
【深度学习】ViT模型详解与Pytorch代码实现
介绍使用PyTorch 从头开始实现 ViT模型代码,在 CIFAR-10 数据集上训练ViT模型 以完成图像分类。ViT的架构ViT 的架构受到 BERT 的启发,BERT 是一种仅编码器的 transformer 模型,通常用于文本分类或命名实体识别等 NLP 监督学习任务。ViT 背后的主要思想是,图像可以看作是一系列的补丁,在 NLP 任务中可以被视为令牌输入图像被分割成小块,然后被...
介绍
使用PyTorch 从头开始实现 ViT模型代码,在 CIFAR-10 数据集上训练ViT模型 以完成图像分类。
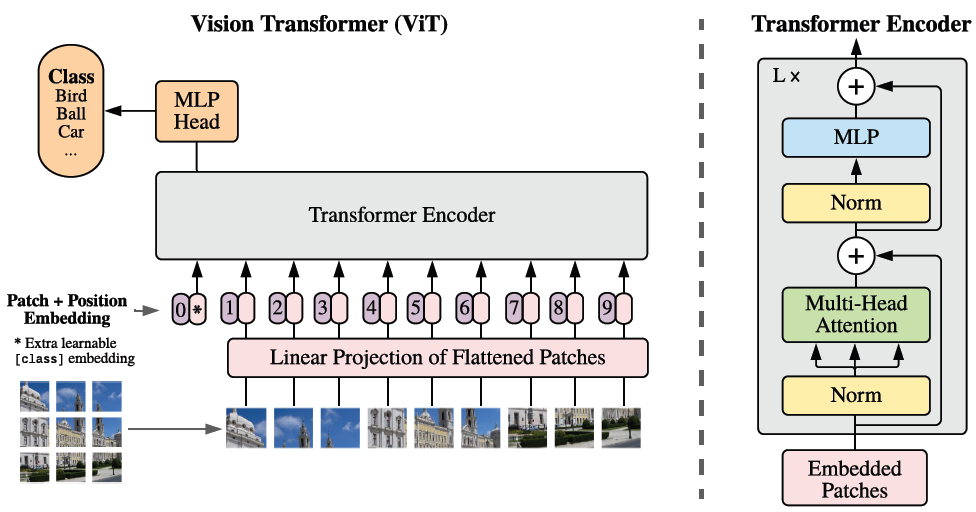
ViT的架构
ViT 的架构受到 BERT 的启发,BERT 是一种仅编码器的 transformer 模型,通常用于文本分类或命名实体识别等 NLP 监督学习任务。ViT 背后的主要思想是,图像可以看作是一系列的补丁,在 NLP 任务中可以被视为令牌
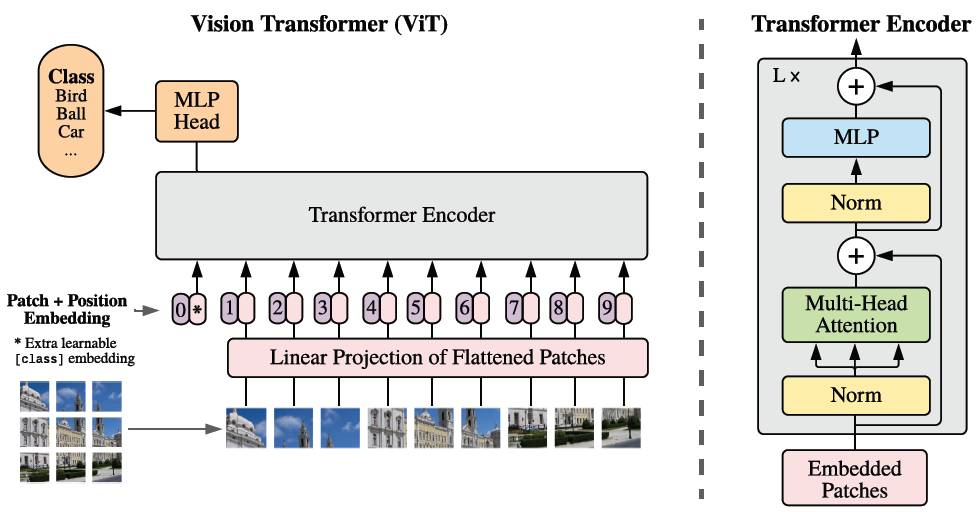
输入图像被分割成小块,然后被展平为向量序列。然后,这些向量由 transformer 编码器处理,它允许模型通过自注意力机制学习补丁之间的交互。然后,transformer 编码器的输出被馈送到一个分类层,该分类层输出输入图像的预测类别
代码实现
下面是模型各个部分组件的 PyTorch代码实现。
01
图像嵌入转换
为了将输入图像馈送到 Transformer 模型,我们需要将图像转换为一系列向量。这是通过将图像分割成一个不重叠的补丁网格来完成的,然后线性投影这些补丁以获得每个补丁的固定大小的嵌入向量。为此,我们可以使用 PyTorch 的层:nn.Conv2d
class PatchEmbeddings(nn.Module):
"""
Convert the image into patches and then project them into a vector space.
"""
def __init__(self, config):
super().__init__()
self.image_size = config["image_size"]
self.patch_size = config["patch_size"]
self.num_channels = config["num_channels"]
self.hidden_size = config["hidden_size"]
# Calculate the number of patches from the image size and patch size
self.num_patches = (self.image_size // self.patch_size) ** 2
# Create a projection layer to convert the image into patches
# The layer projects each patch into a vector of size hidden_size
self.projection = nn.Conv2d(self.num_channels, self.hidden_size, kernel_size=self.patch_size, stride=self.patch_size)
def forward(self, x):
# (batch_size, num_channels, image_size, image_size) -> (batch_size, num_patches, hidden_size)
x = self.projection(x)
x = x.flatten(2).transpose(1, 2)
return xkernel_size=self.patch_size并确保图层的滤镜应用于非重叠的面片。stride=self.patch_size在补丁转换为嵌入序列后,[CLS] 标记被添加到序列的开头,稍后将在分类层中用于对图像进行分类。[CLS] 令牌的嵌入是在训练期间学习的。
由于来自不同位置的补丁对最终预测的贡献可能不同,我们还需要一种方法将补丁位置编码到序列中。我们将使用可学习的位置嵌入向量将位置信息添加到嵌入向量中。这类似于在 Transformer 模型中为 NLP 任务使用位置嵌入的方式。
class Embeddings(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.patch_embeddings = PatchEmbeddings(config)
# Create a learnable [CLS] token
# Similar to BERT, the [CLS] token is added to the beginning of the input sequence
# and is used to classify the entire sequence
self.cls_token = nn.Parameter(torch.randn(1, 1, config["hidden_size"]))
# Create position embeddings for the [CLS] token and the patch embeddings
# Add 1 to the sequence length for the [CLS] token
self.position_embeddings = \
nn.Parameter(torch.randn(1, self.patch_embeddings.num_patches + 1, config["hidden_size"]))
self.dropout = nn.Dropout(config["hidden_dropout_prob"])
def forward(self, x):
x = self.patch_embeddings(x)
batch_size, _, _ = x.size()
# Expand the [CLS] token to the batch size
# (1, 1, hidden_size) -> (batch_size, 1, hidden_size)
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
# Concatenate the [CLS] token to the beginning of the input sequence
# This results in a sequence length of (num_patches + 1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.position_embeddings
x = self.dropout(x)
return x在此步骤中,输入图像被转换为带有位置信息的嵌入序列,并准备馈送到 transformer 层。
02
多头注意力
在介绍 transformer 编码器之前,我们首先探索 multi-head attention module,这是它的核心组件。多头注意力用于计算输入图像中不同色块之间的交互。多头注意力由多个注意力头组成,每个注意力头都是一个注意力层。
让我们实现多头注意力模块的 head。该模块将一系列嵌入向量作为输入,并计算每个嵌入向量的查询向量、键向量和值向量。然后,使用查询和关键向量来计算每个标记的注意力权重。然后,使用注意力权重通过值向量的加权和来计算新的嵌入。我们可以将此机制视为数据库查询的软版本,其中查询向量在数据库中查找最相关的键向量,并检索值向量以计算查询输出。
class AttentionHead(nn.Module):
"""
A single attention head.
This module is used in the MultiHeadAttention module.
"""
def __init__(self, hidden_size, attention_head_size, dropout, bias=True):
super().__init__()
self.hidden_size = hidden_size
self.attention_head_size = attention_head_size
# Create the query, key, and value projection layers
self.query = nn.Linear(hidden_size, attention_head_size, bias=bias)
self.key = nn.Linear(hidden_size, attention_head_size, bias=bias)
self.value = nn.Linear(hidden_size, attention_head_size, bias=bias)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# Project the input into query, key, and value
# The same input is used to generate the query, key, and value,
# so it's usually called self-attention.
# (batch_size, sequence_length, hidden_size) -> (batch_size, sequence_length, attention_head_size)
query = self.query(x)
key = self.key(x)
value = self.value(x)
# Calculate the attention scores
# softmax(Q*K.T/sqrt(head_size))*V
attention_scores = torch.matmul(query, key.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
# Calculate the attention output
attention_output = torch.matmul(attention_probs, value)
return (attention_output, attention_probs)然后,所有注意力头的输出被连接起来并线性投影,以获得多头注意力模块的最终输出。
class MultiHeadAttention(nn.Module):
"""
Multi-head attention module.
This module is used in the TransformerEncoder module.
"""
def __init__(self, config):
super().__init__()
self.hidden_size = config["hidden_size"]
self.num_attention_heads = config["num_attention_heads"]
# The attention head size is the hidden size divided by the number of attention heads
self.attention_head_size = self.hidden_size // self.num_attention_heads
self.all_head_size = self.num_attention_heads * self.attention_head_size
# Whether or not to use bias in the query, key, and value projection layers
self.qkv_bias = config["qkv_bias"]
# Create a list of attention heads
self.heads = nn.ModuleList([])
for _ in range(self.num_attention_heads):
head = AttentionHead(
self.hidden_size,
self.attention_head_size,
config["attention_probs_dropout_prob"],
self.qkv_bias
)
self.heads.append(head)
# Create a linear layer to project the attention output back to the hidden size
# In most cases, all_head_size and hidden_size are the same
self.output_projection = nn.Linear(self.all_head_size, self.hidden_size)
self.output_dropout = nn.Dropout(config["hidden_dropout_prob"])
def forward(self, x, output_attentions=False):
# Calculate the attention output for each attention head
attention_outputs = [head(x) for head in self.heads]
# Concatenate the attention outputs from each attention head
attention_output = torch.cat([attention_output for attention_output, _ in attention_outputs], dim=-1)
# Project the concatenated attention output back to the hidden size
attention_output = self.output_projection(attention_output)
attention_output = self.output_dropout(attention_output)
# Return the attention output and the attention probabilities (optional)
if not output_attentions:
return (attention_output, None)
else:
attention_probs = torch.stack([attention_probs for _, attention_probs in attention_outputs], dim=1)
return (attention_output, attention_probs)03
编码器
编码器由一堆MHA + MLP组成。每个 transformer 层主要由我们刚刚实现的多头注意力模块和前馈网络组成。为了更好地扩展模型并稳定训练,向 transformer 层添加了两个 Layer 归一化层和跳过连接。
让我们实现一个 transformer 层(在代码中称为 ,因为它是 transformer 编码器的构建块)。我们将从前馈网络开始,这是一个简单的两层 MLP,中间有 GELU 激活。Block
class MLP(nn.Module):
"""
A multi-layer perceptron module.
"""
def __init__(self, config):
super().__init__()
self.dense_1 = nn.Linear(config["hidden_size"], config["intermediate_size"])
self.activation = NewGELUActivation()
self.dense_2 = nn.Linear(config["intermediate_size"], config["hidden_size"])
self.dropout = nn.Dropout(config["hidden_dropout_prob"])
def forward(self, x):
x = self.dense_1(x)
x = self.activation(x)
x = self.dense_2(x)
x = self.dropout(x)
return x我们已经实现了多头注意力和 MLP,我们可以将它们组合起来创建变压器层。跳过连接和层标准化将应用于每个层的输入
class Block(nn.Module):
"""
A single transformer block.
"""
def __init__(self, config):
super().__init__()
self.attention = MultiHeadAttention(config)
self.layernorm_1 = nn.LayerNorm(config["hidden_size"])
self.mlp = MLP(config)
self.layernorm_2 = nn.LayerNorm(config["hidden_size"])
def forward(self, x, output_attentions=False):
# Self-attention
attention_output, attention_probs = \
self.attention(self.layernorm_1(x), output_attentions=output_attentions)
# Skip connection
x = x + attention_output
# Feed-forward network
mlp_output = self.mlp(self.layernorm_2(x))
# Skip connection
x = x + mlp_output
# Return the transformer block's output and the attention probabilities (optional)
if not output_attentions:
return (x, None)
else:
return (x, attention_probs)transformer 编码器按顺序堆叠多个 transformer 层:
class Encoder(nn.Module):
"""
The transformer encoder module.
"""
def __init__(self, config):
super().__init__()
# Create a list of transformer blocks
self.blocks = nn.ModuleList([])
for _ in range(config["num_hidden_layers"]):
block = Block(config)
self.blocks.append(block)
def forward(self, x, output_attentions=False):
# Calculate the transformer block's output for each block
all_attentions = []
for block in self.blocks:
x, attention_probs = block(x, output_attentions=output_attentions)
if output_attentions:
all_attentions.append(attention_probs)
# Return the encoder's output and the attention probabilities (optional)
if not output_attentions:
return (x, None)
else:
return (x, all_attentions)04
ViT模型构建
将图像输入到 embedding 层和 transformer 编码器后,我们获得图像补丁和 [CLS] 标记的新嵌入。此时,嵌入在经过 transformer 编码器处理后应该有一些有用的信号用于分类。与 BERT 类似,我们将仅使用 [CLS] 标记的嵌入传递到分类层。
分类层是一个完全连接的层,它将 [CLS] 嵌入作为输入并输出每个图像的 logit。以下代码实现了用于图像分类的 ViT 模型:
class ViTForClassfication(nn.Module):
"""
The ViT model for classification.
"""
def __init__(self, config):
super().__init__()
self.config = config
self.image_size = config["image_size"]
self.hidden_size = config["hidden_size"]
self.num_classes = config["num_classes"]
# Create the embedding module
self.embedding = Embeddings(config)
# Create the transformer encoder module
self.encoder = Encoder(config)
# Create a linear layer to project the encoder's output to the number of classes
self.classifier = nn.Linear(self.hidden_size, self.num_classes)
# Initialize the weights
self.apply(self._init_weights)
def forward(self, x, output_attentions=False):
# Calculate the embedding output
embedding_output = self.embedding(x)
# Calculate the encoder's output
encoder_output, all_attentions = self.encoder(embedding_output, output_attentions=output_attentions)
# Calculate the logits, take the [CLS] token's output as features for classification
logits = self.classifier(encoder_output[:, 0])
# Return the logits and the attention probabilities (optional)
if not output_attentions:
return (logits, None)
else:
return (logits, all_attentions)参考
代码其实是我从github上面整理加工跟翻译得到的(个人认为非常的通俗易懂,有点pytorch基础都可以看懂学会),感兴趣的可以看这里:
https://github.com/lukemelas/PyTorch-Pretrained-ViT/blob/master/pytorch_pretrained_vit/transformer.py
https://tintn.github.io/Implementing-Vision-Transformer-from-Scratch/
往期精彩回顾
写了一本适合本科生的机器学习入门书适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑-
交流群
请备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“加群。
(也可以加入机器学习交流qq群772479961)


汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 1
1 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)