
pytorch实现花卉识别
save_dir = osp.join(params['save_dir'], params['model'] + "_nopretrained_" + str(params["img_size"]))# 设置模型保存路径。save_dir = osp.join(params['save_dir'], params['model']+"_pretrained_" + str(params["img
这篇文章和代码主要是针对一些人工智能领域刚刚入门的小伙伴们练手用的项目,该项目的数据集不是那么的大,可以在自己本地的电脑上进行训练。这种规模的数据集可以避免计算资源的缺乏所造成的影响。
接下来看看整个项目的一个基本结构:
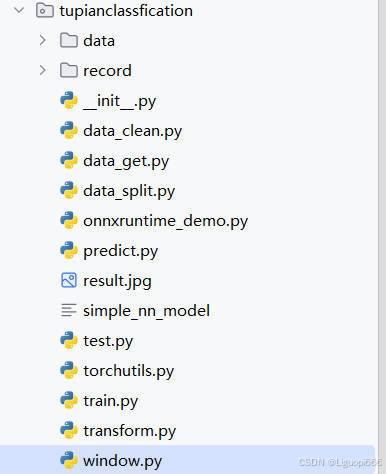
图中所显示的就是一个项目的基本架构,大家按照这个结构来部署项目就可以了,数据集的可以自己去网上搜寻一些相似的数据来进行一个替代。接下来我会分别解释每个代码的作用是什么。
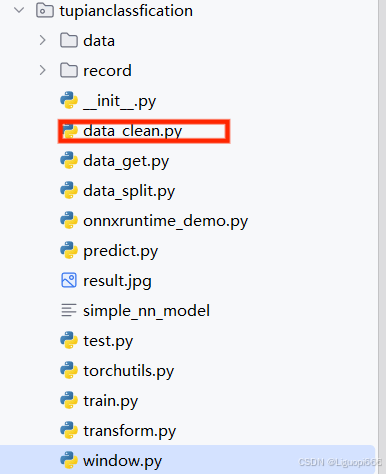
图中所框的代码是用来进行一个数据清洗所使用的。因为有时候我们所收集的数据中可能会有一些数据的残差,比如图片不完整,所以在进行训练之前需要对数据进行一个初步的清洗过程。
data_clean.py:
import shutil
import cv2
import os
import os.path as osp
import numpy as np
from tqdm import tqdm
# 实际的图片保存和读取的过程中存在中文,所以这里通过这两种方式来应对中文读取的情况。
# handle chinese path
def cv_imread(file_path, type=-1):
cv_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), -1)
if type == 0:
cv_img = cv2.cvtColor(cv_img, cv2.COLOR_BGR2GRAY)
return cv_img
def cv_imwrite(file_path, cv_img, is_gray=True):
if len(cv_img.shape) == 3 and is_gray:
cv_img = cv_img[:, :, 0]
cv2.imencode(file_path[-4:], cv_img)[1].tofile(file_path)
def data_clean(src_folder, english_name):
clean_folder = src_folder + "_cleaned"
if os.path.isdir(clean_folder):
print("保存目录已存在")
shutil.rmtree(clean_folder)
os.mkdir(clean_folder)
# 数据清晰的过程主要是通过oepncv来进行读取,读取之后没有问题就可以进行保存
# 数据清晰的过程中,一是为了保证数据是可以读取的,二是需要将原先的中文修改为英文,方便后续的程序读取。
image_names = os.listdir(src_folder)
with tqdm(total=len(image_names)) as pabr:
for i, image_name in enumerate(image_names):
image_path = osp.join(src_folder, image_name)
try:
img = cv_imread(image_path)
img_channel = img.shape[-1]
if img_channel == 3:
save_image_name = english_name + "_" + str(i) + ".jpg"
save_path = osp.join(clean_folder, save_image_name)
cv_imwrite(file_path=save_path, cv_img=img, is_gray=False)
except:
print("{}是坏图".format(image_name))
pabr.update(1)
if __name__ == '__main__':
data_clean(src_folder=r'E:/PythonProject/pytocrh_project/tupianclassfication/data/向日葵', english_name="sunflowers")
data_split.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
@Project :cls_template
@File :data_split.py
@Author :ChenmingSong
@Date :2022/1/9 19:43
@Description:
'''
import os
import random
import shutil
from shutil import copy2
import os.path as osp
def data_set_split(src_data_folder, target_data_folder, train_scale=0.6, val_scale=0.2, test_scale=0.2):
'''
读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行
:param src_data_folder: 源文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/src_data
:param target_data_folder: 目标文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/target_data
:param train_scale: 训练集比例
:param val_scale: 验证集比例
:param test_scale: 测试集比例
:return:
'''
print("开始数据集划分")
class_names = os.listdir(src_data_folder)
# 在目标目录下创建文件夹
split_names = ['train', 'val', 'test']
for split_name in split_names:
split_path = os.path.join(target_data_folder, split_name)
if os.path.isdir(split_path):
pass
else:
os.mkdir(split_path)
# 然后在split_path的目录下创建类别文件夹
for class_name in class_names:
class_split_path = os.path.join(split_path, class_name)
if os.path.isdir(class_split_path):
pass
else:
os.mkdir(class_split_path)
# 按照比例划分数据集,并进行数据图片的复制
# 首先进行分类遍历
for class_name in class_names:
current_class_data_path = os.path.join(src_data_folder, class_name)
current_all_data = os.listdir(current_class_data_path)
current_data_length = len(current_all_data)
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)
val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)
test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)
train_stop_flag = current_data_length * train_scale
val_stop_flag = current_data_length * (train_scale + val_scale)
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
for i in current_data_index_list:
src_img_path = os.path.join(current_class_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_folder)
# print("{}复制到了{}".format(src_img_path, train_folder))
train_num = train_num + 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_folder)
# print("{}复制到了{}".format(src_img_path, val_folder))
val_num = val_num + 1
else:
copy2(src_img_path, test_folder)
# print("{}复制到了{}".format(src_img_path, test_folder))
test_num = test_num + 1
current_idx = current_idx + 1
print("*********************************{}*************************************".format(class_name))
print(
"{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale,
current_data_length))
print("训练集{}:{}张".format(train_folder, train_num))
print("验证集{}:{}张".format(val_folder, val_num))
print("测试集{}:{}张".format(test_folder, test_num))
# 数据集划分还是比较重要的。
if __name__ == '__main__':
src_data_folder = "E:/PythonProject/pytocrh_project/flower_photos" # todo 修改你的原始数据集路径
target_data_folder = src_data_folder + "_" + "split"
if osp.isdir(target_data_folder):
print("target folder 已存在, 正在删除...")
shutil.rmtree(target_data_folder)
os.mkdir(target_data_folder)
print("Target folder 创建成功")
data_set_split(src_data_folder, target_data_folder)
print("*****************************************************************")
print("数据集划分完成,请在{}目录下查看".format(target_data_folder))
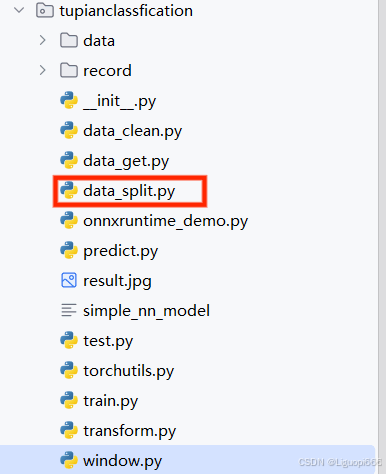
接下来这副图中所框选的代码的作用是用来进行一个数据的划分的作用。在进行模型的训练和评估过程中需要对获取的一个整体数据集进行一个划分。划分成训练集、测试集和验证集三个部分。该三个部分的比例为6:2:2.这篇代码中所给的比例是这样子的,当然大家也可以根据需要自己来进行一个修改。

运行完成之后就会出现如图所示的一个文件夹,其中包含了各个部分的数据集。
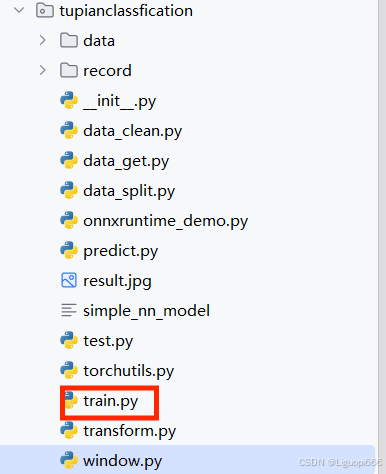
接下来介绍的就是训练集,这个代码的作用主要是对数据进行一个训练,关于预训练的一些参数如图所示: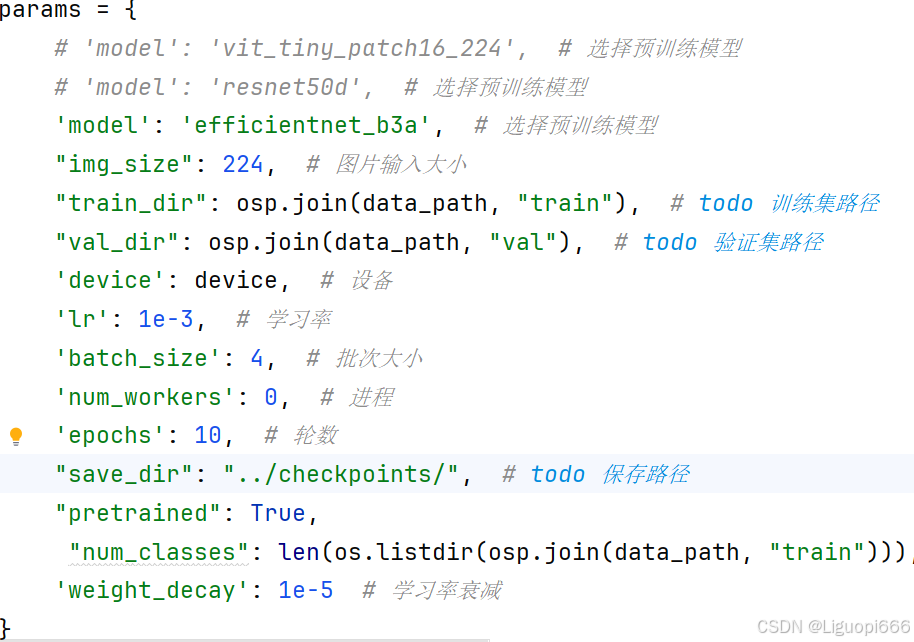
train.py
from torchutils import *
from torchvision import datasets, models, transforms
import os.path as osp
import os
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
print(f'Using device: {device}')
# 固定随机种子,保证实验结果是可以复现的
seed = 42
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
data_path = "E:/PythonProject/pytocrh_project/flower_photos_split" # todo 数据集路径
# 注: 执行之前请先划分数据集
# 超参数设置
params = {
# 'model': 'vit_tiny_patch16_224', # 选择预训练模型
# 'model': 'resnet50d', # 选择预训练模型
'model': 'efficientnet_b3a', # 选择预训练模型
"img_size": 224, # 图片输入大小
"train_dir": osp.join(data_path, "train"), # todo 训练集路径
"val_dir": osp.join(data_path, "val"), # todo 验证集路径
'device': device, # 设备
'lr': 1e-3, # 学习率
'batch_size': 4, # 批次大小
'num_workers': 0, # 进程
'epochs': 10, # 轮数
"save_dir": "../checkpoints/", # todo 保存路径
"pretrained": True,
"num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目
'weight_decay': 1e-5 # 学习率衰减
}
# 定义模型
class SELFMODEL(nn.Module):
def __init__(self, model_name=params['model'], out_features=params['num_classes'],
pretrained=True):
super().__init__()
self.model = timm.create_model(model_name, pretrained=pretrained) # 从预训练的库中加载模型
# self.model = timm.create_model(model_name, pretrained=pretrained, checkpoint_path="pretrained/resnet50d_ra2-464e36ba.pth") # 从预训练的库中加载模型
# classifier
if model_name[:3] == "res":
n_features = self.model.fc.in_features # 修改全连接层数目
self.model.fc = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目
elif model_name[:3] == "vit":
n_features = self.model.head.in_features # 修改全连接层数目
self.model.head = nn.Linear(n_features, out_features) # 修改为本任务对应的类别数目
else:
n_features = self.model.classifier.in_features
self.model.classifier = nn.Linear(n_features, out_features)
# resnet修改最后的全链接层
print(self.model) # 返回模型
def forward(self, x): # 前向传播
x = self.model(x)
return x
# 定义训练流程
def train(train_loader, model, criterion, optimizer, epoch, params):
metric_monitor = MetricMonitor() # 设置指标监视器
model.train() # 模型设置为训练模型
nBatch = len(train_loader)
stream = tqdm(train_loader)
for i, (images, target) in enumerate(stream, start=1): # 开始训练
images = images.to(params['device'], non_blocking=True) # 加载数据
target = target.to(params['device'], non_blocking=True) # 加载模型
output = model(images) # 数据送入模型进行前向传播
loss = criterion(output, target.long()) # 计算损失
f1_macro = calculate_f1_macro(output, target) # 计算f1分数
recall_macro = calculate_recall_macro(output, target) # 计算recall分数
acc = accuracy(output, target) # 计算准确率分数
metric_monitor.update('Loss', loss.item()) # 更新损失
metric_monitor.update('F1', f1_macro) # 更新f1
metric_monitor.update('Recall', recall_macro) # 更新recall
metric_monitor.update('Accuracy', acc) # 更新准确率
optimizer.zero_grad() # 清空学习率
loss.backward() # 损失反向传播
optimizer.step() # 更新优化器
lr = adjust_learning_rate(optimizer, epoch, params, i, nBatch) # 调整学习率
stream.set_description( # 更新进度条
"Epoch: {epoch}. Train. {metric_monitor}".format(
epoch=epoch,
metric_monitor=metric_monitor)
)
return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"] # 返回结果
# 定义验证流程
def validate(val_loader, model, criterion, epoch, params):
metric_monitor = MetricMonitor() # 验证流程
model.eval() # 模型设置为验证格式
stream = tqdm(val_loader) # 设置进度条
with torch.no_grad(): # 开始推理
for i, (images, target) in enumerate(stream, start=1):
images = images.to(params['device'], non_blocking=True) # 读取图片
target = target.to(params['device'], non_blocking=True) # 读取标签
output = model(images) # 前向传播
loss = criterion(output, target.long()) # 计算损失
f1_macro = calculate_f1_macro(output, target) # 计算f1分数
recall_macro = calculate_recall_macro(output, target) # 计算recall分数
acc = accuracy(output, target) # 计算acc
metric_monitor.update('Loss', loss.item()) # 后面基本都是更新进度条的操作
metric_monitor.update('F1', f1_macro)
metric_monitor.update("Recall", recall_macro)
metric_monitor.update('Accuracy', acc)
stream.set_description(
"Epoch: {epoch}. Validation. {metric_monitor}".format(
epoch=epoch,
metric_monitor=metric_monitor)
)
return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['Loss']["avg"]
# 展示训练过程的曲线
def show_loss_acc(acc, loss, val_acc, val_loss, sava_dir):
# 从history中提取模型训练集和验证集准确率信息和误差信息
# 按照上下结构将图画输出
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()), 1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
# 保存在savedir目录下。
save_path = osp.join(save_dir, "results.png")
plt.savefig(save_path, dpi=100)
if __name__ == '__main__':
accs = []
losss = []
val_accs = []
val_losss = []
data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式
train_transforms = data_transforms['train'] # 训练集数据处理方式
valid_transforms = data_transforms['val'] # 验证集数据集处理方式
train_dataset = datasets.ImageFolder(params["train_dir"], train_transforms) # 加载训练集
valid_dataset = datasets.ImageFolder(params["val_dir"], valid_transforms) # 加载验证集
if params['pretrained'] == True:
save_dir = osp.join(params['save_dir'], params['model']+"_pretrained_" + str(params["img_size"])) # 设置模型保存路径
else:
save_dir = osp.join(params['save_dir'], params['model'] + "_nopretrained_" + str(params["img_size"])) # 设置模型保存路径
if not osp.isdir(save_dir): # 如果保存路径不存在的话就创建
os.makedirs(save_dir) #
print("save dir {} created".format(save_dir))
train_loader = DataLoader( # 按照批次加载训练集
train_dataset, batch_size=params['batch_size'], shuffle=True,
num_workers=params['num_workers'], pin_memory=True,
)
val_loader = DataLoader( # 按照批次加载验证集
valid_dataset, batch_size=params['batch_size'], shuffle=False,
num_workers=params['num_workers'], pin_memory=True,
)
print(train_dataset.classes)
model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'],
pretrained=params['pretrained']) # 加载模型
# model = nn.DataParallel(model) # 模型并行化,提高模型的速度
# resnet50d_1epochs_accuracy0.50424_weights.pth
model = model.to(params['device']) # 模型部署到设备上
criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数
optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器
# 损失函数和优化器可以自行设置修改。
# criterion = nn.CrossEntropyLoss().to(params['device']) # 设置损失函数
# optimizer = torch.optim.AdamW(model.parameters(), lr=params['lr'], weight_decay=params['weight_decay']) # 设置优化器
best_acc = 0.0 # 记录最好的准确率
# 只保存最好的那个模型。
for epoch in range(1, params['epochs'] + 1): # 开始训练
acc, loss = train(train_loader, model, criterion, optimizer, epoch, params)
val_acc, val_loss = validate(val_loader, model, criterion, epoch, params)
accs.append(acc)
losss.append(loss)
val_accs.append(val_acc)
val_losss.append(val_loss)
if val_acc >= best_acc:
# 保存的时候设置一个保存的间隔,或者就按照目前的情况,如果前面的比后面的效果好,就保存一下。
# 按照间隔保存的话得不到最好的模型。
save_path = osp.join(save_dir, f"{params['model']}_{epoch}epochs_accuracy{acc:.5f}_weights.pth")
torch.save(model.state_dict(), save_path)
best_acc = val_acc
show_loss_acc(accs, losss, val_accs, val_losss, save_dir)
print("训练已完成,模型和训练日志保存在: {}".format(save_dir))
这个训练是进行的预训练,大家可以根基自己的实际需要来对代码进行一个改写。最后与训练完成之后会得到一个模型,模型保存的地址如图中的所设置的地址所示。
这个代码的作用是对训练所生成的模型进行一个测试评估,测试评估后会得到一个图。
test.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# 最好是把配置文件写在一起,如果写在一起的话,方便进行查看
from torchutils import *
from torchvision import datasets, models, transforms
import os.path as osp
import os
from train import SELFMODEL
if torch.cuda.is_available():
device = torch.device('cuda:0')
else:
device = torch.device('cpu')
print(f'Using device: {device}')
# 固定随机种子,保证实验结果是可以复现的
seed = 42
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
data_path = "E:/PythonProject/pytocrh_project/flower_photos_split" # todo 修改为数据集根目录
model_path = "E:/PythonProject/pytocrh_project/checkpoints/efficientnet_b3a_pretrained_224/efficientnet_b3a_9epochs_accuracy0.99501_weights.pth" # todo 模型地址
model_name = 'efficientnet_b3a' # todo 模型名称
img_size = 224 # todo 数据集训练时输入模型的大小
# 注: 执行之前请先划分数据集
# 超参数设置
params = {
# 'model': 'vit_tiny_patch16_224', # 选择预训练模型
# 'model': 'efficientnet_b3a', # 选择预训练模型
'model': model_name, # 选择预训练模型
"img_size": img_size, # 图片输入大小
"test_dir": osp.join(data_path, "test"), # todo 测试集子目录
'device': device, # 设备
'batch_size': 4, # 批次大小
'num_workers': 0, # 进程
"num_classes": len(os.listdir(osp.join(data_path, "train"))), # 类别数目, 自适应获取类别数目
}
def test(val_loader, model, params, class_names):
metric_monitor = MetricMonitor() # 验证流程
model.eval() # 模型设置为验证格式
stream = tqdm(val_loader) # 设置进度条
# 对模型分开进行推理
test_real_labels = []
test_pre_labels = []
with torch.no_grad(): # 开始推理
for i, (images, target) in enumerate(stream, start=1):
images = images.to(params['device'], non_blocking=True) # 读取图片
target = target.to(params['device'], non_blocking=True) # 读取标签
output = model(images) # 前向传播
# loss = criterion(output, target.long()) # 计算损失
# print(output)
target_numpy = target.cpu().numpy()
y_pred = torch.softmax(output, dim=1)
y_pred = torch.argmax(y_pred, dim=1).cpu().numpy()
test_real_labels.extend(target_numpy)
test_pre_labels.extend(y_pred)
# print(target_numpy)
# print(y_pred)
f1_macro = calculate_f1_macro(output, target) # 计算f1分数
recall_macro = calculate_recall_macro(output, target) # 计算recall分数
acc = accuracy(output, target) # 计算acc
# metric_monitor.update('Loss', loss.item()) # 后面基本都是更新进度条的操作
metric_monitor.update('F1', f1_macro)
metric_monitor.update("Recall", recall_macro)
metric_monitor.update('Accuracy', acc)
stream.set_description(
"mode: {epoch}. {metric_monitor}".format(
epoch="test",
metric_monitor=metric_monitor)
)
class_names_length = len(class_names)
heat_maps = np.zeros((class_names_length, class_names_length))
for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels):
heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1
# print(heat_maps)
heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1)
# print(heat_maps_sum)
# print()
heat_maps_float = heat_maps / heat_maps_sum
# print(heat_maps_float)
# title, x_labels, y_labels, harvest
show_heatmaps(title="heatmap", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float,
save_name="record/heatmap_{}.png".format(model_name))
# 加上模型名称
return metric_monitor.metrics['Accuracy']["avg"], metric_monitor.metrics['F1']["avg"], \
metric_monitor.metrics['Recall']["avg"]
def show_heatmaps(title, x_labels, y_labels, harvest, save_name):
# 这里是创建一个画布
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False
fig, ax = plt.subplots()
# cmap https://blog.csdn.net/ztf312/article/details/102474190
im = ax.imshow(harvest, cmap="OrRd")
# 这里是修改标签
# We want to show all ticks...
ax.set_xticks(np.arange(len(y_labels)))
ax.set_yticks(np.arange(len(x_labels)))
# ... and label them with the respective list entries
ax.set_xticklabels(y_labels)
ax.set_yticklabels(x_labels)
# 因为x轴的标签太长了,需要旋转一下,更加好看
# Rotate the tick labels and set their alignment.
plt.setp(ax.get_xticklabels(), rotation=45, ha="right",
rotation_mode="anchor")
# 添加每个热力块的具体数值
# Loop over data dimensions and create text annotations.
for i in range(len(x_labels)):
for j in range(len(y_labels)):
text = ax.text(j, i, round(harvest[i, j], 2),
ha="center", va="center", color="black")
ax.set_xlabel("Predict label")
ax.set_ylabel("Actual label")
ax.set_title(title)
fig.tight_layout()
plt.colorbar(im)
plt.savefig(save_name, dpi=100)
plt.show()
if __name__ == '__main__':
data_transforms = get_torch_transforms(img_size=params["img_size"]) # 获取图像预处理方式
# train_transforms = data_transforms['train'] # 训练集数据处理方式
valid_transforms = data_transforms['val'] # 验证集数据集处理方式
# valid_dataset = datasets.ImageFolder(params["val_dir"], valid_transforms) # 加载验证集
# print(valid_dataset)
test_dataset = datasets.ImageFolder(params["test_dir"], valid_transforms)
class_names = test_dataset.classes
print(class_names)
# valid_dataset = datasets.ImageFolder(params["val_dir"], valid_transforms) # 加载验证集
test_loader = DataLoader( # 按照批次加载训练集
test_dataset, batch_size=params['batch_size'], shuffle=True,
num_workers=params['num_workers'], pin_memory=True,
)
# 加载模型
model = SELFMODEL(model_name=params['model'], out_features=params['num_classes'],
pretrained=False) # 加载模型结构,加载模型结构过程中pretrained设置为False即可。
weights = torch.load(model_path)
model.load_state_dict(weights)
model.eval()
model.to(device)
# 指标上的测试结果包含三个方面,分别是acc f1 和 recall, 除此之外,应该还有相应的热力图输出,整体会比较好看一些。
acc, f1, recall = test(test_loader, model, params, class_names)
print("测试结果:")
print(f"acc: {acc}, F1: {f1}, recall: {recall}")
print("测试完成,heatmap保存在{}下".format("record"))
最后介绍的是predict.py
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
'''
'''
import torch
from PIL import Image, ImageDraw, ImageFont
# from train_resnet import SelfNet
from train import SELFMODEL
import os
import os.path as osp
import shutil
import torch.nn as nn
from PIL import Image
from torchutils import get_torch_transforms
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
model_path = "E:/PythonProject/pytocrh_project/checkpoints/efficientnet_b3a_pretrained_224/efficientnet_b3a_9epochs_accuracy0.99501_weights.pth" # todo 模型路径
classes_names = ['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips'] # todo 类名
img_size = 224 # todo 图片大小
model_name = "efficientnet_b3a" # todo 模型名称
num_classes = len(classes_names) # todo 类别数目
def predict_batch(model_path, target_dir, save_dir):
data_transforms = get_torch_transforms(img_size=img_size)
valid_transforms = data_transforms['val']
# 加载网络
model = SELFMODEL(model_name=model_name, out_features=num_classes, pretrained=False)
# model = nn.DataParallel(model)
weights = torch.load(model_path)
model.load_state_dict(weights)
model.eval()
model.to(device)
# 读取图片
image_names = os.listdir(target_dir)
for i, image_name in enumerate(image_names):
image_path = osp.join(target_dir, image_name)
img = Image.open(image_path)
img = valid_transforms(img)
img = img.unsqueeze(0)
img = img.to(device)
output = model(img)
label_id = torch.argmax(output).item()
predict_name = classes_names[label_id]
save_path = osp.join(save_dir, predict_name)
if not osp.isdir(save_path):
os.makedirs(save_path)
shutil.copy(image_path, save_path)
print(f"{i + 1}: {image_name} result {predict_name}")
# def predict_single(model_path, image_path):
# data_transforms = get_torch_transforms(img_size=img_size)
# # train_transforms = data_transforms['train']
# valid_transforms = data_transforms['val']
# # 加载网络
# model = SELFMODEL(model_name=model_name, out_features=num_classes, pretrained=False)
# # model = nn.DataParallel(model)
# weights = torch.load(model_path)
# model.load_state_dict(weights)
# model.eval()
# model.to(device)
#
# # 读取图片
# img = Image.open(image_path)
# img = valid_transforms(img)
# img = img.unsqueeze(0)
# img = img.to(device)
# output = model(img)
# label_id = torch.argmax(output).item()
# predict_name = classes_names[label_id]
# print(f"{image_path}'s result is {predict_name}")
def predict_single(model_path, image_path, output_image_path="result.jpg"):
data_transforms = get_torch_transforms(img_size=img_size)
valid_transforms = data_transforms['val']
# 加载网络
model = SELFMODEL(model_name=model_name, out_features=num_classes, pretrained=False)
weights = torch.load(model_path)
model.load_state_dict(weights)
model.eval()
model.to(device)
# 读取图片
img = Image.open(image_path)
img_transformed = valid_transforms(img)
img_transformed = img_transformed.unsqueeze(0)
img_transformed = img_transformed.to(device)
# 模型推理
output = model(img_transformed)
label_id = torch.argmax(output).item()
predict_name = classes_names[label_id]
# 打印预测结果
print(f"{image_path}'s result is {predict_name}")
# 在图片上绘制预测结果
draw = ImageDraw.Draw(img)
font_size = max(20, img.size[0] // 20) # 根据图片大小调整字体大小
try:
font = ImageFont.truetype("arial.ttf", font_size) # 使用 Arial 字体
except IOError:
font = ImageFont.load_default() # 如果 Arial 字体不可用,则使用默认字体
text_position = (10, 10) # 结果文本的位置
text_color = "red" # 文本颜色
draw.text(text_position, predict_name, fill=text_color, font=font)
# 保存并显示结果图片
img.save(output_image_path)
img.show()
# 示例调用
# predict_single_and_show("model_weights.pth", "test_image.jpg", "output_image.jpg")
if __name__ == '__main__':
# 批量预测函数
# predict_batch(model_path=model_path,
# target_dir="D:/cls/cls_torch_tem/images/test_imgs/mini",
# save_dir="D:/cls/cls_torch_tem/images/test_imgs/mini_result")
# 单张图片预测函数
predict_single(model_path=model_path, image_path="C:/Users/李果皮/Desktop/R-C.jpg")
这个代码的作用是用来预测结果的
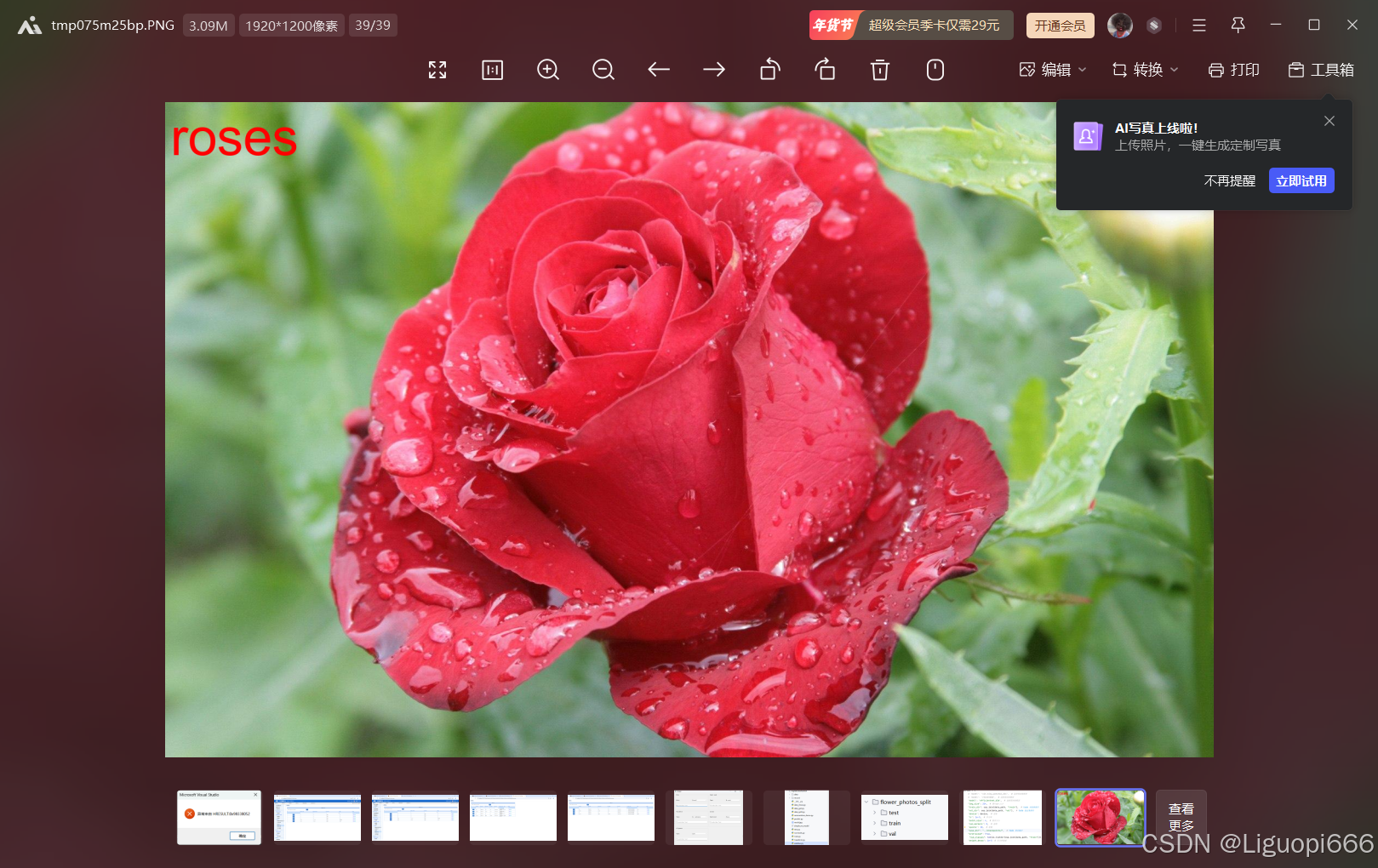
最后会将上传的图片显示一个标注出来。
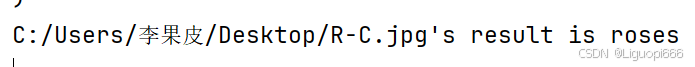
最后希望能够帮助到大家,如果需要博主提供的数据集可私。
希望大家都能够从中有所收获

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 30
30 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)