
pytorch第一步:加载数据Dataset
在使用 PyTorch 进行深度学习时,一般会通过继承类来自定义数据集。这个类的作用是实现一个标准的接口,使得我们能够以相同的方式处理不同的数据集,并且能够方便地使用多线程进行数据的加载和处理。
引言:
在机器学习和深度学习中,使用数据集(Dataset)是非常重要的。一个好的数据集可以帮助我们训练出更加稳定和准确的模型。
介绍:
在使用 PyTorch 进行深度学习时,一般会通过继承 torch.utils.data.Dataset 类来自定义数据集。这个类的作用是实现一个标准的接口,使得我们能够以相同的方式处理不同的数据集,并且能够方便地使用多线程进行数据的加载和处理。
示例代码及其讲解:
完整代码与数据集已上传,可自行下载
shihenren/pytorch-demo1: This is my first pytorch-demo. (github.com)
一个框架的学习我们并不用去特意地背那些个api怎么用,所以直接上代码,理解就完事儿了。
我们现在有两个数据集ants和bees,都存放在训练文件夹train下。

我们现在需要加载这两个数据集,这个可以通过继承Dataset接口来完成
代码如下:
第一步,继承Dataset类并实现一些内部方法
from torch.utils.data import Dataset
from PIL import Image
import os
class MyData(Dataset):
'''
初始化函数,用于读取文件的路径,train_dir指的是训练文件的路径,class_dir指的是哪一类
self.path是训练文件和类名的拼接获得的路径,及类路径
self.img_path指的是所有图片的路径,以list格式存储
'''
def __init__(self,train_dir,label_dir):
self.train_dir = train_dir
self.label_dir = label_dir
self.path = os.path.join(self.train_dir,self.label_dir)
self.img_path = os.listdir(self.path)
'''
重写切片方法,会根据索引打开图片,并返回图片以及其对应的类别
'''
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.path,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label
首先实现他的初始化方法,然后重写了一个切片的方法
其中
def __init__(self,train_dir,label_dir):
self.train_dir = train_dir
self.label_dir = label_dir
self.path = os.path.join(self.train_dir,self.label_dir)
self.img_path = os.listdir(self.path)这段代码主要是 MyData 类的初始化方法,该类是自定义的数据集,用于读取指定文件夹中某个类别的图片并返回。在初始化方法中,输入参数包括训练集数据的文件夹路径和标签(即类别)的文件夹路径,然后通过 os.path.join() 函数将两个路径合并为一个路径,用于获取某一类别的完整路径。接着,使用 os.listdir() 函数获取该路径下对应类别的所有图片的文件名,并将其放入一个列表中,即 self.img_path。这样做可以方便后续根据索引来获取对应的图片。
而这段代码:
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.path,img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img,label这段代码定义了 MyData 类的获取数据方法,用于根据索引获取一张图片及其对应的标签。首先通过传入的索引 idx,获取对应的图片文件名 img_name,然后使用 os.path.join() 函数获取该图片完整路径,并使用 Image.open() 函数打开该图片,返回值为一个 PIL.Image.Image 对象,即 img。接着,由于所有图片都属于同一个类别,所以 label 变量直接赋值为 self.label_dir,即该类别的标签名称。最后,使用 return 语句返回 img 和 label 。这样就可以方便地从自定义数据集中获取某个类别对应的图像数据和标签。
第二步,根据MyData类来加载数据集
'''
测试一下获取蚂蚁和蜜蜂数据集
'''
root_dir = '数据集/hymenoptera_data/train'
ants_dir = 'ants'
ants = MyData(root_dir,ants_dir)
ant1_img,ants1_label = ants[0]
ant1_img.show()
print(ants1_label)
bees_dir = 'bees'
bees = MyData(root_dir,bees_dir)
bee1_img,bee1_label = bees[1]
bee1_img.show()
print(bee1_label)
这段代码初始化了两个数据集,一个ants数据集和一个bees数据集,并且分别根据索引可视化了这两个数据集的其中一张图片,并且输出了他的类别label
第三步:生成这两个数据集的标签
代码如下:
for i in ants.img_path:
# print(i)
name = i[:-4]#切片操作,切掉最后四个字符.jpg
file = open(f"数据集/hymenoptera_data/train/ants_label/{name}.txt", "w")
# 将字符串 "ants" 写入文件
file.write("ants")
# 关闭文件
file.close()
for i in bees.img_path:
# print(i)
name = i[:-4]#切片操作,切掉最后四个字符.jpg
file = open(f"数据集/hymenoptera_data/train/bees_label/{name}.txt", "w")
# 将字符串 "ants" 写入文件
file.write("bees")
# 关闭文件
file.close()生成了这两个训练数据集对应的标签
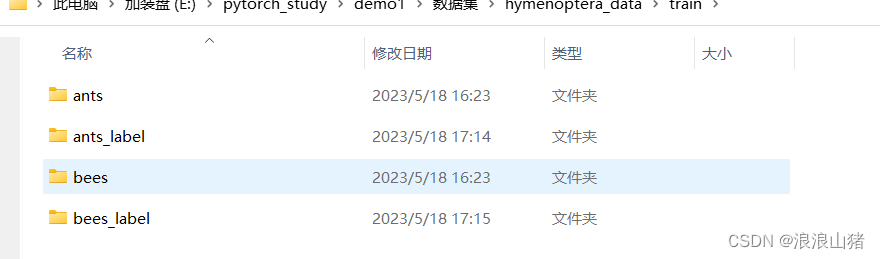
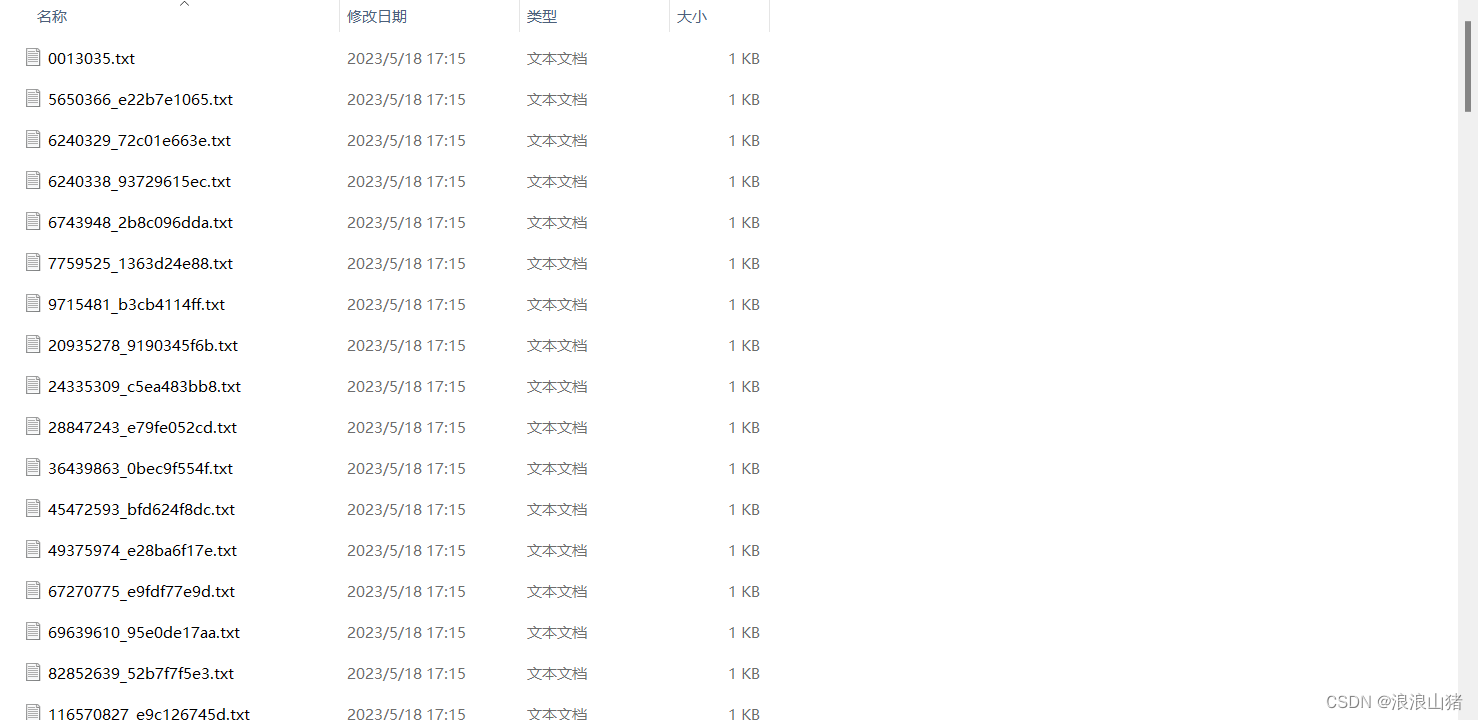
随便打开一个
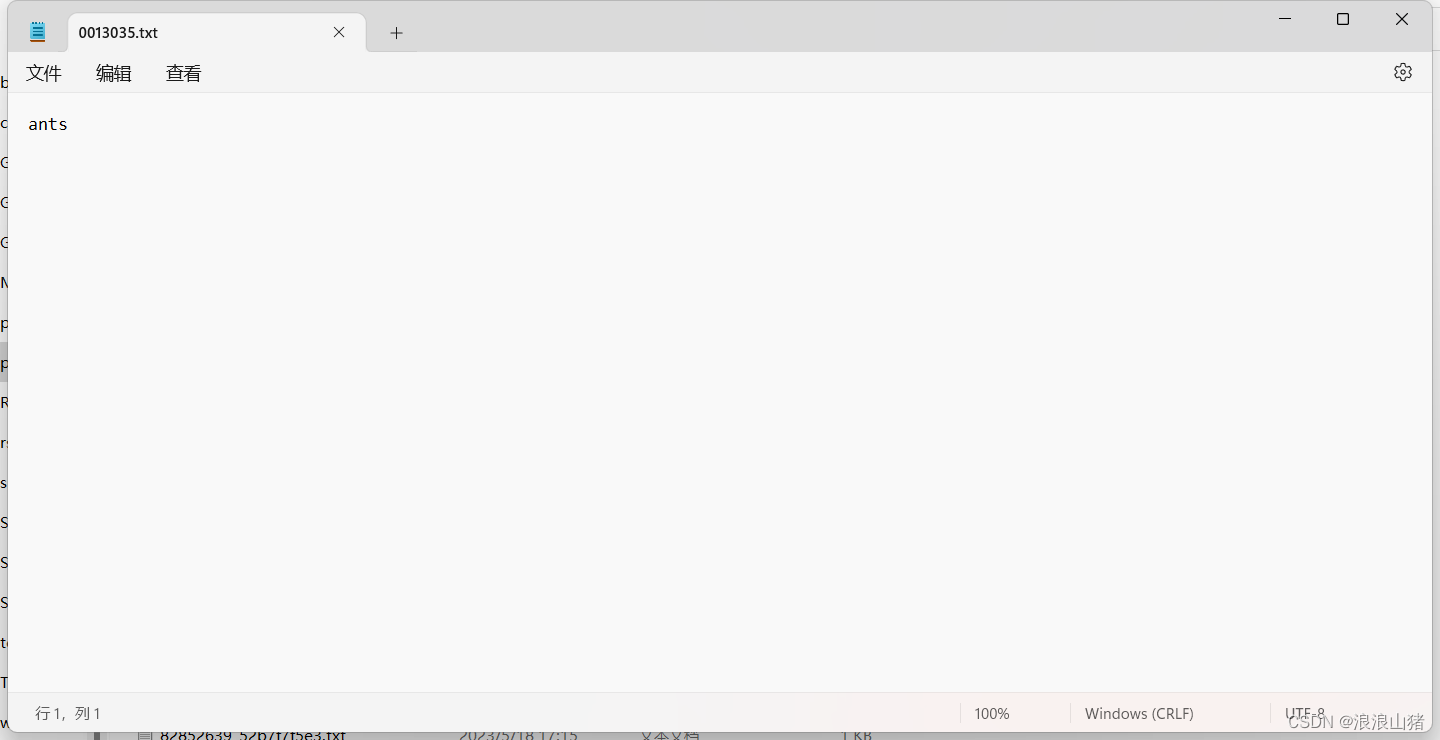
之后我们就可以根据数据集以及其对应的标签来进行模型的训练了。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)