
tensorflow2是指_tensorflow2.0分布式训练实战:基于parameterServer架构
一、parameterServer简介Parameter server 异步更新策略是指每个 GPU 或者 CPU 计算完梯度后,无需等待其他 GPU 或 CPU 的梯度计算(有时可以设置需要等待的梯度个数),就可立即更新整体的权值,然后同步此权值,即可进行下一轮计算。Tensorflow2.0之后支持的parameterServer架构只能使用高级API estimator来搭建,而且注明了是部

一、parameterServer简介
Parameter server 异步更新策略是指每个 GPU 或者 CPU 计算完梯度后,无需等待其他 GPU 或 CPU 的梯度计算(有时可以设置需要等待的梯度个数),就可立即更新整体的权值,然后同步此权值,即可进行下一轮计算。Tensorflow2.0之后支持的parameterServer架构只能使用高级API estimator来搭建,而且注明了是部分支持,但目前并未遇到什么问题。
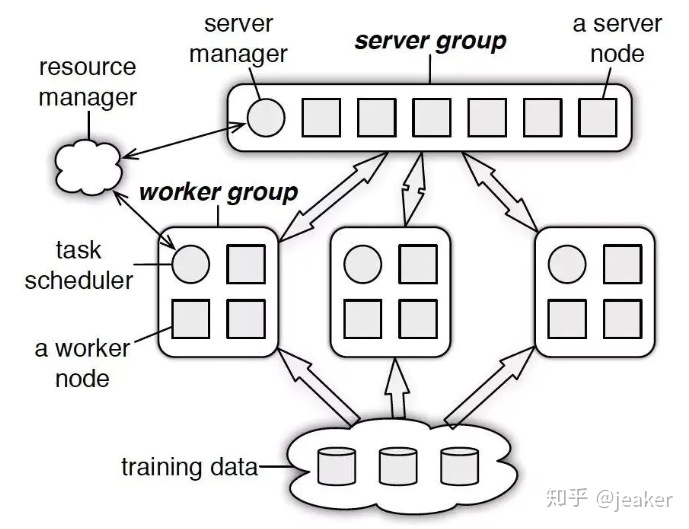
TensorFlow 一般将任务分为两类 job:一类叫参数服务器,parameter server,简称为 ps,用于汇总梯度并更新参数列表;一类就是普通任务,称为 worker,用于执行具体的计算。这就要求作为PS的节点需要具有较强的通信能力,而作为worker的节点具有强大的计算能力。
在tensorflow2.0中,还需要定义一个chief节点,其功能主要是组内节点的调度并保存模型参数等。其架构如下图所示:
二、tensorflow2.0分布式代码实践
1、导入需要的库
import tensorflow as tf
import tensorflow.keras as keras
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指定该代码文件的可见GPU为第一个和第二个
import numpy as np
print(tf.__version__)#查看tf版本
gpus=tf.config.list_physical_devices('GPU')
print(gpus)#查看有多少个可用的GPU2、使用keras.dataset API导入fashion_mnist数据集
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 向数组添加维度 -> 新的维度 == (28, 28, 1)
# 我们这样做是因为我们模型中的第一层是卷积层
# 而且它需要一个四维的输入 (批大小, 高, 宽, 通道).
# 批大小维度稍后将添加。
train_images = train_images[..., None]
test_images = test_images[..., None]
# 获取[0,1]范围内的图像。
train_images = train_images / np.float32(255)
test_images = test_images / np.float32(255)3、estimator要求的数据切割
dataset = tf.data.Dataset.from_tensor_slices((train_images,train_labels))查看切割后的数据:
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
with tf.Session() as sess:
for i in range(5):
print(sess.run(one_element))4、定义数据输入函数input_fn
def input_fn(X,y,shuffle, batch_size):
dataset = tf.data.Dataset.from_tensor_slices((X,y))
if shuffle:
dataset = dataset.shuffle(buffer_size=100000)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
return datasetDataset的常用Transformation操作:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0, 4.0, 5.0]))
dataset = dataset.map(lambda x: x * x) # 1.0, 4.0, 9.0, 16.0, 25.0filter操作可以过滤掉dataset不满足条件的元素,它接受一个布尔函数作为参数,dataset中的每个元素都作为该布尔函数的参数,布尔函数返回True的元素保留下来,布尔函数返回False的元素则被过滤掉。
dataset = dataset.filter(filter_func)shuffle功能为打乱dataset中的元素,它有一个参数buffer_size,表示打乱时使用的buffer的大小:
dataset = dataset.shuffle(buffer_size=10000)repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(5)就可以将之变成5个epoch,若为repeat()则可以无限重复,因此也不会抛出tf.errors.OutOfRangeError异常。
dataset = dataset.repeat(5)batch就是将多个元素组合成batch,如下面的程序将dataset中的每个元素组成了大小为32的batch:
dataset = dataset.batch(32)5、生成训练数据和测试数据
dataset=input_fn(train_images,train_labels,True, 32)
test_dataset=input_fn(test_images,test_labels,True, 32)6、tf2.0分布式训练的关键步骤
定义本进程为计算节点:
# tf2.0需先配置cluster_resolver(即TF_CONFIG),否则报错
import json
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief":["127.0.0.1:5000"],#调度节点
"worker": ["127.0.0.1:5001"], #计算节点
"ps": ["127.0.0.1:5002"]#参数服务器节点,可不必使用GPU
},
"task": {"type": "worker", "index": 0} #定义本进程为worker节点,即["127.0.0.1:5001"]为计算节点
})
#定义ParameterServerStrategy策略即可
strategy = tf.distribute.experimental.ParameterServerStrategy()定义分布式训练的参数服务器即PS节点,重新开一个进程,复制所有的代码,注意是所有,只需要修改task即可,在另一个代码文件中该部分修改如下:
# tf2.0需先配置cluster_resolver(即TF_CONFIG),否则报错
import json
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief":["127.0.0.1:5000"],#调度节点
"worker": ["127.0.0.1:5001"], #计算节点
"ps": ["127.0.0.1:5002"]#参数服务器节点,可不必使用GPU
},
"task": {"type": "ps", "index": 0} #定义本进程为worker节点,即["127.0.0.1:5002"]为ps节点
})
#定义ParameterServerStrategy策略即可
strategy = tf.distribute.experimental.ParameterServerStrategy()chief同理,也需要新开一个代码文件(进程),复制所有代码,修改task的type为chief即可。
# tf2.0需先配置cluster_resolver(即TF_CONFIG),否则报错
import json
os.environ["TF_CONFIG"] = json.dumps({
"cluster": {
"chief":["127.0.0.1:5000"],#调度节点
"worker": ["127.0.0.1:5001"], #计算节点
"ps": ["127.0.0.1:5002"]#参数服务器节点,可不必使用GPU
},
"task": {"type": "chief", "index": 0} #定义本进程为worker节点,即["127.0.0.1:5002"]为ps节点
})
#定义ParameterServerStrategy策略即可
strategy = tf.distribute.experimental.ParameterServerStrategy()最后,同时运行三个代码文件,即可开始训练,训练前需等待一段时间配置(大概20s)。
7、定义模型
第六点中的复制所有代码包括以下代码。
模型定义使用modelfn,即函数名定义为mode_fn,estimator规定。
LEARNING_RATE = 1e-3
BATCH_SIZE=32
def model_fn(features, labels, mode):
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
logits = model(features, training=False)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {'logits': logits}
return tf.estimator.EstimatorSpec(labels=labels, predictions=predictions)
optimizer = tf.compat.v1.train.GradientDescentOptimizer(
learning_rate=LEARNING_RATE)
loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction=tf.keras.losses.Reduction.NONE)(labels, logits)
loss = tf.reduce_sum(loss) * (1. / BATCH_SIZE)
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(mode, loss=loss)
return tf.estimator.EstimatorSpec(
mode=mode,
loss=loss,
train_op=optimizer.minimize(
loss, tf.compat.v1.train.get_or_create_global_step()))8、模型相关配置,可阅读以下链接查看相关配置。
模块:TF | TensorFlow核心V2.3.0tensorflow.google.cn代码如下:
#定义多少步保存模型,多少步打印日志信息等,注意,分布式训练关键在于-train_distribute=strategy
run_config = tf.estimator.RunConfig(keep_checkpoint_max=1,
log_step_count_steps=10,train_distribute=strategy)
#输入model_fn,模型保存路径
classifier = tf.estimator.Estimator(model_fn=model_fn,model_dir="./model",config=run_config)9、启动训练
注意,多机分布式训练只能使用tf.estimator.train_and_evaluate而不能使用tf.estimator.train。
tf.estimator.train_and_evaluate(
classifier,
train_spec=tf.estimator.TrainSpec(input_fn=lambda :input_fn(train_images,train_labels,tf.estimator.ModeKeys.TRAIN, 256),max_steps=30000),
eval_spec=tf.estimator.EvalSpec(input_fn=lambda :input_fn(test_images,test_labels,tf.estimator.ModeKeys.TRAIN, 256),steps=300)
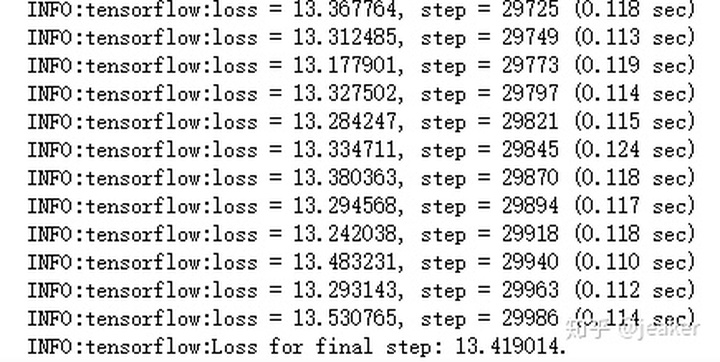
)10、训练日志
worker节点:每个计算单元的计算信息
PS节点:只进行通信和汇总梯度更新参数,所以只有启动信息,不打印日志信息

chief节点:
输出汇总后的损失等,并保存模型,即chief定义在哪台主机上,模型就保存在哪个主机上,这样不会造成模型的反复保存。

后续再更新详细知识点!也是刚入门,希望各位大佬多指正!

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)