
李宏毅机器学习第四周_机器学习任务攻略、局部最小值与鞍点
本文主要介绍了机器学习任务攻略的三个步骤:定义函数、计算 loss、优化,以及如何解决过拟合、局部最小值和鞍点的概念与判断方法,以及如何挑选适合的模型。在机器学习中,需要对预测目标建立函数,并通过计算 loss 来评估模型的好坏,并使用优化方法找出参数使 loss 最小的过程。如果出现 training 数据集的 loss 值偏大,可能是由于模型 bias 或 Gradient Decent 存在
目录
如何区分是local minima还是saddle point?
摘要
本文主要介绍了机器学习任务攻略的三个步骤:定义函数、计算 loss、优化,以及如何解决过拟合、局部最小值和鞍点的概念与判断方法,以及如何挑选适合的模型。在机器学习中,需要对预测目标建立函数,并通过计算 loss 来评估模型的好坏,并使用优化方法找出参数使 loss 最小的过程。如果出现 training 数据集的 loss 值偏大,可能是由于模型 bias 或 Gradient Decent 存在局部最小值的问题,需要重新设计模型或尝试不同的模型来确定问题。如果出现 testing 数据集的 loss 值偏大,则可能存在过拟合的问题,可以通过增加数据、数据扩充、限制模型灵活性、正则化、 early stopping 和 dropout 等方法来解决过拟合问题。同时,本文还介绍了局部最小值和鞍点的概念,并给出了判断方法和应用示例,对深入理解优化方法和模型的训练方式具有指导意义。最后,本文介绍了如何挑选适合的模型,包括将训练数据集分为训练集和验证集,并通过验证集的结果来评估模型的优劣,避免过度拟合,得到更好的结果。
ABSTRACT
This article mainly introduces the three steps of strategy for machine learning tasks: defining the function, calculating the loss, and optimization, as well as how to solve the problem of overfitting, local minimum values, and saddle points. It also discusses the concept of selecting suitable models. In machine learning, it is necessary to establish a function for the prediction target and evaluate the quality of the model by calculating the loss and finding parameters through optimization methods to minimize the loss. If the loss value of the training data set is biased, it may be due to model bias or the problem of local minimum values in Gradient Descent, and the model needs to be redesigned or different models tried to determine the problem. If the loss value of the testing data set is high, there may be an overfitting problem, which can be solved by increasing data, data augmentation, restricting model flexibility, regularization, early stopping, and dropout methods. The article also introduces the concept of local minimum values and saddle points, and gives judgment methods and application examples, which are useful for deepening understanding of optimization methods and training models. Finally, the article describes how to select suitable models by splitting the training data set into training and validation sets and evaluating the model's quality through the validation set results to avoid overfitting and achieve better results.
一、机器学习任务攻略
机器学习一共有三个步骤
- function with unknown
- define loss from training data
- optimization
 将找出的使Loss Function最小的θ,代入到未知参数中,输入测试资料,输出的结果上传到Kaggle。
将找出的使Loss Function最小的θ,代入到未知参数中,输入测试资料,输出的结果上传到Kaggle。
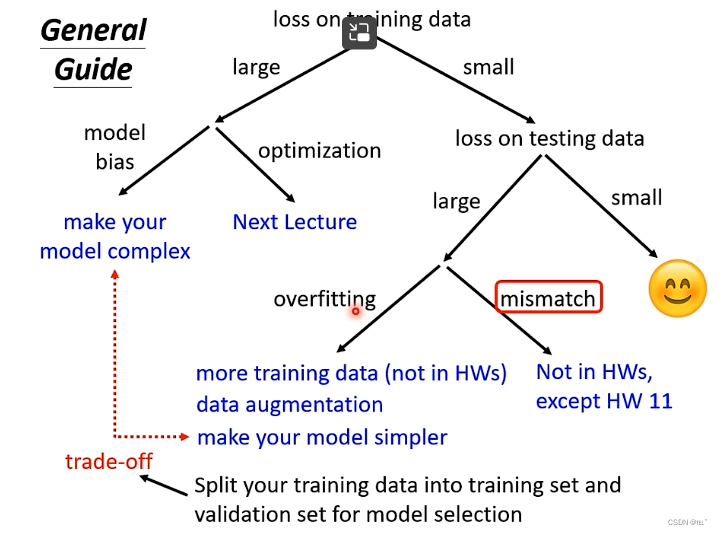
如果Kaggle上的结果不满意,首先要检查Training data的loss值。
Training data loss偏大
如果Training data的loss值很大,显然在训练资料上也不理想,可能是model bias的问题。即定义的model过于简单,无论θ代入何值,没有任何一个Function能使loss变低。即使找出一个θ使Loss Function最小,也不能得到理想结果。解决方法:重新设计model,增加输入的feature,增加更多的neurons,使model更具有弹性。

也可能是optimization不理想,Gradient Decent存在local minima的问题,无法找到使loss值低的参数。
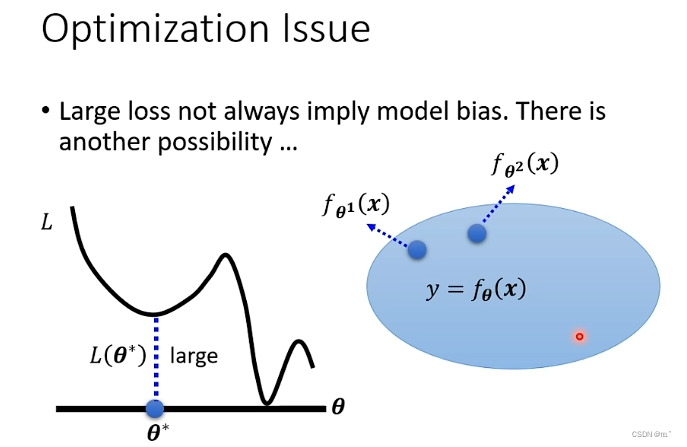
如何确定是model bias的问题导致model弹性不够,还是optimization时Gradient Decent存在local minima的问题导致loss值偏大?
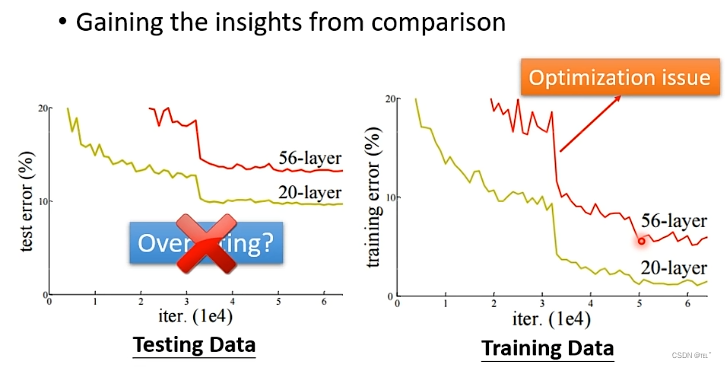
1.比较不同的模型来确定当前的model是否适合。例如:训练两个network,一个network20层,一个56层,在Testing Data上训练。20层的network loss较低,56层的network loss较高。但这并不是过拟合了,在Training Data上,20层的network loss较低,56层的network loss较高,这是因为optimization不理想导致的。因为如果optimization的话,56层的network的loss值一定小于20层的。
2.先训练一些比较浅的network,或者liner model的方法,这些model比较不会出现optimization不理想的问题,可以先得到这些model所得到的loss的大小。再训练一些深的network,如果深的model的loss值不能小于浅的model的loss值,则代表出现了optimization不理想的问题。

Testing Data loss偏大
如果Training Data的loss值已经很小了,则可以检查Testing Data的loss值了。
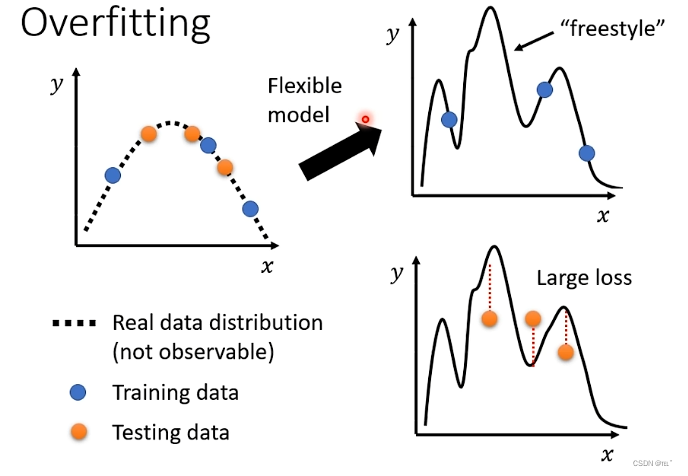
如果Testing Data的loss值偏大就是出现了Overfitting的问题。例如:如图这个函数,在Training data上loss值为0,但是在Testing Data上就非常大。

假设输入x,输出y,x、y是二次曲线的关系,在曲线上随机选择三个点作为Training Data,由于model的灵活性,它会通过这三个点,但是其它没有Training Data作为限制的点就会波动。再用这个model测试Testing Data,会导致训练上的loss小,但测试上的loss大。
解决overfitting的方法:
1.增加训练资料、Data augmentation(创造出新的资料,比如将图片翻转、截图,但是不能过度创造出不合理的图片,比如将图片颠倒)
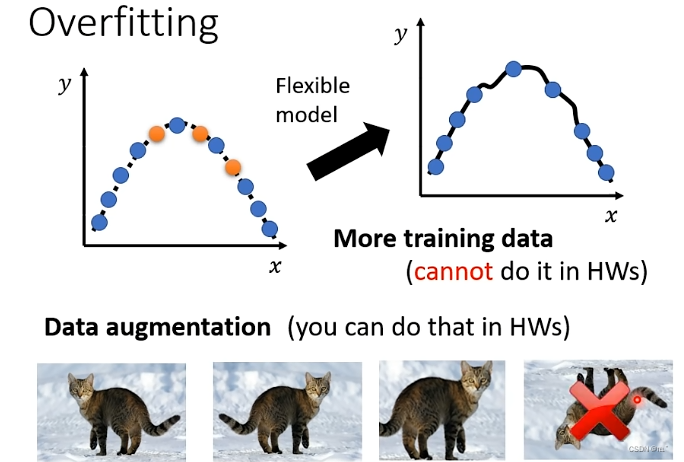
2.给model一些限制,让model没有那么大的弹性,例如:现在的model是二次曲线,所选择的function有限,给出三个点,有可能就会得到比较接近的function,并在测试资料上得到好的结果。(不能过度限制,否则只能找到一条直线,无法将三个点都通过,得不到好的结果,这又会导致model bias的问题)
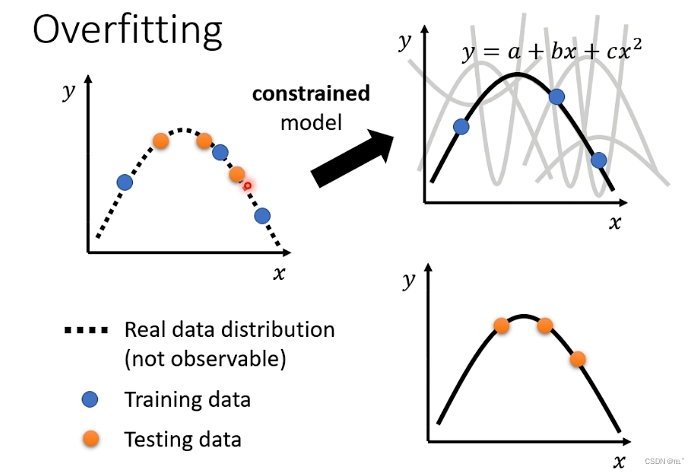
限制model的方法:less parameters,sharing parameters、less features、early stopping、regularization、dropout。
随着model越来越复杂,Training的loss值会越来越低,但是,Testing的loss在刚开始时会越来越小,当复杂的程度超过某一界限,loss值会暴增,这就是overfitting的问题的出现。所以要选择一个适合的model,可以在训练测试资料上得到最小的loss,得到最好的结果。
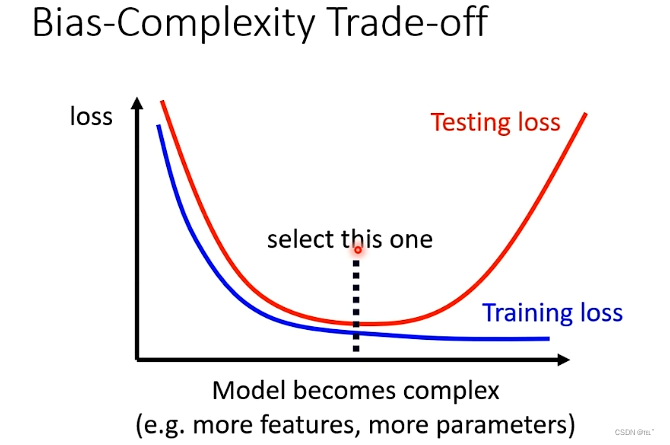
如何选出适合的model?
把Training Set分为两部分,一部分为Training Set,一部分为Validation Set。在Training Set训练出来的model在Validation Set上取衡量他们的分数,根据Validation Set上的分数挑选结果,再将这个结果上传到Kaggle上,得到public的分数。因为挑分数是在Validation Set这个model上,public的分数就可以反应private的分数,这就避免了在public上分数很好,而在private上分数很差。
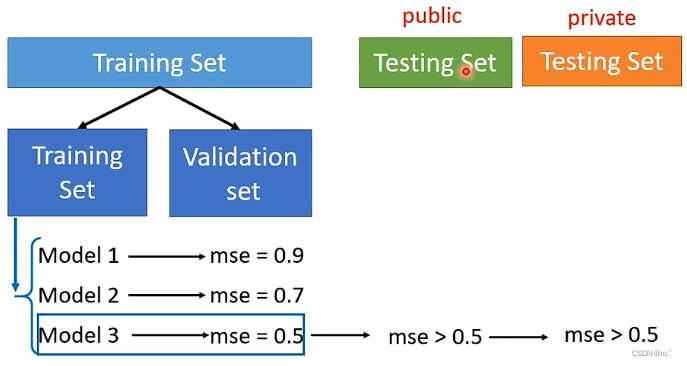
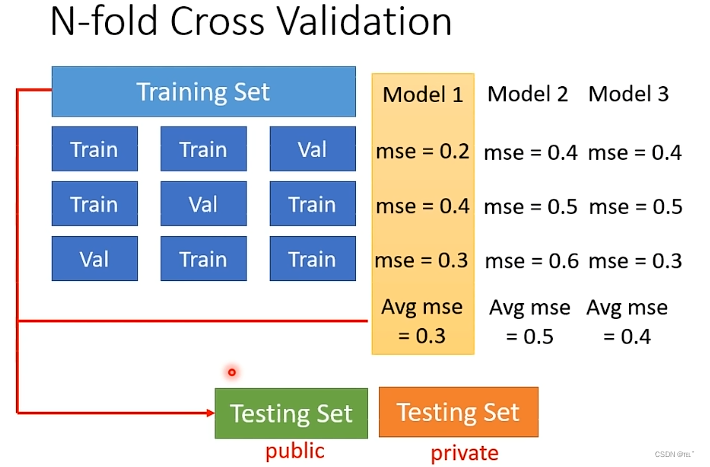
如何分Training Set?
把训练资料分成N等份,例如分成3等份,拿其中的一份作为Validation Set,其它作为Training Set,重复三次。有3个model,将这3个model在Training Set都训练一次,在这三种Training Set的结果平均一下,对比结果。如图,model1最好,再将model1用在全部的Training Set上。
二、局部最小值与鞍点
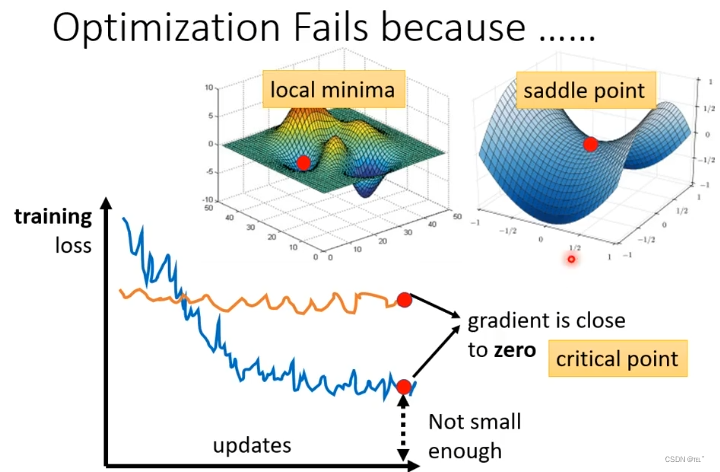
optimization失败:随着参数的不断更新,training loss不会再下降;一开始model就无法训练,training loss不会下降。这是由于参数对loss的微分为0 ,Gradient Decent就无法更新参数,训练停止。Gradient Decent为0有两种情况:1.local minima 2.saddle point,这两种情况统称为critical point。
可以将loss function在 θ 附近表示成L(θ),L(θ)与一次微分和二次微分有关。

如何区分是local minima还是saddle point?
如果现在是在一个critical point,那么微分就等于0,L(θ)就化成如图。根据L(θ)的红色一项判断θ是local minima还是saddle point。
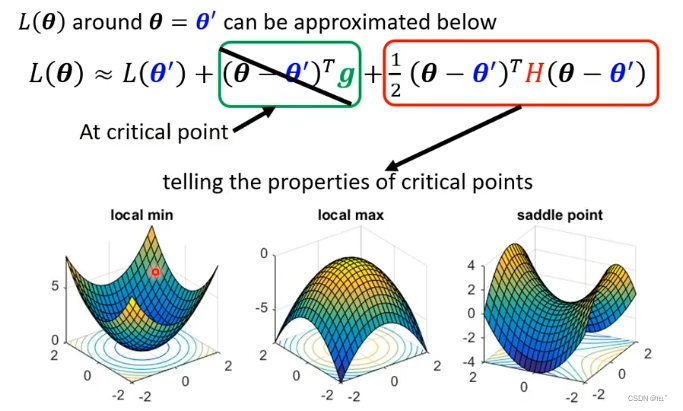
根据求出来值得正负或者H这个向量的特征值可以判断出这个θ是local minima还是saddle point。

矩阵H不仅可以判断出这个点是saddle point,也可以指出参数更新的方向。假设u是H的特征向量,λ 是特征向量u的特征值。如果λ大于0,求出值小于0,则参数更新的方向是沿着u,可以使loss变小。

Example:
如图neural network,只有两个参数w2、w2,得出loss图,在图上可以找到一些critical point。原点处是saddle point,其他是local minima。
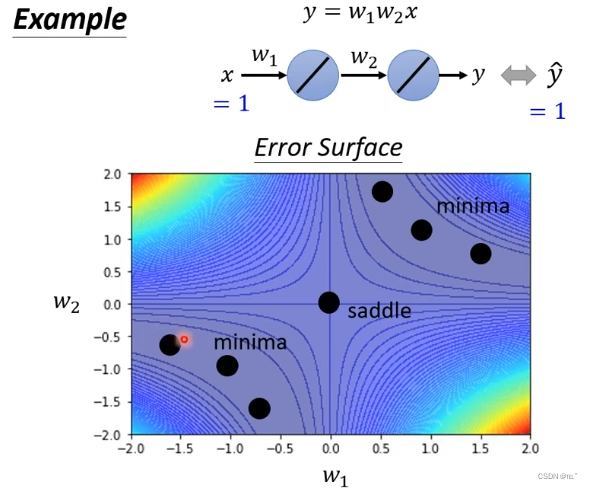
通过计算可以得出一个点是local minima还是saddle point:
原点w1=0、w2=0代入如图可以计算原点为saddle point,特征值λ2=-2,取特征向量u,沿着特征向量u可以得出loss更低的点。

saddle point vs local minima
在一维空间的参数中,local minima很常见,在二维空间中,可能这个local minima只是saddle point。在二维空间中的local minima,在更高维的空间中,可能也只是saddle point。
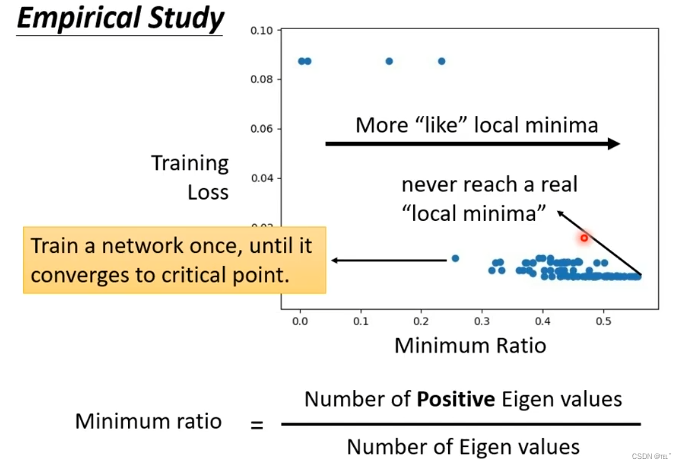
其实local minima非常少见,如图,每一个点代表一个network,纵轴代表loss,横轴代表Minimum Ratio(正的特征值的数量/全部特征值的数量),Minimum Ratio中有正有负代表是saddle point。可以得出local minima并没有那么多。
总结
本文介绍了机器学习任务攻略的三个步骤,包括定义函数、计算loss以及优化过程,同时提出了解决过拟合问题的方法,如增加训练数据、限制模型灵活度等。另外,本文还介绍了局部最小值和鞍点的概念,以及如何判断一个点是局部最小值还是鞍点,并给出了一个神经网络的例子来说明如何使用特征值和特征向量判断是局部最小值还是鞍点。最后,文章说明了在高维空间中,局部最小值并不常见。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)