
机器学习算法中Apriori关联规则算法(举例说明)
Apriori算法是一种用于关联规则学习中频繁项集挖掘的经典算法。它主要用于事务数据库中查找项集(如购物篮中的商品),这些项集在数据库中频繁出现,并基于这些频繁项集生成强关联规则。简单地说,Apriori帮助我们发现在大量数据中一起出现的事物的模式。想象一下,你经营一家小杂货店,并想了解顾客购买商品之间的关系,以便更好地管理库存和布置货架。例如,如果你发现买面包的顾客也经常买牛奶,那么将面包和牛奶
Apriori算法是一种用于关联规则学习中频繁项集挖掘的经典算法。它主要用于事务数据库中查找项集(如购物篮中的商品),这些项集在数据库中频繁出现,并基于这些频繁项集生成强关联规则。简单地说,Apriori帮助我们发现在大量数据中一起出现的事物的模式。
想象一下,你经营一家小杂货店,并想了解顾客购买商品之间的关系,以便更好地管理库存和布置货架。例如,如果你发现买面包的顾客也经常买牛奶,那么将面包和牛奶放在一起可以提高顾客的购物体验并增加销售额。
这里是如何使用Apriori算法来发现这些规律的:
步骤 1: 设置最小支持度和最小置信度
- 支持度表示项集(如面包和牛奶)在所有交易中出现的频率。如果你有100笔交易,面包和牛奶一起出现在20笔交易中,那么{面包,牛奶}的支持度是20%。
- 置信度表示当你有面包时,有多大的可能性会买牛奶。如果买了面包的顾客中有80%也买了牛奶,那么规则{面包 -> 牛奶}的置信度是80%。
你可能会设置最小支持度为5%,最小置信度为50%,这意味着你只关注至少在5%的交易中出现,且置信度至少为50%的规则。
步骤 2: 找出所有频繁项集
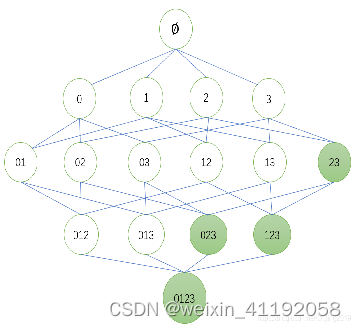
使用Apriori算法,你会从单个商品(1-项集)开始,计算它们的支持度,并剔除低于最小支持度的项。然后,你组合留下的项形成2-项集,再次计算支持度并剔除。这个过程一直重复,直到不能形成更大的频繁项集。(如图所示,{2,3}为低于最小支持度)
步骤 3: 从频繁项集中生成关联规则
一旦有了频繁项集,你就可以生成关联规则并计算置信度。只有那些置信度高于你设定的最小置信度阈值的规则才会被保留。
例子
假设你的数据显示,面包和牛奶是频繁一起购买的(即,它们组成一个频繁项集)。基于这个频繁项集,你可以生成规则{面包 -> 牛奶}。如果这个规则的支持度和置信度都高于你的阈值,那么这个规则就很有价值,它告诉你顾客倾向于在买面包时也买牛奶。
通过这种方式,Apriori算法帮助你发现了一个有用的购物模式,这可以指导你进行更有效的商品布局和促销活动。该算法也常用在网络入侵检测技术、高校贫困生资助等领域

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)