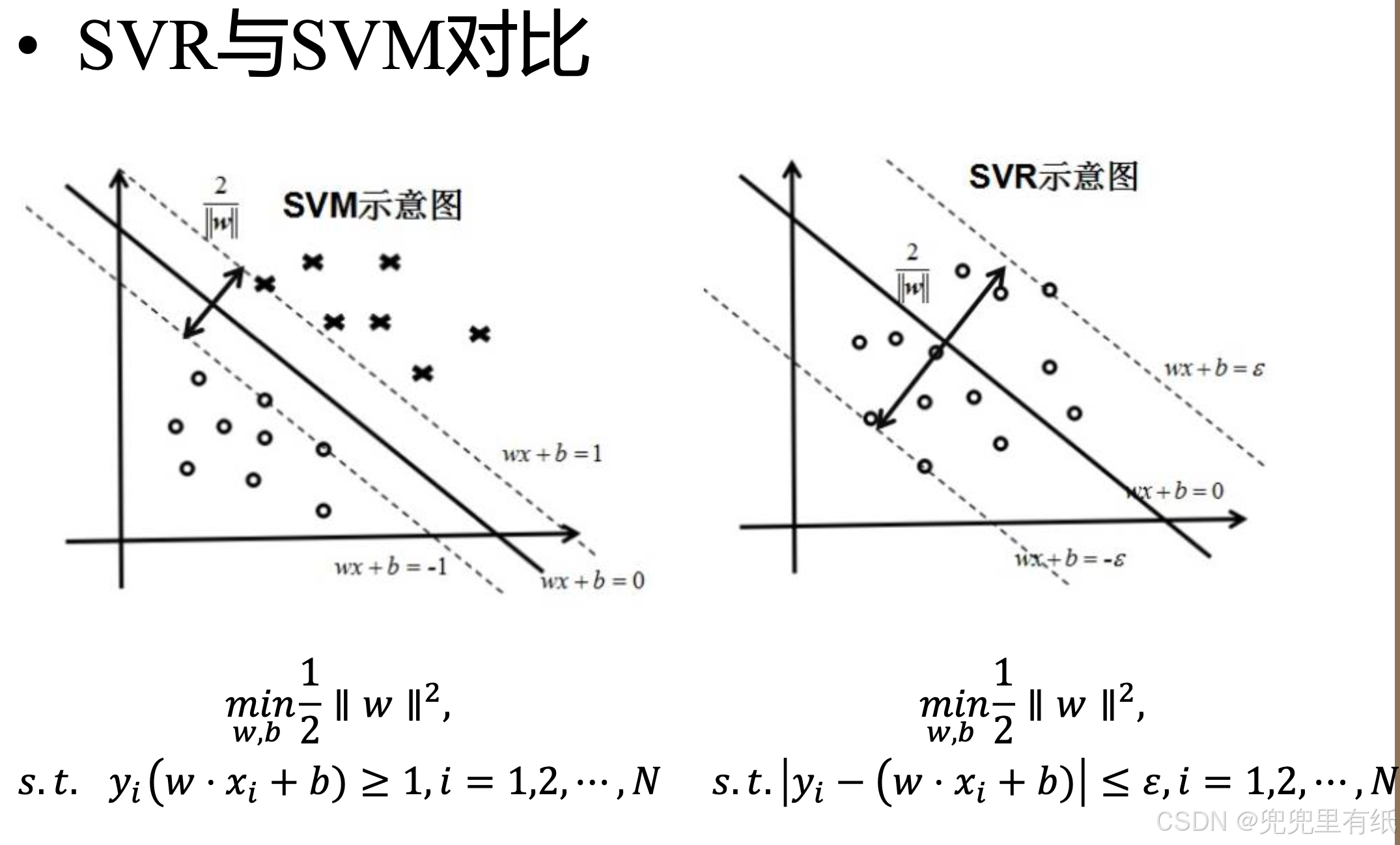
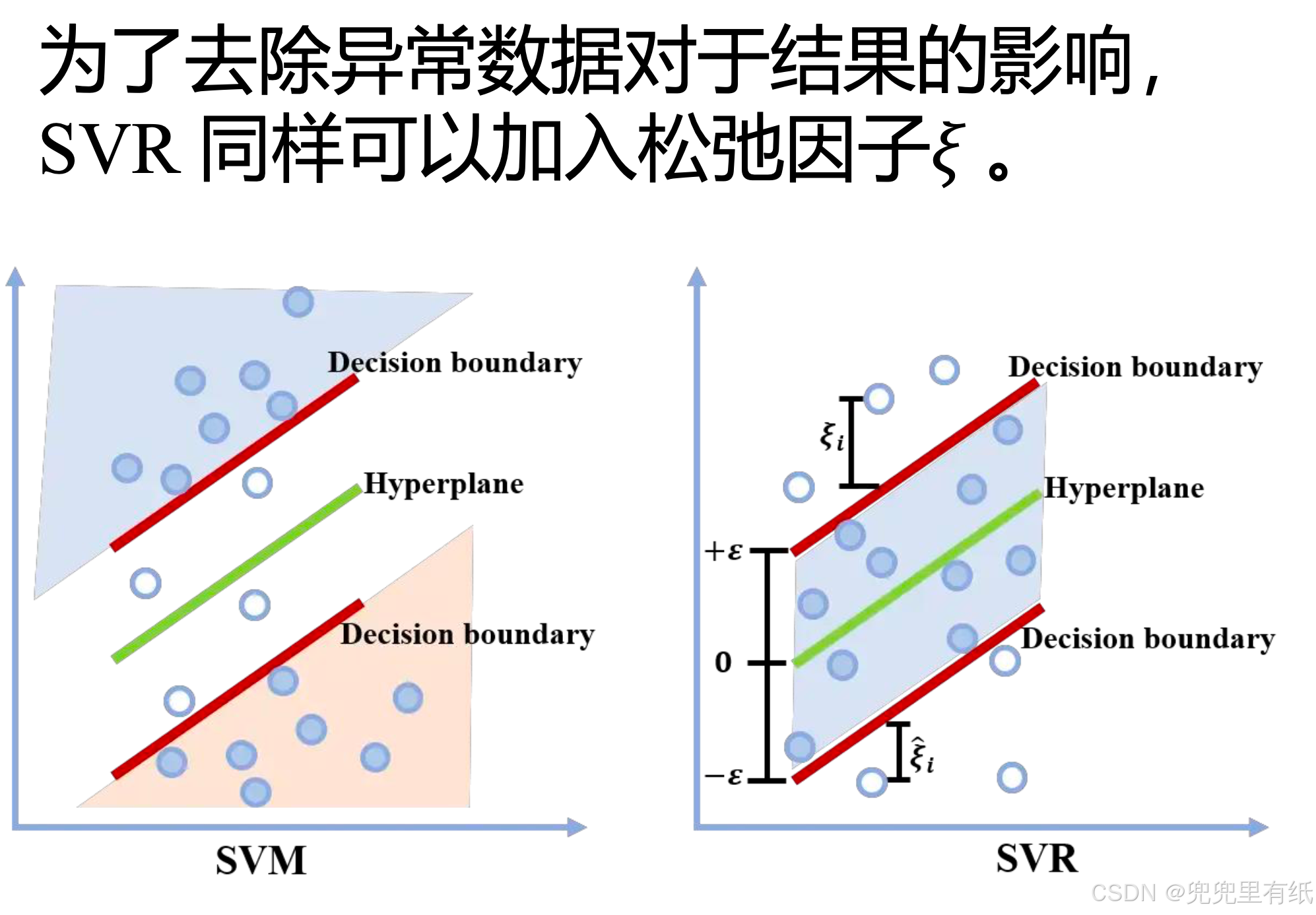


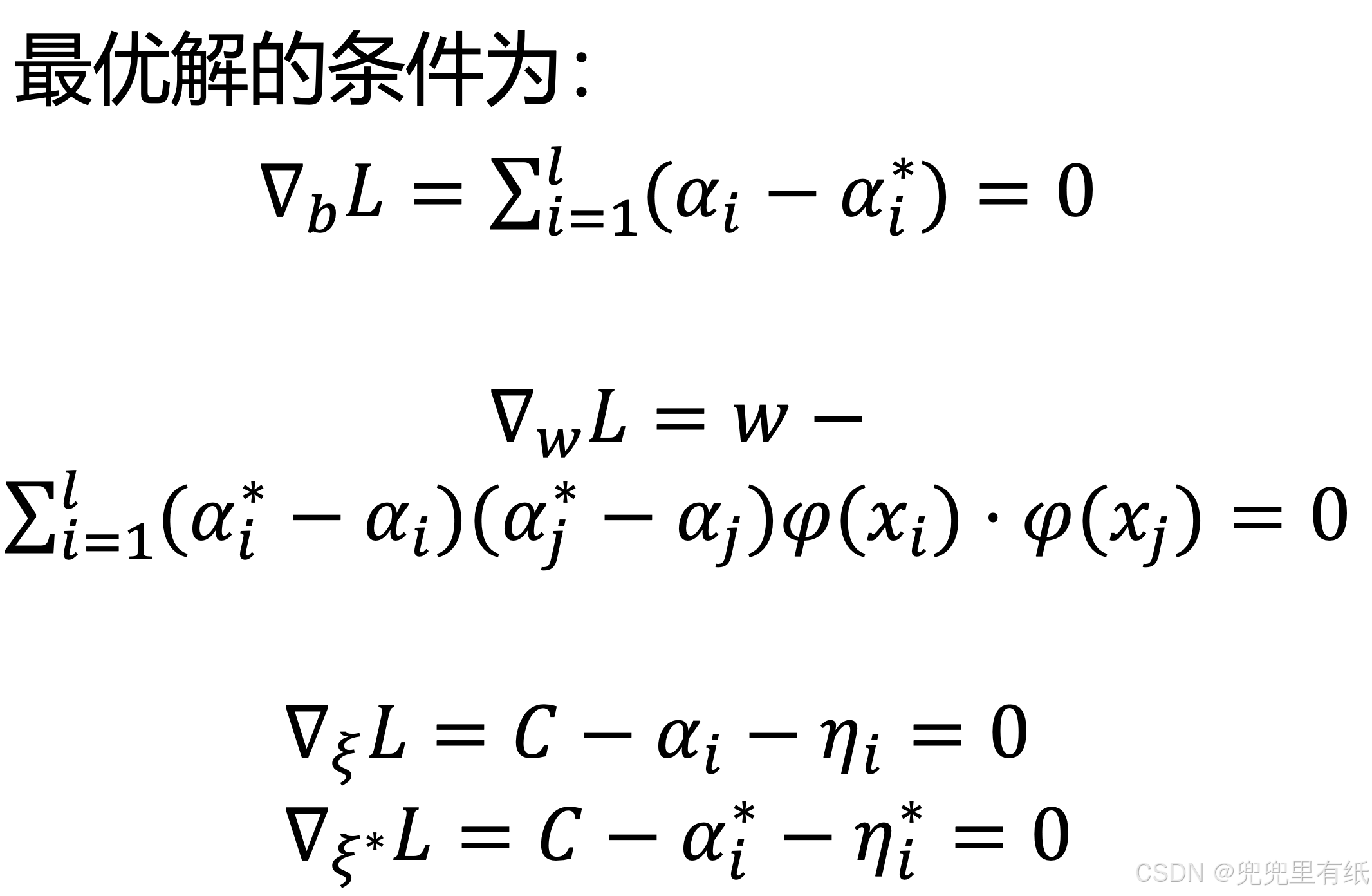


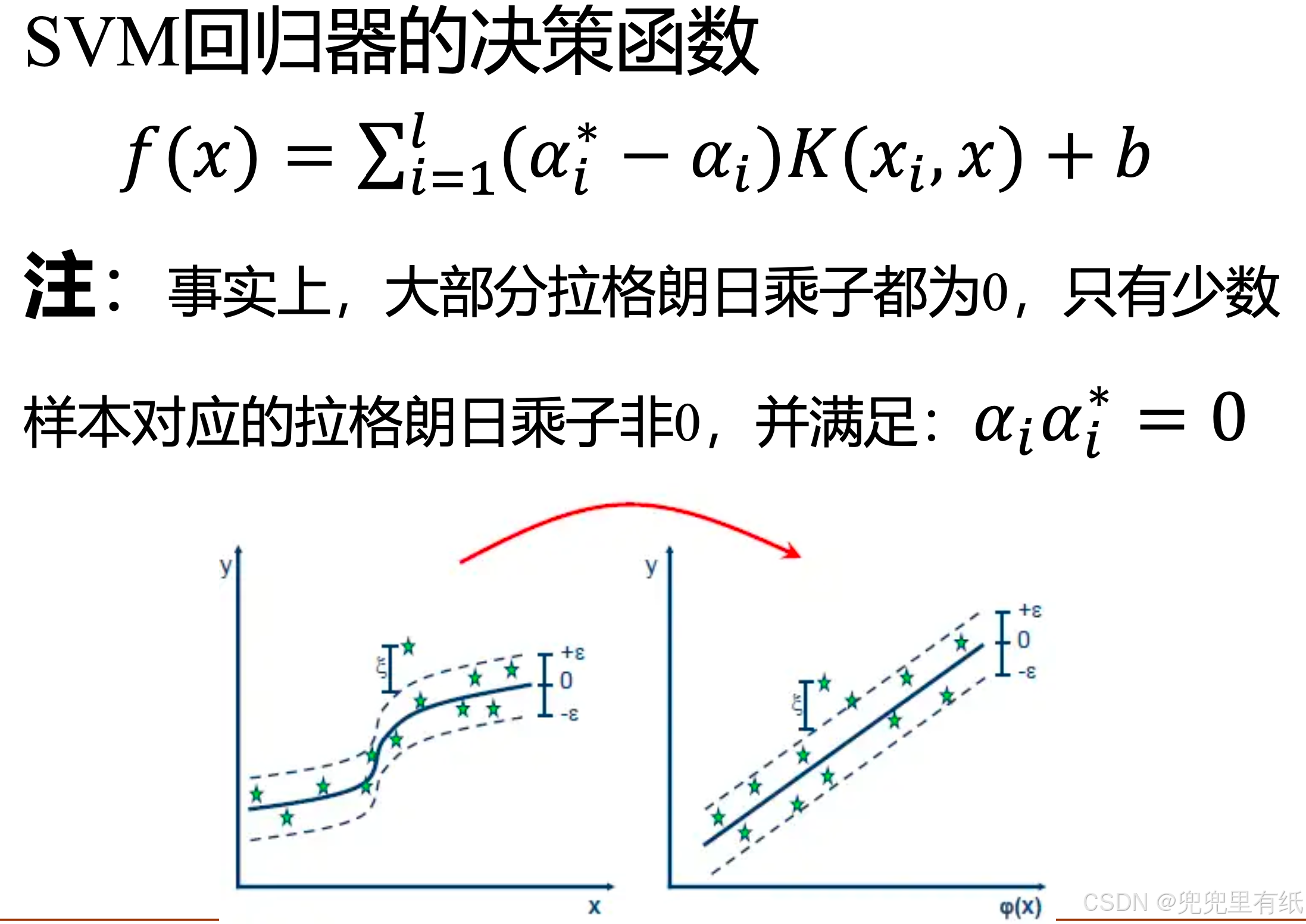
第七章 聚类问题(重点)
聚类问题概述
聚类(Clustering)是最常见的无监督学习算法,它指的是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。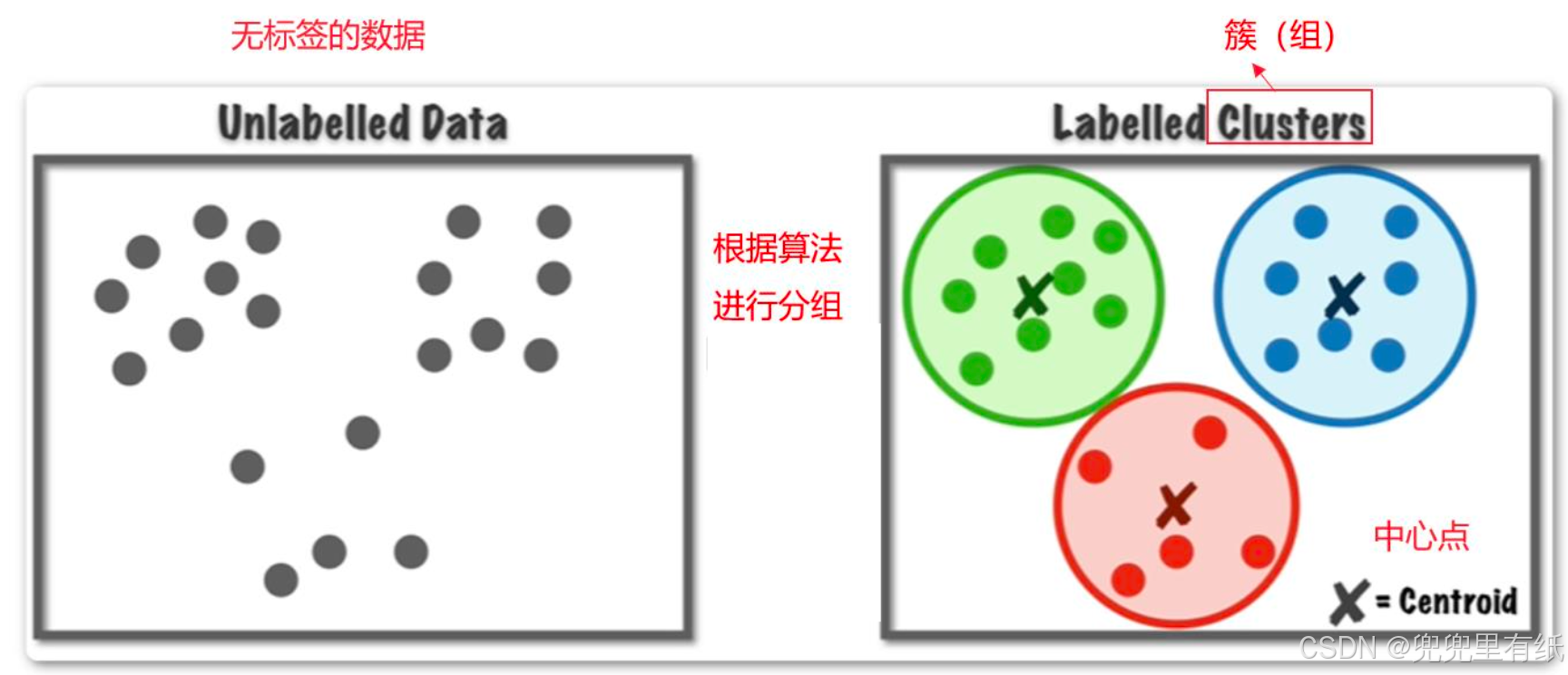
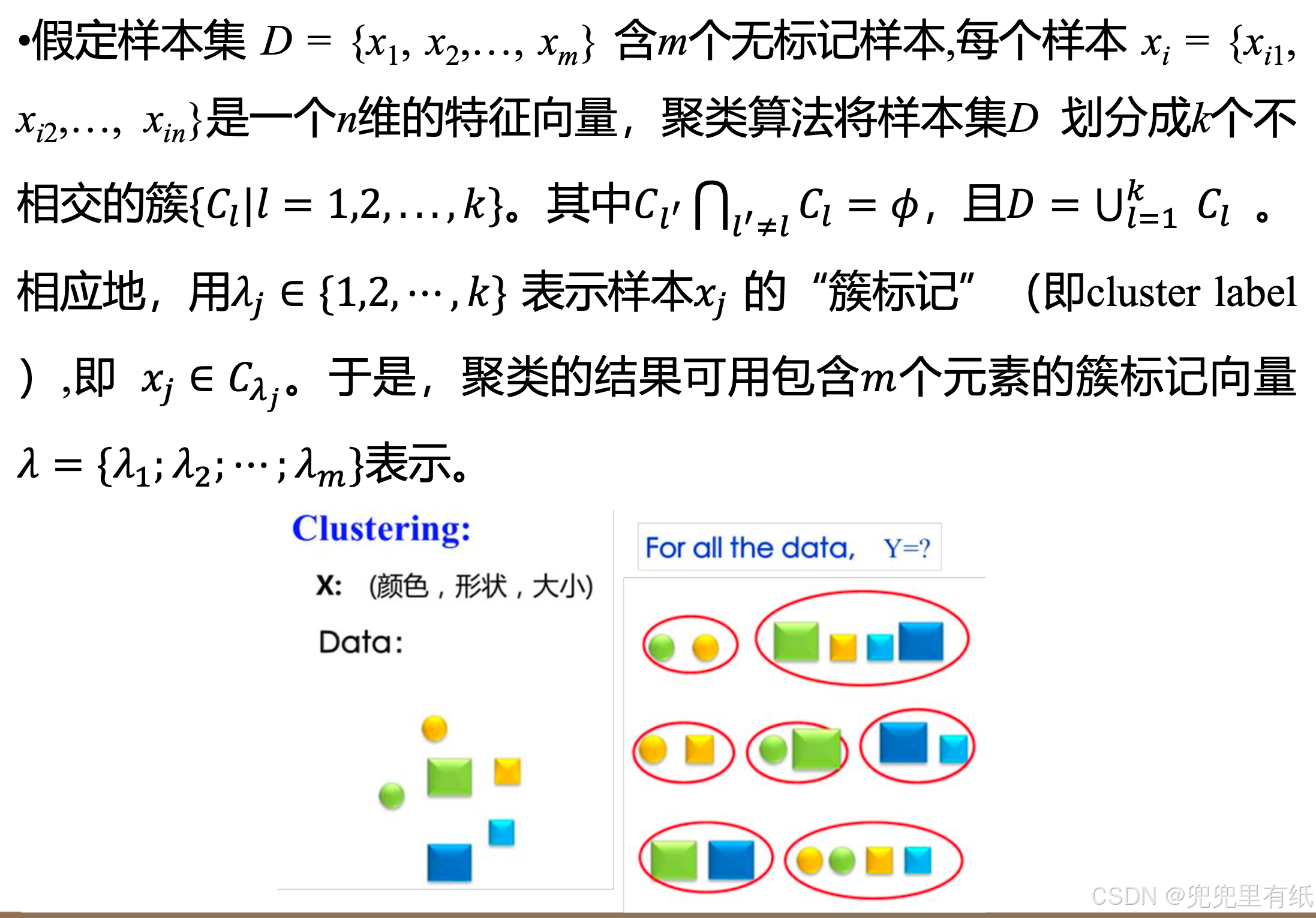
聚类过程中需要解决哪些问题?
1. 定义数据间的距离/相似度度量;
2. 使用相应的算法对数据集进行分割;
3. 度量聚类结果的性能。
聚类算法的类型
◼ 划分聚类(K-means、K-medoids等)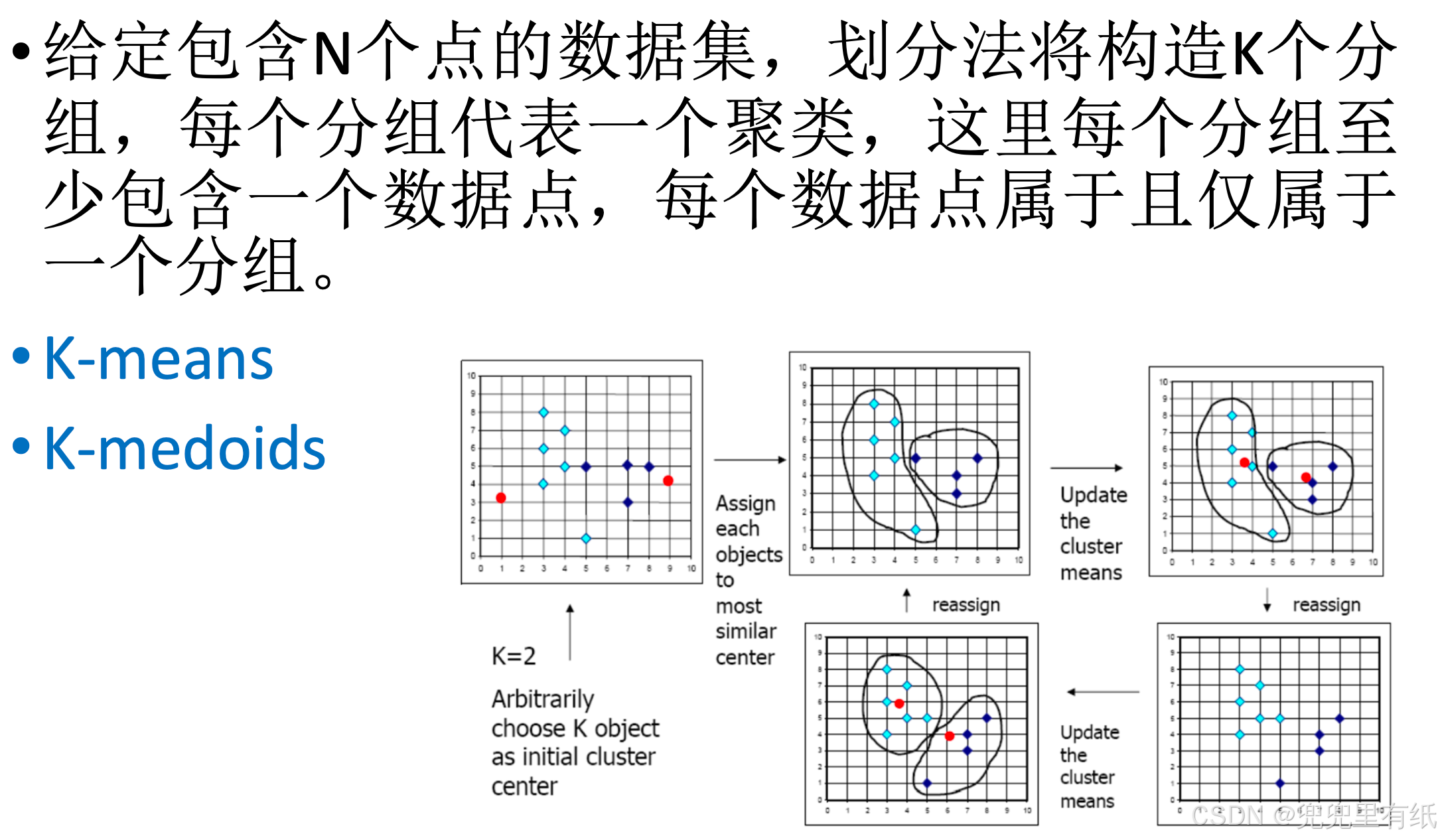
◼ 层次聚类(凝聚法、分裂法)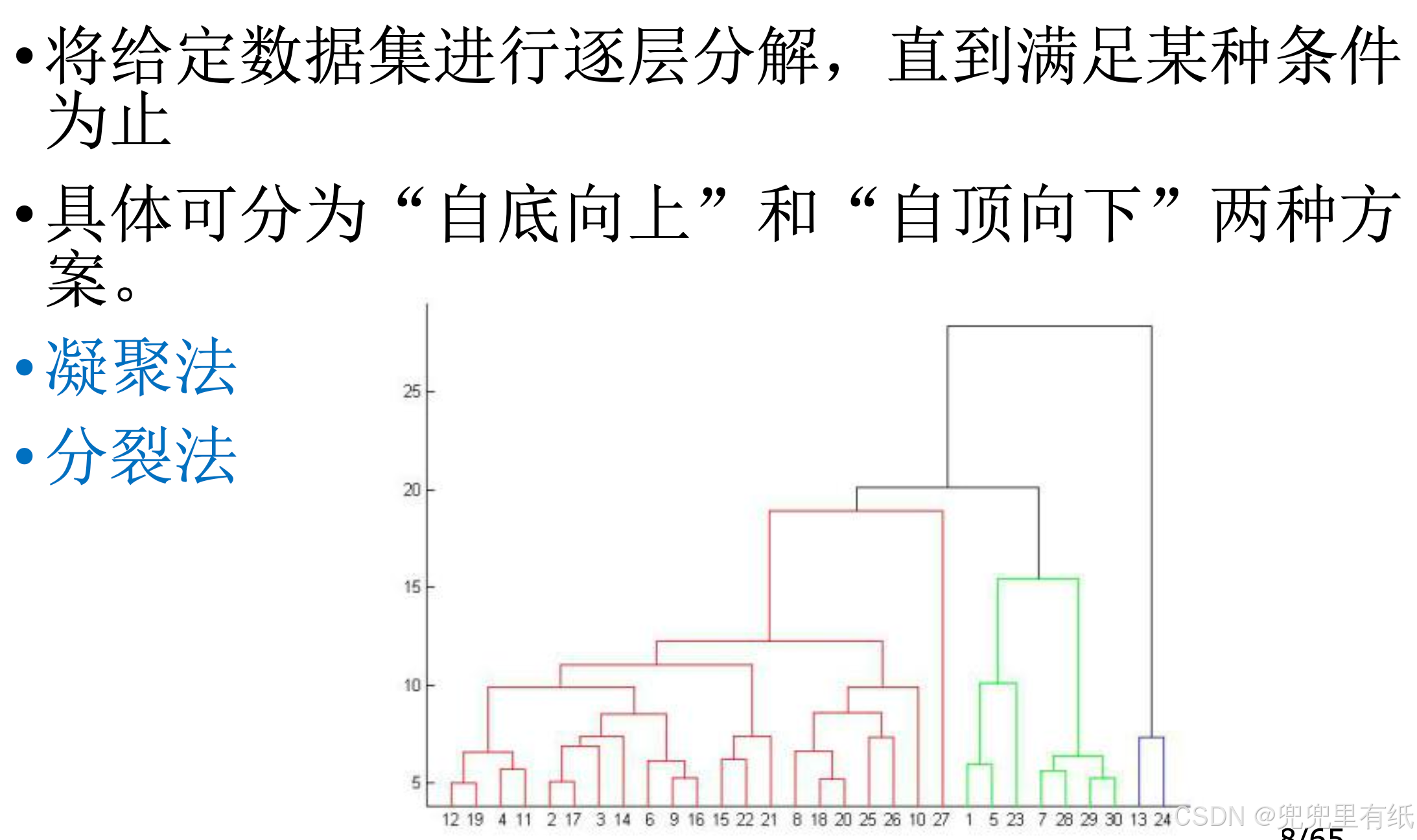
◼ 密度聚类(DBScan、 基于密度峰值算法)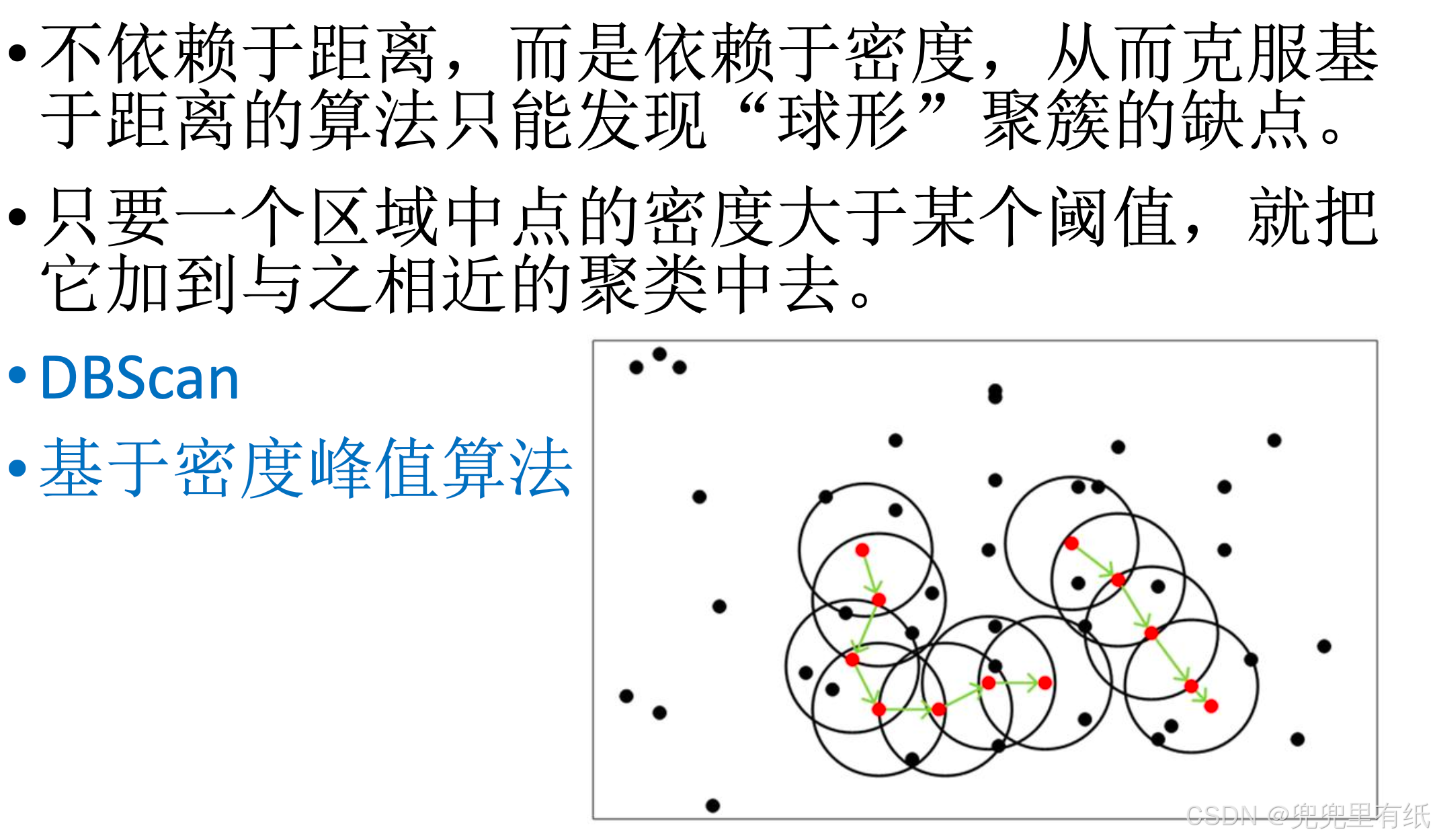
◼ 网格法(STING、CLIQUE)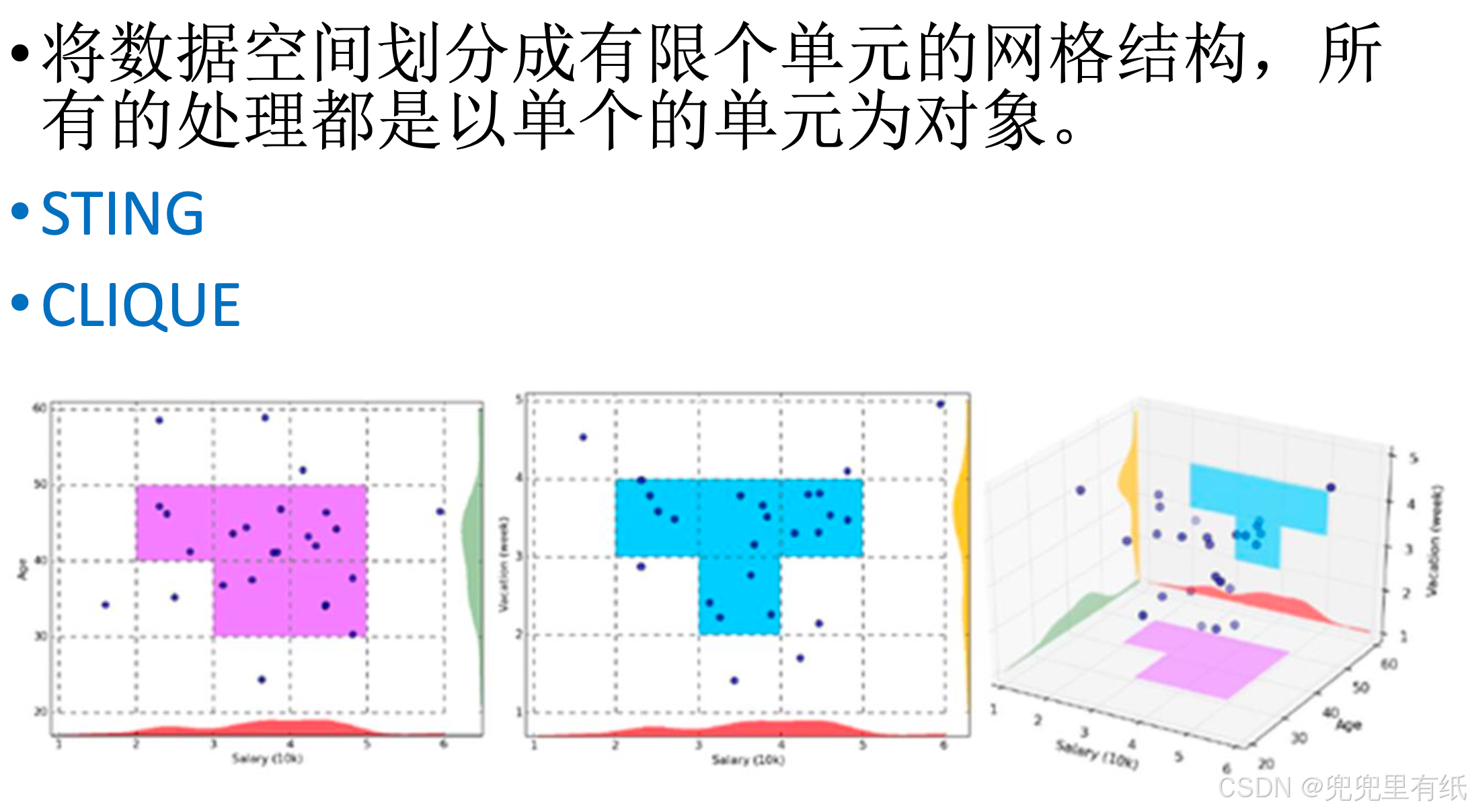
◼ 模型法(概率模型:高斯混合模型Gaussian MixtureModels ;神经网络模型:SOM;吸引子传播算法:AP聚类)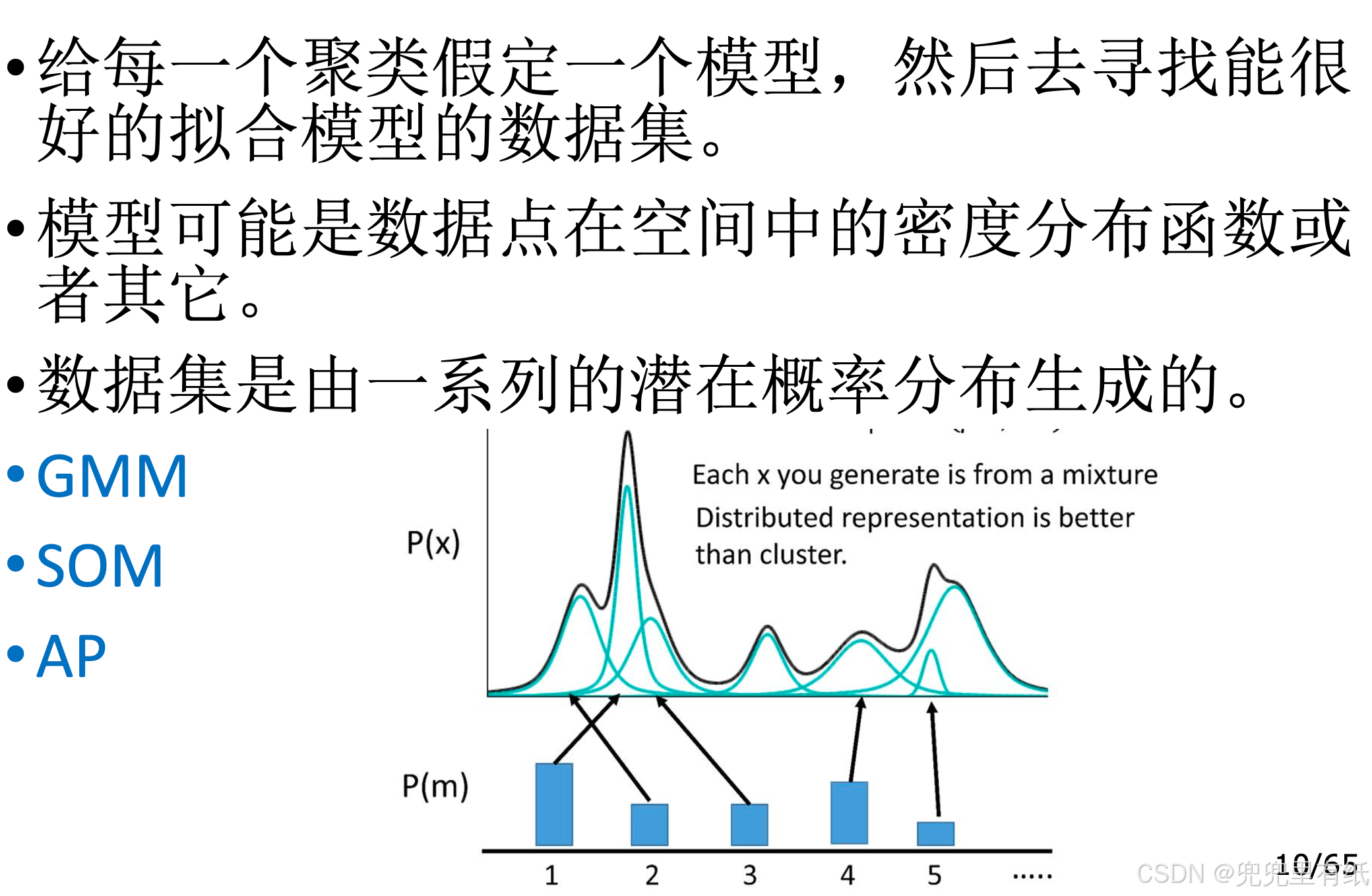
◼ 谱聚类
划分聚类
• K-means聚类,也称为K-平均或K-均值聚类
• K:是最终簇数量(即:K 往往代表类别的个数),它是超参数,需要预先设定
• means:在算法计算中会涉及到求均值
K-means 算法的流程
1. 随机选择 K 个簇中心点(可以选已有的数据作为中心点,也可直接选
高维空间中的位置)
2. 样本被分配到离其最近的中心点
3. K 个簇中心点根据所在簇样本,以求平均值的方式重新计算
4. 开始迭代,重复第2步和第3步直到所有样本的分配不再改变
K-means 的损失函数
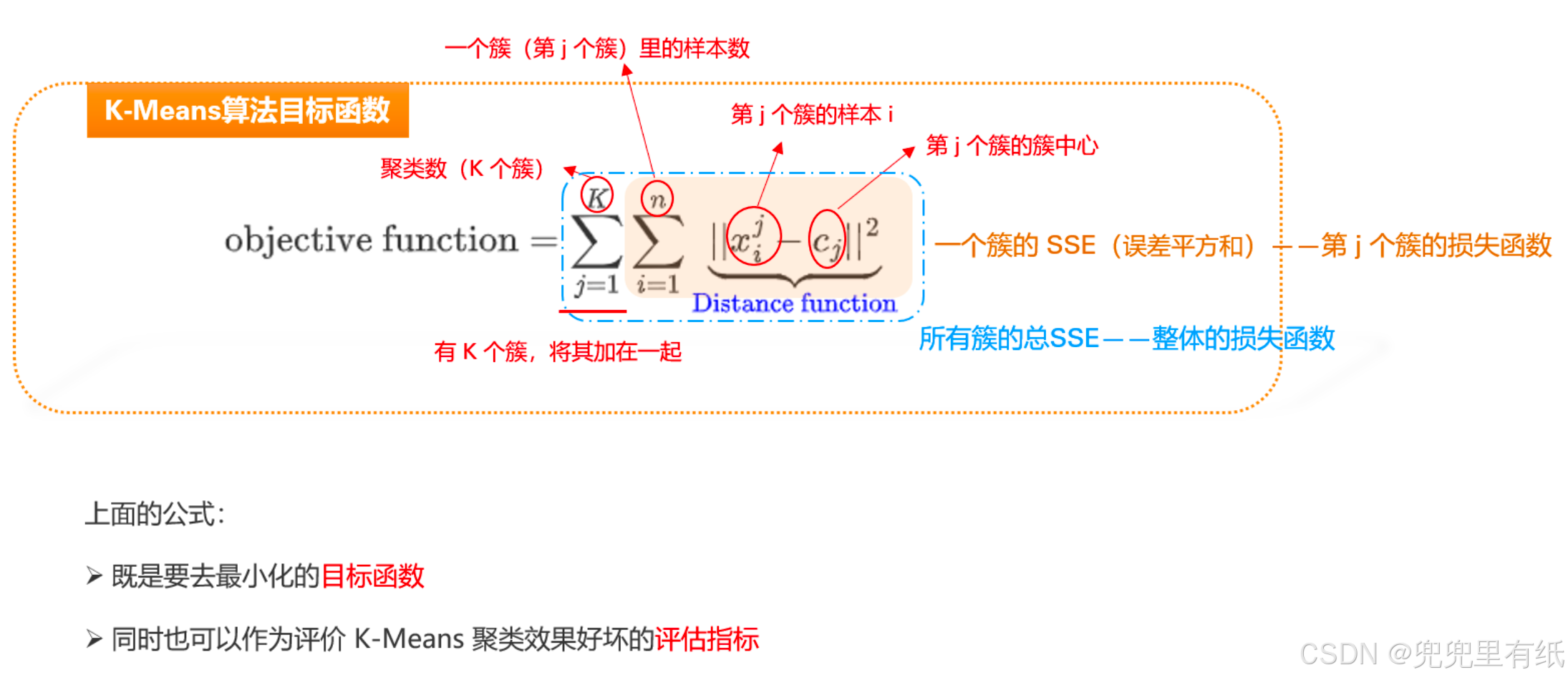
K-means算法 K 的选择(肘部法(elbow method))
• 目标:(找到最合适的点——拐点)
• 找到一个聚类数目,使得K高于该值之后的损失变换会发生显著递减;
• 这个 K 值,称为肘部点(elbow point),因为它看起来像一个人的肘部。
优点:
◼ 是解决聚类问题的一种经典算法,简单、快速
◼ 对处理大数据集,该算法保持可伸缩性和高效率
◼ 当结果簇是密集的,它的效果较好
• 缺点
◼ 只适合对数值型数据聚类
◼ 必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。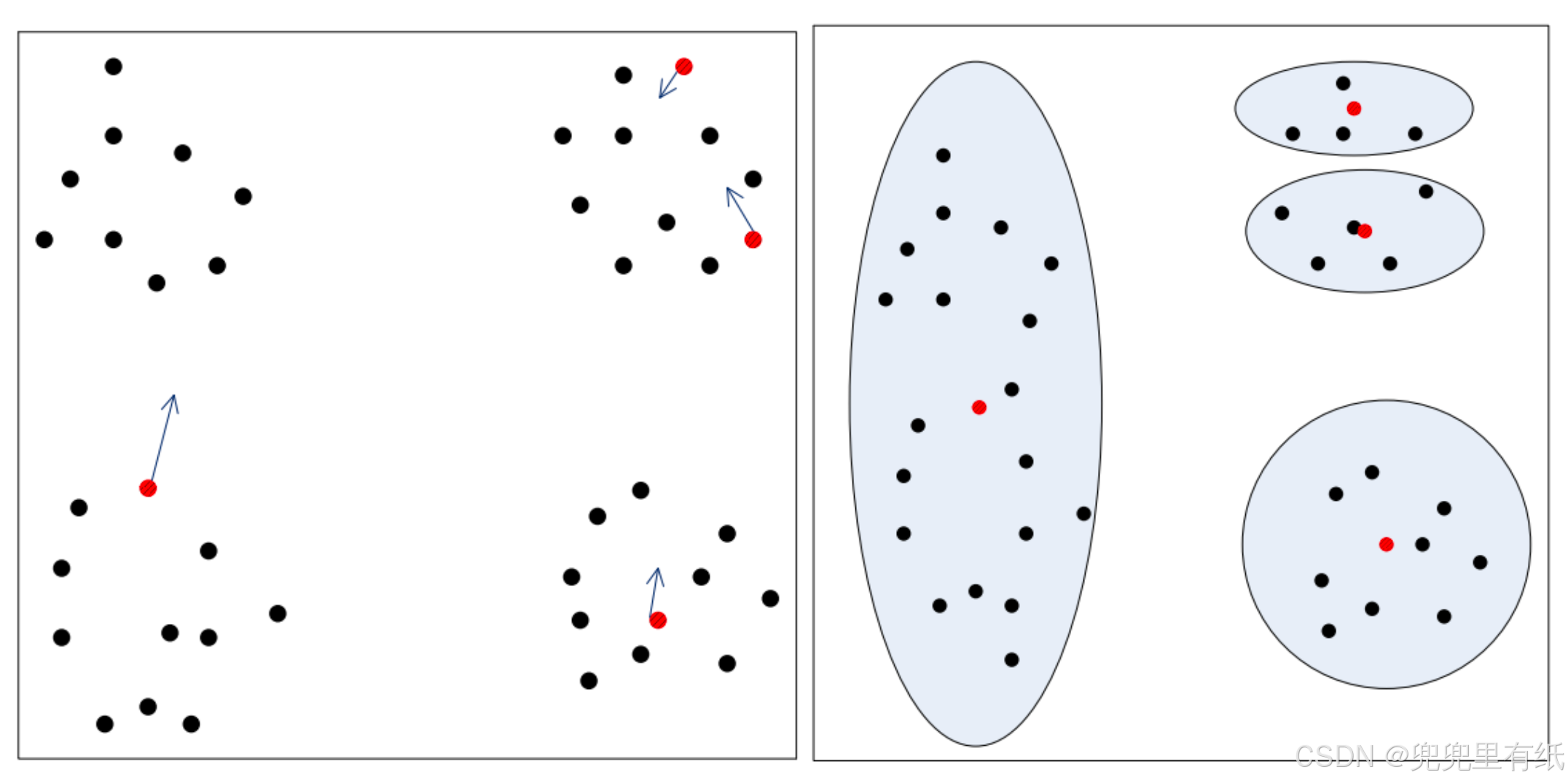
◼ 不适合于发现非凸面形状的簇或者大小差别很大的簇
◼ 对噪声和孤立点数据敏感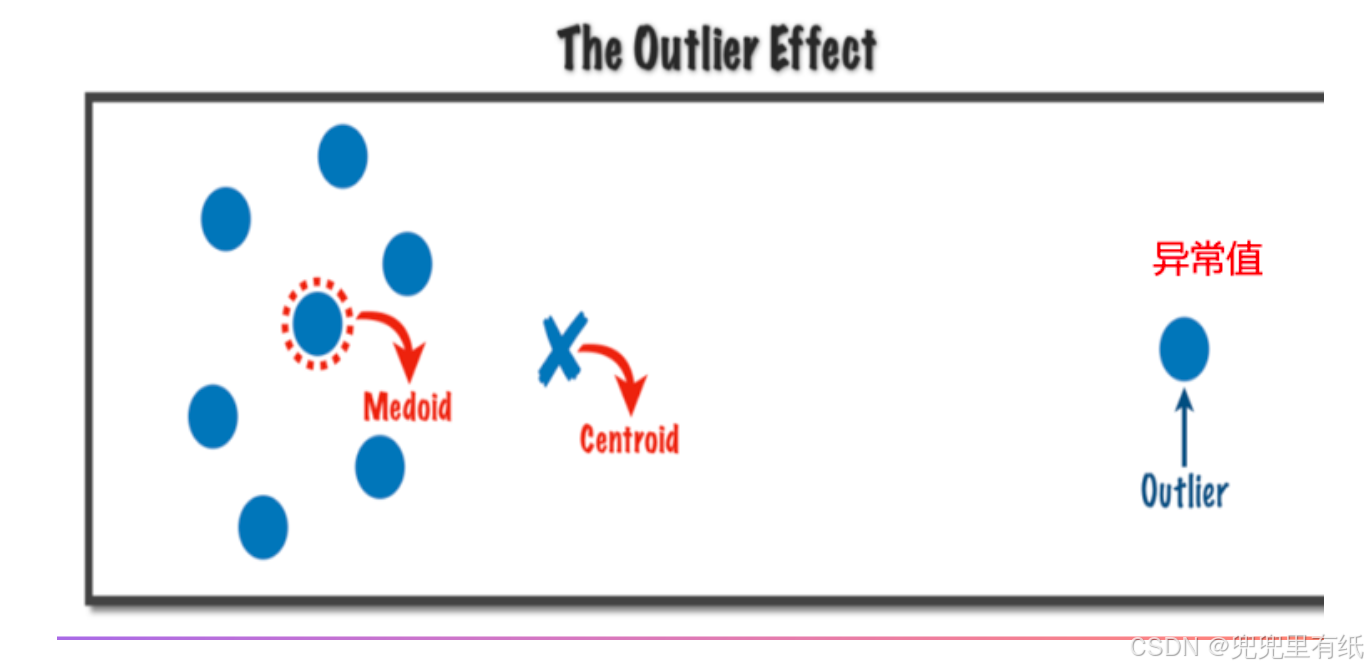
改进算法
第八章 降维(重点)
数据降维概述
• 维数灾难(Curse of Dimensionality):通常是指在涉及到向量的计算的问题中,随着维数的增加,计算量呈指数倍增长的一种现象。
• 在很多机器学习问题中,每条数据经常具有很高的特征维度。如果直接使用原始的数据,不仅会让训练非常缓慢,还会影响模型的泛化性能。
什么是数据降维?
• 降维(Dimensionality Reduction)是将训练数据中的样本(实例)从高维空间转换到低维空间。该过程与信息论中有损压缩概念相似,完全无损的降维是不存在。
• 降维方法又分为线性降维和非线性降维,非线性降维又分为基于核函数和基于流形等方法。
为什么要降维?
• 数据降维可以使得数据集更易使用、确保变量之间彼此独立、降低算法计算运算成本、去除噪音。
• 数据降维常应用于文本处理、人脸识别、图片识别、自然语言处理等领域。
主成分分析(PCA)算法(大题)
算法思想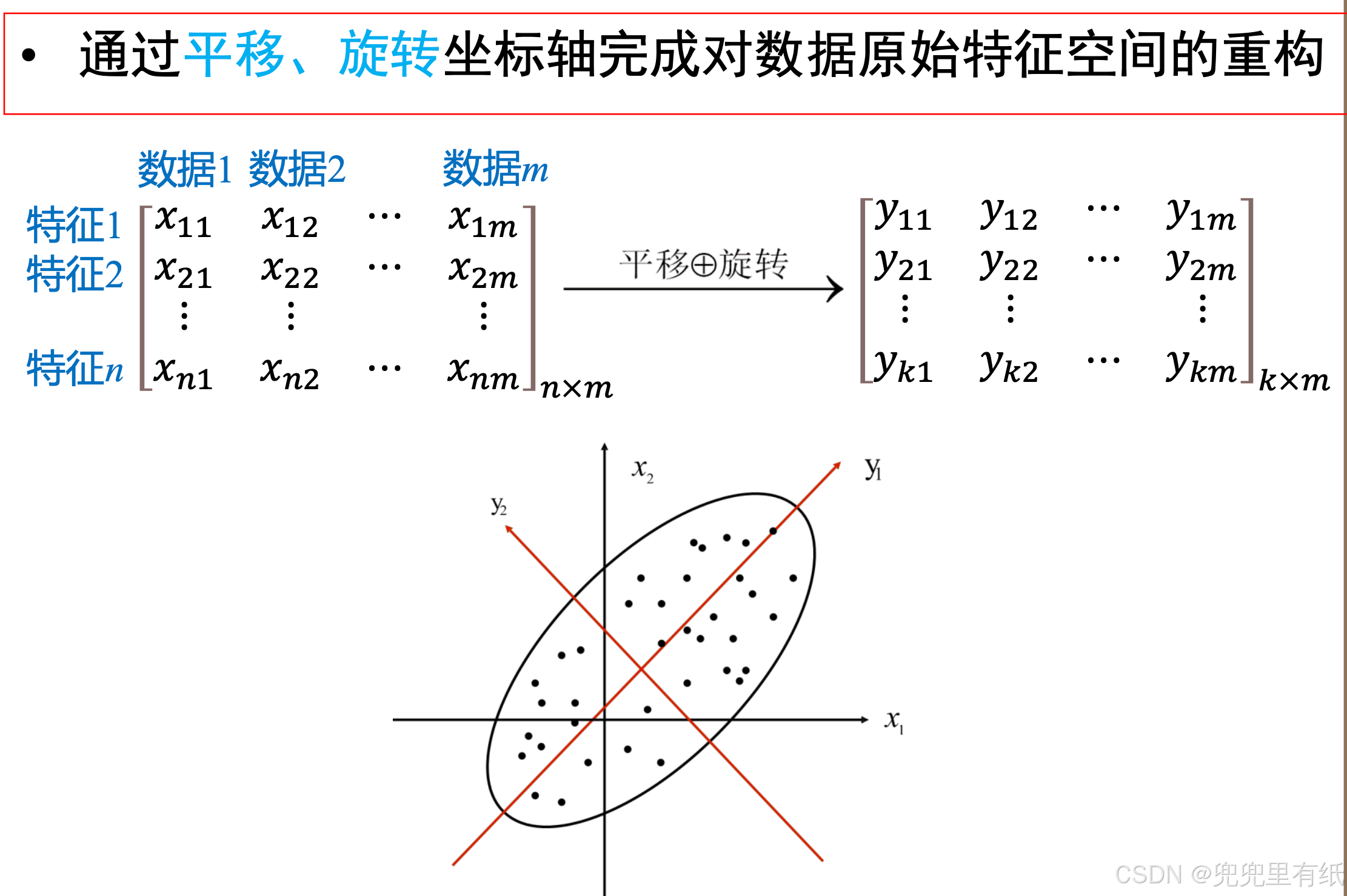
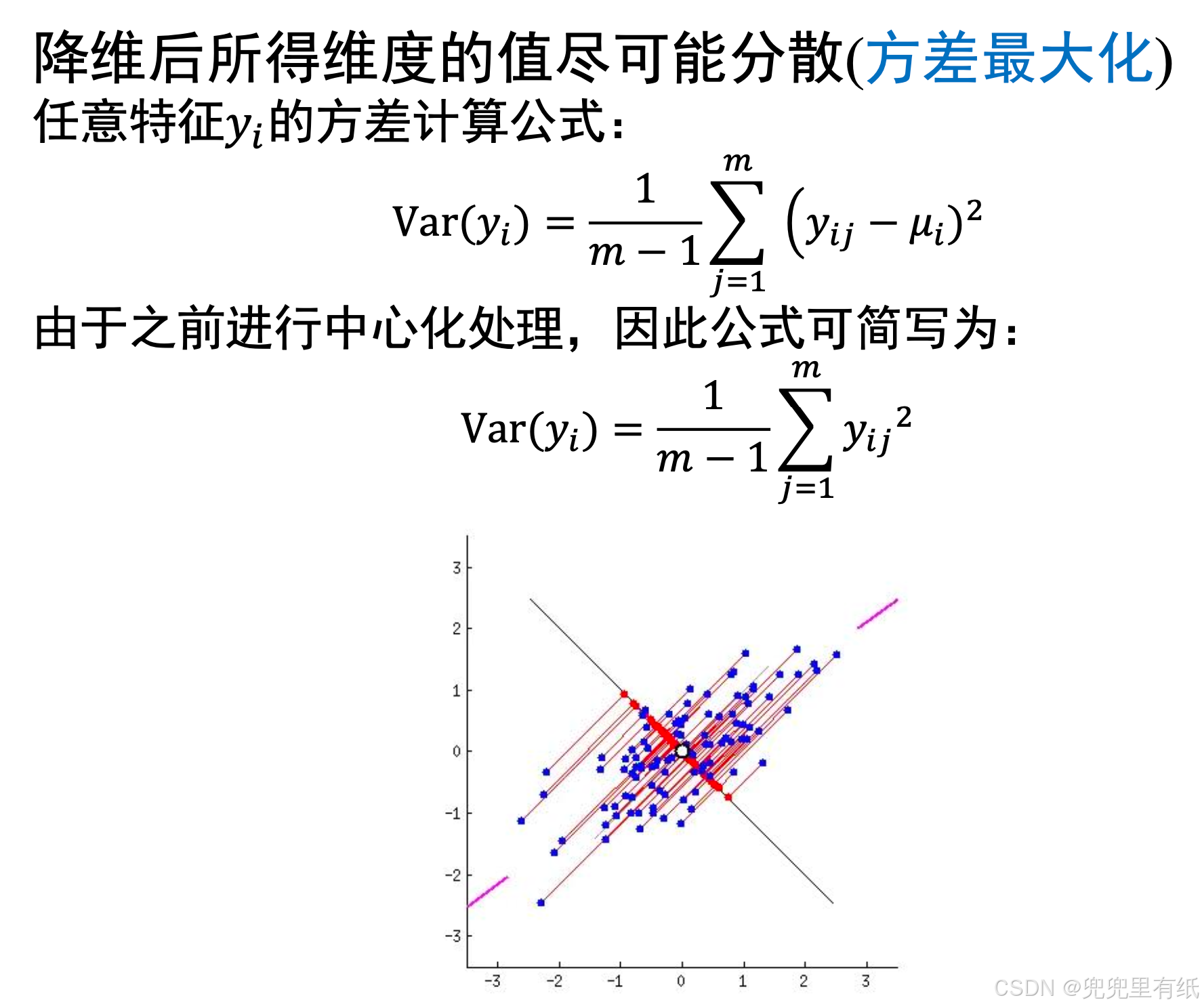
• PCA算法对于重构和降维的要求:
1. 重构的不同维度之间线性无关(正交、协方差为0);
2. 降维后所得维度的值尽可能分散(最大方差);
• 一个使用PCA算法的实例
1. 识别在数据集中最大方差量的轴(c1);
2. 找到与第一个轴正交的第二个轴(c2)。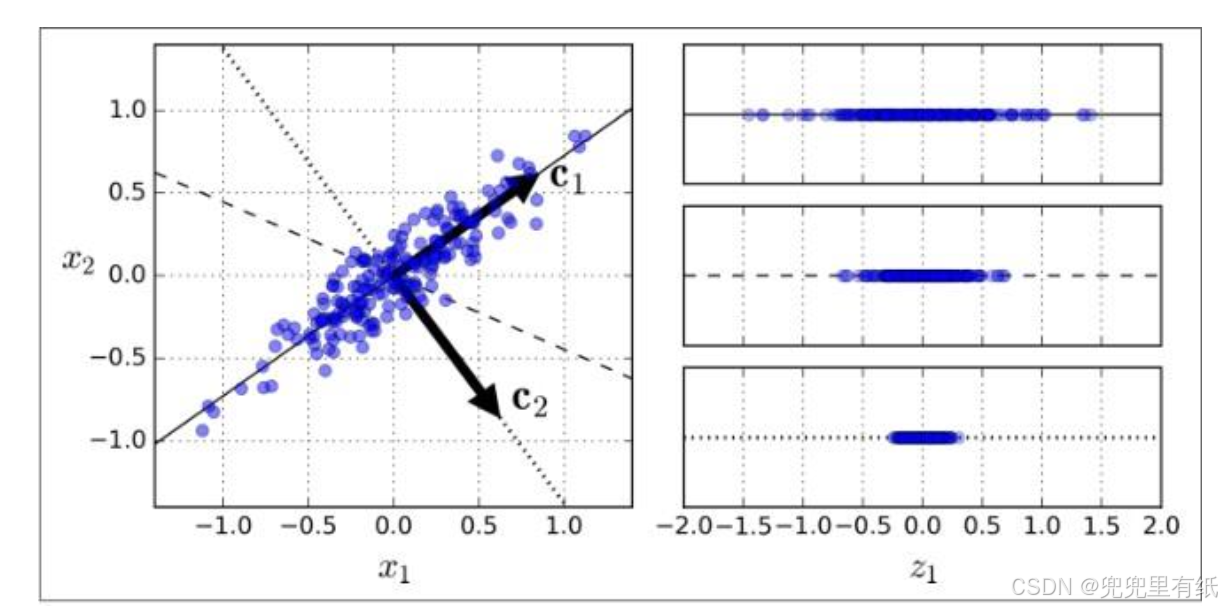
• 对于高维数据按照规则继续计算;
• 第𝒊 轴的单位向量称为第 𝒊 个主成分(PC) ;
• 例子中第一个PC为𝑐1,第二个PC 为𝑐2 。
算法推导

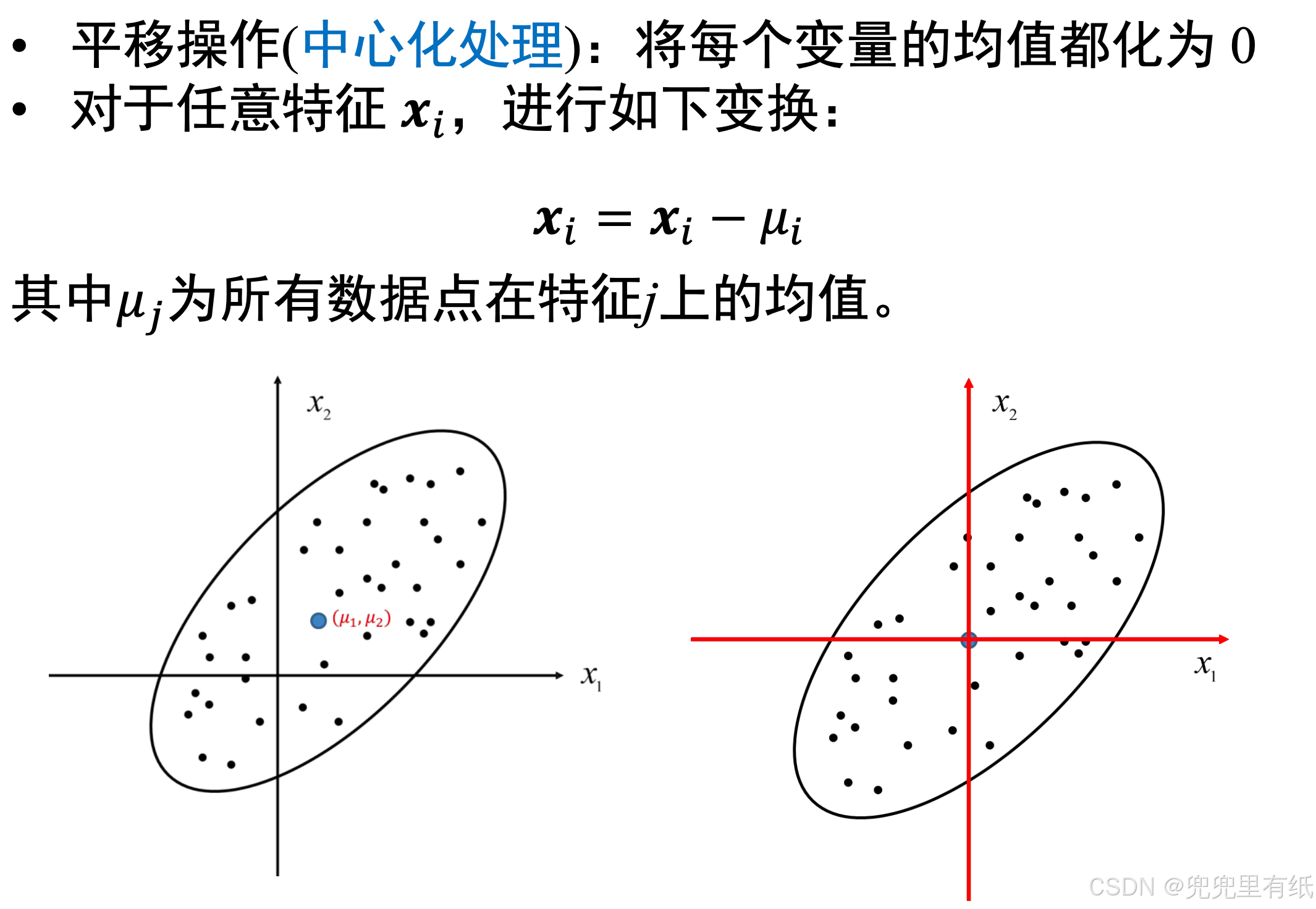


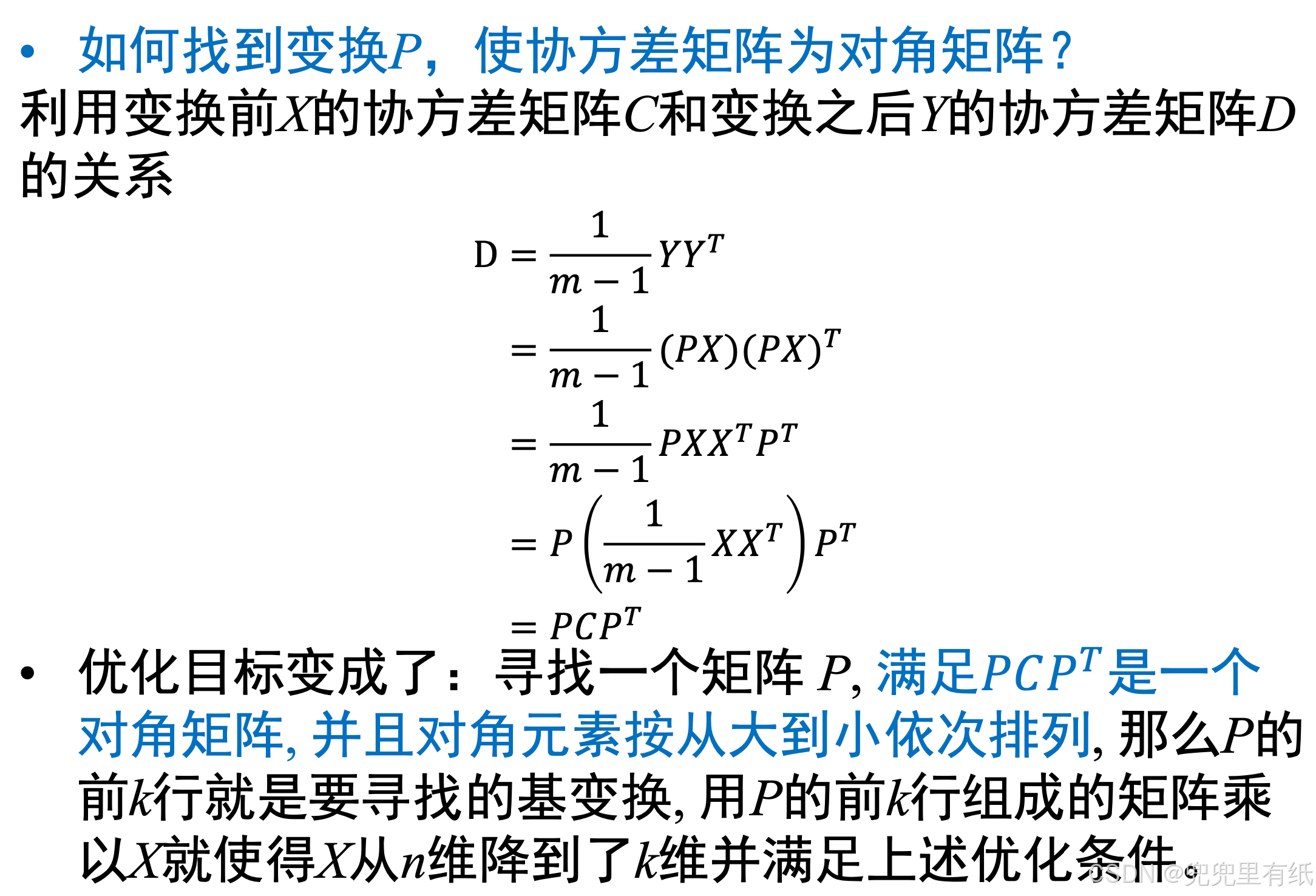

算法步骤
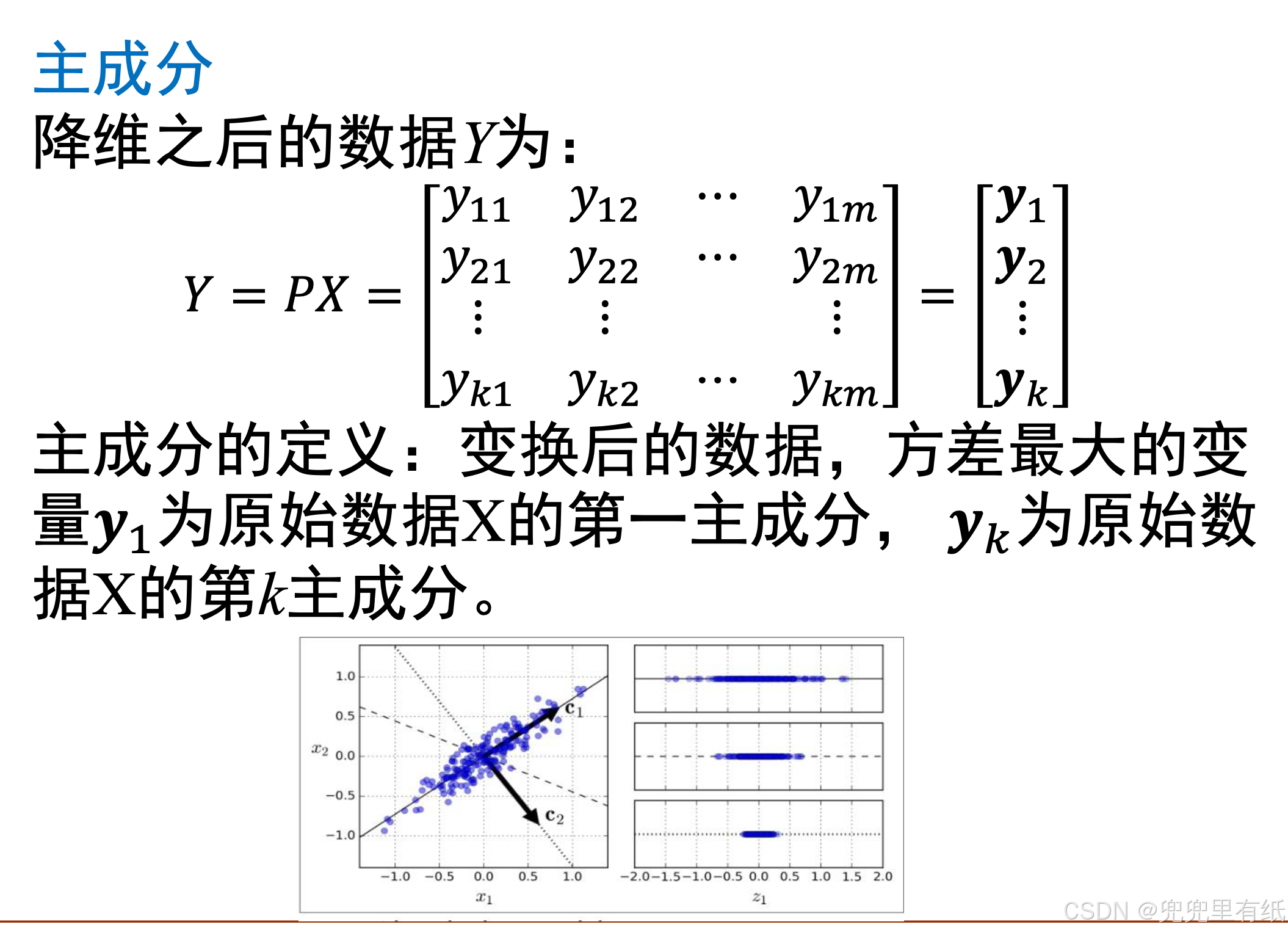

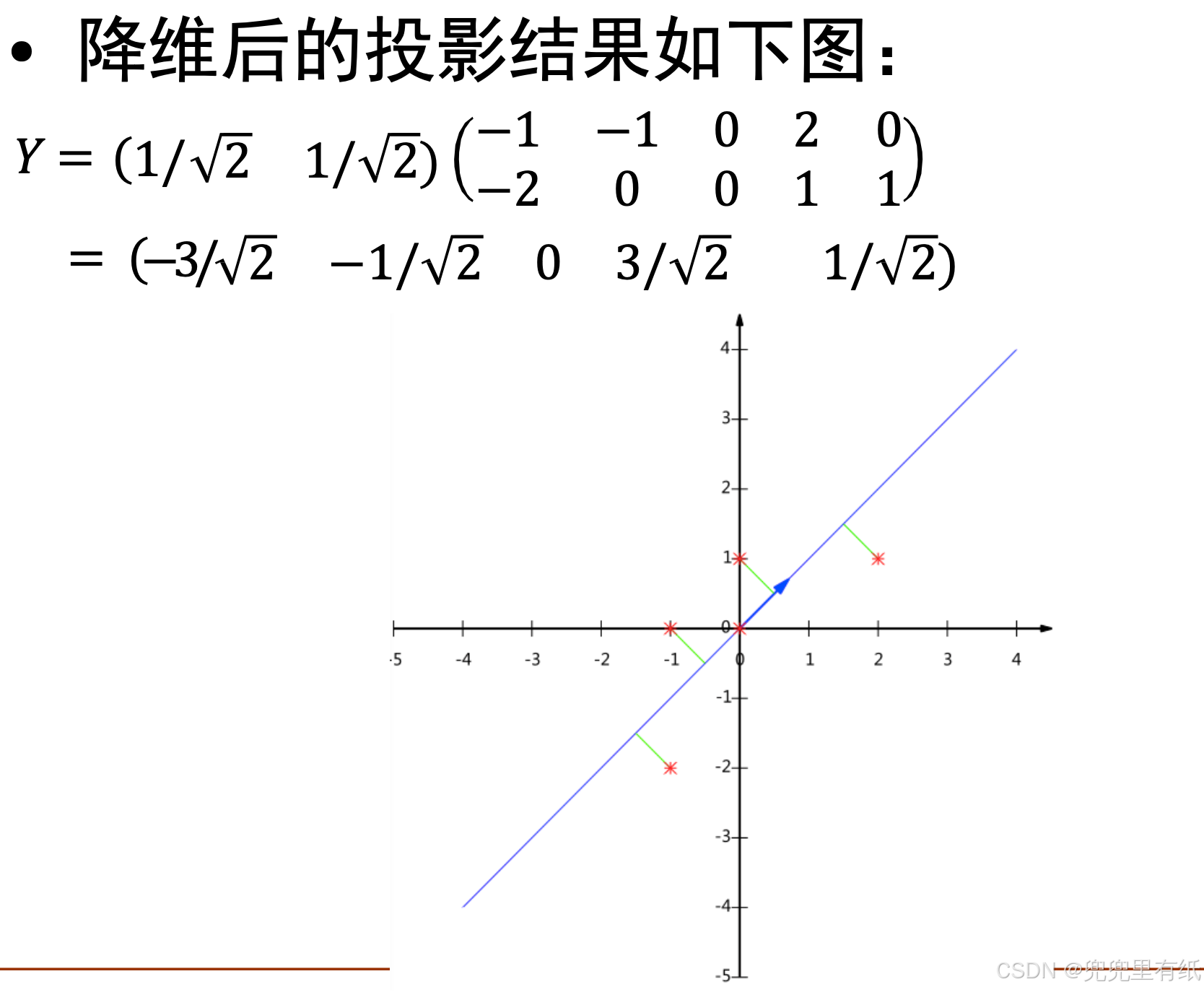
实例



(取第一行是因为对应的特征值最大)
• PCA算法优点
1. 仅仅需要以方差衡量信息量,不受数据集以外的因素影响
2. 各主成分之间正交,可消除原始数据成分间的相互影响的因素
3. 计算方法简单,主要运算时特征值分解,易于实现
4. 它是无监督学习,完全无参数限制的
• PCA算法缺点
1. 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强
2. 方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)