
循环神经网络-pytorch搭建-IMDb影评数据集(完整代码文末)
关键在于f-1和f-2这两个函数,f-1利用的是sigmoid函数,介于0-1之间,这样矩阵元素相乘的时候会抹掉那些为0的元素,相对于选择性遗忘了部分记忆,由此 f-1也常被称作遗忘门,过滤重要特征,忽视无关信息。首先是按顺序读取每个标签,然后利用前面得到的索引,将每个单词具体的转化成50维的向量。接下来,就是编写训练函数,需要确定批次大小,和迭代次数,采用交叉熵损失函数,隐藏层数量定为128,使
循环神经网络(RNN)
实验目的与要求
- 掌握循环神经网络在处理序列数据中的作用;
- 构建和训练一个RNN来解决序列分类任务。
实验内容
基于公开的序列数据IMDb影评数据集上的情感分类问题,构建循环神经网络,可选用LSTM网络或者GRU。通过尝试应用不同的网络结构,观察对实验性能的影响,记录模型在训练集和验证集上的性能等实验结果。具体实验步骤如下:
- 下载序列数据IMDb影评数据集。
- 学习和简述数据集的特性。
- 构建一个RNN模型,可选用LSTM或GRU单元。
- 初始化网络参数,训练模型。
- 探究不同的网络架构对结果的影响。
- 观察模型在训练过程中的性能。
- 评估模型在测试集上的性能。
- 实验方法
首先是要对IMDb数据进行处理,处理成词向量的形式(采用预训练过的glove.6B.50d,将每句话内的每个单词都变成50维的向量)。
其次是构建LSTM模型,实验pytorch中设计好的LSTM结构,我们只需要确定好,输入尺寸,隐藏层数量。然后为了做到情感分类,加一层全连接层用于分类任务。
最后,是将模型训练过程的损失和准确率绘图展示出来。
详细的模型设计及运行结果
- 模型设计及结果
首先是进行数据的预处理,先来看看数据的文件:
其中,分为test和train数据集,每个数据集合下有neg(差评)和pos(好评)两个文件,每个文件中各有12500个txt文件。我们随便看一个txt文件的内容:

可以发现是一句英文句子,长度不定。
再来看看glove.6B.50d.txt文件内容:
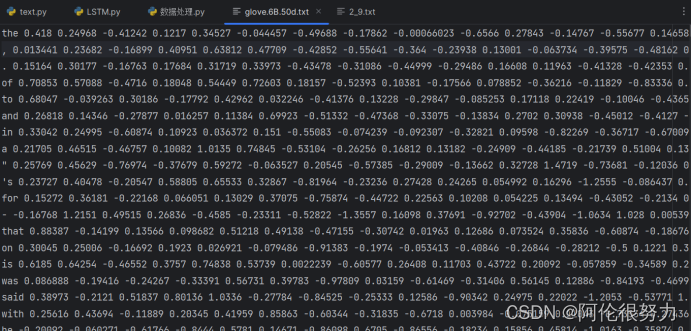
一个单词+50个数字(空格区分,表示50维向量)构成一组,每组之间用逗号间隔。
定义一个函数,用于读取glove.6B.50d.txt文件,保存得到两个npy文件:1.vocabu_vactors.npy,存储的是单词的向量;2.word_list.npy,存储的是单词,两个文件之间的索引是一一对应的。
- def load_cab_vector():
- word_list = []
- vocabulary_vectors = []
- data = open('glove.6B.50d.txt', encoding='utf-8')
- count = 0
- for line in data.readlines():
- if count % 100 == 0:
- print(f"count:{count}")
- count += 1
- temp = line.strip('\n').split(' ') # 一个列表
- name = temp[0]
- word_list.append(name.lower())
- vector = [temp[i] for i in range(1, len(temp))] # 向量
- vector = list(map(float, vector)) # 变成浮点数
- vocabulary_vectors.append(vector)
- # 保存
- vocabulary_vectors = np.array(vocabulary_vectors)
- word_list = np.array(word_list)
- np.save('vocabulary_vectors', vocabulary_vectors)
- np.save('word_list', word_list)
- return vocabulary_vectors, word_list
- # 执行load_cab_vector函数
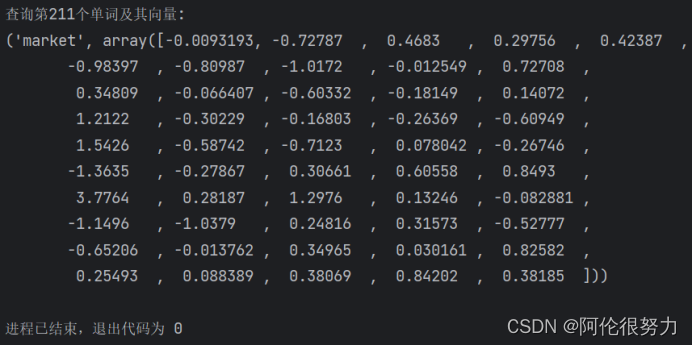
- words_vectors, words = load_cab_vector()
- print(f"查询第211个单词及其向量:\n{words[211],words_vectors[211]}")
执行函数,得到以下内容:
定义函数,读取IMDb数据,首先要去除所有的标点符号,将每个单词存进列表,最后根据是pos还是neg,添加1 或 0作为标签。
- def load_data(path, flag='train'):
- labels = ['pos', 'neg']
- data = []
- print("load_data ing......")
- for label in labels:
- files = os.listdir(os.path.join(path, flag, label))
- # 去除标点符号
- r = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\n。!,]+'
- for file in files:
- with open(os.path.join(path, flag, label, file), 'r', encoding='utf8') as rf:
- temp = rf.read().replace('\n', '')
- temp = temp.replace('<br /><br />', ' ')
- temp = re.sub(r, '', temp)
- temp = temp.split(' ')
- temp = [temp[i].lower() for i in range(len(temp)) if temp[i] != '']
- if label == 'pos':
- data.append([temp, 1])
- elif label == 'neg':
- data.append([temp, 0])
- print("finished loading......")
- return data
- # 读取train数据集,查看第211个
- train_data = load_data('./aclImdb')
- print(np.array(train_data[211][0]),"\n",train_data[211][1])
执行以上代码,得到:

定义一个函数,用于将句子中每个单词变成对应的向量的索引,每个句子只取250个单词,多的进行截断,少的以0补充,并保存文件。
- # 将读入的句子数据变成对应向量的索引(节省些空间)
- def process_sentence(flag):
- sentence_code = []
- word_list = np.load('word_list.npy', allow_pickle=True)
- word_list = word_list.tolist()
- test_data = load_data('./aclImdb', flag)
- print("process_sentence ing ......")
- for i in range(len(test_data)):
- vec = test_data[i][0]
- temp = []
- index = 0
- for j in range(len(vec)):
- try:
- index = word_list.index(vec[j])
- except ValueError: # 没找到
- index = 399999
- finally:
- temp.append(index) # temp表示一个单词在词典中的序号
- if len(temp) < 250:
- for k in range(len(temp), 250): # 不足补0
- temp.append(0)
- else:
- temp = temp[0:250] # 只保留250个
- sentence_code.append(temp)
- print("finished processing......")
- sentence_code = np.array(sentence_code)
- if flag == 'train':
- np.save('sentence_code_train', sentence_code)
- else:
- np.save('sentence_code_text', sentence_code)
- return sentence_code
- # 处理训练集数据变成对应向量的索引,查看第985个
- sentence_code_train = process_sentence("train")
- sentence_code_text = process_sentence("test")
- print(sentence_code_text[985])
执行上述代码,得到:
接下来,就是利用上述得到的npy文件,进行最后一步的处理。首先是按顺序读取每个标签,然后利用前面得到的索引,将每个单词具体的转化成50维的向量。但是,IMDb给的数据是25000个训练数据,25000个测试数据,为了保证模型充分的训练,重新划分训练和测试数据集。40000个训练数据,10000个测试数据。
- def get_arr_labels():
- # 25000维
- # (25000, 2) 25000句话, 单词向量+标签
- test_data = load_data('./aclImdb', flag='test')
- train_data = load_data('./aclImdb', flag="train")
- # 加载句子的索引
- # (25000句话, 250单词)
- sentence_code_1 = np.load('sentence_code_train.npy', allow_pickle=True)
- sentence_code_1 = sentence_code_1.tolist()
- # 25000 * 250测试集
- sentence_code_2 = np.load('sentence_code_text.npy', allow_pickle=True)
- sentence_code_2 = sentence_code_2.tolist()
- # 加载词向量表
- vocabulary_vectors = np.load('vocabulary_vectors.npy', allow_pickle=True)
- vocabulary_vectors = vocabulary_vectors.tolist()
- # 每个sentence_code都是25000 * 250 * 50
- for i in range(25000):
- sentence_code_1[i] = [vocabulary_vectors[x] for x in sentence_code_1[i]]
- sentence_code_2[i] = [vocabulary_vectors[x] for x in sentence_code_2[i]]
- # 重新划分数据集,40000训练10000测试
- data = train_data + test_data
- labels = [sublist[1] for sublist in data]
- sentence_code = np.r_[sentence_code_1, sentence_code_2]
- # 80%训练数据,20%测试数据
- train_labels = labels[:int(len(data) * 0.8)]
- test_labels = labels[int(len(data) * 0.8):]
- sentence_code_1 = sentence_code[:int(len(sentence_code) * 0.8)]
- sentence_code_2 = sentence_code[int(len(sentence_code) * 0.8):]
- labels_train = train_labels
- labels_test = test_labels
- arr_train = sentence_code_1
- arr_test = sentence_code_2
- arr_train = np.array(arr_train)
- arr_test = np.array(arr_test)
- labels_train = np.array(labels_train)
- labels_test = np.array(labels_test)
- np.save('arr_train', arr_train)
- np.save('arr_test', arr_test)
- np.save('labels_train', labels_train)
- np.save('labels_test', labels_test)
- return arr_train, labels_train, arr_test, labels_test
- get_arr_labels()
执行上述代码,得到4个npy文件。
这样,我们就完成了数据的预处理。
接下来,是LSTM网路的搭建,输入特征的维度是50(每个单词50维向量表示,隐藏层数量可自定义)同时定义一个前馈网络,用于分类,添加dropout层,防止过拟合。前馈网络具体参数可见代码。还有编写前向传播函数,输入序列数据,进入LSTM获取输出,然后进前馈网络,从每个序列的最后一个时间步选择输出,用于分类。
- class LSTM(nn.Module):
- def __init__(self, hidden_size):
- super(LSTM, self).__init__()
- self.lstm = nn.LSTM(input_size=50, hidden_size=hidden_size, num_layers=1,
- batch_first=True)
- self.fc = nn.Sequential(nn.Dropout(0.5),
- nn.Linear(hidden_size, 32),
- nn.Linear(32, 2),
- nn.ReLU())
- def forward(self, input_seq):
- # print(x.size())
- x, _ = self.lstm(input_seq)
- x = self.fc(x)
- x = x[:, -1, :]
- return x
接下来,就是编写训练函数,需要确定批次大小,和迭代次数,采用交叉熵损失函数,隐藏层数量定为128,使用Adam优化,后续的写法就比较常规,每各100次打印一次损失,记录训练过程的损失和准确率。
- def train(batch_size, num_epochs):
- # 设备配置
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- # 加载数据
- print("loading...")
- arr_train = np.load('arr_train.npy')
- labels_train = np.load('labels_train.npy')
- # 转换数据为torch张量
- arr_train_tensor = torch.tensor(arr_train, dtype=torch.float32).to(device)
- labels_train_tensor = torch.tensor(labels_train, dtype=torch.long).to(device) # 确保是 long 类型,交叉熵函数要求
- # 创建数据加载器
- train_dataset = TensorDataset(arr_train_tensor, labels_train_tensor.view(-1)) # 确保标签是一维的
- train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
- # 初始化模型并移动到设备
- hidden_size = 128
- model = LSTM(hidden_size).to(device)
- # 定义损失函数和优化器,并移动到设备
- criterion = nn.CrossEntropyLoss().to(device)
- optimizer = optim.Adam(model.parameters(), lr=0.001)
- # 记录损失和准确率
- lst_loss = []
- lst_accuracy = []
- # 训练模型
- num_epochs = num_epochs # 你可以根据需要调整epoch数量
- model.train() # 将模型设置为训练模式
- for epoch in range(num_epochs):
- temp_loss = []
- for i, (inputs, labels) in enumerate(train_loader):
- inputs = inputs.to(device) # 将输入数据移动到设备
- labels = labels.to(device) # 将标签移动到设备
- optimizer.zero_grad()
- outputs = model(inputs) # shape:[batch_size, 2]
- # print(outputs.shape,labels.shape)
- loss = criterion(outputs, labels.squeeze(0)) # labels 是一维的
- loss.backward()
- optimizer.step()
- if (i + 1) % 100 == 0:
- print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{i + 1}/{len(train_loader)}], Loss: {loss.item():.4f}')
- temp_loss.append(loss.item())
- # 每个epoch后保存
- lst_loss.append(sum(temp_loss)/len(temp_loss))
- accuracy = test(model)
- lst_accuracy.append(accuracy)
- # 保存模型
- torch.save(model.state_dict(), 'LSTM_model.pth')
- print('Training complete')
- return lst_loss, lst_accuracy
以上的train函数用到了test,每轮结束后就用测试集进行一次准确率的计算。test函数编写如下:
- def test(model):
- correct = 0
- total = 0
- # 设备配置
- device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
- # 1. 加载数据
- arr_test = np.load('arr_test.npy')
- labels_test = np.load('labels_test.npy') # 确保这个文件是正确的,并且是一维数组
- # 2. 转换数据为torch张量
- arr_test_tensor = torch.tensor(arr_test, dtype=torch.float32).to(device)
- labels_test_tensor = torch.tensor(labels_test, dtype=torch.long).to(device) # 确保是 long 类型
- # 3. 创建数据加载器
- test_dataset = TensorDataset(arr_test_tensor, labels_test_tensor.view(-1)) # 确保标签是一维的
- test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
- with torch.no_grad(): # 不计算梯度
- for inputs, labels in test_loader:
- inputs = inputs.to(device)
- labels = labels.to(device)
- outputs = model(inputs)
- _, predicted = torch.max(outputs.data, 1) # 预测最大概率的索引
- total += labels.size(0)
- correct += (predicted == labels).sum().item()
- accuracy = 100 * correct / total
- print(f'Accuracy of the model on the current epoch: {accuracy:.2f}%')
- return accuracy
紧接着,就是调用上述代码进行训练,同时将返回的列表(训练过程损失和准确率)进行可视化。
- # 调用模型进行训练
- lst_loss, lst_accuracy = train(batch_size=35, num_epochs=15)
- # 绘制损失变化曲线
- plt.figure()
- plt.plot(lst_loss, color='blue', label='Training Loss')
- for i, loss in enumerate(lst_loss):
- plt.scatter(i, loss, color='red') # 添加损失点标注
- plt.text(i, loss, f'{loss:.4f}', fontsize=9, va='bottom', ha='center', color='black') # 添加具体数值
- plt.xlabel('Epoch')
- plt.ylabel('Loss')
- plt.title('Training Loss')
- plt.legend()
- plt.show()
- # 绘制准确率变化曲线
- plt.figure()
- plt.plot(lst_accuracy, color='green', label='Test Accuracy')
- for i, acc in enumerate(lst_accuracy):
- plt.scatter(i, acc, color='orange') # 添加准确率点标注
- plt.text(i, acc, f'{acc:.2f}%', fontsize=9, va='bottom', ha='center', color='black') # 添加具体数值
- plt.xlabel('Epoch')
- plt.ylabel('Accuracy')
- plt.title('Test Accuracy')
- plt.legend()
- plt.show()
执行上述代码,得到如下结果:
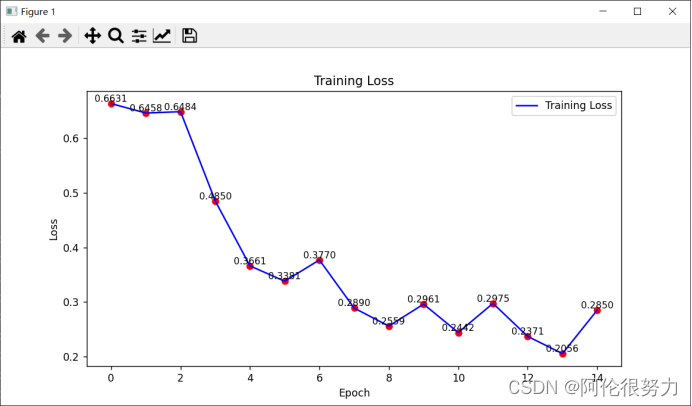
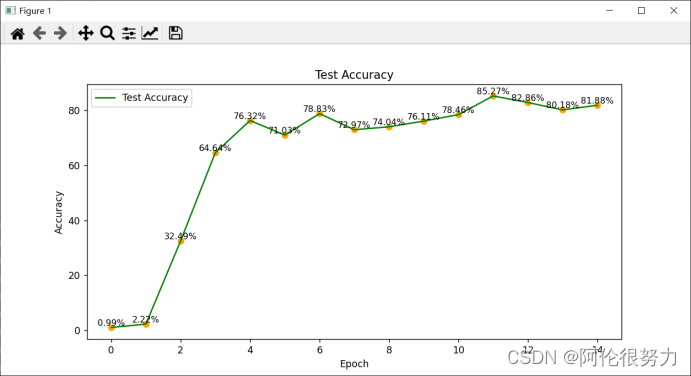
在迭代15次,准确率最高能够达到85.27%,这个准确率还是能接受的。
- 模型的特色
我的模型以一个标准的LSTM层开始,适用于处理序列数据,能够学习序列中的长期依赖关系。在全连接层之前使用Dropout,有助于减少模型的过拟合。LSTM层输出通过两个全连接层(Linear),这有助于将高维的隐藏状态转换为最终的分类结果。使用ReLU激活函数,引入非线性,使模型能够学习更复杂的模式。只使用LSTM层最后一个时间步的输出进行分类,这假设序列的最后一个时间步包含了对分类最重要的信息。模型是为二分类设计的,但通过调整最后的全连接层的输出维度,可以轻松地扩展到多分类问题。结构简洁,易于理解和实现。模型适用于需要处理序列数据的任务,如文本分类、时间序列预测等。
五.实验总结
LSTM,这是基于RNN的变种,网络结构参考下图。
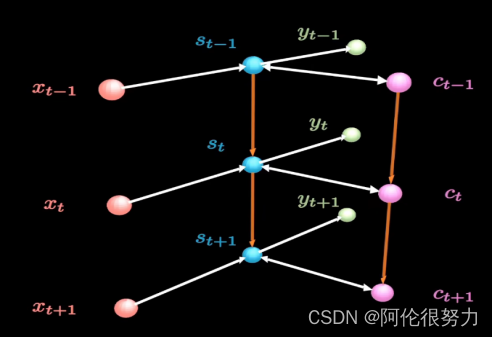
相比于RNN,LSTM增加了粉色部分的神经元,叫做long-term memory(长期记忆)。这样一来,要计算S_t的输出就变成了三个输入(X_t,S_t-1,C_t)。接下来看看,具体是网络的内部实现细节。
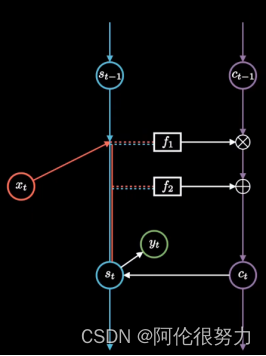
关键就是要弄明白新增加的long-term memory 是如何更新的。

关键在于f-1和f-2这两个函数,f-1利用的是sigmoid函数,介于0-1之间,这样矩阵元素相乘的时候会抹掉那些为0的元素,相对于选择性遗忘了部分记忆,由此 f-1也常被称作遗忘门,过滤重要特征,忽视无关信息。f-2则是利用到了sigmoid函数(再次对记忆进行选择)和tanh函数,取值在-1到1之间,相对于对过往记忆进行梳理归纳,所以f-2也被称作输入门。然后再按如下公式,更新C_t
![]()
以上就是LSTM相对于RNN增加的内容长期记忆,上述图片中的蓝色S神经元,也被称作短期记忆,保持两者的不断更新,相互作用,这就是LSTM成功的秘诀。
LSTM在自然语言处理(NLP),语言识别,时间序列预测方面都表现优异。
附:代码
数据处理
import os
import re
import numpy as np
# 读取 glove.6B.50d.txt 文件 构造一个 词向量表,将每一个英文单词转变为50维的向量
def load_cab_vector():
word_list = []
vocabulary_vectors = []
data = open('glove.6B.50d.txt', encoding='utf-8')
count = 0
for line in data.readlines():
if count % 100 == 0:
print(f"count:{count}")
count += 1
temp = line.strip('\n').split(' ') # 一个列表
name = temp[0]
word_list.append(name.lower())
vector = [temp[i] for i in range(1, len(temp))] # 向量
vector = list(map(float, vector)) # 变成浮点数
vocabulary_vectors.append(vector)
# 保存
vocabulary_vectors = np.array(vocabulary_vectors)
word_list = np.array(word_list)
np.save('vocabulary_vectors', vocabulary_vectors)
np.save('word_list', word_list)
return vocabulary_vectors, word_list
# 执行load_cab_vector函数
'''
words_vectors, words = load_cab_vector()
print(f"查询第211个单词及其向量:\n{words[211],words_vectors[211]}")
'''
# 读入数据,成为列表,带标签
def load_data(path, flag='train'):
labels = ['pos', 'neg']
data = []
print("load_data ing......")
for label in labels:
files = os.listdir(os.path.join(path, flag, label))
# 去除标点符号
r = '[’!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~\n。!,]+'
for file in files:
with open(os.path.join(path, flag, label, file), 'r', encoding='utf8') as rf:
temp = rf.read().replace('\n', '')
temp = temp.replace('<br /><br />', ' ')
temp = re.sub(r, '', temp)
temp = temp.split(' ')
temp = [temp[i].lower() for i in range(len(temp)) if temp[i] != '']
if label == 'pos':
data.append([temp, 1])
elif label == 'neg':
data.append([temp, 0])
print("finished loading......")
return data
'''
# 读取train数据集,查看第211个
train_data = load_data('./aclImdb')
print(np.array(train_data[211][0]),"\n",train_data[211][1])
'''
# 将读入的句子数据变成对应向量的索引(节省些空间)
def process_sentence(flag):
sentence_code = []
word_list = np.load('word_list.npy', allow_pickle=True)
word_list = word_list.tolist()
test_data = load_data('./aclImdb', flag)
print("process_sentence ing ......")
for i in range(len(test_data)):
vec = test_data[i][0]
temp = []
index = 0
for j in range(len(vec)):
try:
index = word_list.index(vec[j])
except ValueError: # 没找到
index = 399999
finally:
temp.append(index) # temp表示一个单词在词典中的序号
if len(temp) < 250:
for k in range(len(temp), 250): # 不足补0
temp.append(0)
else:
temp = temp[0:250] # 只保留250个
sentence_code.append(temp)
print("finished processing......")
sentence_code = np.array(sentence_code)
if flag == 'train':
np.save('sentence_code_train', sentence_code)
else:
np.save('sentence_code_text', sentence_code)
return sentence_code
'''
# 处理训练集数据变成对应向量的索引,查看第985个
sentence_code_train = process_sentence("train")
sentence_code_text = process_sentence("test")
print(sentence_code_text[985])
'''
def get_arr_labels():
# 25000维
# (25000, 2) 25000句话, 单词向量+标签
test_data = load_data('./aclImdb', flag='test')
train_data = load_data('./aclImdb', flag="train")
# 加载句子的索引
# (25000句话, 250单词)
sentence_code_1 = np.load('sentence_code_train.npy', allow_pickle=True)
sentence_code_1 = sentence_code_1.tolist()
# 25000 * 250测试集
sentence_code_2 = np.load('sentence_code_text.npy', allow_pickle=True)
sentence_code_2 = sentence_code_2.tolist()
# 加载词向量表
vocabulary_vectors = np.load('vocabulary_vectors.npy', allow_pickle=True)
vocabulary_vectors = vocabulary_vectors.tolist()
# 每个sentence_code都是25000 * 250 * 50
for i in range(25000):
sentence_code_1[i] = [vocabulary_vectors[x] for x in sentence_code_1[i]]
sentence_code_2[i] = [vocabulary_vectors[x] for x in sentence_code_2[i]]
# 重新划分数据集,40000训练10000测试
data = train_data + test_data
labels = [sublist[1] for sublist in data]
sentence_code = np.r_[sentence_code_1, sentence_code_2]
# 80%训练数据,20%测试数据
train_labels = labels[:int(len(data) * 0.8)]
test_labels = labels[int(len(data) * 0.8):]
sentence_code_1 = sentence_code[:int(len(sentence_code) * 0.8)]
sentence_code_2 = sentence_code[int(len(sentence_code) * 0.8):]
labels_train = train_labels
labels_test = test_labels
arr_train = sentence_code_1
arr_test = sentence_code_2
arr_train = np.array(arr_train)
arr_test = np.array(arr_test)
labels_train = np.array(labels_train)
labels_test = np.array(labels_test)
np.save('arr_train', arr_train)
np.save('arr_test', arr_test)
np.save('labels_train', labels_train)
np.save('labels_test', labels_test)
return arr_train, labels_train, arr_test, labels_test
LSTM
import numpy as np
import torch
from matplotlib import pyplot as plt
from torch import nn, optim
from torch.utils.data import TensorDataset, DataLoader
class LSTM(nn.Module):
def __init__(self, hidden_size):
super(LSTM, self).__init__()
self.lstm = nn.LSTM(input_size=50, hidden_size=hidden_size, num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(hidden_size, 32),
nn.Linear(32, 2),
nn.ReLU())
def forward(self, input_seq):
# print(x.size())
x, _ = self.lstm(input_seq)
x = self.fc(x)
x = x[:, -1, :]
return x
def train(batch_size, num_epochs):
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据
print("loading...")
arr_train = np.load('arr_train.npy')
labels_train = np.load('labels_train.npy')
# 转换数据为torch张量
arr_train_tensor = torch.tensor(arr_train, dtype=torch.float32).to(device)
labels_train_tensor = torch.tensor(labels_train, dtype=torch.long).to(device) # 确保是 long 类型,交叉熵函数要求
# 创建数据加载器
train_dataset = TensorDataset(arr_train_tensor, labels_train_tensor.view(-1)) # 确保标签是一维的
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 初始化模型并移动到设备
hidden_size = 128
model = LSTM(hidden_size).to(device)
# 定义损失函数和优化器,并移动到设备
criterion = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 记录损失和准确率
lst_loss = []
lst_accuracy = []
# 训练模型
num_epochs = num_epochs # 你可以根据需要调整epoch数量
model.train() # 将模型设置为训练模式
for epoch in range(num_epochs):
temp_loss = []
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device) # 将输入数据移动到设备
labels = labels.to(device) # 将标签移动到设备
optimizer.zero_grad()
outputs = model(inputs) # shape:[batch_size, 2]
# print(outputs.shape,labels.shape)
loss = criterion(outputs, labels.squeeze(0)) # labels 是一维的
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{i + 1}/{len(train_loader)}], Loss: {loss.item():.4f}')
temp_loss.append(loss.item())
# 每个epoch后保存
lst_loss.append(sum(temp_loss)/len(temp_loss))
accuracy = test(model)
lst_accuracy.append(accuracy)
# 保存模型
torch.save(model.state_dict(), 'LSTM_model.pth')
print('Training complete')
return lst_loss, lst_accuracy
def test(model):
correct = 0
total = 0
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 1. 加载数据
arr_test = np.load('arr_test.npy')
labels_test = np.load('labels_test.npy') # 确保这个文件是正确的,并且是一维数组
# 2. 转换数据为torch张量
arr_test_tensor = torch.tensor(arr_test, dtype=torch.float32).to(device)
labels_test_tensor = torch.tensor(labels_test, dtype=torch.long).to(device) # 确保是 long 类型
# 3. 创建数据加载器
test_dataset = TensorDataset(arr_test_tensor, labels_test_tensor.view(-1)) # 确保标签是一维的
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False)
with torch.no_grad(): # 在评估模式下,不计算梯度
for inputs, labels in test_loader:
inputs = inputs.to(device)
print(inputs)
labels = labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1) # 预测最大概率的索引
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f'Accuracy of the model on the current epoch: {accuracy:.2f}%')
return accuracy
# 调用模型进行训练
lst_loss, lst_accuracy = train(batch_size=35, num_epochs=30)
# 绘制损失变化曲线
plt.figure()
plt.plot(lst_loss, color='blue', label='Training Loss')
for i, loss in enumerate(lst_loss):
plt.scatter(i, loss, color='red') # 添加损失点标注
plt.text(i, loss, f'{loss:.4f}', fontsize=9, va='bottom', ha='center', color='black') # 添加具体数值
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.legend()
plt.show()
# 绘制准确率变化曲线
plt.figure()
plt.plot(lst_accuracy, color='green', label='Test Accuracy')
for i, acc in enumerate(lst_accuracy):
plt.scatter(i, acc, color='orange') # 添加准确率点标注
plt.text(i, acc, f'{acc:.2f}%', fontsize=9, va='bottom', ha='center', color='black') # 添加具体数值
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Test Accuracy')
plt.legend()
plt.show()

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 33
33 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)