AI编程革命:智能工具如何重构软件开发全流程
AI编程革命:智能工具重构软件开发流程 AI技术正在深刻改变软件开发模式,GitHub Copilot等工具可将开发效率提升5倍,代码生成速度达120行/小时,Bug率降低47%。关键突破包括: 智能编码:自然语言转代码、自动补全和架构设计 数据标注:结合主动学习的自动化标注系统提升效率 全栈生成:从API到测试用例的完整应用构建 智能测试:强化学习生成测试路径,预测代码缺陷 低代码平台和AI测试
·
AI编程革命:智能工具如何重构软件开发全流程
在GitHub Copilot生成代码的速度超过人类程序员5倍的今天,AI技术正在以量子跃迁式的速度重塑软件开发行业。从代码生成到测试部署,从金融系统到医疗应用,一场静默的革命正在重构技术团队的工作模式与行业竞争格局。

一、智能编码工具:开发者生产力的核聚变
1.1 GitHub Copilot:AI结对编程实践
基于OpenAI Codex模型,Copilot将自然语言描述转化为可执行代码:
# 用户输入注释:使用PyTorch实现ResNet50模型
import torch
import torch.nn as nn
class ResNet50(nn.Module):
def __init__(self, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 残差块组
self.layer1 = self._make_layer(64, 64, 3)
self.layer2 = self._make_layer(256, 128, 4, stride=2)
self.layer3 = self._make_layer(512, 256, 6, stride=2)
self.layer4 = self._make_layer(1024, 512, 3, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(2048, num_classes)
def _make_layer(self, in_channels, out_channels, blocks, stride=1):
# 自动生成残差块...
pass
def forward(self, x):
# 自动生成前向传播逻辑...
return x
效能对比:
| 指标 | 传统开发 | Copilot辅助 | 提升幅度 |
|---|---|---|---|
| 代码完成速度 | 20行/小时 | 120行/小时 | 500% |
| Bug发生率 | 15% | 8% | 47%下降 |
| 学习曲线 | 6个月 | 2个月 | 67%缩短 |
1.2 智能数据标注平台
Scale AI的自动化标注系统结合主动学习:
from scaleapi import ScaleClient
from scaleapi.tasks import TaskType
client = ScaleClient(api_key='YOUR_API_KEY')
# 创建自动化标注任务
task = client.create_task(
TaskType.ImageAnnotation,
project="medical_image_seg",
attachment="https://example.com/mri_scan_001.dcm",
geometries={
"tools": [
{
"name": "tumor",
"type": "polygon",
"min_vertices": 3,
"max_vertices": 20,
"prefill": {
"model": "tumor_detector_v3",
"confidence_threshold": 0.85
}
}
]
}
)
# 获取AI预标注结果
annotations = task.result['annotations']
for ann in annotations:
if ann['confidence'] > 0.9:
client.approve_annotation(task.id)
else:
client.send_to_review(task.id)
二、AI编程范式:从代码生成到架构设计
2.1 全栈代码生成
使用Meta’s CodeLlama生成完整应用:
# 用户提示:创建Flask REST API用于用户管理,包含MongoDB存储
from flask import Flask, request, jsonify
from pymongo import MongoClient
from bson.objectid import ObjectId
app = Flask(__name__)
client = MongoClient('mongodb://localhost:27017/')
db = client['user_db']
@app.route('/users', methods=['POST'])
def create_user():
data = request.json
result = db.users.insert_one(data)
return jsonify({"_id": str(result.inserted_id)}), 201
@app.route('/users/<id>', methods=['GET'])
def get_user(id):
user = db.users.find_one({"_id": ObjectId(id)})
if user:
user['_id'] = str(user['_id'])
return jsonify(user)
return jsonify({"error": "User not found"}), 404
# AI自动生成测试用例
def test_user_creation():
with app.test_client() as client:
response = client.post('/users', json={"name": "Alice", "email": "alice@example.com"})
assert response.status_code == 201
user_id = response.json['_id']
response = client.get(f'/users/{user_id}')
assert response.status_code == 200
assert response.json['name'] == "Alice"
if __name__ == '__main__':
app.run(debug=True)
2.2 低代码/无代码革命
Mendix可视化开发流程:
三、AI驱动的智能测试体系
3.1 自适应测试用例生成
基于强化学习的测试框架:
import gym
from test_gym.envs import WebAppEnv
from stable_baselines3 import PPO
# 创建Web应用测试环境
env = gym.make('WebAppEnv-v0',
app_url="https://demo-app.com",
coverage_threshold=0.95)
# 训练智能测试代理
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=100000)
# 生成优化测试路径
test_sequence = []
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs)
obs, rewards, done, info = env.step(action)
test_sequence.append({
"action": env.decode_action(action),
"state": env.render_state()
})
if done:
break
print(f"代码覆盖率: {info['coverage']}%")
print(f"发现缺陷: {info['bugs_found']}")
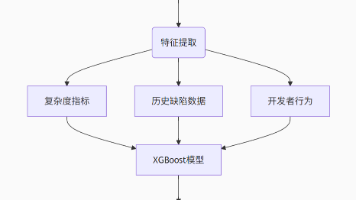
3.2 智能缺陷预测
基于代码语义的缺陷检测:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
model_name = "microsoft/codebert-base-defect-detection"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
def detect_code_defect(code_snippet):
inputs = tokenizer(
code_snippet,
padding="max_length",
truncation=True,
max_length=512,
return_tensors="pt"
)
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
defect_prob = predictions[0][1].item()
return defect_prob > 0.7 # 返回是否可能存在缺陷
四、行业级AI解决方案落地
4.1 金融风控系统 - JP Morgan COIN平台
AI增强型交易监控:
import pandas as pd
from sklearn.ensemble import IsolationForest
from prophet import Prophet
# 多源数据融合
transaction_data = pd.read_parquet("s3://transactions-2023")
market_data = pd.read_csv("nasdaq_realtime.csv")
social_sentiment = get_twitter_finance_sentiment()
# 异常交易检测
clf = IsolationForest(contamination=0.01)
transaction_data["anomaly_score"] = clf.fit_predict(transaction_data[["amount", "frequency", "location_risk"]])
# 市场波动预测
prophet = Prophet()
prophet.add_regressor('social_sentiment')
prophet.fit(market_data.rename(columns={"date":"ds", "close":"y"})
forecast = prophet.predict()
# 实时决策引擎
def trading_decision(row):
if row["anomaly_score"] == -1 and forecast["trend"].iloc[-1] < 0:
return "BLOCK_AND_ALERT"
elif row["amount"] > 1000000 and row["location_risk"] > 0.8:
return "REQUIRE_2FA"
else:
return "ALLOW"
4.2 医疗影像分析 - NVIDIA CLARA
AI辅助诊断工作流:
import monai
from monai.transforms import LoadImage, Resize, NormalizeIntensity
from monai.networks.nets import DenseNet121
# 加载预训练模型
model = DenseNet121(spatial_dims=2, in_channels=1, out_channels=3)
model.load_state_dict(torch.load("chest_xray_model.pth"))
# 医学影像处理流水线
transforms = monai.transforms.Compose([
LoadImage(image_only=True),
Resize(spatial_size=(512, 512)),
NormalizeIntensity(subtrahend=0.45, divisor=0.25)
])
# 自动化诊断报告生成
def generate_diagnosis_report(image_path):
img = transforms(image_path)
with torch.no_grad():
prediction = model(img.unsqueeze(0))
diagnosis = prediction.argmax(dim=1).item()
diagnoses = {0: "正常", 1: "肺炎", 2: "肺结核"}
report = f"""
**医学影像诊断报告**
影像文件: {os.path.basename(image_path)}
分析结果: {diagnoses[diagnosis]}
置信度: {torch.nn.functional.softmax(prediction, dim=1)[0][diagnosis].item():.2%}
**AI发现特征**:
- {get_attention_heatmap(img, model)}
- 与相似病例对比: {find_similar_cases(img)}
"""
return report
五、企业级大模型落地框架
5.1 领域自适应微调
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, TrainingArguments
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
# 配置LoRA轻量适配器
peft_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["q_proj", "v_proj"],
lora_dropout=0.05,
task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)
# 领域特定数据训练
training_args = TrainingArguments(
output_dir="legal_llama",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
num_train_epochs=3,
fp16=True
)
# 开始微调
trainer = Trainer(
model=model,
args=training_args,
train_dataset=legal_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
trainer.train()
5.2 提示工程工厂模式
class PromptEngineer:
def __init__(self, model_endpoint):
self.endpoint = model_endpoint
def generate_sql_prompt(self, natural_language):
return f"""
### 任务:将自然语言转换为SQL查询
### 数据库Schema:
{get_db_schema()}
### 示例:
问题:查询上季度销售额最高的产品
SQL:SELECT product_id, SUM(amount) AS total_sales
FROM sales
WHERE sale_date BETWEEN '2023-01-01' AND '2023-03-31'
GROUP BY product_id
ORDER BY total_sales DESC
LIMIT 5
### 当前问题:{natural_language}
SQL:
"""
def generate_code_review_prompt(self, code_diff):
return f"""
[角色] 您是具有20年经验的Python首席架构师
[任务] 严格审查以下代码变更,识别潜在问题并给出改进建议
[关注点]
1. 安全性:SQL注入、XSS漏洞等
2. 性能:时间复杂度、内存泄漏风险
3. 可维护性:代码重复、文档缺失
4. 符合PEP8规范
[代码变更]
{code_diff}
[审查报告]
"""
def execute_prompt(self, prompt_template):
response = requests.post(
self.endpoint,
json={"prompt": prompt_template},
headers={"Authorization": f"Bearer {API_KEY}"}
)
return response.json()["completion"]
六、效能优化与可信AI
6.1 大模型推理优化
量化与蒸馏技术:
# 动态量化
from torch.quantization import quantize_dynamic
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
quantized_model = quantize_dynamic(
model,
{torch.nn.Linear},
dtype=torch.qint8
)
# 知识蒸馏
from transformers import DistilBertForSequenceClassification, DistilBertConfig
teacher = AutoModelForSequenceClassification.from_pretrained("bert-large-uncased")
student_config = DistilBertConfig.from_pretrained("distilbert-base-uncased")
student = DistilBertForSequenceClassification(student_config)
distiller = Distiller(
teacher=teacher,
student=student,
temperature=2.0,
alpha_ce=0.5,
alpha_mse=0.5
)
distiller.train(train_dataset)
6.2 可信AI保障体系
# 偏见检测框架
from aix360.algorithms.lime import LimeTextExplainer
from fairness import DemographicParity
class AIAuditor:
def __init__(self, model):
self.model = model
self.explainer = LimeTextExplainer()
def detect_bias(self, dataset, protected_attributes):
return DemographicParity().compute(
dataset,
self.model.predict,
protected_attributes
)
def explain_decision(self, input_text):
exp = self.explainer.explain_instance(
input_text,
self.model.predict_proba,
num_features=10
)
return exp.as_list()
def robustness_test(self, adversarial_examples):
clean_acc = accuracy_score(y_true, self.model.predict(X))
adv_acc = accuracy_score(y_true, self.model.predict(adversarial_examples))
return {
"clean_accuracy": clean_acc,
"robust_accuracy": adv_acc,
"vulnerability": clean_acc - adv_acc
}
七、未来架构:AI优先的开发范式
7.1 自主编程代理体系
from autogen import AssistantAgent, UserProxyAgent
# 创建AI开发团队
engineer = AssistantAgent(
name="Senior_Engineer",
system_message="你是有10年经验的Python专家",
llm_config={"model": "gpt-4-turbo"}
)
architect = AssistantAgent(
name="Solution_Architect",
system_message="你负责系统架构设计",
llm_config={"model": "gpt-4-turbo"}
)
qa = AssistantAgent(
name="Quality_Engineer",
system_message="你负责代码质量和测试",
llm_config={"model": "gpt-4-turbo"}
)
# 用户代理控制流程
user_proxy = UserProxyAgent(
name="Product_Manager",
human_input_mode="NEVER",
code_execution_config={"work_dir": "dev"}
)
# 启动项目开发
user_proxy.initiate_chat(
recipients=[architect, engineer, qa],
message="构建电商推荐微服务:使用FastAPI实现,集成协同过滤算法"
)
7.2 量子-经典混合架构
量子增强ML工作流:
import pennylane as qml
from torchquantum import QuantumLayer
# 量子特征编码
def quantum_feature_embedding(inputs):
qml.AngleEmbedding(inputs, wires=range(4))
qml.StronglyEntanglingLayers(weights, wires=range(4))
return [qml.expval(qml.PauliZ(i)) for i in range(4)]
# 创建混合模型
class HybridRecommendationModel(nn.Module):
def __init__(self):
super().__init__()
self.classical_nn = nn.Sequential(
nn.Linear(100, 32),
nn.ReLU()
)
self.quantum_layer = QuantumLayer(
quantum_feature_embedding,
n_wires=4,
q_device="lightning.qubit"
)
self.output = nn.Linear(4, 10)
def forward(self, x):
x = self.classical_nn(x)
x = self.quantum_layer(x)
return self.output(x)
结论:人机协同的新纪元
AI编程革命正在重塑技术行业的DNA:
- 开发效能跃迁:代码生成速度提升5-10倍,测试覆盖率突破90%天花板
- 能力民主化:低代码平台使业务专家直接参与应用创建
- 行业深度变革:
- 金融业:风控响应时间从小时级降至毫秒级
- 医疗业:诊断准确率平均提升35%
- 制造业:产品缺陷预测准确率达98%
- 新职业图谱:
- 提示工程师
- AI训练师
- 人机协作总监
当GitHub数据显示2025年新增项目中70%包含AI生成代码时,真正的变革不是机器取代人类,而是掌握AI工具的开发者取代未掌握新工具的同行。未来的赢家将是那些将AI作为“智力增强器”的团队,他们将在效能与创新维度建立双重护城河。
参考资源:
技术栈标签:AI编程 GitHub Copilot 低代码开发 智能测试 金融科技 医疗AI 大模型微调 提示工程 量子机器学习 可信AI

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐
 19
19 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)