
深度学习调参策略:lr_scheduler的选择
转载文章:https://zhuanlan.zhihu.com/p/52608023caffe 框架中的策略包括 fixed,step,exp,inv,multistep,poly,sigmoid。1. fixedfixed,即固定学习率,这是最简单的一种配置,只需要一个参数。如上图,在整个的优化过程中学习率不变,这是非常少使用的策略,因为随着向全局最优点逼近,学习率应该越来越小才能避免跳过最优点
转载文章:https://zhuanlan.zhihu.com/p/52608023
caffe 框架中的策略包括 fixed,step,exp,inv,multistep,poly,sigmoid。
1. fixed
fixed,即固定学习率,这是最简单的一种配置,只需要一个参数。
lr_policy: "fixed"
base_lr: 0.01
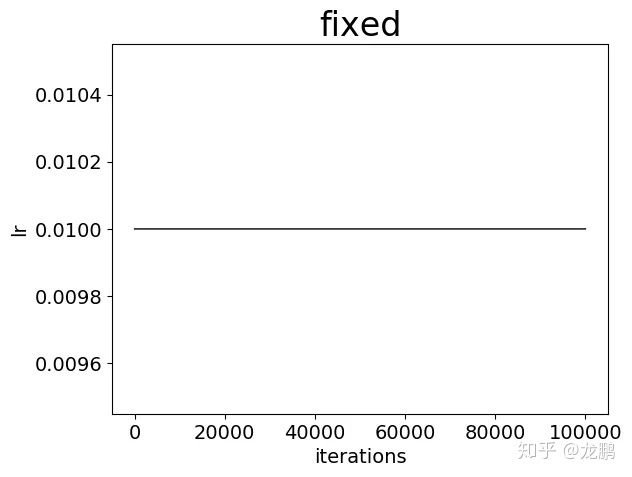
如上图,在整个的优化过程中学习率不变,这是非常少使用的策略,因为随着向全局最优点逼近,学习率应该越来越小才能避免跳过最优点。
2. step
采用均匀降低的方式,比如每次降低为原来的 0.1 倍。
lr_policy: "step"
base_lr: 0.01
stepsize: 10000
gamma:0.1
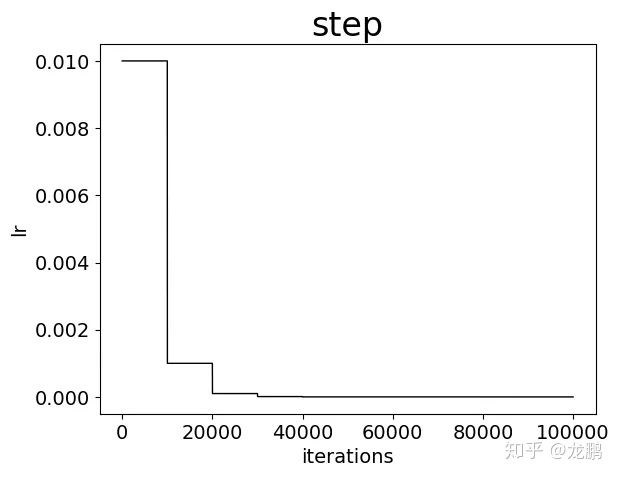
这是非常常用的一个学习率迭代策略,每次将学习率降低为原来的一定倍数,属于非连续型的变换,使用简单,而且效果通常较好。不过从上图也可以看出,其实学习率的变化一点都不平滑。
3. multistep
采用非均匀降低策略,指定降低的 step 间隔,每次降低为原来的一定倍数。
lr_policy: "multistep"
gamma: 0.5
stepvalue: 10000
stepvalue: 30000
stepvalue: 60000
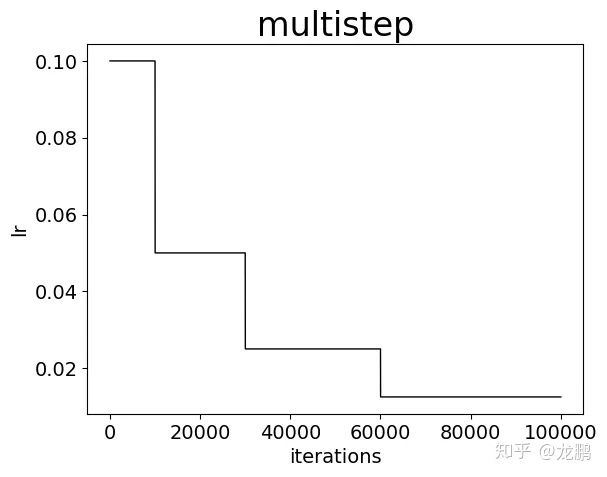
这是比 step 更加复杂的策略,也是采用非连续型的变换,但是变换的迭代次数不均匀,也是非常常用的策略,需要经验。
4. exp
这是一种指数变化,new_lr = base_lr * (gamma^iter),可知这是连续变化,学习率的衰减非常快,gamma 越大则衰减越慢,但是因为 caffe 中的实现使用了 iter 作为指数,而 iter 通常都是非常大的值,所以学习率衰减仍然非常快。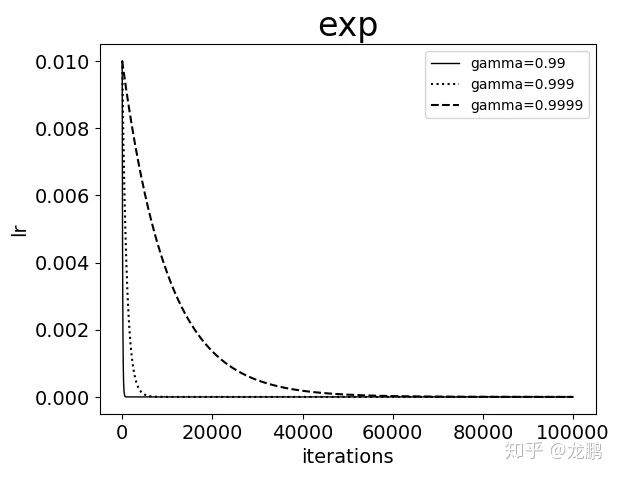
5. inv
new_lr = base_lr * (1 + gamma * iter) ^ (- power),可以看出,也是一种指数变换,参数 gamma 控制曲线下降的速率,而参数 power 控制曲线在饱和状态下学习率达到的最低值。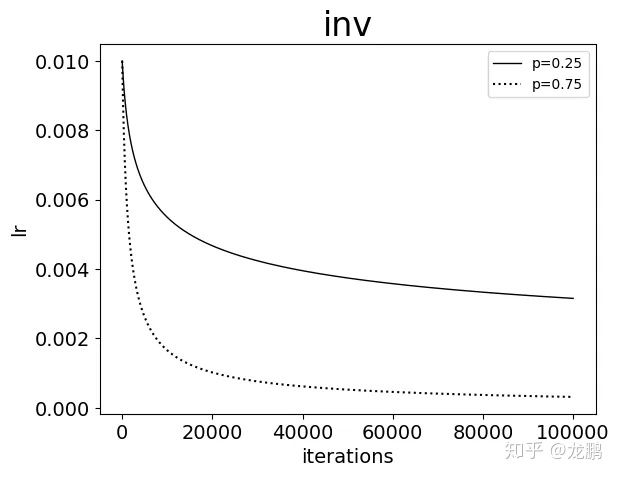
6. poly
new_lr = base_lr * (1 – iter/maxiter) ^ (power),可以看出,学习率曲线的形状主要由参数 power 的值来控制。当 power = 1 的时候,学习率曲线为一条直线。当 power < 1 的时候,学习率曲线是凸的,且下降速率由慢到快。当 power > 1 的时候,学习率曲线是凹的,且下降速率由快到慢。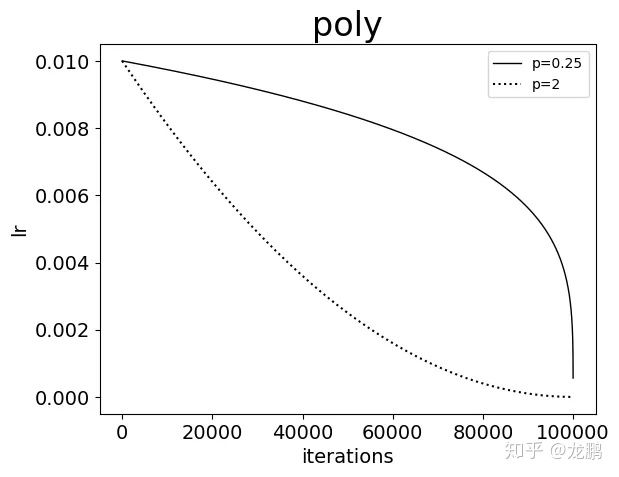
7. sigmoid
new_lr = base_lr *( 1/(1 + exp(-gamma * (iter - stepsize))))
参数 gamma 控制曲线的变化速率,gamma 必须小于 0 才能下降,而这在 caffe 中并不被支持。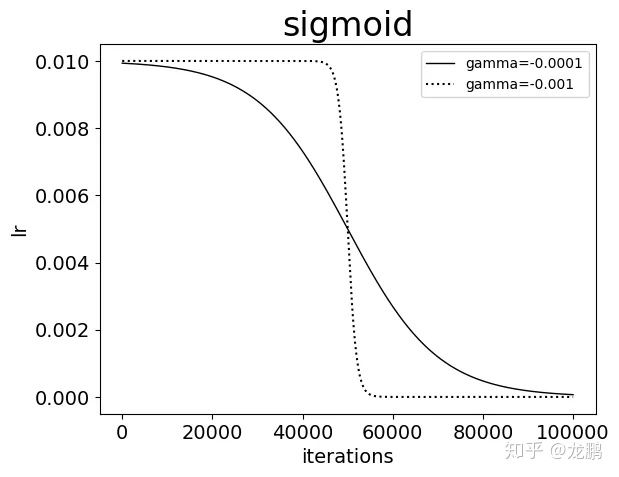
学习率的具体变更方式如下: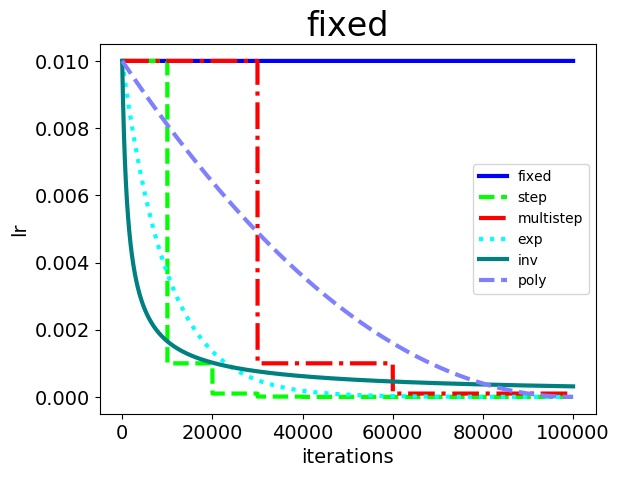
- step,multistep 方法的收敛效果最好,这也是我们平常用它们最多的原因。虽然学习率的变化是最离散的,但是并不影响模型收敛到比较好的结果
- 其次是 exp,poly。它们能取得与 step,multistep 相当的结果,也是因为学习率以比较好的速率下降,操作的确很骚,不过并不见得能干过 step 和 multistep
- inv 和 fixed的收敛结果最差。这是比较好解释的,因为 fixed 方法始终使用了较大的学习率,而 inv 方法的学习率下降过程太快,这一点,当我们直接使用 0.001 固定大小的学习率时可以得到验证,最终收敛结果与 inv 相当

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)