
机器学习:逻辑回归python实现
逻辑回归是一种较为简单的分类算法。通常是将线性回归的预测值放入不同的中概率密度函数中,得到是某一类的概率,根据概率大小判断是否为某一类别。谈到逻辑回归必然离不开线性回归,线性回归能够通过损失函数的约束与对特征的学习得到如下的公式:每组x和w的第一位相乘即为截距。对于函数简单的函数,我们追求运算速度,使用牛顿法能够更快的得到答案。
前言:
逻辑回归是一种较为简单的分类算法。通常是将线性回归的预测值放入不同的中概率密度函数中,得到是某一类的概率,根据概率大小判断是否为某一类别。
谈到逻辑回归必然离不开线性回归,线性回归能够通过损失函数的约束与对特征的学习得到如下的公式:
每组x和w的第一位相乘即为截距。
逻辑回归:二分类
要实现分类,便需要求得每个值属于某个类的概率,利于我们理解的函数:
这是一个阶跃函数,可以看出阶跃函数非常不利于求导优化,以0为界分开两类,在0到1是一根直线,非常陡,梯度为0,无法进行优化。所以我们使用sigmod函数,作为我们的分类函数。
sigmod函数:
sigmod图像:
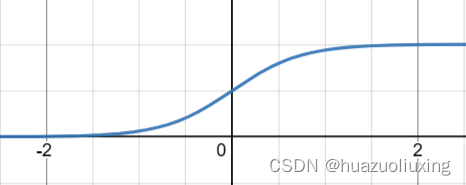
sigmod让0的左右变得平滑,让0到1之间产生了梯度
通过将线性回归的预测值放入Sigmod得到每个值,Sigmoid函数可以将实数映射到0到1之间的连续值,因此在逻辑回归中,Sigmoid函数的输出值可以被解释为一个概率,表示样本属于某个类别的可能性。Sigmod函数以0.5为默认阈值,分割为了两个区域,默认认为大于等于0.5则为正类,小于0.5则为负类:
组合起来就得到了逻辑回归二分类的关键公式:
损失函数的推导:
我们选择二分类损失函数BCE表示为:
以上loss函数是基于伯努利分布得到。伯努利分布是一种离散概率分布,它描述的是一个随机变量只有两个取值的情况,比如抛硬币的结果只有正面和反面两种可能。在伯努利分布中,随机变量的取值只能是0或1,其中1表示成功,0表示失败。我们假设真实标签服从伯努利分布:
| 正 | 负 |
| p | 1-p |
那么模型输出来的预测y_pre也应服从二项分布,根据伯努利概率质量公式
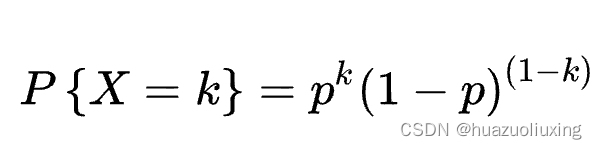
其中,k表示随机变量X的取值,取值为0或1;p表示随机变量X取值为1的概率。模型的输出y_pred表示样本属于正类的概率,我们可以将其视为伯努利分布的参数。我们可以将其视为伯努利分布的参数。则样本的似然函数为:
我们的目标是最大化似然函数,即找到最适合样本的参数p。为了方便计算,我们可以取对数并取负数,得到损失函数:
p为模型预测的正值的概率,k为实际标签。
定义优化函数:
对于函数简单的函数,我们追求运算速度,使用牛顿法能够更快的得到答案。
牛顿法求导
根据链式法则,对loss函数求导:
最终导数为:
对loss求二阶导:
由此我们得到牛顿法的更新公式为:
代码展示
import numpy as np
class Logistic:
def transform(self,x):#转换,将逻辑回归得到的概率值转换为实际标签
for i in range(len(x)):
if x[i]>=0.5:
x[i]=1
elif x[i]<0.5:
x[i]=0
return x
def fit(self,x,y,x1,y1):
x=np.array(x)
x=np.column_stack((np.ones(len(y)),x))#向x中插入一行1,表示线性回归中的截距
y=np.array(y)
sample,featers=x.shape
self.w=np.zeros(featers)#初始化参数值
self.iters=2#迭代次数,牛顿法迭代次数较低,可以很快的得到最优值
for _ in range(self.iters):
y_pre=1/(1+np.power(np.e,-1*np.dot(x,self.w)))#sigmod公式得到预测值
error=y_pre-y#损失值
dw=np.dot(error,x)#一阶导(ypre-y)*x
dsigmod=y_pre*(1-y_pre)*x.T#对sigmod求导
hasen=np.dot(dsigmod,x)#海森矩阵
delt=np.linalg.solve(hasen,dw)#变化量
self.w-=delt
if np.linalg.norm(delt)<1e-6:
break
def predict(self,x):#预测
x=np.array(x)
x=np.column_stack((np.ones(x.shape[0]),x))
y_pre=1 / (1 + np.exp(-np.dot(x, self.w)))
y_pre=self.transform(y_pre)
return y_pre结果展示:
数据集总共4k条,使用的是某公司客户的流失情况。我们需对其进行建模并分析其各个特征对用户流失的重要性。
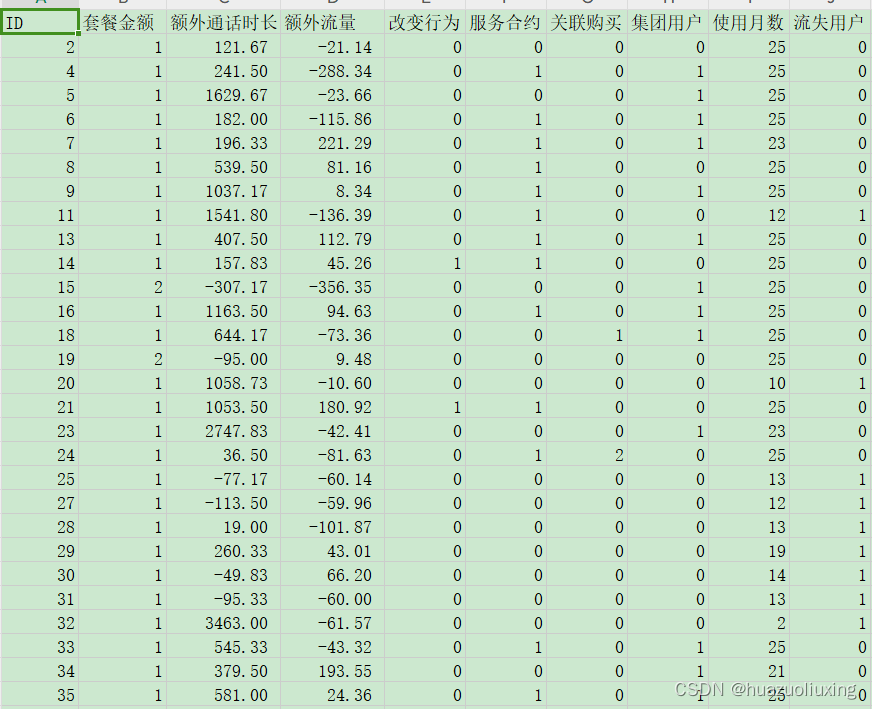
流失用户只有0和1两种情况,符合伯努利分布,可以对其使用二分类模型。对其进行数据清洗后,建模效果:

数据较高,我们使用k则交叉验证验证一下是否过拟合:
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
from sklearn.model_selection import KFold
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
x_train,x_test,y_train,y_test=train_test_split(data.iloc[:,:-1],data.iloc[:,-1],random_state=421)#分训练集和测试集
x_train=scaler.fit_transform(x_train)#z-score转换,正态转换
x_test=scaler.fit_transform(x_test)#z-score转换,正态转换
y_train=np.array(y_train)#将pandas转换为numpy数组
clf=KFold(n_splits=5,shuffle=True,random_state=35)#k则分为5组
scores=[]
model=Logistic()
for i,j in clf.split(x_train):#训练集交叉训练,并得到得分
x_t1,x_val=x_train[i],x_train[j]
y_t1,y_val=y_train[i],y_train[j]
model.fit(x_t1,y_t1)
y_pre=model.predict(x_val)
scores.append(accuracy_score(y_val,y_pre))
print("训练集k则平均",np.mean(scores))#取得分平均值
y_pre=model.predict(x_test)
y_pre1=model.predict(x_train)
print('训练集准确率',accuracy_score(y_train,y_pre1))
print('准确率',accuracy_score(y_test,y_pre))
print('精确率',precision_score(y_test,y_pre))
print('召回率',recall_score(y_test,y_pre))
print('f1',f1_score(y_test,y_pre))
可以看出k则平均值与验证集准确率相差较小,初步判断没有过拟合。逻辑回归的二分类模型实现成功。
逻辑回归:多分类:
实现了二分类,日常生活中,存在多种选择的情况比比皆是。所以仅仅只是二分类并不能满足我们分类的需求,多分类在二分类的基础上衍生而出。
对于逻辑回归而言,多分类在本质上其实只是多个二分类问题,例如:书籍的分类,当我们以计算机书籍为正类时,其他所有类都会负类,让一个多分类问题变成了一个二分类。为正代表是,为负代表除是以外的所有选项。让一组随机变量对每一个类都求一个概率,最后选择最大类的概率作为每个随机变量的类。例如下表所示:
| y_pre | 0 | 1 | 2 | 3 |
| y1 | 0.33 | 0.53 | 0.2 | 0.3 |
| y2 | 0.31 | 0.61 | 0.03 | 0.05 |
| y3 | 0.02 | 0.05 | 0.61 | 0.42 |
| y4 | 0.3 | 0.03 | 0.09 | 0.32 |
每个预测值根据每个类预测出来的概率,选取其中最大概率值代表的类,当做它的预测类。
对于每个类都需要训练出单独的一组w,这样得到的概率就为是当前类的概率。
代码展示
import numpy as np
class Logistic_mut:
def fit(self,x,y):
x=np.array(x)
x=np.column_stack((np.ones(len(y)),x))#向x中添加一行1作为截距
y=np.array(y)
self.sample,self.features=x.shape#获取样本数,特征数
self.kinds=np.unique(y)
self.iter=10 #迭代次数
self.po=[]
for i in self.kinds:#类的选取
self.w=np.zeros(self.features)#每到一个类初始化w参数
y1=y.copy()#获取一个副本计算
y1[y1!=i]=self.kinds[-1]+1#让所有不为当前副本的等于一个不存在类中的数
y1[y1==i]=1#让选到的类等于1
y1[y1==self.kinds[-1]+1]=0#让其他类等于0完成二分类的准备
for j in range(self.iter):#迭代更新
ypre=1/(1+np.exp((-1)*np.dot(x,self.w)))
error=ypre-y1
dw=np.dot(x.T,error)
dsigmod=ypre*(1-ypre)*x.T
hasen=np.dot(dsigmod,x)
delt=np.linalg.solve(hasen,dw)
self.w-=delt
if np.linalg.norm(delt)<1e-6:
break
self.po.append(self.w)
def predict(self,x):
Probability=[]
x=np.column_stack((np.ones(x.shape[0]),x))
for i in self.po:#循环多次得到x属于每个类的概率
ypre=1/(1+np.exp((-1)*np.dot(x,i)))
Probability.append(ypre)
Probability=np.array(Probability)#每个x属于每个类的概率汇总
ypre=self.kinds[np.argmax(Probability,axis=0)]#获取最大下标
print(Probability)
return ypre效果展示:
数据集为sklearn内置的鸢尾花数据集。

四个大指标都为1,模型效果良好,多元逻辑回归成功实现。
如有不足,还请各位大佬指出。博主会继续虚心学习。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)