
深度学习Keras(六):dogs vs cats数据集(卷积神经网络)(一)
在Francois Chollet先生的书中,首先对猫狗图片数据集进行了规模上的缩小,这里将直接使用缩小后的数据集进行神经网络的训练。#利用已经划分好的小数据集来训练import numpy as npimport matplotlib.pyplot as pltfrom keras import layers, models, optimizers#使用ImageDataGenerator从目录
·
在Francois Chollet先生的书中,首先对猫狗图片数据集进行了规模上的缩小,这里将直接使用缩小后的数据集进行神经网络的训练。
#利用已经划分好的小数据集来训练
import numpy as np
import matplotlib.pyplot as plt
from keras import layers, models, optimizers
#使用ImageDataGenerator从目录中读取图像
from keras.preprocessing.image import ImageDataGenerator
train_dir = '/home/wildchap/cats_and_dogs_small/train'
test_dir = '/home/wildchap/cats_and_dogs_small/test'
validation_dir = '/home/wildchap/cats_and_dogs_small/validation'
#将所有图像缩放255倍
train_datagen = ImageDataGenerator(rescale=1.0/255)
test_datagen = ImageDataGenerator(rescale=1.0/255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150), #图像大小为150*150
batch_size=20,
class_mode='binary') #二进制标签
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
#测试生成器输出
'''for data_batch, label_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('label batch shape:', label_batch.shape)'''
#定义模型
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
#编译模型
model.compile(optimizer=optimizers.RMSprop(lr=1e-4), loss='binary_crossentropy', metrics=['acc'])
#利用批量生成器拟合模型
History = model.fit_generator(
train_generator,
steps_per_epoch=100, #每次取20个样本作为依据梯度下降,如此100次
epochs=30,
validation_data = validation_generator,
validation_steps=50)
#保存模型
model.save('cats_and_dogs_small_1.h5')
#绘制其在训练数据和验证数据上的精度
acc = History.history['acc']
val_acc = History.history['val_acc']
loss = History.history['loss']
val_loss = History.history['val_loss']
x = range(1, len(acc)+1)
plt.plot(x, acc, 'bo', label='Train_acc')
plt.plot(x, val_acc, 'b', label='Validation_acc')
plt.xlabel('epoch')
plt.ylabel('acc')
plt.title('accuracy')
plt.legend()
plt.figure()
plt.plot(x, loss, 'bo', label='Train_loss')
plt.plot(x, val_loss, 'b', label='Validation_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title('loss')
plt.legend()
plt.show()
可以很明显的发现,由于数据量少,发生了过拟合。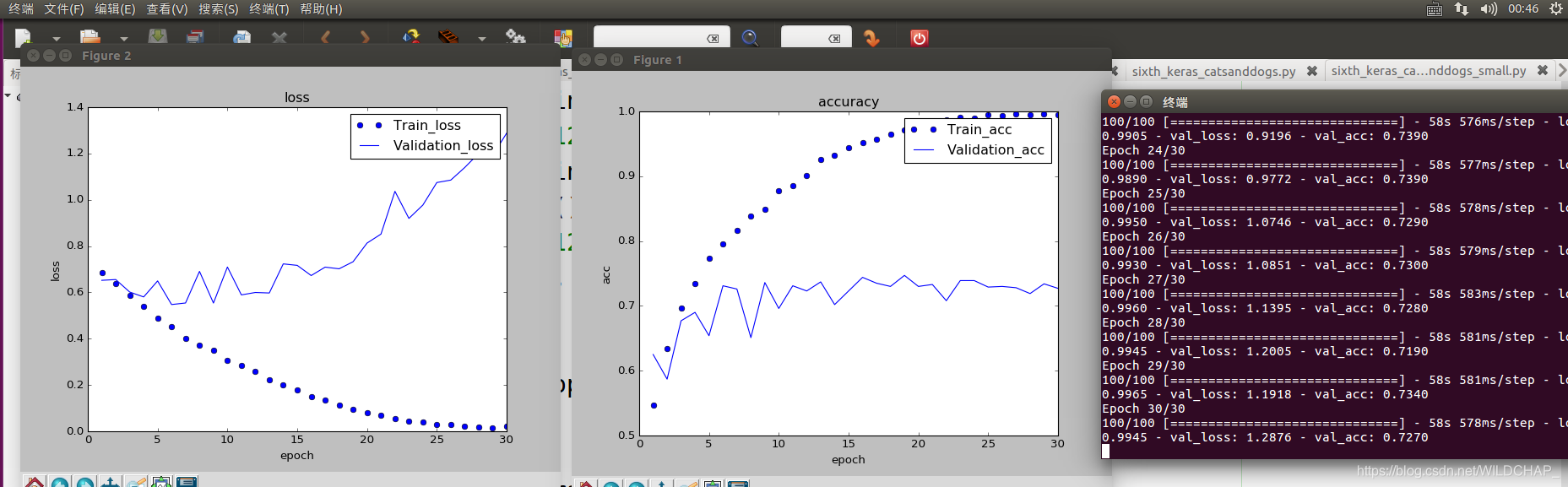

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)