怎样判断keras模型是否使用了tpu_15 分钟搭建一个基于XLNET的文本分类模型
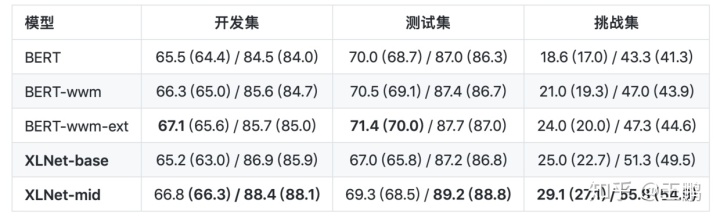
今天笔者将简要介绍一下后bert 时代中一个又一比较重要的预训练的语言模型——XLNET ,下图是XLNET在中文问答数据集CMRC 2018数据集(哈工大讯飞联合实验室发布的中文机器阅读理解数据,形式与SQuAD相同)上的表现。我们可以看到XLNET的实力略胜于BERT。这里笔者会先简单地介绍一下XLNET精妙的算法设计,当然我尽量采用通俗的语言去表达那些深奥的数学表达式,整个行文过程会直接采用
今天笔者将简要介绍一下后bert 时代中一个又一比较重要的预训练的语言模型——XLNET ,下图是XLNET在中文问答数据集CMRC 2018数据集(哈工大讯飞联合实验室发布的中文机器阅读理解数据,形式与SQuAD相同)上的表现。我们可以看到XLNET的实力略胜于BERT。
这里笔者会先简单地介绍一下XLNET精妙的算法设计,当然我尽量采用通俗的语言去表达那些深奥的数学表达式,整个行文过程会直接采用原论文的行文流程:Observition—>Motivition—>Contribution。然后我会介绍一下如何用python在15分钟之内搭建一个基于XLNET的文本分类模型。
XLNET的原理
Observision
XLNET的原论文将预训练的语言模型分为两类:
1. 自回归:根据上文预测下文将要出现的单词,让模型在预训练阶段去做补充句子任务,其中代表模型就是GPT。
把句子补充完整。
1.秋天到了,__。
2 .自编码:根据上下文去预测中间词,其实就是让模型在预训练阶段去做完形填空任务,其中的代表模型就是BERT,在实际预训练过程中用[MASK]这个字符替代要被预测的目标单词。
请选择最合适的词填入空缺处
1.这种梦说明你正在__挑战,但你还没有做好准备。
A.面临 B.逃避 C.参考 D.承担
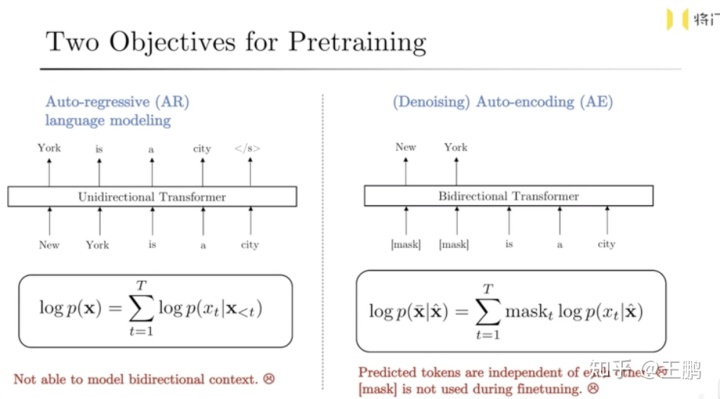
但这两种语言模型都有各自的不足之处,如下图所示:
- 自回归语言模型:由于是标准的单向语言模型,无法看到下文的信息,可能导致信息利用不充分的问题,实际的实验结果也证明利用上下文信息的BERT的效果要强于只利用上文信息的GPT。
- 自编码语言模型:1.预训练阶段(存在[Mask] 字符)和finetuning 阶段(无[Mask] 字符)文本分布不一致,会影响到下游任务的funetuning效果。2.被预测的token(词或者字)之间彼此独立,没有任何语义关联,
Motivation
- 解决自回归语言模型无法获取下文信息(预知未来)的问题
- 优化自编码语言模型存在的两个缺点:1.预训练阶段(存在[Mask] 字符)和finetuning 阶段(无[Mask] 字符)文本分布不一致,2.被预测Mask词之间彼此独立,不符合人的认知。
Contribution
有了上面两个Motivation,作者就提出了XLNET去解决这两个问题,这里我不会引入公式,只是简单的解释一下XLNET的三个比较创新的设计。
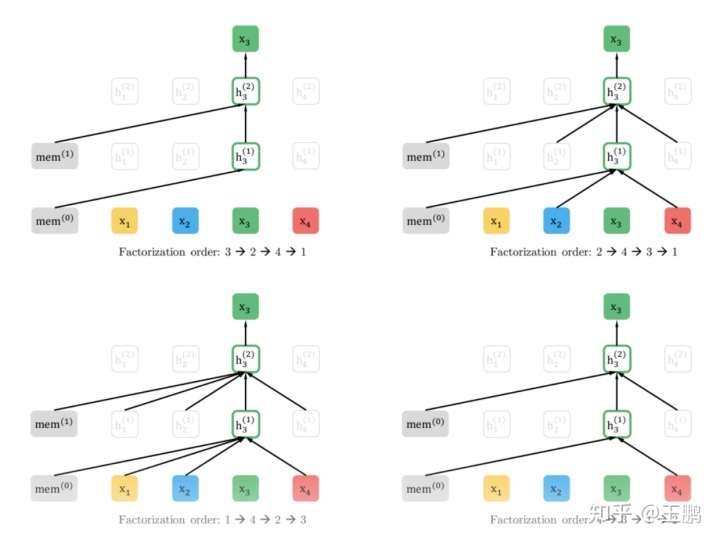
- Permutation Language Model:这个部分是XLNET最精彩的设计。主要目的就是为了解决单向语言模型无法利用下文信息的缺陷,如下图所示,其实就是对句子的顺序做随机打乱后,然后作为单向语言模型的输入。预训练时需预测当前位置的token。我们来详细体会一下 Permutation Language Model的过程。
1 .假设我们有一个序列[1,2,3,4],预测目标是3。
2 .先对该序列进行因式分解,对句子的顺序做随机打乱,最终会有24种排列方式,下图是其中可能的四种情况。
3 .其中右上的图中,3的左边还包括了2与4,以为着我们在预测3的时候看到3这个token上下文的信息,同时依然保持着单向的语言模型。
这部分的设计就是为了解决之前的自回归和自编码语言模型的缺陷,也就是Motivation中的两个问题。所以这个设计是整片文章最精妙的部分。
接下来的两个设计主要为了解决构建Permutation Language Model带来的两个问题:
1.序列进行因式分解使得token失去位置感。
2.序列进行因式分解使得进行预测时模型能够提前看到答案。
- Reparameterization with positions:由于Permutation Language Model对句子顺序做了随机打乱,可能会导致模型失去对某个token在句子中的原始位置的感知,导致模型退化成一个词袋模型,于是作者利用Reparameterization with positions去解决这个问题。
- Two-stream attention
这部分的设计依然是为了解决Permutation Language Model留下的另外一个问题,细心的读者会发现序列因式分解会使得被预测的token被提起预知,回到上图:有一个序列[1,2,3,4],预测目标是3。可是其中有个因式分解的顺序是[3,2,4,1] 导致预测3的时候提前拿到了3的信息,这样就使得预训练的过程变得无意义了,于是作者设计了Two-stream attention:
1.一个query stream只编码目标单词以外的上下文的信息以及目标单词的位置信息。
2.一个content stream既编码目标单词自己的信息,又编码上下文的信息供。
query stream 的作用就是避免了模型在预训练时提前预知答案。 而做下游任务 fine-tune 时将query stream去掉,这样就完美的解决了这个问题。
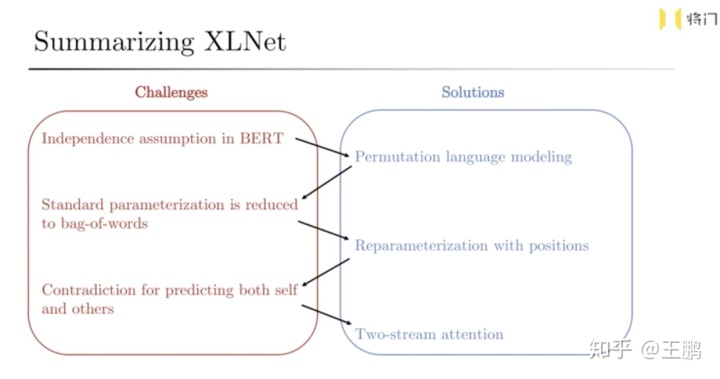
下图就是文章作者的PPT中对XLNET的总结。具体如果实作的建议读者去看看原文和作者对XLNET的讲解视频つロ 干杯~-bilibili
XLNET实战部分
好的,经过了不是特别深刻的XLNET原理简介,来到我们激动人心的实战部分。(其实上文原理部分只是希望大家在感性上知道XLNET到底做了些什么,至于如何做到的还请拜读原文和源代码)。
准备工作
- 1.首先你需要这个网址下载(https://github.com/ymcui/Chinese-PreTrained-XLNet) XLNET中文版的预训练的权重——tensorflow版,感谢大佬的开源。
- 2.在你的python环境中安装CyberZHG 大佬开源的keras版的keras-xlnet ,之间pip install keras-xlnet一键安装,同时读者也可以去https://github.com/CyberZHG/keras-xlnet具体看看keras-xlnet使用方法。
- 3.下方实战代码,主要借鉴CyberZHG 大佬XLNET情感分析代码的demo(CyberZHG/keras-xlnet),针对自己的任务做了一点点修改,感谢大佬的开源。
定义一下超参数和预训练模型的路径
import os
import sys
from collections import namedtuple
import numpy as np
import pandas as pd
from keras_xlnet.backend import keras
from keras_bert.layers import Extract
from keras_xlnet import Tokenizer, load_trained_model_from_checkpoint, ATTENTION_TYPE_BI
from keras_radam import RAdam
### 预训练模型的路径
pretrained_path = "/opt/developer/wp/xlnet/pretrain"
EPOCH = 10
BATCH_SIZE = 16
SEQ_LEN = 256
MODEL_NAME = 'xlnet_cls.h5'
PretrainedPaths = namedtuple('PretrainedPaths', ['config', 'model', 'vocab'])
config_path = os.path.join(pretrained_path, 'xlnet_config.json')
model_path = os.path.join(pretrained_path, 'xlnet_model.ckpt')
vocab_path = os.path.join(pretrained_path, 'spiece.model')
paths = PretrainedPaths(config_path, model_path, vocab_path)
tokenizer = Tokenizer(paths.vocab)数据准备
这里我选择了一个语义相似度判断的任务——及判断两个问题是否是同一个问题。数据集如下图所示:
如上图所示:数据集共2万条,主要任务就是判断question1 和 question2 是否为同一问题。label为1则是同一个问题,label为0则不是同一个问题。其中还有列标注了问题的类型。
在由于XLNET的输入为单输入,于是笔者将数据预处理成 “问题类型:’question1是否和question2是同一个问题?”。举个例了,上图数据集的第一条数据最终变成如下格式:
- data: aids:艾滋病窗口期会出现腹泻症状吗是否和头疼腹泻四肢无力是不是艾滋病是同一个问题?
- label:0
# Read data
class DataSequence(keras.utils.Sequence):
def __init__(self, x, y):
self.x = x
self.y = y
def __len__(self):
return (len(self.y) + BATCH_SIZE - 1) // BATCH_SIZE
def __getitem__(self, index):
s = slice(index * BATCH_SIZE, (index + 1) * BATCH_SIZE)
return [item[s] for item in self.x], self.y[s]
def generate_sequence(df):
tokens, classes = [], []
for _, row in df.iterrows():
###这里笔者将数据进行拼接 类型+问题1+问题2
text, cls = row["category"] + ":"+ row['question1'] + "是否和" + row['question2'] + "是同一个问题?", row['label']
encoded = tokenizer.encode(text)[:SEQ_LEN - 1]
encoded = [tokenizer.SYM_PAD] * (SEQ_LEN - 1 - len(encoded)) + encoded + [tokenizer.SYM_CLS]
tokens.append(encoded)
classes.append(int(cls))
tokens, classes = np.array(tokens), np.array(classes)
segments = np.zeros_like(tokens)
segments[:, -1] = 1
lengths = np.zeros_like(tokens[:, :1])
return DataSequence([tokens, segments, lengths], classes)
### 读取数据,然后将数据
data_path = "/opt/developer/wp/xlnet/data/train.csv"
data = pd.read_csv(data_path)
test = data.sample(2000)
train = data.loc[list(set(data.index)-set(test.index))]
### 生成训练集和测试集
train_g = generate_sequence(train)
test_g = generate_sequence(test)加载模型
加载事先下载好的xlnet的预训练语言模型,然后再接两个dense层和一个bn层构建一个类别为2的分类器。
# Load pretrained model
model = load_trained_model_from_checkpoint(
config_path=paths.config,
checkpoint_path=paths.model,
batch_size=BATCH_SIZE,
memory_len=0,
target_len=SEQ_LEN,
in_train_phase=False,
attention_type=ATTENTION_TYPE_BI,
)
#### 加载预训练权重
# Build classification model
last = model.output
extract = Extract(index=-1, name='Extract')(last)
dense = keras.layers.Dense(units=768, name='Dense')(extract)
norm = keras.layers.BatchNormalization(name='Normal')(dense)
output = keras.layers.Dense(units=2, activation='softmax', name='Softmax')(norm)
model = keras.models.Model(inputs=model.inputs, outputs=output)
model.summary()针对下游任务fine-tuning
接下来只需要定义好优化器,学习率,损失函数,评估函数,以及一些回调函数,就可以开始针对语义相似度判断任务进行模型微调了。
# 定义优化器,loss和metrics
model.compile(
optimizer=RAdam(learning_rate=1e-5),
loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'],
)
### 定义callback函数,只保留val_sparse_categorical_accuracy 得分最高的模型
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint("./model/best_xlnet.h5", monitor='val_sparse_categorical_accuracy', verbose=1, save_best_only=True,
mode='max')
模型训练
model.fit_generator(
generator=train_g,
validation_data=test_g,
epochs=EPOCH,
callbacks=[checkpoint],
)下发截图是模型训练过程,看起来还不错,loss下降和sparse_categorical_accuracy得分上升都很稳定。

至于最后效果,我只和bert做了一个简单的对比。在这个任务上,xlnet相较于bert稍微弱了2个百分点,可能是由于文本过短的原因或者我自己打开的方式不对,对应xlnet的finetune还是需要好好研究。最后的感觉就是深度学习的炼丹之路任重而道远,大家且行且珍惜。
结语
预训练的语言模型成为NLP的热点,通过无监督的预训练让模型学习领域基础知识,之后专注在这个领域的某个下游任务上才能有所建树。这个过程和我们大学教育培养模式很像,大学四年海纳百川式的学习一些基本的科学知识,研究生之后专注于某个方向深入研究。所以这个过程make sense。笔者认为以下三个方向是预训练模型还可以更进一步的方向:
- 更好,更难的的无监督预训练的任务(算法)
- 更精妙的网络设计(算法)
- 更大,更高质量的数据(算力)
参考文献
xlnet原文
CyberZHG/keras-xlnet
https://github.com/ymcui/Chinese-PreTrained-XLNet
Recurrent.ai联合创始人 杨植麟:自然语言理解模型:XLNet_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)