
生产力UP!文心快码 Rules 功能实战指南
一文学会在Comate AI IDE中配置Rules
AI 编程提升生产力的诀窍,不在于“能生成”,而是“生成得对”。虽然调试 Prompt 能在一定程度上提升生成效果,但面对复杂的开发任务,Prompt 往往显得力不从心——需要反复输入,补充上下文,操作琐碎且难以复用。只有当 AI 拥有足够丰富、结构化的上下文,它才能真正理解用户的意图、持续做出正确响应。在真实开发场景中,AI 要完成的工作远比普通问答更复杂,真正实现提效,必须优化上下文工程。
而配置Rules正是在AI编程场景中做好上下文工程的关键手段之一,可将你的项目规范、组件偏好、命名方式等转化为机器可读的规则,持续作为上下文注入到智能体生成逻辑中。通过给文心快码编程智能体Zulu配置 Rules,开发者可以向Zulu解释代码库和各名词是干什么的、关键的代码在哪里、常见场景怎么写代码,还可以正向控制Zulu的生成行为、反向约束它的错误行为。有了明确的规则,Zulu可以更懂你,更能让复杂、重复、场景化的需求一键复用,真正实现从“指令式对话”迈向“协同式开发”,让AI编程智能体真正具备工程师思维。
一 Rules功能应用场景
在实际开发中,Zulu 规则功能可广泛应用于但不限以下典型场景:
1.项目初始化与结构规范
通过规则预设框架选型、目录结构、命名习惯等,Zulu 可自动将新功能模块生成至正确位置,保持代码整洁一致。
如:新增页面时,自动落在 pages/xxx/index.tsx 并按团队规范命名组件与样式。
2.统一接口与服务管理
设定接口命名和注册规则,Zulu 在生成接口时会自动完成统一挂载、类型定义和错误处理逻辑,降低维护成本。
如:新增 API 会同步写入 api/index.ts 和统一错误处理模块。
3.测试与文档自动补全
规则可指定测试文件生成路径与模板,或要求在生成组件/方法时同步补充注释与文档说明,提升工程可维护性。
如:生成函数时自动补充 JSDoc,或同步生成 Jest 单测文件。
4.团队协作与开发风格约定
通过规则固定代码风格(命名、缩进、注释习惯等),Zulu 可作为“代码守门人”辅助新成员快速对齐团队标准。
如:强制使用驼峰命名,禁止使用特定不推荐的 API。
二 使用指南
新建Rules
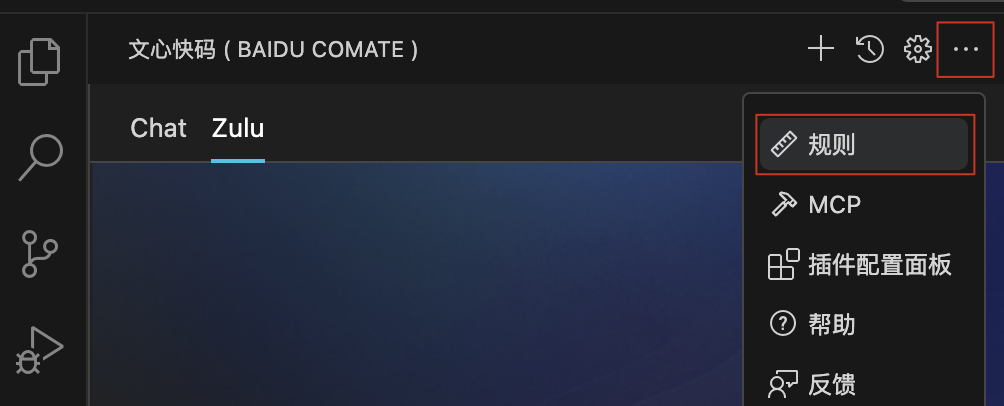
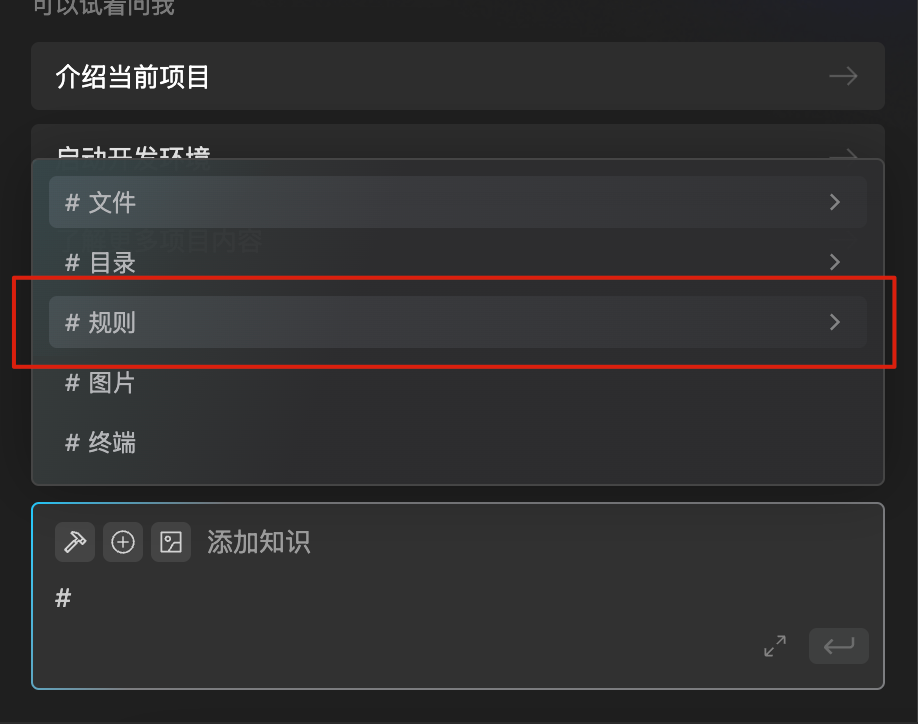
1.进入规则设定页面:在文心快码插件或Comate AI IDE中点击右上角更多「…」选项,再点击「规则」进入规则设定页面。
2.可以从设置中查看所有规则及其状态的列表。
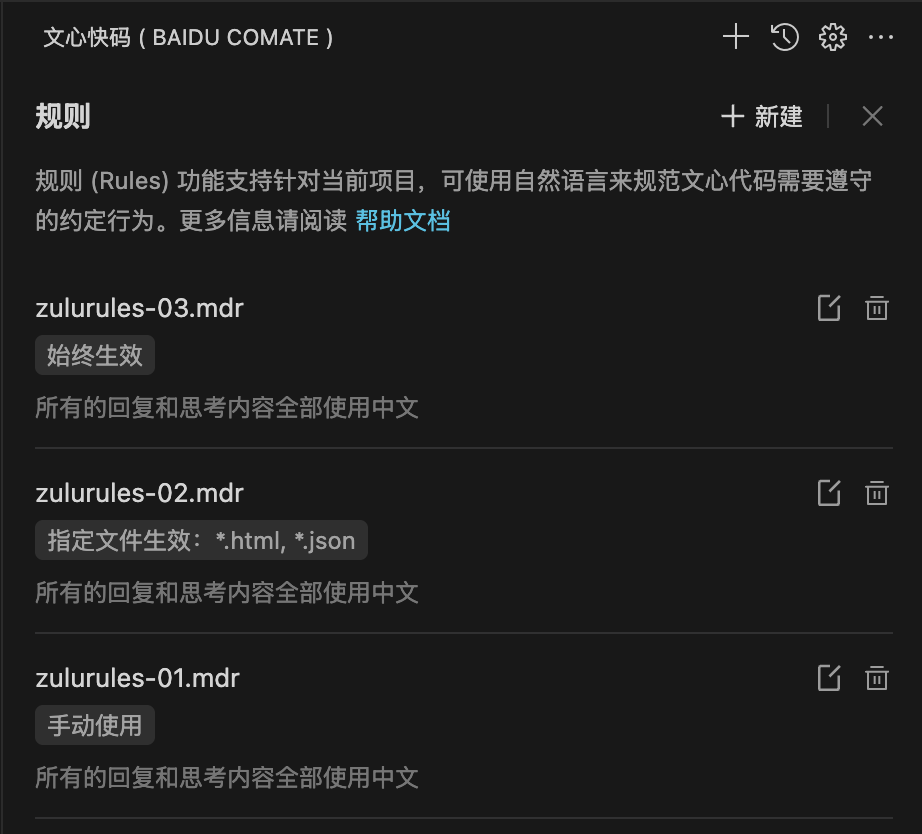
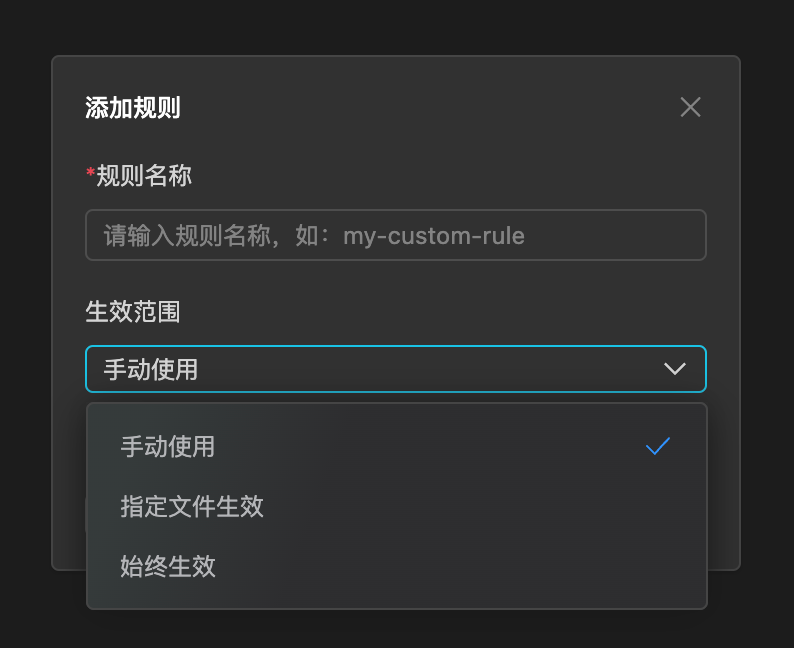
3.新建规则:进入规则设定页面后,点击右上角「+ 新建」按钮,添加新的规则,为规则进行命名和选择生效范围。

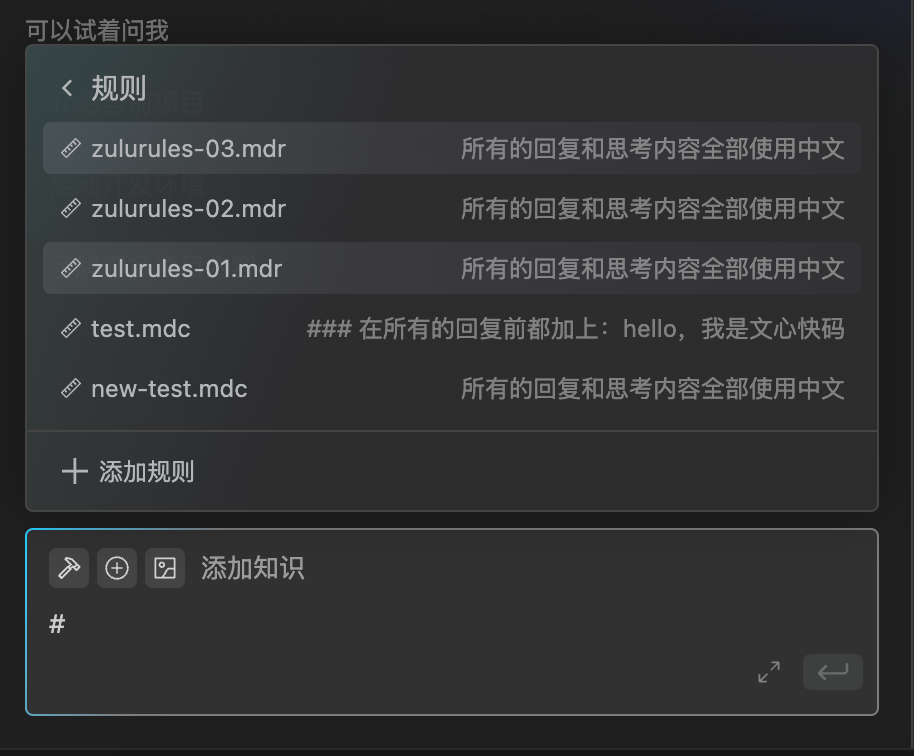
4.直接新建规则文件:你也可以在.comate/rules路径下直接创建格式为*.mdr的文件。
5.编写规则内容: 在*.mdr的规则文件中,使用清晰、明确的自然语言,可以按 Markdown 格式组织内容,编写你希望 AI 在处理此项目时必须遵守的指令、约束或偏好设置。编写后记得要将文件进行保存。
设置多Rules
你可以在规则设定页面,根据需求设定不同的规则和生效方式。Zulu 在后续与该项目相关的交互中,会自动加载并遵循设定的规则。
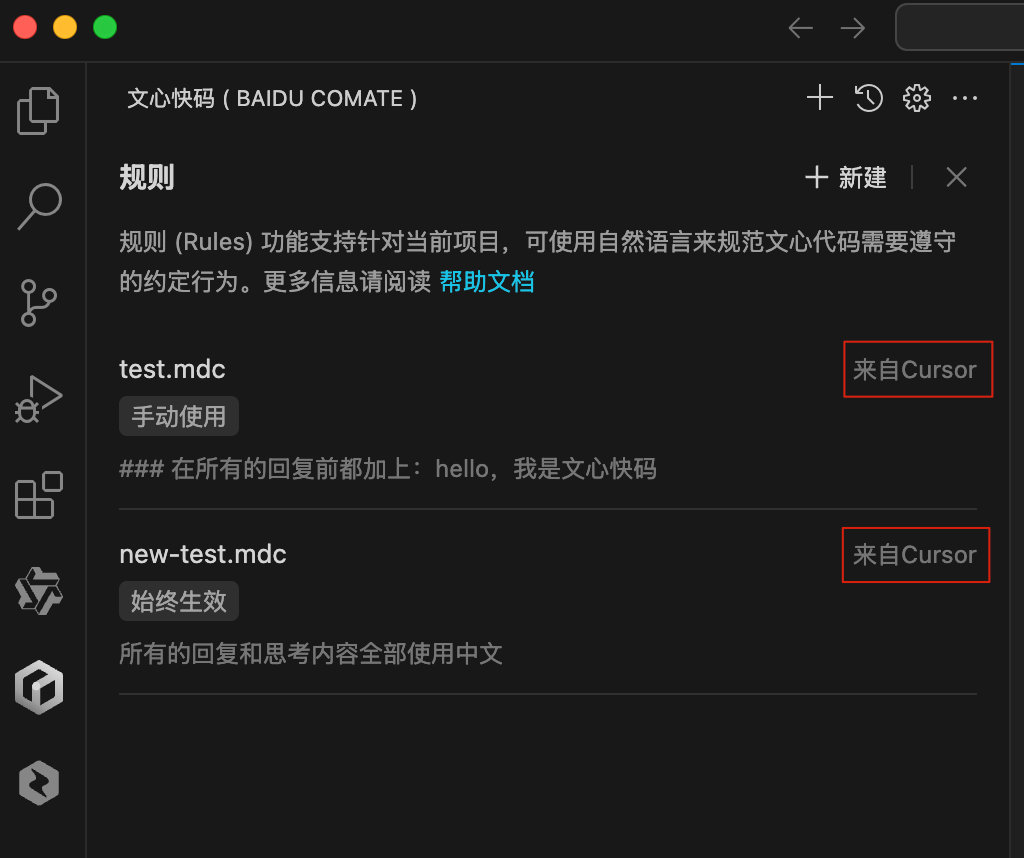
兼容Cursor Rules
Zulu可自动获取你在Cursor中设定的规则,无需在文心快码中重复添加。
注意:
1.Zulu无法通过图形化界面编辑Cursor规则的生效范围,可通过文件编辑器修改
2.暂不支持获取Cursor Rules子目录
使用规则
每个规则文件都是一个 .mdr 格式文档,可将生效信息和规则内容放在一个文件中。当前支持以下生效方式:
1.如果你希望规则仅在自己的本地开发环境生效,不想通过版本控制分享给团队其他成员(例如,一些个人编码习惯或临时性的指令),可以将.comate/rules/文件路径添加到项目的目录文件中。这样,Git 等版本控制系统就会忽略这些文件的变动。
2.始终生效的规则每次对话都会调用,就像刻入了Zulu的DNA,到哪儿都适用,无需持续关注。
3.指定文件生效的规则仅在上下文中包含特定文件时生效,Zulu会根据历史对话或当前对话中已添加文件判断哪些规则生效,指定文件支持通配符+文件路径/文件格式(例如*.py或client/*/*.tsx) 。
4.手动生效的的规则,需要用到时,在对话框中#此规则进行使用即可,随用随取(例如在对话中#rulename)
注意:你可以手动选择所有设定的规则,但其是否在会话中生效,取决于具体的设定内容。例如规则指定文件*.py,但当前对话上下文中未包含*.py的文件,则此规则依旧不会生效。
三 实战演练
接下来和我们一起练手吧,看看Zulu是如何在规则的约束下按照项目规范进行开发。示例项目async-iterator 是一个处理异步数据流的工具库,默认提供了一些数据操作符,包括:
-
chunk.ts: 数据分块
-
debounce.ts: 防抖处理
-
filter.ts: 数据过滤
-
map.ts: 数据转换
-
take.ts: 取前N个元素
-
until.ts: 条件终止
接下来我们为项目新增一个 skip 操作符,看看 Zulu 如何在规则的约束下生成更高质量的代码。
视频版教程⬇️
如何使用Rules功能让AI“做对事”?
示例 Rules
以下是示例规则,它定义了示例项目的开发规范。先来看看每个部分都跟Zulu约定了什么:
1. 项目概述
用一句话向 Zulu 说明:“这是一个处理异步数据流的工具库,目标是简化 JS/TS 中 async iterable 的使用。” 这样 AI 就能快速建立起对项目核心目标的理解。
2. 项目架构
清晰列出项目模块的职责和文件位置,比如控制器、工厂方法、操作符等等。这能帮助 Zulu 理解“不同类型的代码该放在哪”,写代码不再“乱放”。
3. 代码结构说明
包括两部分:
核心接口:定义了 OverAsyncIterator 接口,也就是链式操作符的标准格式。AI 据此知道该如何设计新方法。
工厂函数:列出已有的数据源工厂(数组、事件、流等),提示 AI 未来应如何复用已有模式创建新流。
4. 开发指南
这是最关键的一部分,规定了项目扩展的标准流程。
“基本流程”告诉 Zulu新增操作符应该放哪里、怎么导出、如何支持链式调用。
“扩展指南”更细致地列出了每一步,比如添加操作符时要修改哪些文件,确保它能“按套路出牌”,不会遗漏关键步骤。
“测试规范”告诉 Zulu功能要配测试,测试必须符合命名和结构规范,而且不能降低覆盖率标准。这确保了自动生成的代码也能顺利通过项目的 CI 要求。
5. 代码风格指南
设定了统一的代码风格:
-
类型用 interface
-
多用泛型提高复用性
-
错误统一用 Error 对象处理
-
命名使用驼峰规则(函数名小驼峰、类名大驼峰)
有了这些规范,AI 生成的代码就能和团队已有代码风格保持一致,不再“风格跑偏”。
6. 注意事项
列出一些“隐性规范”,类似资深工程师的开发经验:
-
异步代码要正确 catch 错误
-
注意事件监听器导致的内存泄漏
-
接口不能随便破坏兼容性
-
要写清楚注释、避免副作用、提高可测试性
这些细节告诉 AI:你不只是来“生成代码的”,你要像个真正的工程师一样思考和交付。
## 项目概述
这是一个用于处理异步迭代的工具库,提供了一系列用于处理异步数据流的工具和操作符。该项目主要解决了在JavaScript/TypeScript中处理异步数据流的复杂性问题,提供了简单易用的API。
## 项目架构
项目采用模块化设计,主要分为以下几个核心部分:
1. **核心控制器** (`controller.ts`)
- 实现了 `AsyncIteratorController` 类
- 负责管理异步数据流的状态和控制
- 提供了数据的输入输出接口
2. **工厂模块** (`factory/`)
- `array.ts`: 处理数组的异步迭代
- `event.ts`: 处理事件源的异步迭代
- `reader.ts`: 处理流读取器的异步迭代
- `stream.ts`: 处理Node.js流的异步迭代
3. **辅助工具** (`helper/`)
- 提供了一系列操作符来处理异步迭代器
- 实现了链式调用API
- 包含多个独立的操作符实现
4. **操作符** (`helper/operators/`)
- `chunk.ts`: 数据分块
- `debounce.ts`: 防抖处理
- `filter.ts`: 数据过滤
- `map.ts`: 数据转换
- `take.ts`: 取前N个元素
- `until.ts`: 条件终止
## 代码结构说明
### 1. 核心接口
typescript
interface OverAsyncIterator<T> extends AsyncIterable<T> {
filter(predicate: Predicate<T>): OverAsyncIterator<T>;
map<R>(transform: (value: T) => R): OverAsyncIterator<R>;
chunk(size: number): OverAsyncIterator<T[]>;
debounce(ms: number): OverAsyncIterator<T[]>;
take(count: number): OverAsyncIterator<T>;
until(predicate: Predicate<T>): OverAsyncIterator<T>;
}
### 2. 工厂函数
项目提供了多个工厂函数来创建异步迭代器:
- `fromIntervalEach`: 从数组创建带间隔的异步迭代器
- `fromEvent`: 从事件源创建异步迭代器
- `fromStreamReader`: 从流读取器创建异步迭代器
- `fromStream`: 从Node.js流创建异步迭代器
## 开发指南
### 1. 基本开发流程
1. 如需增加运算符,放置在`src/helper/operators`目录下。
2. 所有运算符都要从`src/helper/index.ts`导出,并能够链式调用。
3. 如果增加对流的消费、创建流的方式,放置在`src/factory`目录下。
### 2. 扩展开发指南
1. **添加新的工厂函数**
- 在 `factory/` 目录下创建新文件
- 实现相应的工厂函数
- 在 `index.ts` 中导出
2. **添加新的操作符**
- 在 `helper/operators/` 目录下创建新文件
- 实现操作符函数
- 在 `helper/index.ts` 中添加到 `OverAsyncIterator` 接口
- 在 `over` 函数中实现新方法
### 3. 测试规范
- 所有功能都需要编写对应的单元测试
- 测试文件放置在相应模块的 `__tests__` 目录下
- 测试文件命名规则:`[功能名].test.ts`
- 增加任何功能,都要运行单元测试,确保测试的行覆盖率在100%,分支覆盖率大于90%。
## 代码风格指南
1. **类型定义**
- 优先使用接口(interface)定义类型
- 为所有公开API提供完整的类型定义
- 使用泛型增加代码复用性
2. **错误处理**
- 统一使用 Error 对象处理错误
- 在异步操作中正确处理错误传播
3. **命名规范**
- 使用驼峰命名法
- 类名使用大驼峰
- 接口名清晰表达其用途
## 注意事项
1. 所有的异步操作都应该正确处理错误情况
2. 注意内存泄漏,特别是在处理事件监听器时
3. 在实现新功能时,确保与现有的接口保持一致
4. 保持代码的可测试性,避免副作用
5. 文档注释要清晰完整,包含参数说明和使用示例操作方式
1.打开 Comate AI IDE
2.点击右上角进入更多选项,打开 「规则」
3.添加规则,命名为:async-iterator-rule,并设置为「始终生效」
4.将添加 Rules 文件正文
5.输入 query:新增一个 skip 操作符,完成所需任务
6.查看生成后的代码是否已严格按照项目规范来生成
效果对比
在设定好规则的情况下
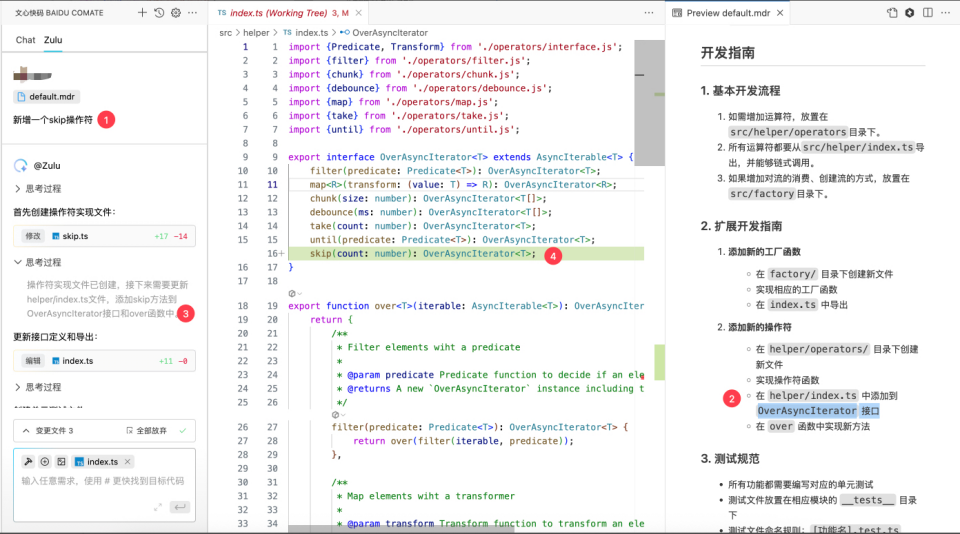
1.我们要求 Zulu 新增一个 skip 操作符
2.项目配置的规则中,有关于添加新操作符的规范,要求新的操作符必须在OverAsyncIterator接口中注册
3.Zulu 在生成过程中,发现并遵循了这个规范
4.最后 Zulu 按照要求将skip操作符注册到了OverAsyncIterator接口,满足要求
如果不定义这个规则,AI 不会严格按照项目规范来生成代码,用户需要花更多时间修正 AI 生成的代码。
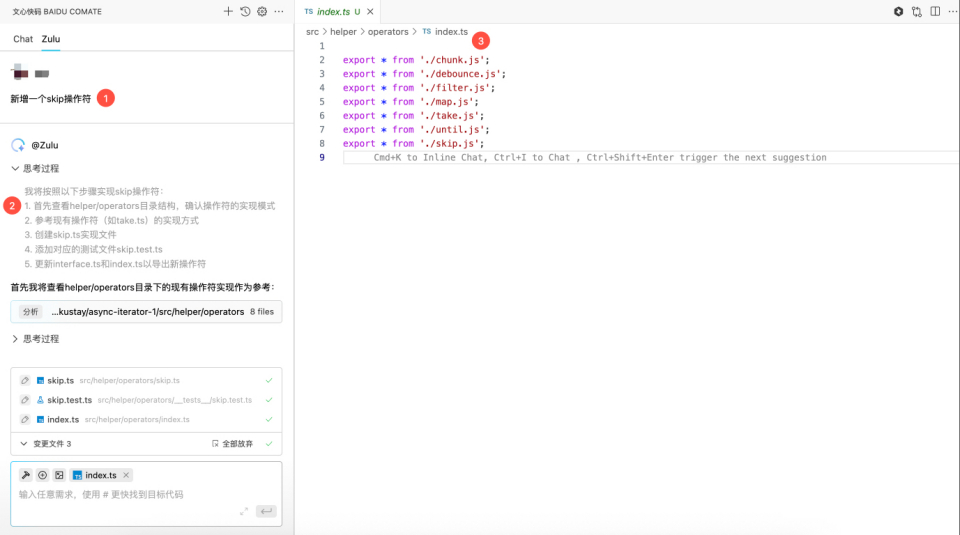
1.我们要求 Zulu 新增一个 skip 操作符,项目中没有配置规则
2.Zulu 在生成代码时,没有发现新的操作符必须在OverAsyncIterator接口中注册这个要求
3.最后 AI 按照自己的理解生成一个新的index.js文件,而没有在现有的index.js中注册,违反了项目规范
在 AI 编程日益普及的今天,Prompt 是初级指令,而 Rules 则是高阶语法。它不仅让 AI 更懂你,还让你的项目更稳定、更可靠。现在,就试试为自己的Zulu配置一条规则吧,看看 Zulu 能做到多聪明。如果你已经有了实用的规则设置,也欢迎在评论区或社区分享你的实战经验,帮助更多开发者解锁 AI 编程的新可能,把Zulu训练成真正的AI工程师。
如果本期内容对你有帮助,关注文心快码,更多干货都在这里。

汇聚全球AI编程工具,助力开发者即刻编程。
更多推荐


 24
24 0
0- 0



 已为社区贡献130条内容
已为社区贡献130条内容

所有评论(0)