【深度学习目标检测|YOLO算法3】YOLO家族进化史:从YOLOv1到YOLOv11的架构创新、性能优化与行业应用全解析...
【深度学习目标检测|YOLO算法3】YOLO家族进化史:从YOLOv1到YOLOv11的架构创新、性能优化与行业应用全解析...
【深度学习目标检测|YOLO算法3】YOLO家族进化史:从YOLOv1到YOLOv11的架构创新、性能优化与行业应用全解析…
【深度学习目标检测|YOLO算法3】YOLO家族进化史:从YOLOv1到YOLOv11的架构创新、性能优化与行业应用全解析…
文章目录
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz
论文地址:https://www.preprints.org/manuscript/202410.1785/v1
3. Single Stage Object Detectors
3.1. Understanding Single-Stage Detectors in Object Detection: Concepts, Architecture, and Applications
单阶段目标检测器是一类通过神经网络的单次前向传递来检测图像中的物体的模型【10】。与两阶段检测器需要分别进行区域提议和物体分类不同,单阶段检测器同时执行这两个任务,从而简化了检测过程【8】。这种方法因其简单性、计算效率和实时处理能力而受到广泛欢迎,尤其适用于需要快速推理的应用场景,如自动驾驶和监控系统【15】。
典型的单阶段检测器直接预测物体类别概率和边界框,无需使用区域提议网络(RPN)【4,16】。单阶段目标检测器的几个关键概念如下:
(1)统一架构
- 这些检测器采用统一的神经网络架构,同时预测边界框和类别概率,省去了单独的区域提议阶段【17】。
(2)锚框(Anchor Boxes)或默认框(Default Boxes)
- 为适应不同物体的尺度和长宽比,单阶段检测器使用锚框(也称为默认框)【18】。这些预定义框允许网络进行调整,以更好地拟合不同形状和尺寸的物体。
(3)回归和分类头
- 单阶段检测器由两个主要组件组成:回归头用于预测边界框坐标,分类头用于确定物体类别。两个头都在输入图像提取的特征图上进行操作【19】。
(4)损失函数
- 模型的训练目标是最小化三种损失的组合:定位损失(用于准确的边界框预测)、置信度损失(用于物体的存在与否)、分类损失(用于类别标签的准确性)【20】。
(5)非极大值抑制(NMS)
- 在预测多个边界框后,应用非极大值抑制过滤掉低置信度和重叠的预测框,确保仅保留最有信心且不冗余的边界框【21,22】。
(6)效率和实时处理
- 单阶段检测器的主要优势之一是其计算效率,使其适合实时处理。省去了单独的区域提议步骤,减少了计算开销,从而实现快速检测【23】。
(7)应用
- 单阶段检测器广泛应用于多个领域,包括自动驾驶、监控、机器人技术以及图像和视频中的物体识别。其速度和简洁性使其特别适合需要实时检测的场景。这些应用得到许多研究的支持,突显了单阶段检测器在动态环境中的效率和有效性,尤其在自动驾驶和行人检测场景中的表现【24-27】。在监控系统中,单阶段检测器支持连续监控和快速响应,这是安全应用所必需的【25】。在机器人技术中,这些检测器辅助实时物体识别,促进了导航和与环境的交互【28,29】。因此,单阶段检测器的多功能性和高性能使其成为现代技术应用中的关键组成部分。
这些特性使单阶段检测器成为物体检测中的重要工具,平衡了速度和准确性,同时支持广泛的实际应用。单阶段检测器的工作流程如图1所示。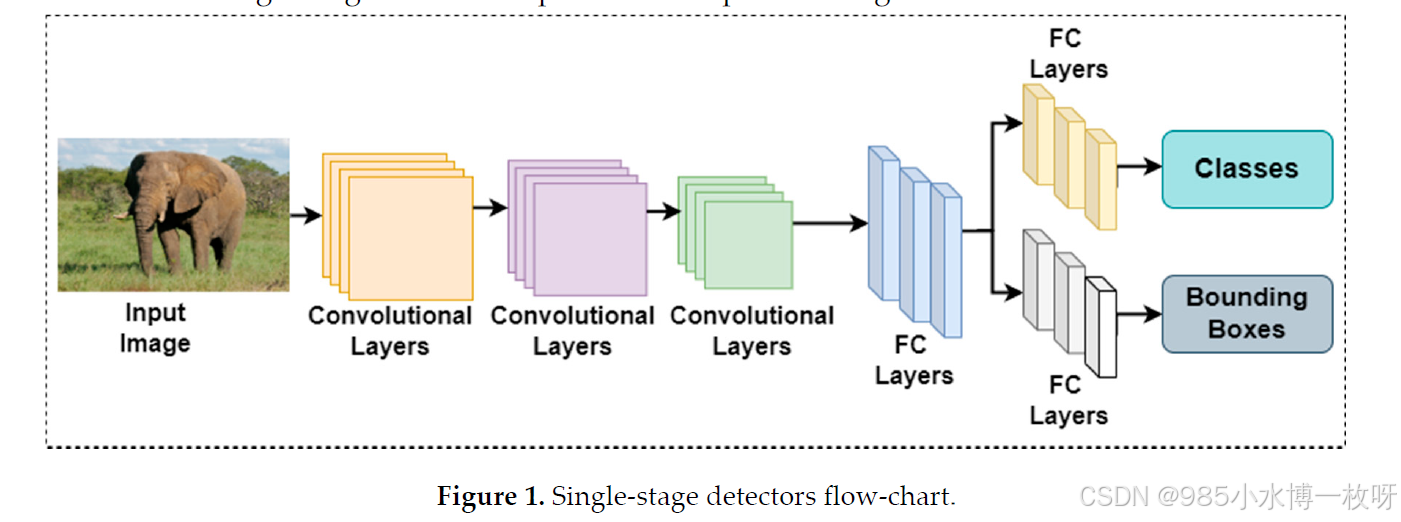
3.2. Typical Single-Stage Object Detectors
多年来,已经开发了几种单阶段目标检测器,每种都有其独特的创新和优化。以下是一些关键单阶段检测器的概述,包括它们的架构及对目标检测领域的贡献:
SSD (Single Shot Detectors)
Single Shot MultiBox Detector (SSD):由Liu等人在2016年提出【30】,SSD采用卷积神经网络(CNN)作为特征提取的骨干网络。SSD利用基础网络的多个层次生成多尺度特征图,使其能够检测不同尺度的物体。对于每个特征图尺度,SSD为不同的长宽比和尺寸分配锚框,并同时预测物体类别得分和边界框偏移量。预测完成后,应用非极大值抑制(NMS)来去除重复的边界框,保留最有信心的检测。SSD的架构如图2所示。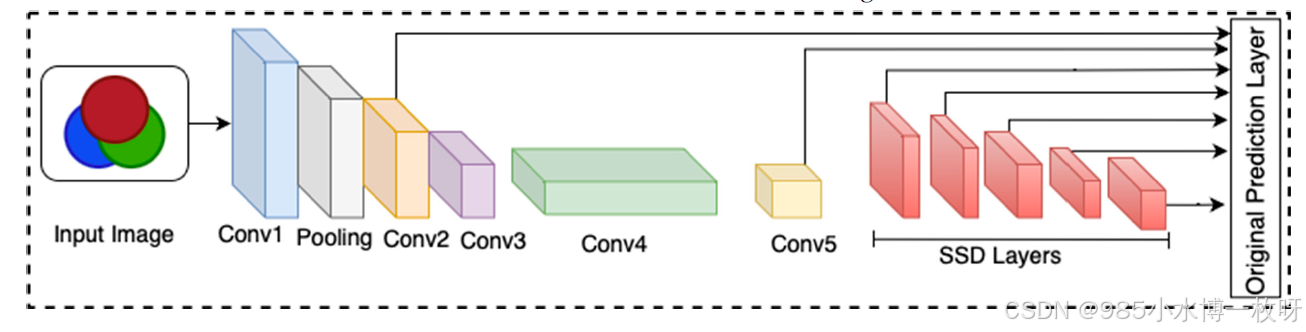
DenseBox
DenseBox:由Huang等人开发【31】,DenseBox将物体定位和分类集成在一个框架内。与其他依赖稀疏锚框的模型不同,DenseBox在整个图像上密集地预测边界框,从而提高定位精度。该模型采用深度CNN进行特征提取,随后通过非极大值抑制来精炼物体检测。DenseBox的密集预测机制提高了对小物体和紧密排列物体的检测性能。图3展示了DenseBox的详细架构。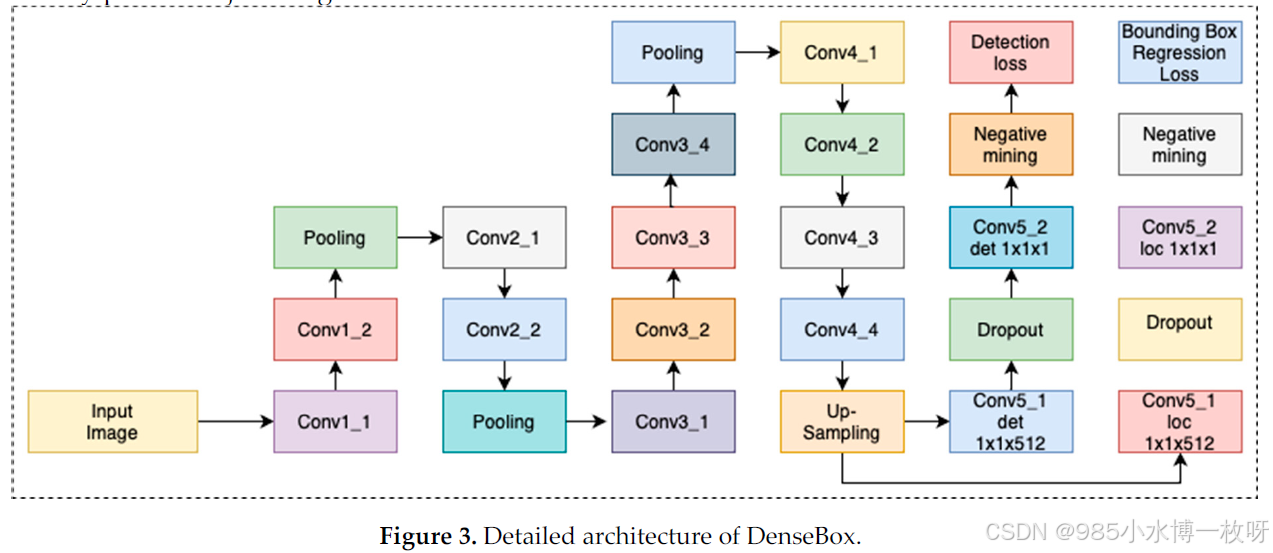
RetinaNet
RetinaNet:由Lin等人提出【32】,RetinaNet解决了目标检测任务中常见的类别不平衡问题。该架构结合了特征金字塔网络(FPN)进行多尺度特征提取,并采用了新颖的焦点损失函数,训练时对难以检测的物体赋予更高的权重。该损失函数有助于缓解前景与背景类别之间的不平衡,使RetinaNet在物体稀疏出现的场景中尤其有效。RetinaNet的工作流程如图4所示。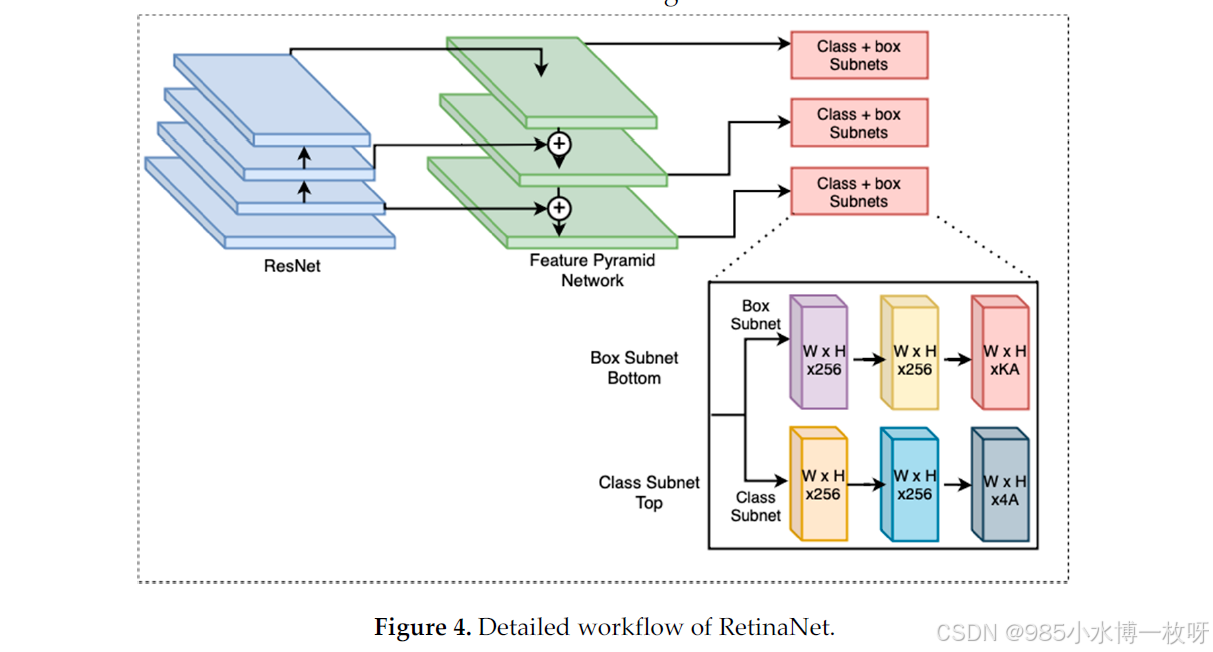
RFB Net (RefineNet with Anchor Boxes)
RFB Net (RefineNet with Anchor Boxes):由Niu和Zhang开发【33】,RFB Net在基础RefineNet架构的基础上进行改进,采用不同尺寸和长宽比的锚框以提高检测性能,特别是对小物体的检测。该模型应用一系列精细化阶段,逐步提升定位精度和分类信心。RFB Net的架构如图5所示。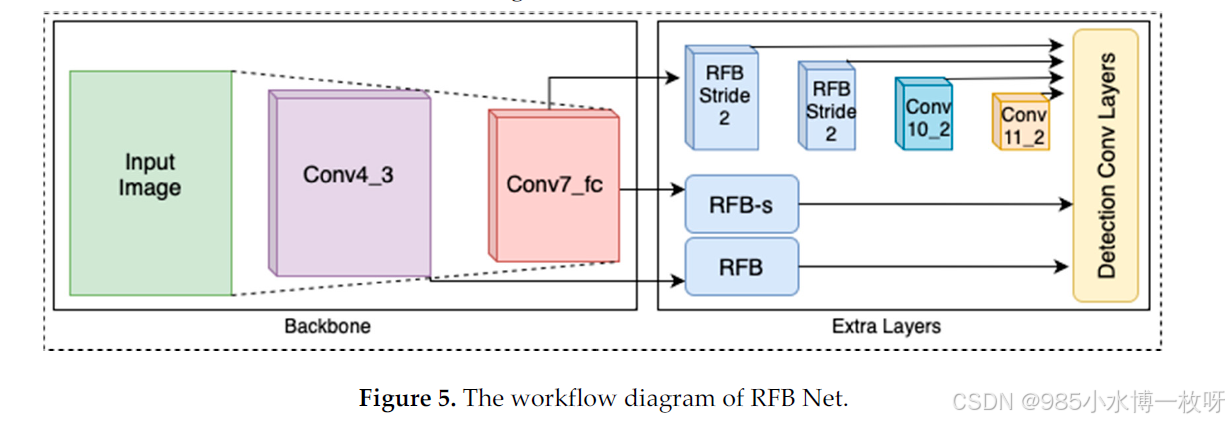
EfficientDet
EfficientDet:由Tan和Le提出【34】,**EfficientDet引入了一种复合缩放方法,同时增加网络深度、宽度和分辨率,同时保持计算效率。EfficientDet使用双向特征金字塔网络(BiFPN)进行高效的多尺度特征融合,平衡了模型大小和性能。**这一设计在降低计算复杂度的同时,实现了最先进的目标检测结果,特别适用于资源受限的应用。EfficientDet的架构如图6所示。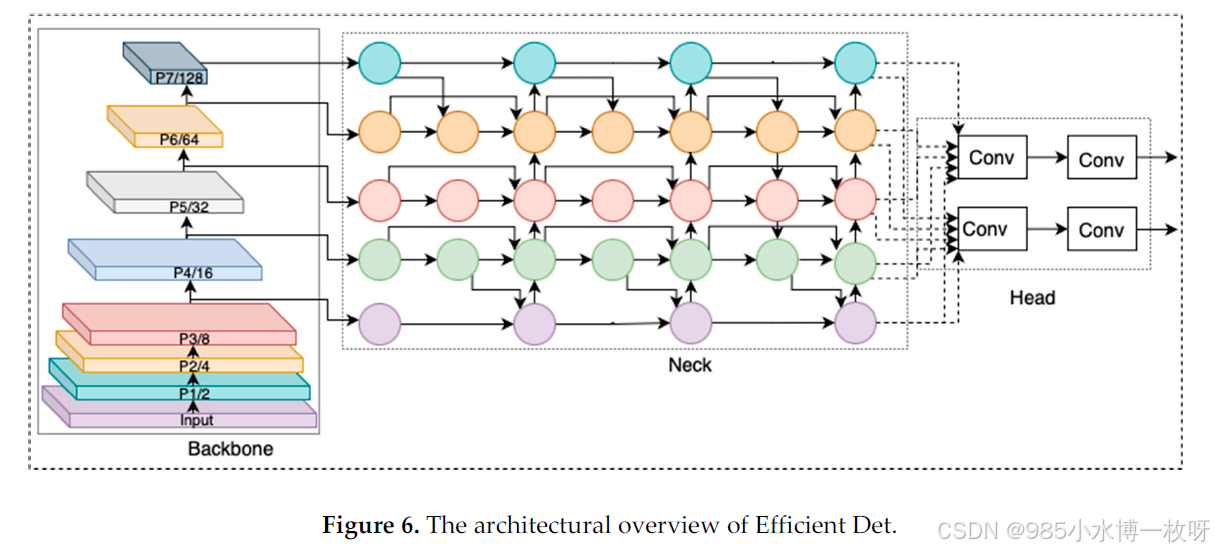
YOLO (You Only Look Once)
YOLO (You Only Look Once):由Joseph Redmon开创,YOLO通过引入基于网格的方法来同时预测边界框和类别概率,革新了实时目标检测【35】。这一创新设计实现了高效的检测过程,使YOLO特别适合需要实时性能的应用。自发布以来,YOLO架构经历了不断演化,从YOLOv1到最新的YOLOv9,每个版本都在准确性、速度和效率方面有所提升【36】。重要进展包括引入锚框,以改进模型对不同形状和尺寸物体的检测能力,并优化了新的损失函数以提高性能。此外,每个YOLO版本还优化了骨干网络,以提高处理速度和检测能力。
YOLO框架从2015年到2023年的演变展示了其在目标检测中不断应对新挑战的改进【37】。每次修订都在最大化检测精度、最小化延迟方面取得了进展,这是实时目标检测技术发展的核心目标。YOLO的演变时间线见图7。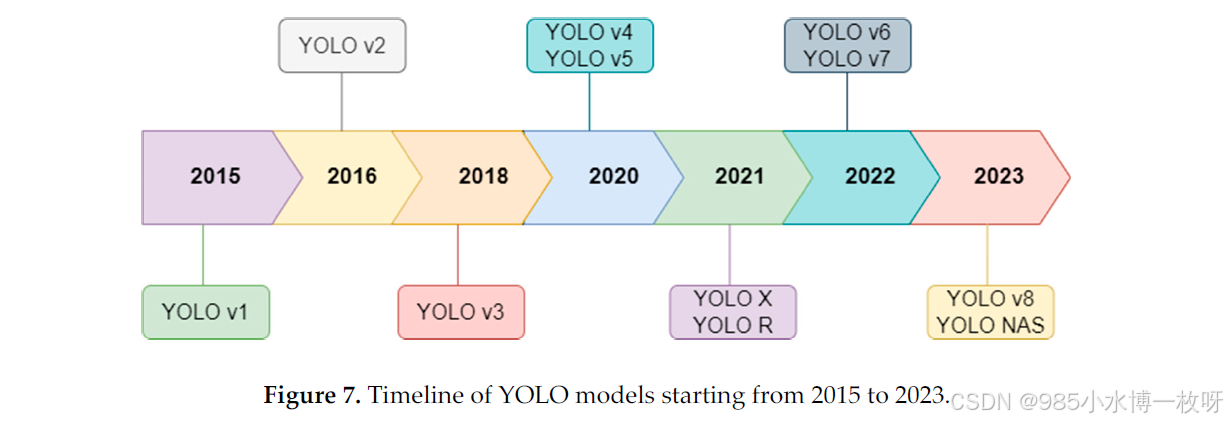
YOLO通过将图像划分为网格并同时预测边界框和类别概率来快速准确地识别物体。边界框坐标和类别概率由卷积层生成,随后通过深度卷积神经网络(CNN)进行特征提取。YOLO通过在多个尺度上使用锚框,改善了对不同尺寸物体的检测。最终检测结果通过非极大值抑制(NMS)进行精炼,去除冗余和低置信度的预测,使YOLO成为一种高效且可靠的目标检测方法。
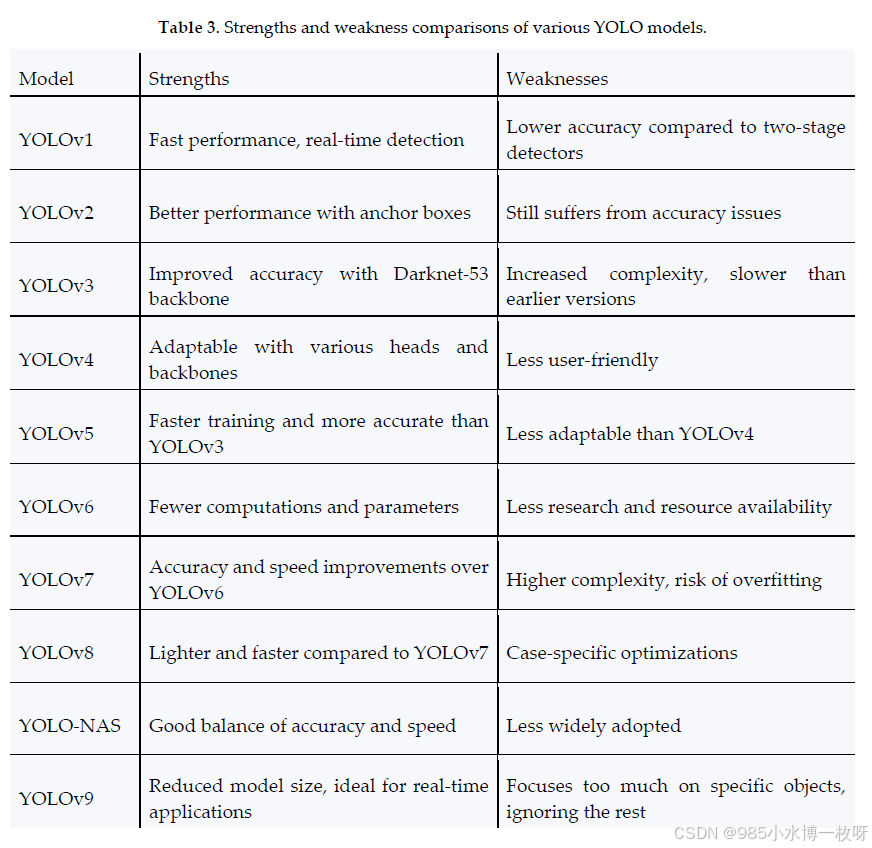
每个YOLO变种都引入了旨在优化速度和准确性的独特创新。例如,YOLOv4和YOLOv5集成了先进的骨干网络和损失函数,如完全交并比(CIoU),以改善物体定位。下表2总结了不同YOLO模型中使用的损失函数,突出了它们对分类和边界框回归的贡献。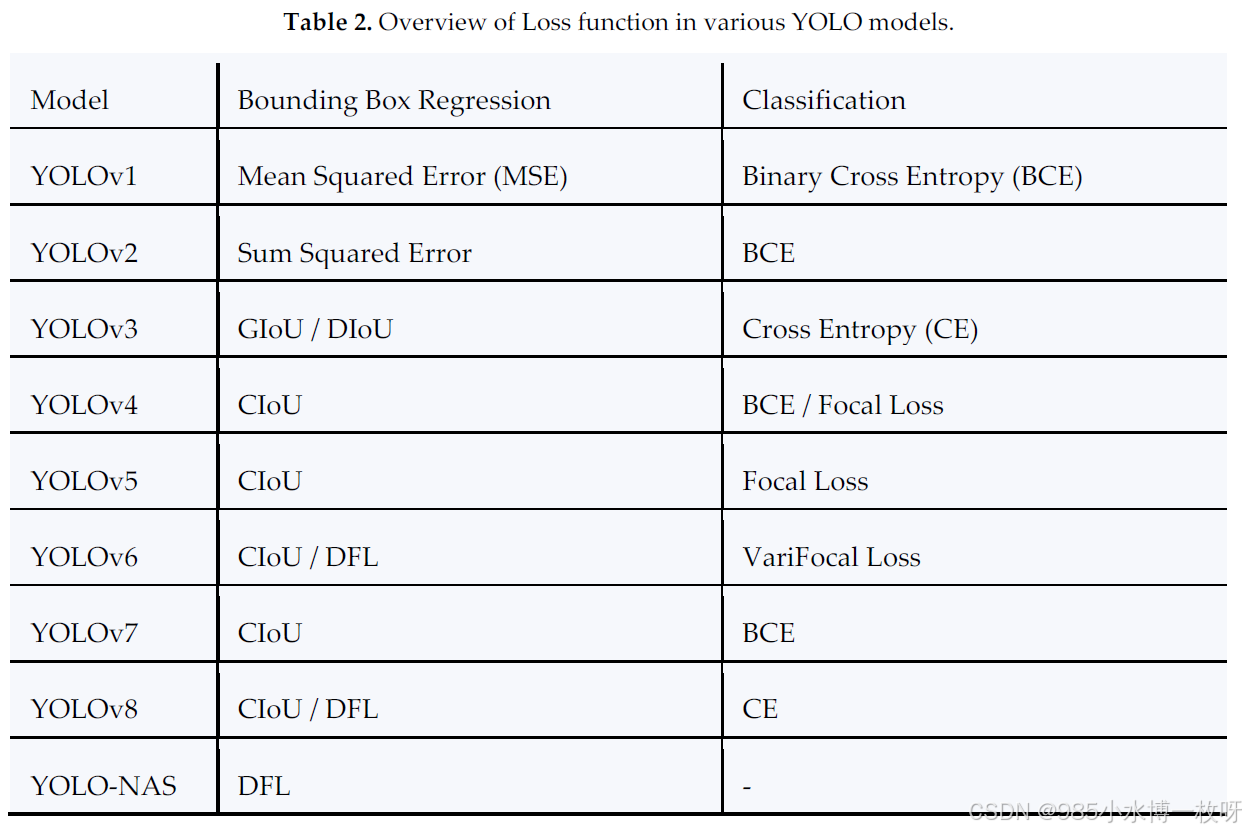

3.3. The YOLO Architecture: Backbone, Neck, and Head
YOLO架构的三个主要组成部分——骨干网络(Backbone)、颈部(Neck)和头部(Head)——在不同版本中经历了显著的修改,以提升性能:
- 骨干网络(Backbone):负责从输入数据中提取特征【38】。骨干网络通常是经过大规模数据集(如ImageNet)预训练的卷积神经网络(CNN)。YOLO各版本常用的骨干网络包括ResNet50、ResNet101和CSPDarkNet53。
- 颈部(Neck):颈部进一步处理和精炼骨干网络生成的特征图。它通常采用特征金字塔网络(FPN)和空间注意模块(SAM)【39】等技术,以改善特征表示能力。
- 头部(Head):头部处理来自颈部的融合特征,预测边界框和类别概率。YOLO的头部通常使用多尺度锚框,确保有效检测不同尺度的物体【40】。
欢迎宝子们点赞、关注、收藏!欢迎宝子们批评指正!
祝所有的硕博生都能遇到好的导师!好的审稿人!好的同门!顺利毕业!
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议入口:https://ais.cn/u/mmmiUz

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 13
13 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)