
机器学习算法——决策树
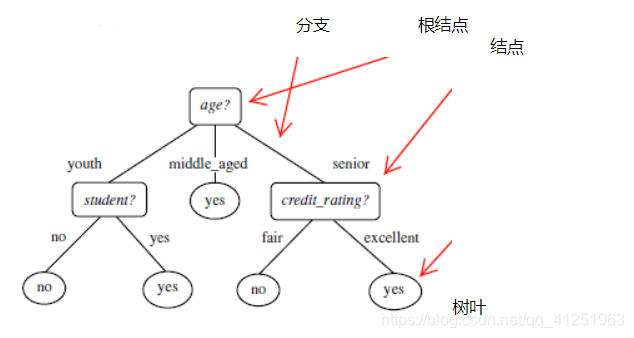
1. 什么是决策树/判定树(decision tree)?判定树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。树模型:决策树:从根结点开始一步步走到叶子结点(决策)所有的数据最终会落到叶子结点,既可以做分类也可以做回归树的组成:根结点:第一个选择点非叶子结点与分支...
1. 什么是决策树/判定树(decision tree)?
判定树是一个类似于流程图的树结构:其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。
树模型:
- 决策树:从根结点开始一步步走到叶子结点(决策)
- 所有的数据最终会落到叶子结点,既可以做分类也可以做回归
树的组成:
- 根结点:第一个选择点
- 非叶子结点与分支:中间过程
- 叶子结点:最终的决策结果
决策树的训练与测试:
- 训练阶段:从给定的训练集构造出来一棵树(从跟结点开始选择特征,如何进行特征切分)
- 测试阶段:根据构造出来的树模型从上到下走一遍
- 一旦构造好了决策树,分类或者预测任务就简单了,只需要走一遍就可以了。
如何切分特征(选择节点):
- 通过一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点,以此类推。
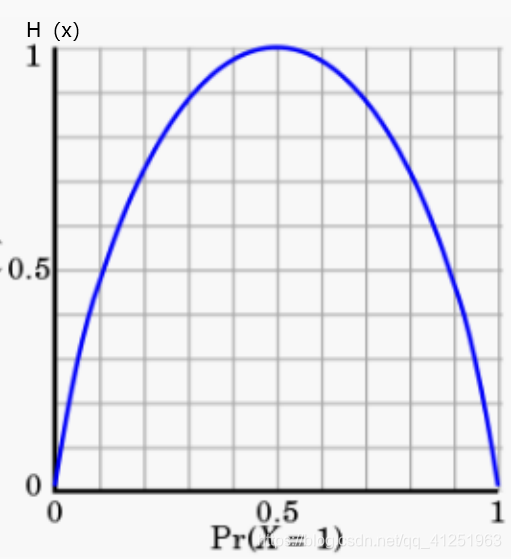
衡量标准-熵:熵是表示随机变量不确定性的度量(变量的不确定性越大,熵也越大)
-
信息和抽象,如何度量?
1948年,香农提出了 ”信息熵(entropy)“的概念
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者
是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少
例子:猜世界杯冠军,假如一无所知,猜多少次?每个队夺冠的几率不是相等的
比特(bit)来衡量信息的多少
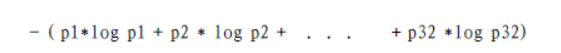
公式:H(x)=-∑pi*logPi,i=1,2,...,n
当p=0或p=1时,H(p)=0,随机变量完全没有不确定性
当p=0.5时,H(P)=1,此时随机变量的不确定性最大
信息增益:表示特征X使得类Y的不确定性减少的程度。(分类后的专一性,希望分类后的结果是同类在一起)
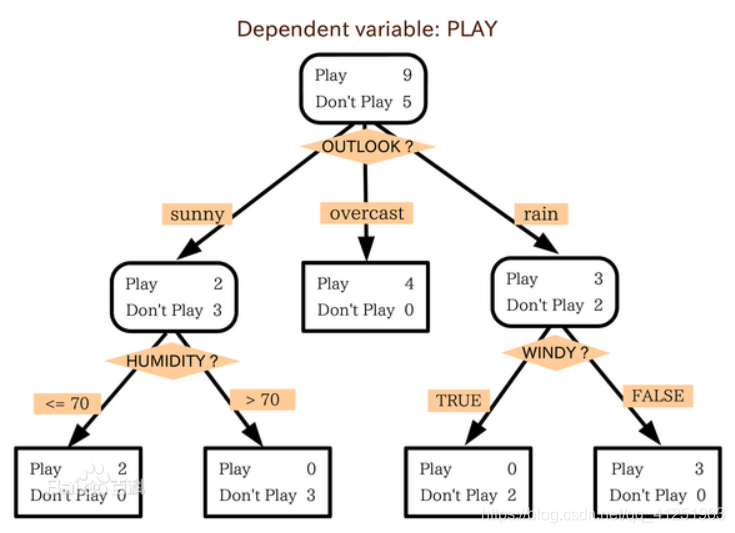
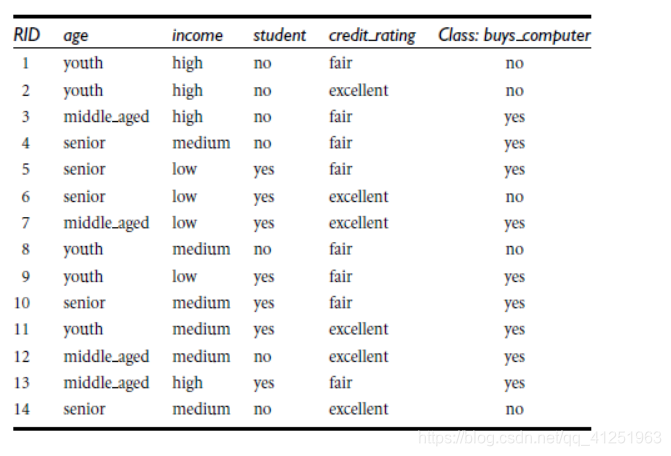
决策树构造实例:
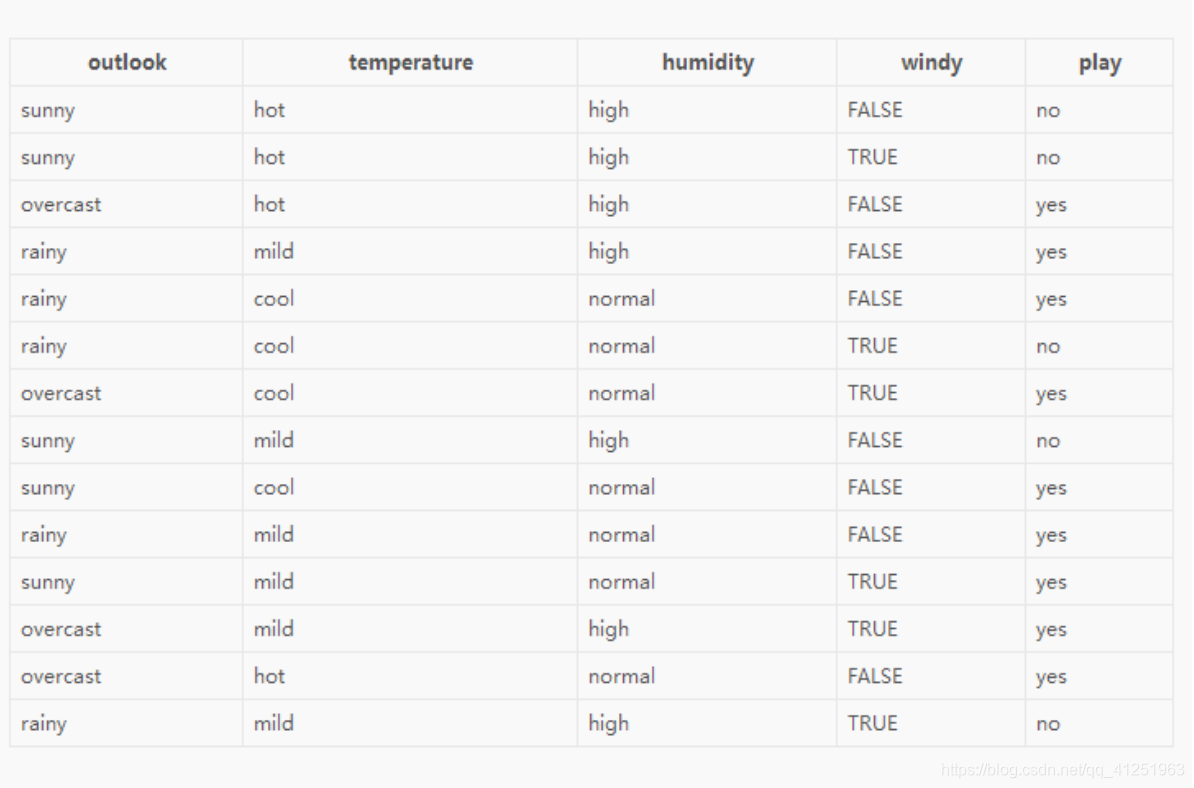
- 数据:14天打球情况
- 特征:4种环境变化
- 目标:构造决策树
在历史数据中(14天)有9天打球,5天不打球,所以此时的熵应为:
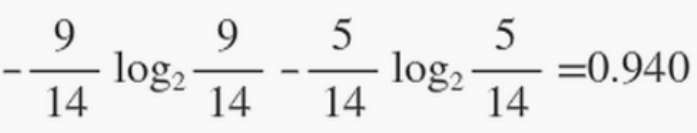
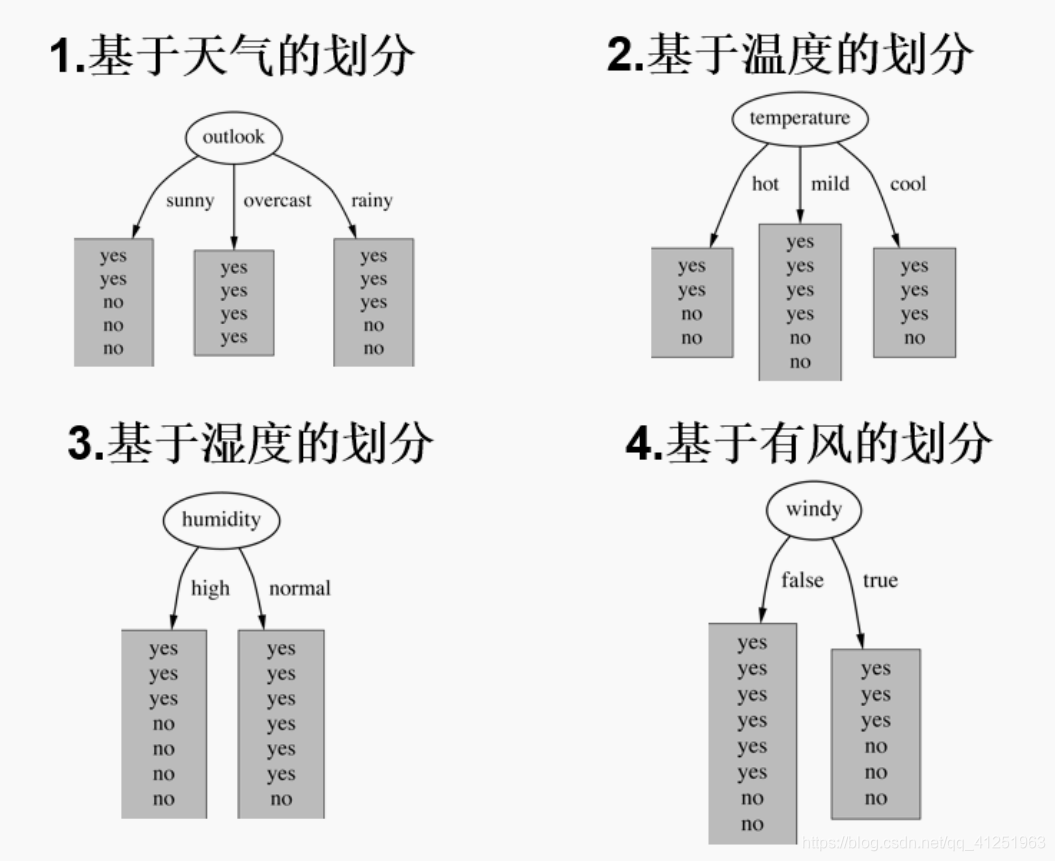
4个特征逐一分析,先从outlook特征开始:
Outlook = sunny时,熵值为0.971
Outlook = overcast时,熵值为0
Outlook = rainy时,熵值为0.9
- 根据数据统计,outlook取值分别为sunny,overcast,rainy的概率分别为:
5/14, 4/14, 5/14 - 熵值计算:5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693
(gain(temperature)=0.029 gain(humidity)=0.152 gain(windy)=0.048) - 信息增益:系统的熵值从原始的0.940下降到了0.693,增益为0.247
- 同样的方式可以计算出其他特征的信息增益,那么我们选择最大的那个
就可以啦
决策树算法:
- ID3:信息增益
- C4.5:信息增益率(解决ID3问题,考虑自身熵)
- CART:使用GINI系数来当做衡量标准
- GINI系数:
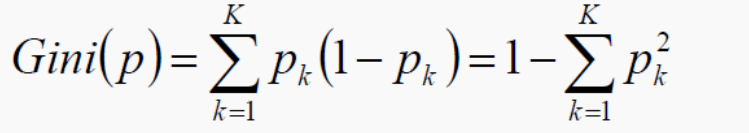
- 和熵的衡量标准类似计算方式不同
遇到连续值,二分
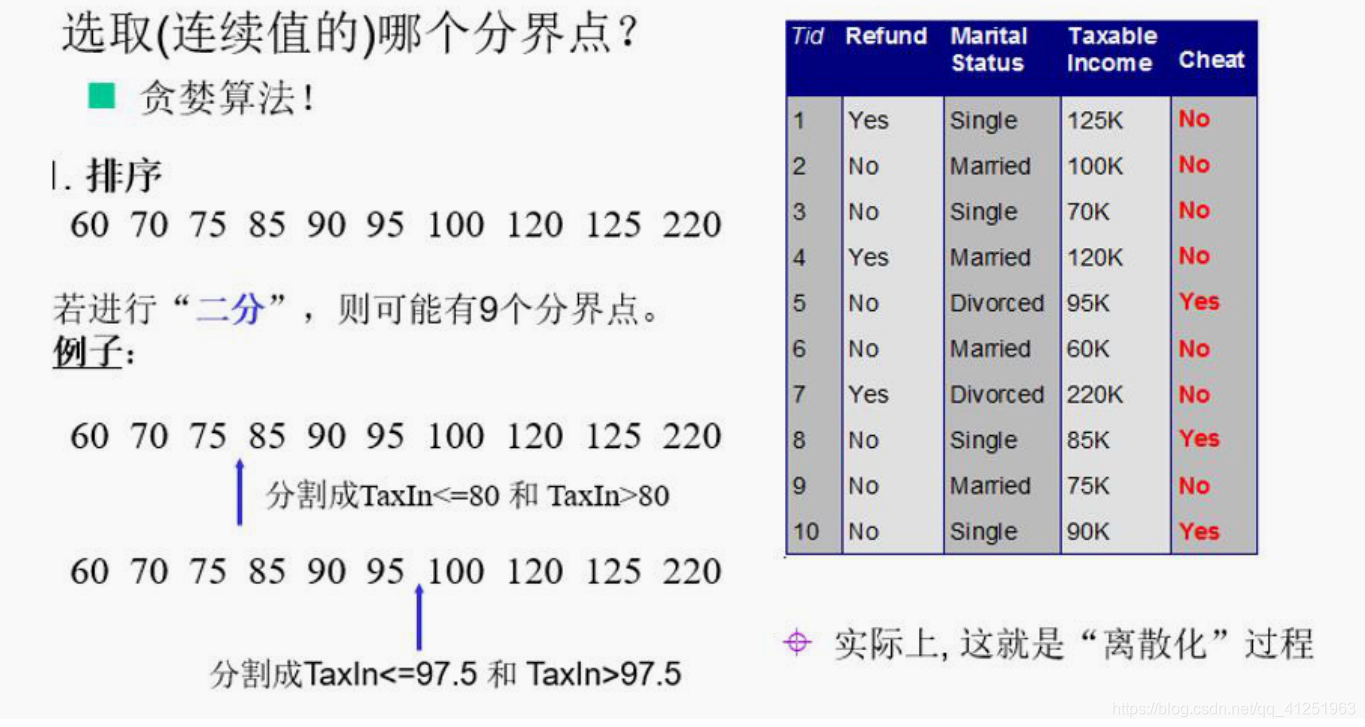
决策树剪枝策略:
- 为什么要剪枝:决策树过拟合风险很大,理论上可以完全分得开数据
- 剪枝策略:预剪枝,后剪枝
- 预剪枝:边建立决策树边进行剪枝的操作(更实用)。限制深度,叶子节点个数,叶子节点样本数,信息增益量等。
- 后剪枝:当建立完决策树后来进行剪枝操作。通过一定的衡量标准
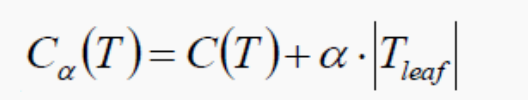
叶子节点越多,损失越大。
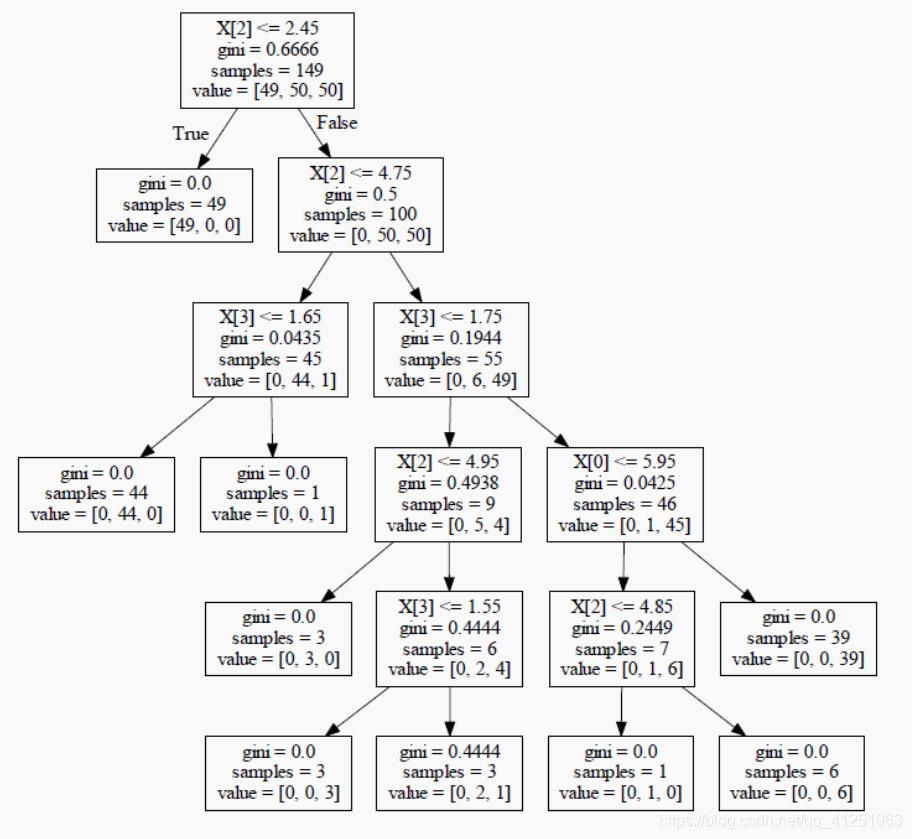
使用sklearn构造决策树模型:
树模型参数:
-
1.criterion gini or entropy
-
2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)
-
3.max_features None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的
-
4.max_depth 数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下
-
5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
-
6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
-
7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
-
8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制具体的值可以通过交叉验证得到。
-
9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
-
10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
- n_estimators:要建立树的个数
import matplotlib.pyplot as plt
#导入内置数据集
from sklearn.datasets.california_housing import fetch_california_housing
housing=fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.data[0])
from sklearn import tree
#树的最大深度为2
dtr=tree.DecisionTreeRegressor(max_depth=2)
dtr.fit(housing.data[:,[6,7]],housing.target)
print(dtr)
dot_data = tree.export_graphviz(
dtr,
out_file = None,
feature_names = housing.feature_names[6:8],
filled = True,
impurity = False,
rounded = True
)
import pydotplus
graph = pydotplus.graph_from_dot_data(dot_data)
graph.get_nodes()[7].set_fillcolor("#FFF2DD")
from IPython.display import Image
Image(graph.create_png())
graph.write_png("dtr_white_background.png") 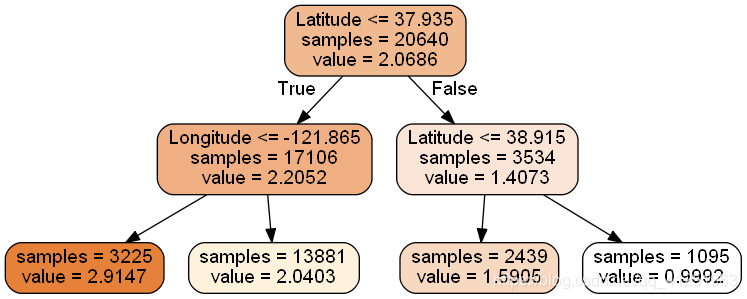
import matplotlib.pyplot as plt
import pandas as pd
#导入内置数据集
from sklearn.datasets.california_housing import fetch_california_housing
housing=fetch_california_housing()
print(housing.DESCR)
print(housing.data.shape)
print(housing.data[0])
from sklearn import tree
#树的最大深度为2
dtr=tree.DecisionTreeRegressor(max_depth=2)
dtr.fit(housing.data[:,[6,7]],housing.target)
print(dtr)
#
#
from sklearn.model_selection import train_test_split
data_train, data_test, target_train, target_test = train_test_split(housing.data, housing.target, test_size = 0.1, random_state = 42)
dtr = tree.DecisionTreeRegressor(random_state = 42)
dtr.fit(data_train, target_train)
print(dtr.score(data_test, target_test))
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor( random_state = 42)
rfr.fit(data_train, target_train)
print(rfr.score(data_test, target_test))
from sklearn.model_selection import GridSearchCV
tree_param_grid = { 'min_samples_split': list((3,6,9)),'n_estimators':list((10,50,100))}
grid = GridSearchCV(RandomForestRegressor(),param_grid=tree_param_grid, cv=5)
grid.fit(data_train, target_train)
print(grid.cv_results_, grid.best_params_, grid.best_score_)
rfr = RandomForestRegressor( min_samples_split=3,n_estimators = 100,random_state = 42)
rfr.fit(data_train, target_train)
print(rfr.score(data_test, target_test))
pd.Series(rfr.feature_importances_, index = housing.feature_names).sort_values(ascending = False)

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)