
前馈神经网络-pytorch搭建-MINIST数据集测试(完整代码在文末)
基于公开的MNIST手写数字数据上的分类问题,构建一个包含至少一个隐藏层的前馈神经网络,其中包括选择适当的激活函数和损失函数实现训练模型,并记录训练过程中损失和准确率等实验结果。进一步分析原因,问题或许是出现在激活函数上,由于最后手写数字识别本质上是个多分类的问题,所以在最后一层的10个输出上,使用Softmax函数才是最佳选择,这样更改过之后,准确率就达到了97.48%在最初我只使用了一层的隐藏
前馈神经网络(FNN)
实验目的与要求
- 掌握前馈神经网络的结构;
- 构建和训练一个简单的多层感知机来解决分类问题。
实验内容
基于公开的MNIST手写数字数据上的分类问题,构建一个包含至少一个隐藏层的前馈神经网络,其中包括选择适当的激活函数和损失函数实现训练模型,并记录训练过程中损失和准确率等实验结果。具体实验步骤如下:
- 下载公开的MNIST手写数字数据集。
- 学习和简述数据集的特征,包括数据的维度、类别数等。
- 构建一个包含至少一个隐藏层的前馈神经网络。
- 初始化网络参数,选择适当的激活函数,如ReLU函数。
- 编写代码实现神经网络的训练过程,包括前向传播和反向传播。
- 选择适当的损失函数,如交叉熵损失。
- 应用梯度下降算法进行参数优化。
- 训练模型,并记录训练过程中的损失和准确率变化。
- 评估模型在测试集上的性能。
实验方法
构建前馈神经网络,确定隐藏层数量和激活函数:
第一层 in:28*28 out:256 激活函数:ReLU
第二层 in:256 out:128 激活函数:ReLU
第三层 in:128 out:64 激活函数:ReLU
第四层 in:64 out:32 激活函数:ReLU
第五层 in:32 out:10 激活函数:Softmax
训练轮次Epoch:10,每轮样本数量:938
损失函数:交叉熵损失函数
参数更新:Adam优化器
详细的模型设计及运行结果
模型设计及结果
首先,导入相关库,pytorch用于网络的搭建,matplotlib用于绘制最后的loss曲线和accuracy曲线,tqdm库用于训练过程的可视化
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torchvision import datasets, transforms
- from torch.utils.data import DataLoader
- import matplotlib.pyplot as plt
- from tqdm import tqdm
将网络封装成类,继承torch库中的Module类,网络各层信息如下所示,同时定义前向传播函数
- class FNN(nn.Module):
- def __init__(self):
- super(FNN, self).__init__()
- self.flatten = nn.Flatten()
- self.linear_relu_stack = nn.Sequential(
- nn.Linear(28 * 28, 256),
- nn.ReLU(),
- nn.Linear(256, 128),
- nn.ReLU(),
- nn.Linear(128, 64),
- nn.ReLU(),
- nn.Linear(64, 32),
- nn.ReLU(),
- nn.Linear(32, 10),
- nn.LogSoftmax(dim=1)
- )
- def forward(self, x):
- x = self.flatten(x)
- logits = self.linear_relu_stack(x)
- return logits
准备MNIST数据集的训练和测试数据,将其转换为PyTorch中的Tensor格式,并进行归一化处理。
- transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
- train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
- test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
- train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
- test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
创建了一个神经网络模型 model、一个交叉熵损失函数 criterion 和一个Adam优化器 optimizer。学习率初始化0.001
- model = FNN()
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.Adam(model.parameters(), lr=0.001)
创建三个列表,分别用于每个Epoch的训练集损失,测试集损失,准确率
- train_losses = []
- test_losses = []
- accuracies = []
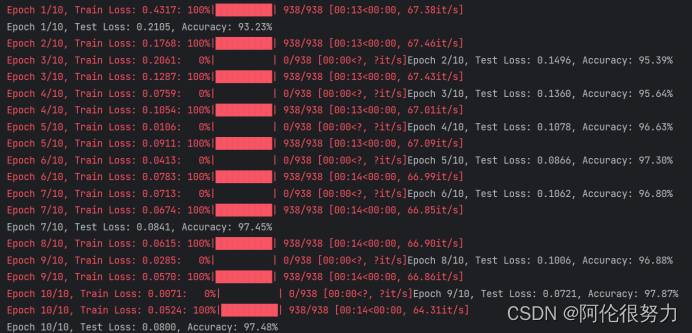
训练神经网络模型(训练进度可视化),并在每个epoch之后进行测试并打印损失和准确率。
- for epoch in range(epochs):
- model.train() # Set to training mode
- train_loss = 0.0
- correct = 0
- total = 0
- progress_bar = tqdm(enumerate(train_loader), total=len(train_loader))
- for batch_idx, (images, labels) in progress_bar:
- optimizer.zero_grad()
- outputs = model(images)
- loss = criterion(outputs, labels)
- loss.backward()
- optimizer.step()
- train_loss += loss.item()
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- progress_bar.set_description(f'Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss / (batch_idx + 1):.4f}')
- train_losses.append(train_loss / len(train_loader))
- # Test the model
- model.eval() # Set to evaluation mode
- test_loss = 0
- correct = 0
- total = 0
- with torch.no_grad():
- for images, labels in test_loader:
- outputs = model(images)
- _, predicted = torch.max(outputs.data, 1)
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- test_loss += criterion(outputs, labels).item()
- test_losses.append(test_loss / len(test_loader))
- accuracy = 100 * correct / total
- accuracies.append(accuracy)
- print(f'Epoch {epoch + 1}/{epochs}, Test Loss: {test_losses[-1]:.4f}, Accuracy: {accuracy:.2f}%')
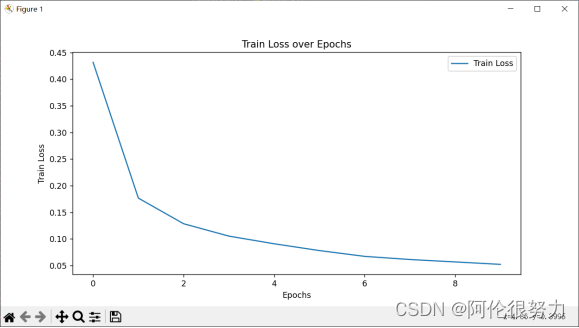
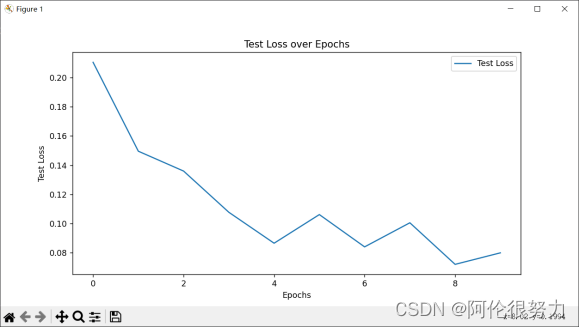
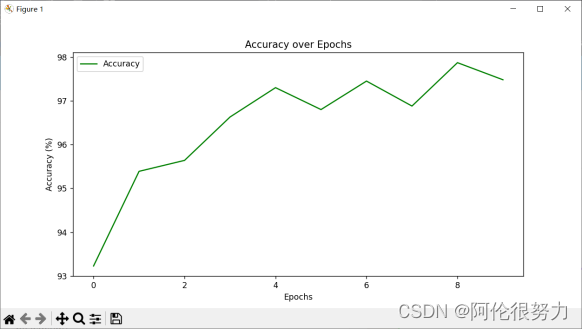
绘制loss和accuracy变化曲线
- # Plotting
- plt.figure(figsize=(10, 5))
- plt.plot(train_losses, label='Train Loss')
- plt.xlabel('Epochs')
- plt.ylabel('Train Loss')
- plt.title('Train Loss over Epochs')
- plt.legend()
- plt.show()
- plt.figure(figsize=(10, 5))
- plt.plot(test_losses, label='Test Loss')
- plt.xlabel('Epochs')
- plt.ylabel('Test Loss')
- plt.title('Test Loss over Epochs')
- plt.legend()
- plt.show()
- plt.figure(figsize=(10, 5))
- plt.plot(accuracies, label='Accuracy', color='green')
- plt.xlabel('Epochs')
- plt.ylabel('Accuracy (%)')
- plt.title('Accuracy over Epochs')
- plt.legend()
- plt.show()
模型的特色
我的FNN模型具有多个隐藏层,并且它们之间使用ReLU激活函数进行非线性变换。这样可以使模型具有一定的深度和复杂性,能够对输入数据进行多层次的特征提取和组合,从而提高了模型的表示能力。
最后一层采用了softmax激活函数。使模型最后一层的输出是经过softmax处理的,即将输出转化为类别概率分布介于0-1之间。
我使用交叉熵损失函数作为模型的损失函数。在多类别分类问题中,交叉熵损失函数是一种常用的选择,它能够衡量模型输出与真实标签之间的差异,并且在优化过程中能够有效地推动模型向正确的方向调整。
Adam优化器来训练模型。Adam是一种自适应学习率的优化算法,结合了动量方法和自适应学习率调整策略。相比于传统的梯度下降算法,Adam通常能够更快地收敛,并且具有较好的性能。
实验总结
在最初我只使用了一层的隐藏层,得到的准确率只有67.58%,这是由于模型的深度不够,在数字识别这种高维问题上,表现不佳。
随后我添加隐藏层的数量,将层数拔高到5层,这样准确率有了大幅度的提高,达到了87.55%,但还是不够理想。
进一步分析原因,问题或许是出现在激活函数上,由于最后手写数字识别本质上是个多分类的问题,所以在最后一层的10个输出上,使用Softmax函数才是最佳选择,这样更改过之后,准确率就达到了97.48%
附:完整代码
若无tqdm库,删除相关内容即可,只是个训练过程可视化,无伤大雅
安装也很方便,pip install tqdm 即可
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from tqdm import tqdm
class FNN(nn.Module):
def __init__(self):
super(FNN, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10),
nn.LogSoftmax(dim=1)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
model = FNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train_and_test(model, train_loader, test_loader, optimizer, criterion, epochs):
train_losses = []
test_losses = []
accuracies = []
for epoch in range(epochs):
model.train() # Set to training mode
train_loss = 0.0
correct = 0
total = 0
progress_bar = tqdm(enumerate(train_loader), total=len(train_loader))
for batch_idx, (images, labels) in progress_bar:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
progress_bar.set_description(f'Epoch {epoch + 1}/{epochs}, Train Loss: {train_loss / (batch_idx + 1):.4f}')
train_losses.append(train_loss / len(train_loader))
# Test the model
model.eval() # Set to evaluation mode
test_loss = 0
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_loss += criterion(outputs, labels).item()
test_losses.append(test_loss / len(test_loader))
accuracy = 100 * correct / total
accuracies.append(accuracy)
print(f'Epoch {epoch + 1}/{epochs}, Test Loss: {test_losses[-1]:.4f}, Accuracy: {accuracy:.2f}%')
# Plotting
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Train Loss')
plt.xlabel('Epochs')
plt.ylabel('Train Loss')
plt.title('Train Loss over Epochs')
plt.legend()
plt.show()
plt.figure(figsize=(10, 5))
plt.plot(test_losses, label='Test Loss')
plt.xlabel('Epochs')
plt.ylabel('Test Loss')
plt.title('Test Loss over Epochs')
plt.legend()
plt.show()
plt.figure(figsize=(10, 5))
plt.plot(accuracies, label='Accuracy', color='green')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.title('Accuracy over Epochs')
plt.legend()
plt.show()
# Train and test the model
train_and_test(model, train_loader, test_loader, optimizer, criterion, epochs=10)
汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)